元学习 Meta Learning,meta 这个词很好玩,在各个领域都能经常听到。“Meta X”的意思就是“X about X”。比如 Meta data 的意思就是“描述数据的数据”,而 Meta Learning 其实就是“learn to learn”学习如何学习。
元学习听起来名字挺大,有种与深度学习齐名的感觉,但其实是训练模型的一种框架。元学习的初衷是让模型自主学习如何去对数据进行分类、回归等,具体一点,比如“如何进行二分类、三分类”等。既然是“学习如何学习”,一般情况下就是希望使用少量的数据就能让模型学到一个不错的效果。所以元学习的方法,经常用来完成小样本学习(Few-shot Learning)任务。
1 Meta Learning 元学习基础
该部分基于李宏毅机器学习元学习部分,结合本人所学过程中问题以及阅读论文等相关资料,介绍元学习的思想以及模型架构。
使用机器学习(深度学习)完成指定任务,一般可以总结为三个步骤:
- 定义函数
 ,制定好哪些参数
,制定好哪些参数 是可学习的;
是可学习的; - 定义损失函数
 ;
; - 找到一个合适的优化算法,在深度学习里面一般就是梯度下降法及其变种
 。
。
元学习也是如此三个步骤,接下来依次展开。优化算法当然还是基于梯度下降法,就不赘述了。
1.1 定义函数 F

图片截自李宏毅机器学习元学习视频
Meta learning 希望学习得到一个函数 ,进而通过
,进而通过 根据不同的输入
根据不同的输入 产生一个对应的(分类、回归等)模型
产生一个对应的(分类、回归等)模型 来预测
来预测 ,即
,即 。其中
。其中 是可学习的参数,而
是可学习的参数,而 是由
是由 产生的,这里的
产生的,这里的 就可以是任何拍脑门想出来的模型参数,比如模型的层数、每一层(CNN、FCN 等)的参数、学习率等。根据视频中可知,元学习是基于要学习参数的类别进行分类的。
就可以是任何拍脑门想出来的模型参数,比如模型的层数、每一层(CNN、FCN 等)的参数、学习率等。根据视频中可知,元学习是基于要学习参数的类别进行分类的。
从上图中可知, 就是我们正常用来图片分类、自然语言处理等深度学习模型,而这个深度学习的模型不是直接通过训练数据学出来的,而是通过另一个模型
就是我们正常用来图片分类、自然语言处理等深度学习模型,而这个深度学习的模型不是直接通过训练数据学出来的,而是通过另一个模型 的输出所得到的,因此
的输出所得到的,因此 才是直接学习的对象。那么既然可以用一个深度神经网络来拟合参数
才是直接学习的对象。那么既然可以用一个深度神经网络来拟合参数 ,那么
,那么 就也可以是自定义的神经网络或其他模型。
就也可以是自定义的神经网络或其他模型。
1.2 定义损失函数
元学习本质还是机器学习,即给定样本特征 和标签
和标签 ,得到预测标签
,得到预测标签 。如何定义损失函数(
。如何定义损失函数( 与
与 之间的差距)就要看模型的输出长什么样,模型的输出长什么样就要看元学习是如何输入数据、处理数据的。
之间的差距)就要看模型的输出长什么样,模型的输出长什么样就要看元学习是如何输入数据、处理数据的。
图片截自李宏毅机器学习元学习视频
一般深度学习的训练和测试流程会把训练数据和测试数据分成好多批次(batch),每个批次的大小为 batch_size,一个批次一个批次地训练 | 预测模型。而元学习是将数据分成好多个训练任务(task)和测试任务,每个任务中都包含了训练样本(samples)和测试样本。当然,训练任务就是用来训练模型的,而测试任务就是用来测试模型性能的。由于 才是我们最终希望学习的参数,所以训练任务和测试任务的区别就在于是否对
才是我们最终希望学习的参数,所以训练任务和测试任务的区别就在于是否对 通过反向传播进行更新。
通过反向传播进行更新。
那么在一个任务中为什么又分训练样本和测试样本,它们是如何使用的呢? —— 这就牵涉到了元学习的核心思想。
首先,元学习的初衷是通过学习 进而让其产生出的模型
进而让其产生出的模型 学习一类任务,而不是某一个任务。以二分类问题举例,“二分类”是一类任务,而“分类猫和狗”则是一个具体的任务,元学习希望通过在不同的二分类任务(分类猫狗、分类苹果和橘子等)学习,最终让模型学会“如何进行二分类”(听起来有点夸张),而不是只会分类猫狗、苹果和橘子。上面所说的“二分类”任务,就是元学习的全体可能的输入,而具体的“分类猫和狗”、“分类苹果和橘子”则是元学习模型每一次输入的一个任务。
学习一类任务,而不是某一个任务。以二分类问题举例,“二分类”是一类任务,而“分类猫和狗”则是一个具体的任务,元学习希望通过在不同的二分类任务(分类猫狗、分类苹果和橘子等)学习,最终让模型学会“如何进行二分类”(听起来有点夸张),而不是只会分类猫狗、苹果和橘子。上面所说的“二分类”任务,就是元学习的全体可能的输入,而具体的“分类猫和狗”、“分类苹果和橘子”则是元学习模型每一次输入的一个任务。
其次,具体到每一个训练任务而言,以上图中分类苹果和橘子为例,训练样本首先被输入到 中,由
中,由 产生一个能够解决该任务(即能够分类苹果和橘子)的初始模型
产生一个能够解决该任务(即能够分类苹果和橘子)的初始模型 。随后,用训练样本对
。随后,用训练样本对 进行训练几个 step(在论文中通常被叫做
进行训练几个 step(在论文中通常被叫做update_step,update_step的数值通常较小)得到 。随后将训练任务中的测试样本输入到
。随后将训练任务中的测试样本输入到 中并计算得到损失
中并计算得到损失 作为
作为 在该任务上的损失。
在该任务上的损失。
在一轮的训练过程中会牵涉到 个训练任务和测试任务,
个训练任务和测试任务, 在一轮中的训练损失为将
在一轮中的训练损失为将 个任务的损失求和再取平均,如下图所示。
个任务的损失求和再取平均,如下图所示。
图片截自李宏毅机器学习元学习视频
上图中也包含了一个关键信息,就是同一个任务中的训练样本和测试样本,都来自相同的二分类问题,即 task1 是分类苹果和橘子, task2 是分类自行车和汽车。为了检测模型是否“学会了如何进行二分类”,在测试任务中的分类问题都将是模型没有见过的二分类问题,如“分类猫和狗”等,但只对通过 计算得到的模型预测计算准确度,而不再对参数
计算得到的模型预测计算准确度,而不再对参数 进行更新。元学习训练的大致流程图如下:
进行更新。元学习训练的大致流程图如下: 
在 testing task 上进行预测,只是没有最后一步更新 ,其他的流程跟训练相同。
,其他的流程跟训练相同。
1.3 相关概念
在阅读论文和代码的过程中,除了上述的task、update_step等还经常会遇到一些别的概念。
图片截自李宏毅机器学习元学习视频
在同一个任务(不管是训练任务还是测试任务)中,训练样本通常被称为 support set,而测试样本被称为 query set。

