作者:吴锺瑞、刘洪初 编辑:毕小烦
一. 需求背景
造数据可能是日常迭代中最频繁也是最耗时的工作。
我们在20年8月对部门内的测试同学做了一次统计调研,日常工作中各项事务的耗时占比。
如下所示: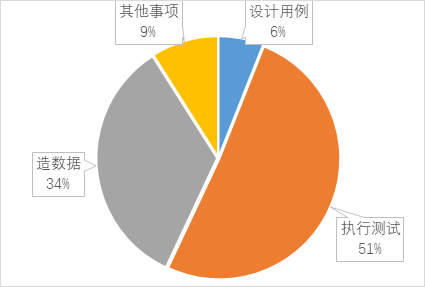
可见造数据所花的时间占了相当大的比重。
其实,造数据的需求不仅是测试人员有,其他人员也有。
比如:
- 产品需要测试数据梳理业务逻辑、验收新功能;
- 开发需要测试数据进行调试、自测、复现问题;
- 其他业务组的同学日常工作中需要上下游的测试数据支持;
- 性能测试需要的大批量数据;
……
从团队整体效率而言,若测试数据需依赖他人支持,还会有额外的沟通成本、等待时间成本,所消耗的时间就更多了。
那如何节省造数据的成本?
常见的解决方式:
- 造数脚本:通过脚本语言快速编写造数据脚本,比较适用于需要大批量(或高频次)的复杂数据需求。优点是灵活性高,可实现绝大多数数据需求。缺点是技术成本偏高,无论实现还是使用,都需要一定技术门槛,难以大范围推广。多是个人编码,个人使用。可能会导致编写成本大于使用收益、重复造轮子等情况。
- 定制工具:一般为桌面端程序,将常用的一些数据场景(如造账号)制作成客户端应用,小巧、易于使用、方便推广。但缺点在于灵活性差,若数据结构发生变更,难以全面更新,还可能导致数据库中脏数据泛滥。
上述 2 个方案都可在一定程度上减少造数据成本,但不够完美,我们需要的应该是一个更加健全的数据工厂。
