Java通识基础24——集合类1
Collection综述
集合类的概念——容器类
集合类的对象——容器本身
集合类对象的基本功能——
- 装对象——
add(对象) - 取出对象——
get - 删除对象
- 容器大小
- 查看容器是否为空——
empty - 清空容器——
clear() - 遍历容器
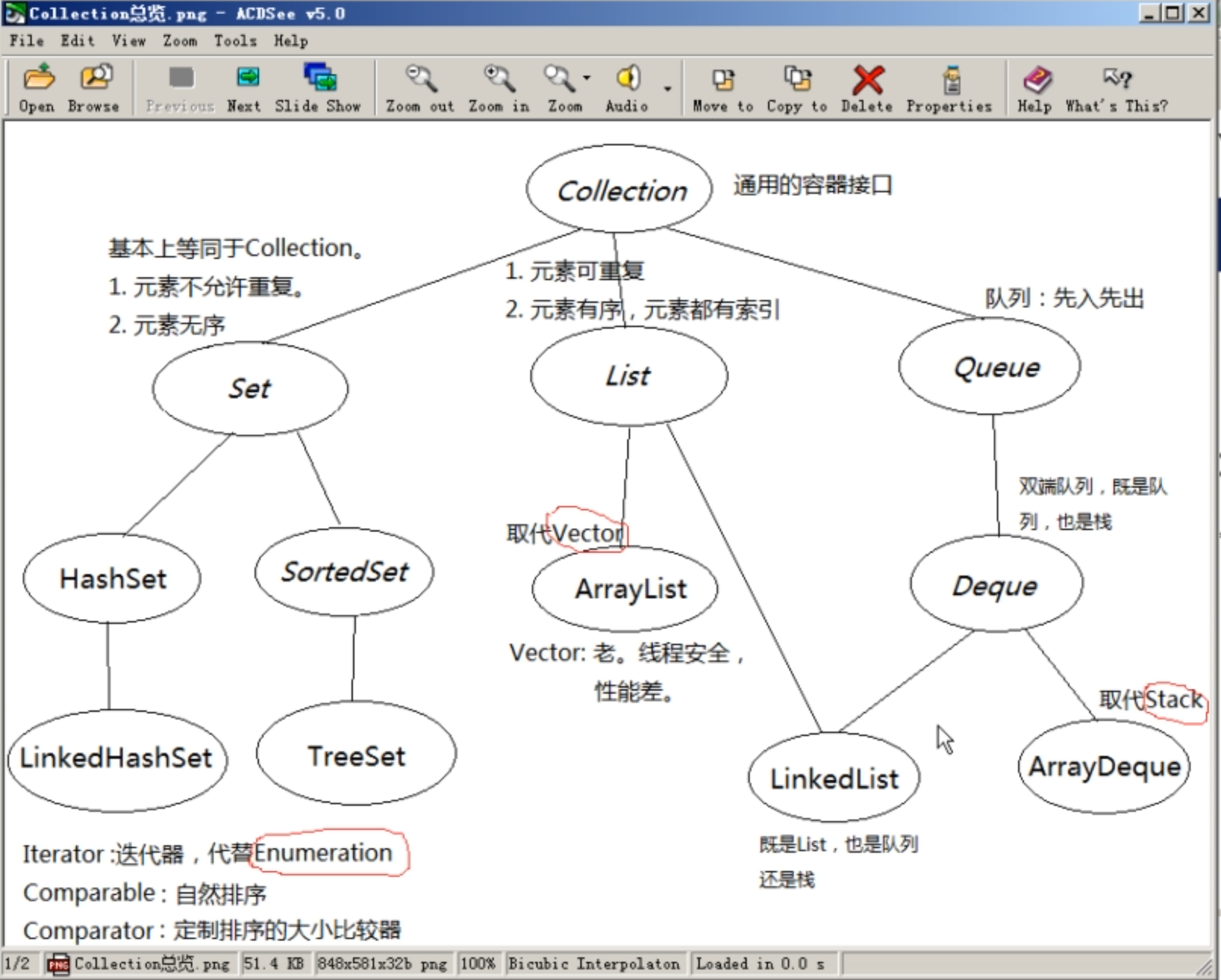
集合的根接口collection
collection的三个子接口
Set子类
- 基本等同于
collection,但是集合元素不允许重复(不能装两个相同的对象) - 集合元素是无序的
- 实现类
HashSet(真正无序)- 子类
LinkedHashSet
- 子类
- 接口
SortedSet(字面意思,有序的Set集合)- 子类
TreeSet
- 子类
- 实现类
List子类(Set的反例)
- 集合元素可以重复
- 元素时有序的,元素都有索引
- 基于数组的实现类
ArrayList - 基于链表的实现类
LinkedList(既是队列,也是栈)
- 基于数组的实现类
Queue子类
- 队列——先入先出(后面将解释)
- 提供子接口
Deque- 该接口的实现类
ArrayDeque - 继承实现类
LinkedList(既是队列,也是栈)
- 该接口的实现类
- 提供子接口
三个基础的数据结构
数据结构介绍
数据结构——栈(Stack)
形象的将栈理解为一个弹夹——后压进去的子弹先被打出来
push(压栈)——将对象压入栈中
pop(弹栈)——让对象从栈中弹出
综上所述,栈遵循先入后出的特征(只有一个出入口)
数据结构——队列(Queue)
可以形象理解为单项轨道,特征是遵循这一个方向
对象先入先出(一个入口一个出口)、
数据结构双端队列(Deque)
既可以作为栈,也可作为队列
有两个口既可以出也可以入
Collection根接口的基本用法和基本方法
import java.util.Collection;import java.util.HashSet;import java.util.Iterator;public class CollectionTest {public static void main(String[] args) {Collection<String> c=new HashSet<String>();//尖括号内叫泛型,限制该集合只能装指定类型的对象Collection<String> c1=new HashSet<>();//菱形语法,功能与上一句相同//该语句实现了向上转型,从HashSet向上转型为Collection//装对象——add(对象)c.add("Date");//上面泛型已经声明只能装Stringc.add("wyd");c.add("lsl");c.add("ggg");System.out.println(c);//取出对象——get//删除对象c.remove("wyd");System.out.println(c);//容器大小System.out.println(c.size());//查看容器是否为空——emptySystem.out.println(c.isEmpty());//遍历容器(集合)for (String g:c){System.out.println(g);}//用foreach循环进行遍历for(Iterator<String> a=c.iterator();a.hasNext();){String st=a.next();System.out.println(st);}//用Iterator遍历器进行遍历Iterator<String> b=c.iterator();while (b.hasNext()){String st=b.next();System.out.println(st);}//用Iterator遍历器进行遍历c.forEach(t-> System.out.println(c));//Lambda表达式遍历//判断是否包含某一个对象System.out.println(c.contains("wyd"));System.out.println(c.contains("lsl"));//清空容器——clear()c.clear();System.out.println(c);}}
Set子接口
HashSet实现类的特征与功能
特征
基本等同于collection,所拥有的方法相同
但增加了两个要求
- 元素不可重复
- 元素无序
- 快速存读数据
最大的特征是速度快——Set最常用的实现类是HashSet
import java.util.*;public class Set {public static void main(String[] args) {HashSet<Integer> sets=new HashSet<>();sets.add(2);sets.add(3);sets.add(6);sets.add(0);sets.add(2);//元素不能重复sets.add(122);System.out.println(sets);}}/*[0, 2, 3, 6, 122]顺序打乱并且不显示重复元素*/