图片截自李宏毅机器学习元学习视频
在训练过程中,在一个任务内训练模型被叫做 within-task training (inner loop),而在不同任务之间训练模型被称为 accros-task trainning (outer loop)。
2 Categorization 元学习分类 TODO
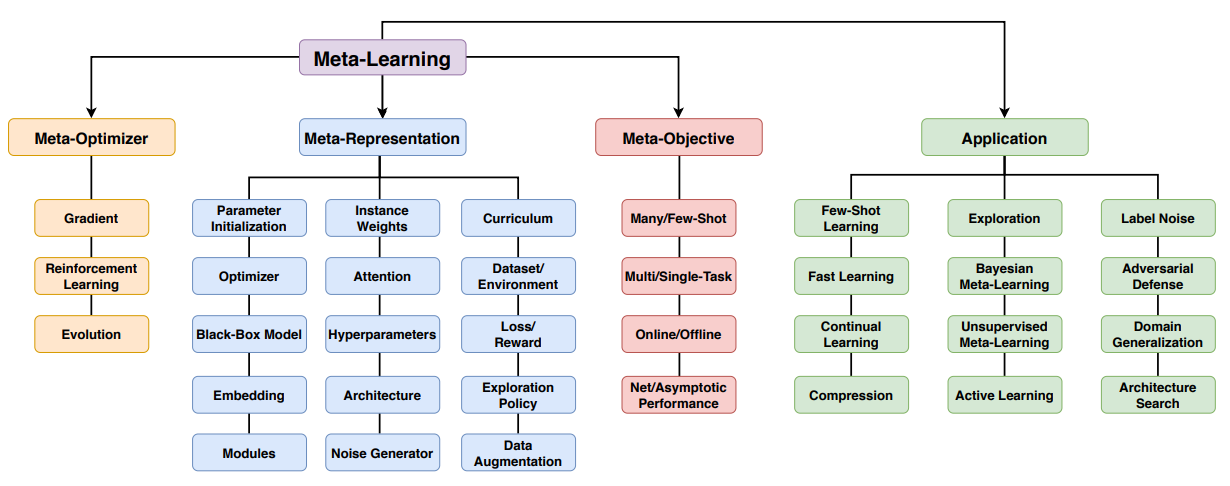
图片来自论文
论文从四个不同的维度对元学习进行分类:
- Meta-Optimizer —— 对元学习模型进行优化的方法
- 梯度下降法
- 强化学习方法
- 进化算法
- Meta-Representation —— 就是元学习具体要学的东西
- 模型初始化参数
- 网络层数
- 学习率
- ……
- Meta-Objective —— 元学习的具体目标
- Few-Shot Learning 小样本学习
- Fast Learning 快速学习
- Continual Learning 持续学习
- Compression 模型压缩
- Application —— 应用场景
援引文章的一段话:
这就是一个方法库,仿佛引出了一条水 paper 的 pipeline:
- 选择一个 application,构造为meta learning的问题
- 确定 meta-objective
- 选择一个或多个 meta-representation
- 选择一个 meta-optimizer
或者
- 确定 meta-objective
- 选择一个或多个 meta-representation
- 选择一个 meta-optimizer
- 根据以上寻找一个适合的 application
针对每一个类别的 paper 解读,请移步 Daily Paper Reading 仓库。

若有收获,就点个赞吧
0 人点赞