对于,数据工厂,我们的需要是什么呢?
1. 易于使用
我们的核心目的是降本增效,因此需要保证一个造数据功能带来的效益一定远大于其实现成本。那么,最重要的一点,便是要让所有需要测试数据的人都能独立、便捷地造数据。即实现“一次实现,大量使用”、“一人实现,集体使用”。因此,数据工厂应有一个独立的面向使用者的友好界面,最大限度降低使用门槛和学习成本,在此基础上优化使用体验。
2. 易于开发
具体业务的测试数据,自然是对应业务组的人员最为熟悉。因此,由他们实现对应造数据功能是最为高效。但我们无法要求所有测试同学拥有较高的开发能力,所以平台应提供低代码实现功能的能力,才能让有数据需求的同学在最短时间完成造数据工具并投入使用。
3. 便于维护
应制定统一规范对各造数据功能进行管理,避免功能找不到、重复造轮子等问题。
因此我们对于数据工厂的设计,倾向于易于大多数测试人员快速开发的低代码平台。
二. 前端的设计方案
2.1 应用端的设计
数据工厂的前端功能界面,如下图所示: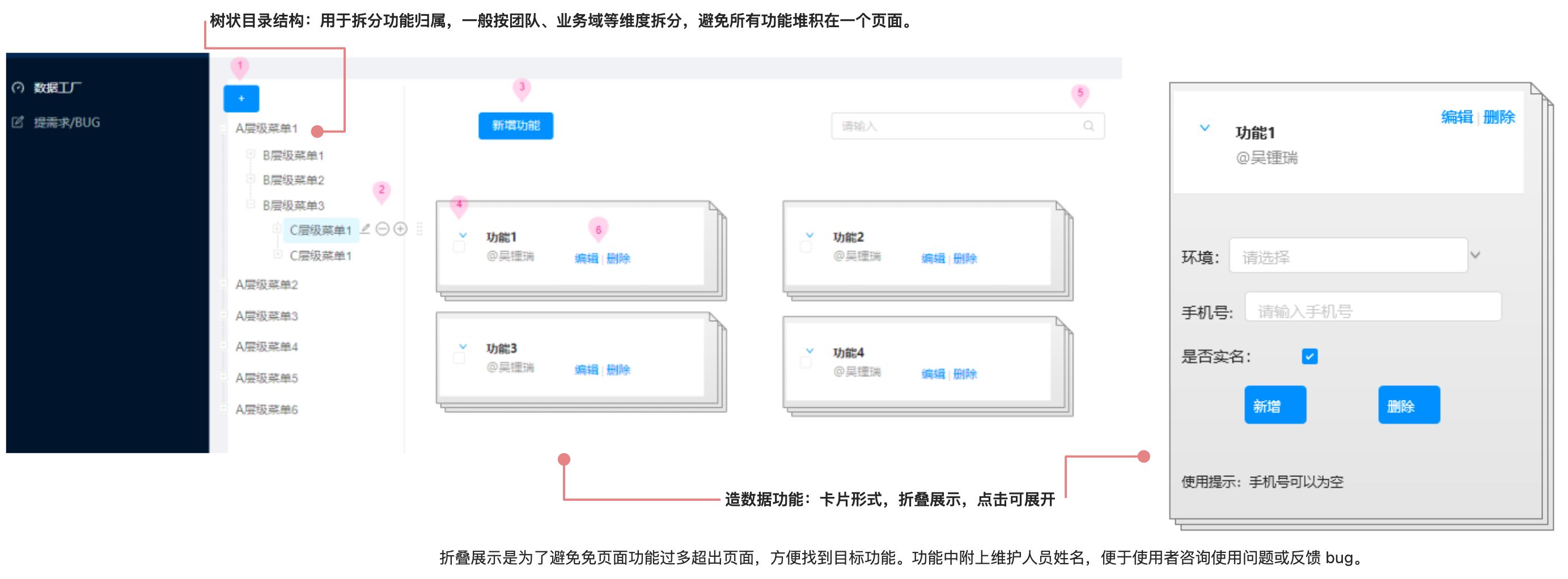
需求的描述如下:
实际的效果如下: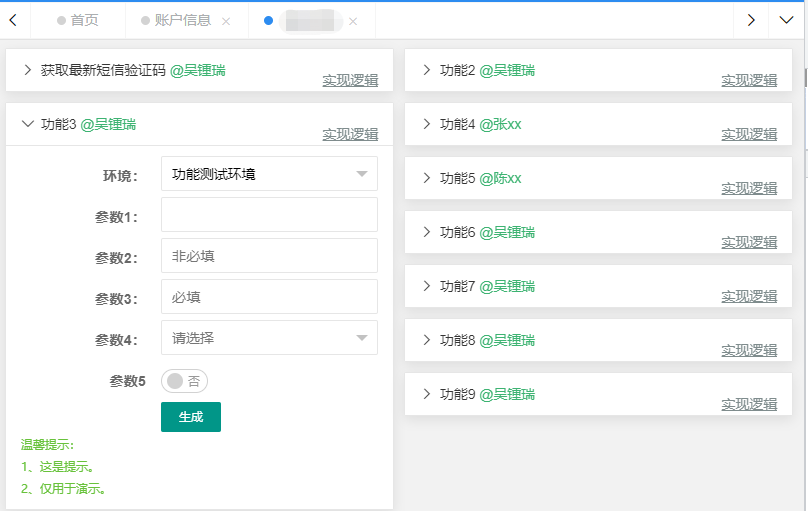
2.2 低代码的实现
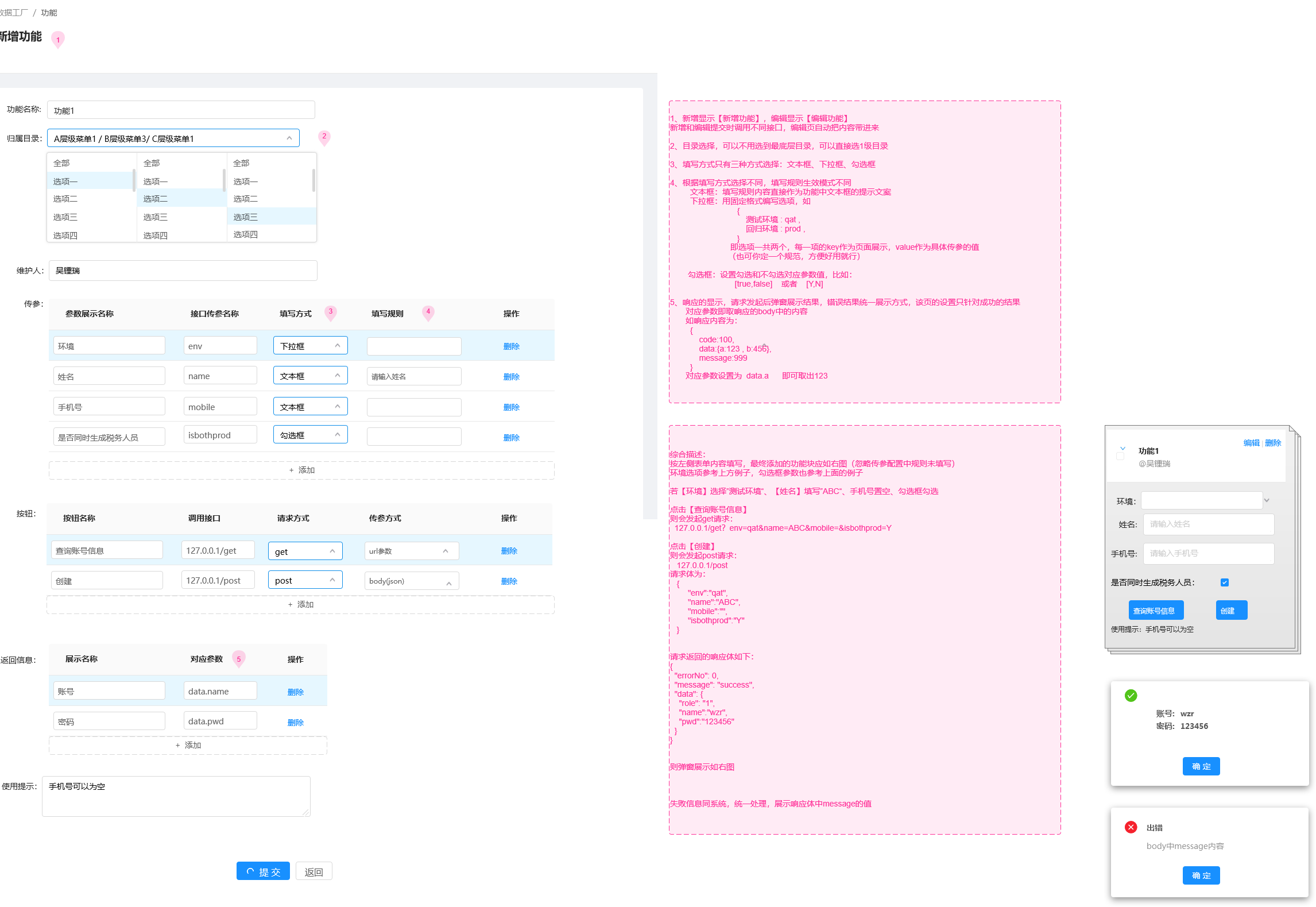
三. 后端的设计方案
后端也是一套低代码开发平台,测试同学可通过平台将造数据所需的 SQL、Shell 命令、业务接口调用等封装成一个 HTTP 接口,提供给前端调用,根据传参动态生成不同的数据。
