1.1 通过id定位元素
- 语法:find_element_by_id(‘kw’)
kw 为该页面元素的id
- 举个栗子:实现在百度首页输入框输入selenium
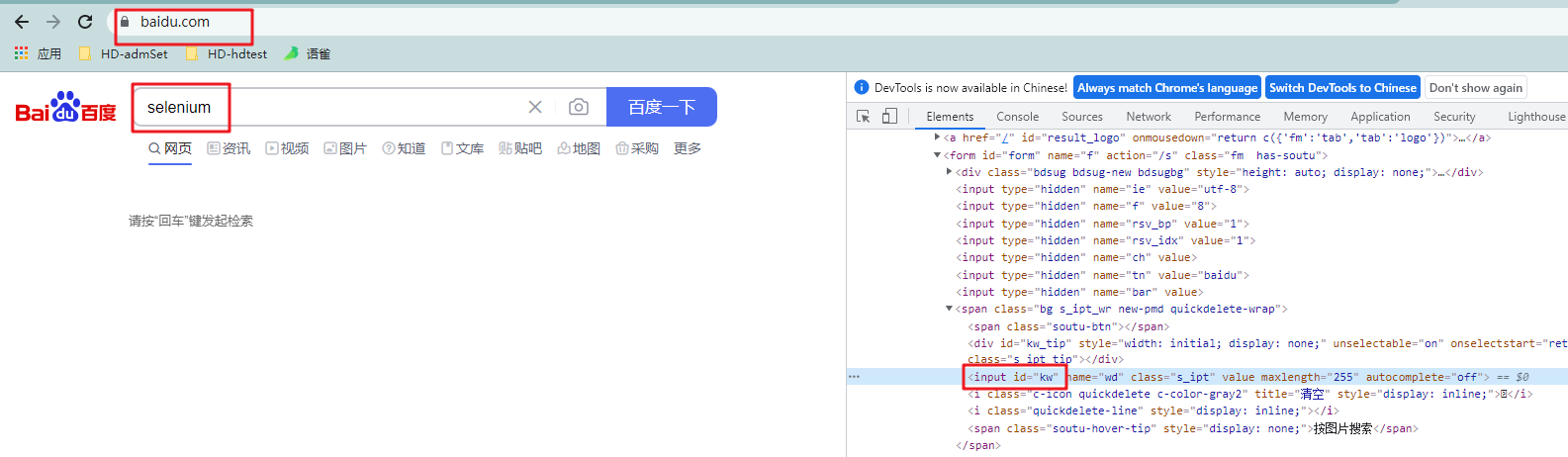
- 代码: ```python from selenium import webdriver
打开Chrome浏览器
driver = webdriver.Chrome()
窗口最大化
driver.maximize_window()
打开百度
driver.get(‘https://www.baidu.com/‘)
在百度首页输入框输入selenium
driver.find_element_by_id(‘kw’).send_keys(‘selenium’)
<a name="Ve79m"></a>### 1.2 通过xpath定位- 语法:find_element_by_xpath('//*[@id="kw"]')//*[@id="kw"] 为该元素的xpath路径- 举个栗子:实现在百度首页输入框输入selenium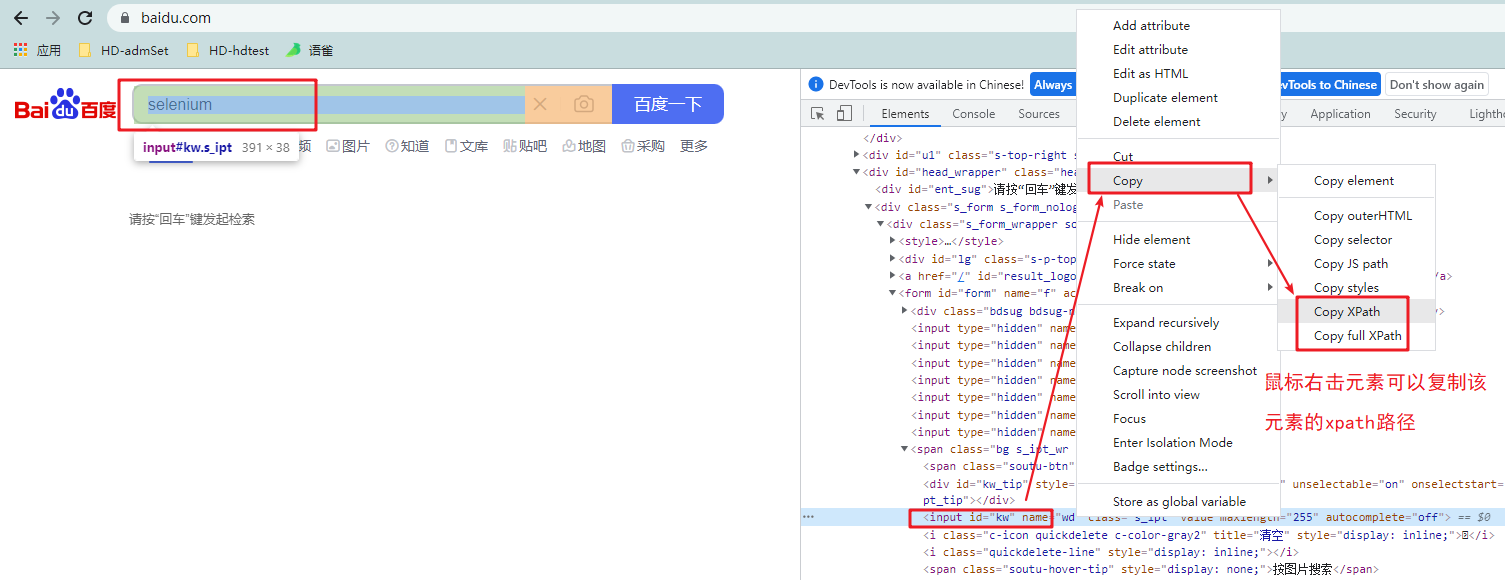- 代码:```python# 只改动1.1 代码的最后一行,其他都是一样的# 在百度首页输入框输入 seleniumdriver.find_element_by_xpath('//*[@id="kw"]').send_keys('selenium')