HashSet判断两个元素是否相等
- 两个对象通过
equals比较是否相等 - 两个对象的
HashCode()返回值是否相等
该方法是给HashSet、HashMap等需要Hash算法的程序调用的,作为该对象的标识
hashCode方法
重写原则
- 所有参与
equals比较的field都需要参与HashCode计算 - 计算出每一个
HashCode的值。并且将其累加(乘质数,质数个数取决于变量数量)
重写目的——让equals和hashCode方法一致
import java.util.HashSet;public class SetTest2 {public static void main(String[] args) {HashSet<Cat> m1=new HashSet<>();m1.add(new Cat("black",2.2));m1.add(new Cat("black",2.2));System.out.println(m1);}}class Cat {private String color;private Double weight;public Cat(String color,double weight){this.color=color;this.weight=weight;}public void setColor(String color) {this.color = color;}public void setWeight(double weight) {this.weight = weight;}public double getWeight() {return weight;}public String getColor() {return color;}@Overridepublic String toString(){return "Cat"+this.color+" "+this.weight;}@Overridepublic boolean equals(Object obj){if(this==obj){return true;}if (obj!=null&&obj.getClass()==Cat.class){Cat target=(Cat)obj;return this.color.equals(target.color)&&(this.weight-target.weight)<1e-6;}return false;}@Overridepublic int hashCode(){int prime=31;//定义一个质数return this.color.hashCode()*prime+this.weight.hashCode();//计算出每一个Field的hashCode值并乘质数//这里有两个变量,第一个乘一个质数(一般31)}}/*[Catblack 2.2]此时就保留了一个元素*/
Java系统提供的类只要重写了equals方法,一般也要重写hashCode方法
HashSet的底层实现机制详解
HashSet的底层是基于Hash表(本质是数组)实现的HashSet的方法是基于HashMap实现的
数组,在所有的数据结构中是最迅捷的——
数组变量保存了数组对象的首地址,这样查找很迅速
数组的第i个元素的地址=首地址+i*元素大小注意,此处的i从0开始,避免从1开始有减法参与运算(在计算机中,加法运算永远都比减法运算块),当程序需要取第i个元素的时候,直接根据上式计算出来的地址取值
HashSet存元素的步骤:HashSet会先调用该元素的HashCode(),该方法返回一个int值HashSet会根据元素的HashCode()方法的返回值计算该元素应该保存在HashSet底层数组的什么位置
具体而言就是拿此元素的HashCode方法的返回值对于数组长度取余
比如HashCode值为100,数组长度为8,其余即为4。这个元素将被放在底层数组的第5位HashSet会到底层数组的该位置去检查该位置是否有已有元素- 如果这个位置没有元素,就把新元素存到数组的该位置
- 如果这个位置有元素,就会形成链(旧元素会被新元素从原有的位置挤出去,新元素会给旧元素抛出橄榄枝手牵手形成链条的逻辑模型)
HashSet取元素的步骤:HashSet会先调用该元素的HashCode(),该方法返回一个int值HashSet会根据元素的HashCode()方法的返回值计算该元素应该保存在HashSet底层数组的什么位置HashSet会到底层数组的该位置去检查该位置是否有需要的元素- 如果这个位置确实保存着我们需要找的元素,直接取出该元素即可
- 如果该位置的元素不是我们需要找的元素,需要遍历该位置形成的链逐个去找
链越长,查找的性能越差,而底层数组越大,形成链的概率越小
HashSet的两个性能选项
HashSet(int initialCapacity, float loadFactor)