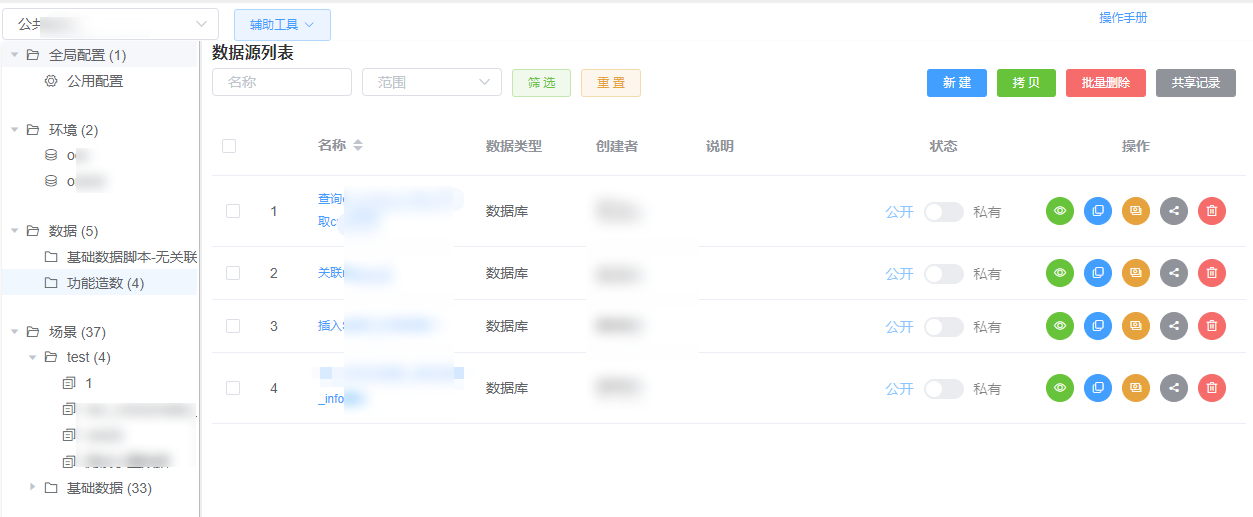
3.1 平台能力
低代码开发平台的能力:
1. 基础配置维护
- 维护各数据库链接,支持5种数据库,可通过参数灵活切换;
- 支持不同测试环境的配置,可通过关键参数调用;
- 全局通用。
2. 造数据功能维护
- 与使用端的目录结构保持一致,便于维护。
3. 编辑造数据功能
- 低代码操作,仅需组装 SQL(或其他操作);
- 提供
select语句转insert语句的能力; - 支持 SQL 语句中参数高亮;
- 支持从接口响应、查询结果、SQL 命令中提取参数;
- 提供一些常用函数,如随机数、加密、获取年月日等;
- 提供批量调用入口,方便为压测场景批量造数据。
3.2 开发流程
低代码开发接口的流程,一共 6 步。
STEP 1. 设计接口需求
假如我们需要一个“造账号”的功能,需要实现一个后端接口 /account/create。
参数使用起来尽可能的简单,那就只有一个用户名(username)是必填的,其他的可选填参数包括性别(sex)、证件号(cid)、账号身份(role,用户登录目标系统后的权限管理)。当然,环境参数(env)也是必须的。
所以我们需要的是一个 POST 请求,请求体内容为:
{"env":"test"," username ":"boss","sex":""," cid ":""," role ":""}