1.3 通过链接文本定位
- 语法:find_element_by_link_text(‘新闻’)
新闻 为该标签的文本
- 举个栗子:实现点击百度首页的新闻
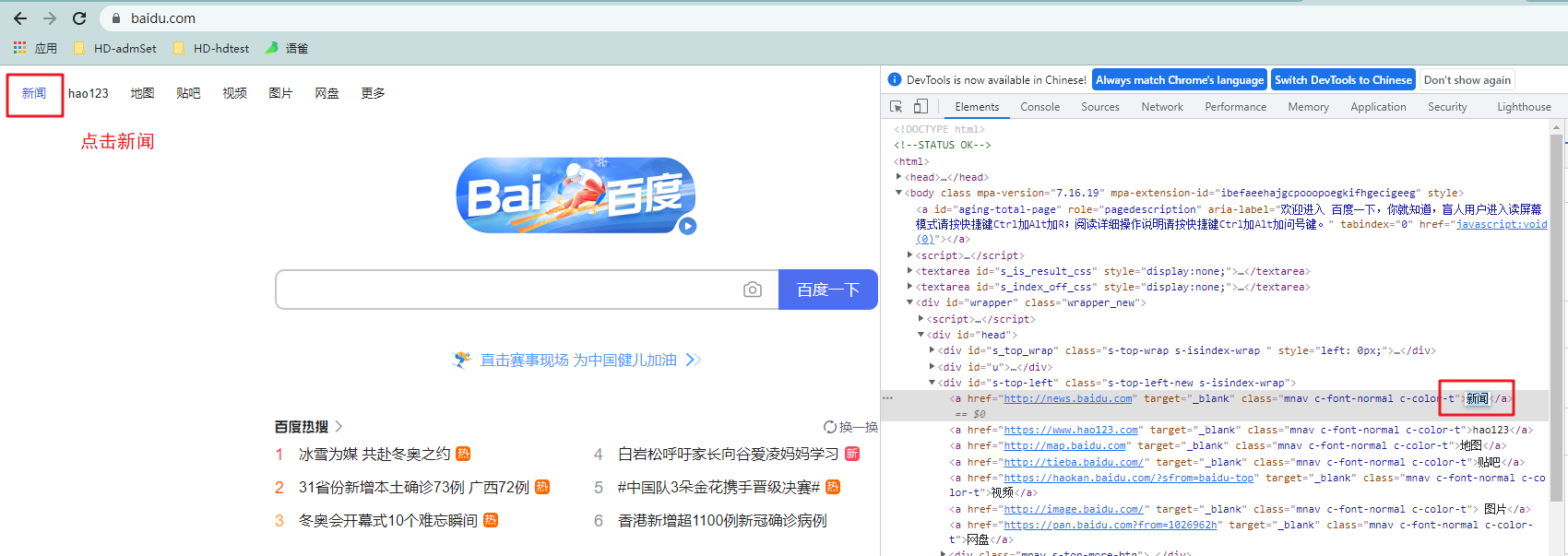
- 代码:
```python
只改动1.1 代码的最后一行,其他都是一样的
在百度首页点击‘新闻’,跳转到新闻页面
driver.find_element_by_link_text(‘新闻’).click()
<a name="i1T9j"></a>### 1.4 通过部分链接文本定位- 语法:find_element_by_partial_link_text('新')新 为该<a>标签的部分文本- 举个栗子:实现点击百度首页的新闻- 代码:```python# 只改动1.1 代码的最后一行,其他都是一样的# 在百度首页点击‘新闻’,跳转到新闻页面driver.find_element_by_partial_link_text('新').click()
1.5 通过标签name值定位
- 语法:find_element_by_name(‘wd’)
wd 为该标签的name属性的值
- 举个栗子:实现在百度首页输入框输入selenium