initialCapacity——初始大小,也就是底层数组的大小,其默认值是16loadFactor——负载因子——当元素个数除以数组长度大于等于负载因子的时候,此时HashSet会将数组长度扩大一倍。比如负载因子是0.5,数组用了一半的时候就会扩展。所以当负载因子越大,数组的利用率越高,形成链的概率越大。反之,数组的利用率越低,形成链的概率越小
默认的负载因子大小为0.75
List接口和ArrayList实现类
特征
- 元素可以重复
- 元素有序,按照添加顺序排列,第一个元素的元素索引为0,第二个元素的元素索引为1…..
由于List的集合元素是有索引(下标)的,因此程序可以根据下标来就行添加。获取,删除
形象的看,List相当于一个竹子容器,每一节只能装一个对象
Set集合支持的方法,List集合也完全支持
import java.util.ArrayList;import java.util.List;public class ListTest {public static void main(String[] args) {List<String> a=new ArrayList<>();a.add("233");a.add("wyd");a.add("wyd");System.out.println(a);//根据索引来添加a.add(1,"gtn");a.add(1,"lsl");//根据索引替换a.set(3,"wt");System.out.println(a);//根据索引获取System.out.println(a.get(3));//根据索引删除a.remove(4);System.out.println(a);//获取元素位置System.out.println(a.indexOf("gtn"));System.out.println(a.indexOf("kkk"));//不存在将返回-1//取出子集List<String> b=a.subList(1,3);//前包后不包System.out.println(b);}}/*[233, wyd, wyd][233, lsl, gtn, wt, wyd]wt[233, lsl, gtn, wt]2-1[lsl, gtn]*/
可以通过下标来遍历集合,原有的三种遍历方式也是可行的
for (int i=0;i<a.size();i++){System.out.println(a.get(i));}
List集合类同样可以在初始化的时候指定底层数组的长度,默认长度为10
Deque接口
代表双端队列——既是栈也是队列
ArrayDeque基于数组实现,性能较好(块!已经代替了stack)
使用场景
栈——
push(元素)pop()peek()获取最顶端的元素但并不弹出
import java.util.ArrayDeque;import java.util.Deque;public class ArrayDequeTest {public static void main(String[] args) {Deque<String> stack=new ArrayDeque<>();stack.push("wyd");stack.push("sff");stack.push("zsj");//压入元素System.out.println(stack);System.out.println(stack.pop());//先压的在下面,先弹最后压进去的“子弹”System.out.println(stack.peek());//显示最上面的元素}}/*[zsj, sff, wyd]zsjsff*/
队列——
offer(元素):入队poll():出队peek():回去队头元素,但不出队
import java.util.ArrayDeque;import java.util.Deque;public class ArrayDequeTest {public static void main(String[] args) {Deque<String> stack=new ArrayDeque<>();stack.offer("wyd");stack.offer("sff");stack.offer("zsj");//压入元素System.out.println(stack);System.out.println(stack.poll());//先压的在下面,先弹最后压进去的“子弹”System.out.println(stack.peek());//显示最上面的元素}}/*[wyd, sff, zsj]wydsff*/
List有的方法Deque同样也有
回顾
根接口——collection
Set子接口——元素内容不可以重复;元素无序
List子接口——元素内容可以重复;元素有序
ArrayList实现类:基于数组实现——性能好LinkedList实现类:功能强大性能差
Queue子接口:队列;特征——FIFO先入先出
Set子接口的子接口——SortedSet
- 实现类
HashSet——基于hash表,快速存取LinkedHashSet子类——额外维护一条链的记住元素的添加顺序
Queue子接口的子接口——Deque,双端队列——既是栈,也是队列
Interator接口——遍历器

若有收获,就点个赞吧
0 人点赞