请求的响应中,应包含账号的基本信息以供记录并使用,如用户名、密码(初始密码统一)、随机生成的姓名、证件号(未填写则随机生成)等。
经过前端解析后,大概展示如下: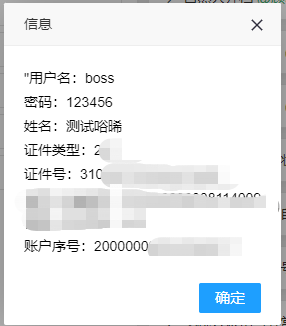
STEP 2. 梳理数据结构
目标明确后,就要梳理如何实现了。假设造账号涉及 3 张表,账号信息表、证件表、身份表,那么基础的是 3 条 SQL 语句。
INSERT INTO 账号信息表(`id`,`username`, `pwd`) VALUES (自增, 'boss', 'xxxxx');INSERT INTO 证件表(`uid`,`cid`,`sex`) VALUES ('xxxxx', 'xxxxx', 'xxxxx');INSERT INTO 身份表(`uid`,`role`) VALUES ('xxxxx', 'xxxxx');
STEP 3. 处理动态参数
然后开始实现功能,首先是变量定义。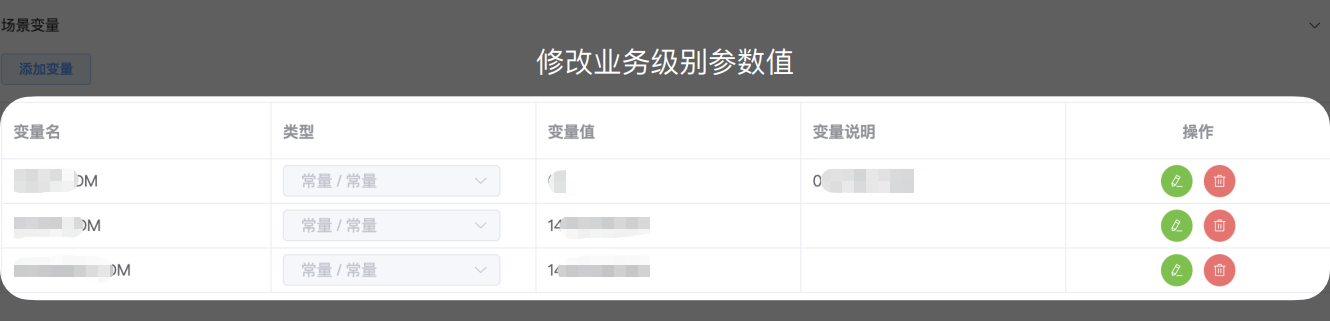
将 SQL 需要的动态参数定义成变量 uid、username、cid、sex、role:
uid为账号信息表的 id,由自增函数自动生成,那么需要在 insert 账号信息表后,用 select 语句查出来,将查询结果赋值。username从接口请求体中读取。cid、sex、role三个参数,使用平台提供的条件判断功能,先判断接口请求体中对应参数值是否为空,若为空则调用平台提供的公共函数随机生成(包含范围随机数、随机证件号等函数)。在 SQL 中使用${变量名}的形式引用。