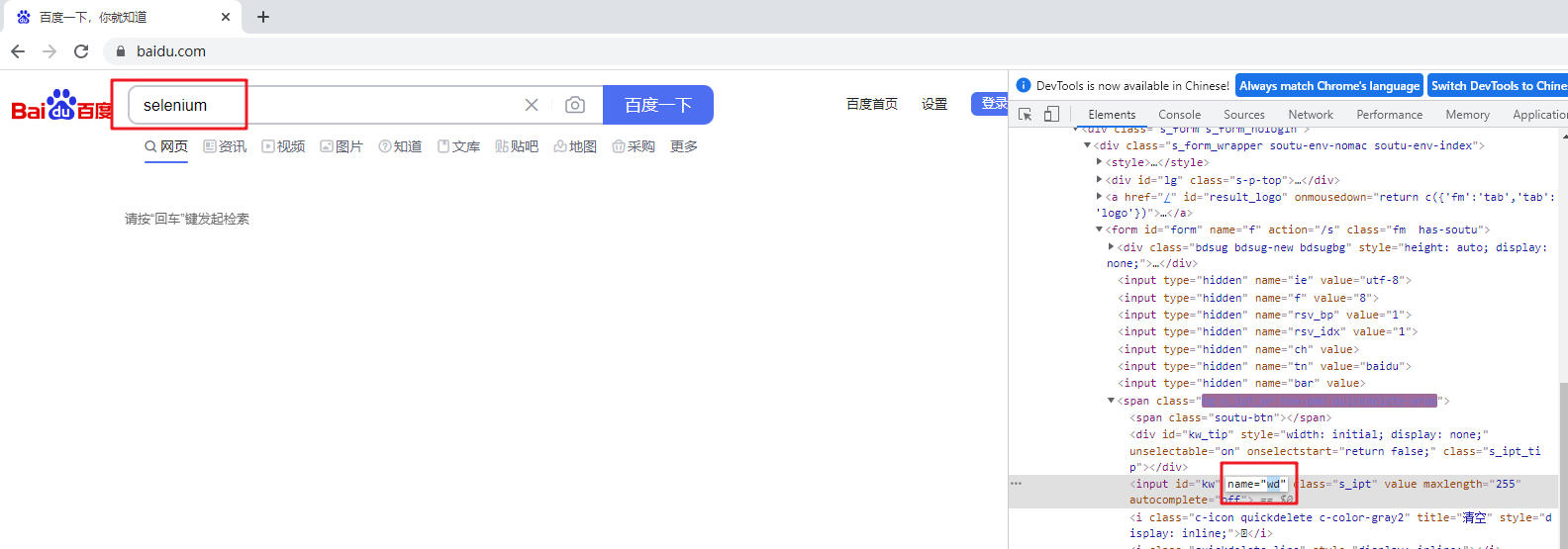
在百度首页输入框输入 selenium
driver.find_element_by_name(‘wd’).send_keys(‘selenium’)
<a name="wqAOa"></a>### 1.6 通过标签名称定位- 语法:find_element_by_tag_name('input')input 为该标签名称- 举个栗子:实现在百度首页定位input输入框- 代码:```python# 只改动1.1 代码的最后一行,其他都是一样的# 在百度首页定位输入框并打印结果print(driver.find_element_by_tag_name('input'))
1.7 通过class定位
- 语法:find_element_by_class_name(‘s_ipt’)
s_ipt 为该标签的class属性的值
- 举个栗子:实现在百度首页定位input输入框
在百度首页输入框输入 selenium
driver.find_element_by_class_name(‘s_ipt’).send_keys(‘selenium’)
<a name="r7xyr"></a>### 1.8 通过css选择器定位- 语法:find_element_by_css_selector('#kw')#kw 为该标签的css选择器- 