STEP 4. 组装 SQL 语句
将需要的 SQL 语句按数据处理的顺序组装(此处实际需要 4 条 SQL),用变量引用替换 SQL 中的动态参数。
注:还可添加 http 接口调用、redis 处理、shell 命令等操作,但本例不需要。
STEP 5. 提取关键数据
参考顶层设计,该功能需要将账号的基础信息返回,以供记录。
关键数据的提取有多种方式,包括 SQL 语句(语句中提取、执行结果提取)、HTTP 请求(参数提取、响应体提取)、局部/全局变量提取等。
STEP 6. 生成所需接口
功能实现后,会自动生成接口 /account/create,将提取的关键数据组装 JSON 作为响应进行返回。
到此,一个造数功能的接口服务就实现了,可以通过前端页面进行调用,还可通过特殊参数进行批量执行支持压测所需的大批量数据。
四. 效果收益
我们团队从 2021 年开始实践数据工厂,初步成型后推广至整个事业部。截至2022年6月,平台上已上线造数据功能 N 个,满足事业部 95% 以上的业务场景。产品、开发、其他团队人员均可在短时间内的完成造数,测试人员日常工作中造数据的用时占比已降至 6.8%。
(完)
微信搜索“毕小烦”或者扫描下面的二维码,即可订阅我的微信公众号。
如果文章对你有帮助,记得留言、点赞、加关注哦!

若有收获,就点个赞吧
0 人点赞