举个栗子:实现在百度首页定位input输入框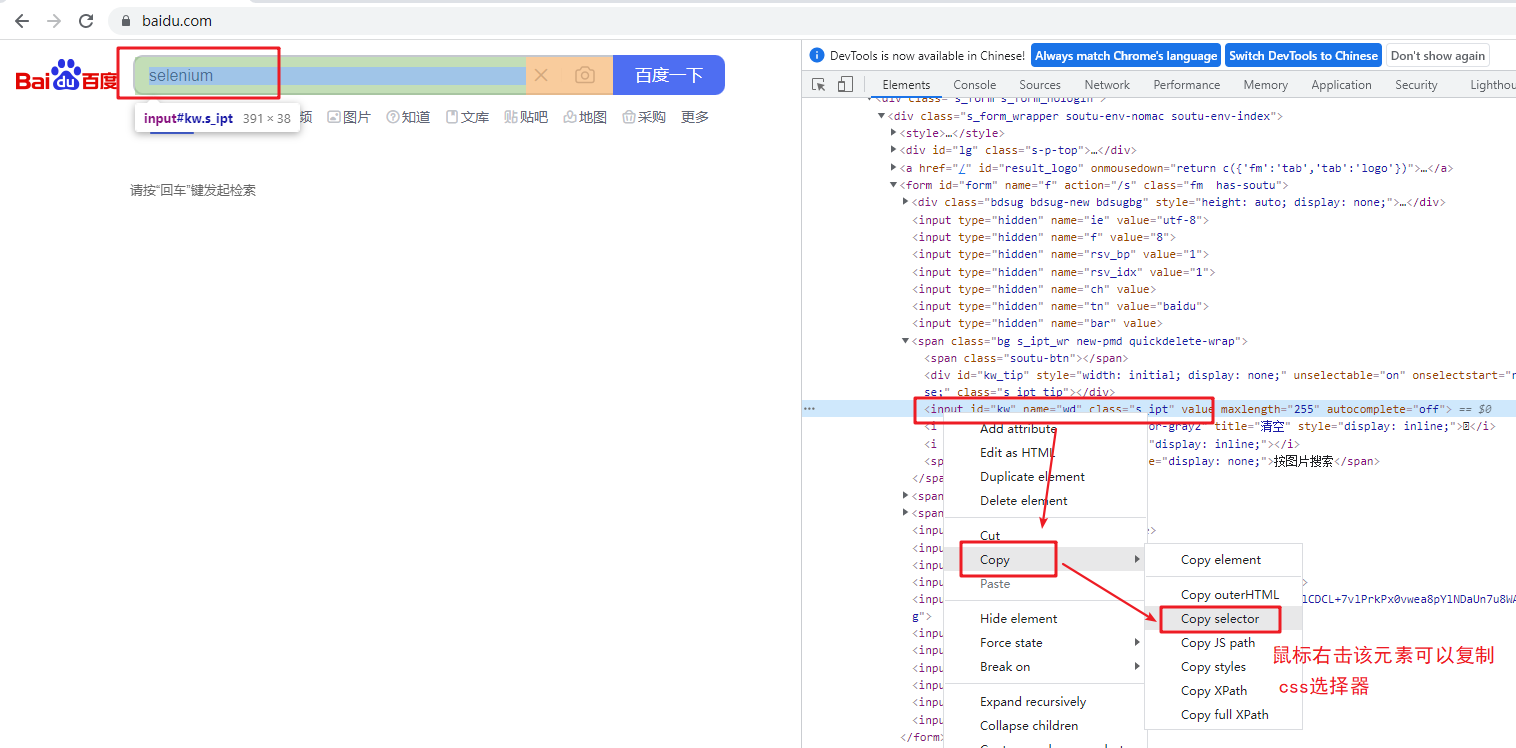- 代码:```python# 只改动1.1 代码的最后一行,其他都是一样的# 在百度首页输入框输入 seleniumdriver.find_element_by_css_selector('#kw').send_keys('selenium')
以上举例的是定位单个元素的用法。定位单个元素用 find_element_by_xxx,当要定位具有相同 id、name、class值等的多个元素时,则用过使用 find_elements_by_xxx。
例如:页面中有多个元素的class值为 kw , 获取页面中class值为 kw 的所有元素的代码为:
# 获取多个元素,返回的结果是一个listkw = driver.find_elements_by_class_name('kw')# 可以通过下标来获取指定元素# 例如将第一个元素赋值给kw1kw1 = driver.find_elements_by_class_name('kw')[0]# 如果用错方法,用成find_element_by_class_name是,会只返回第一个元素# find_element_by_class_name('kw') 跟 find_elements_by_class_name('kw')[0] 结果是一样的

若有收获,就点个赞吧
0 人点赞
