Collection接口

迭代器

迭代器一般是内部类 类里维护了
- 当前游标cursor
- 上一个返回游标lastRet
- 预计容量expectedModCount
hasNext 判断游标+1是否超过集合的size next 校验后 返回cursor++位置的元素 并把lastRet设为cursor remove 校验后 删除lastRet位置的元素 并把cursor设为lastRet lastRet设为-1 forEachRemaining 校验后 把从游标开始到剩余容量的元素遍历并执行消费者方法
由此可见 调用remove前必须调用next
Collection实现了Iterable 所以子类都有iterator和foreach的方法
Iterator<String> iterator = list.iterator();while (iterator.hasNext()){String next = iterator.next();if("".equals(next)){iterator.remove();}System.out.println(next);}
集合中的接口
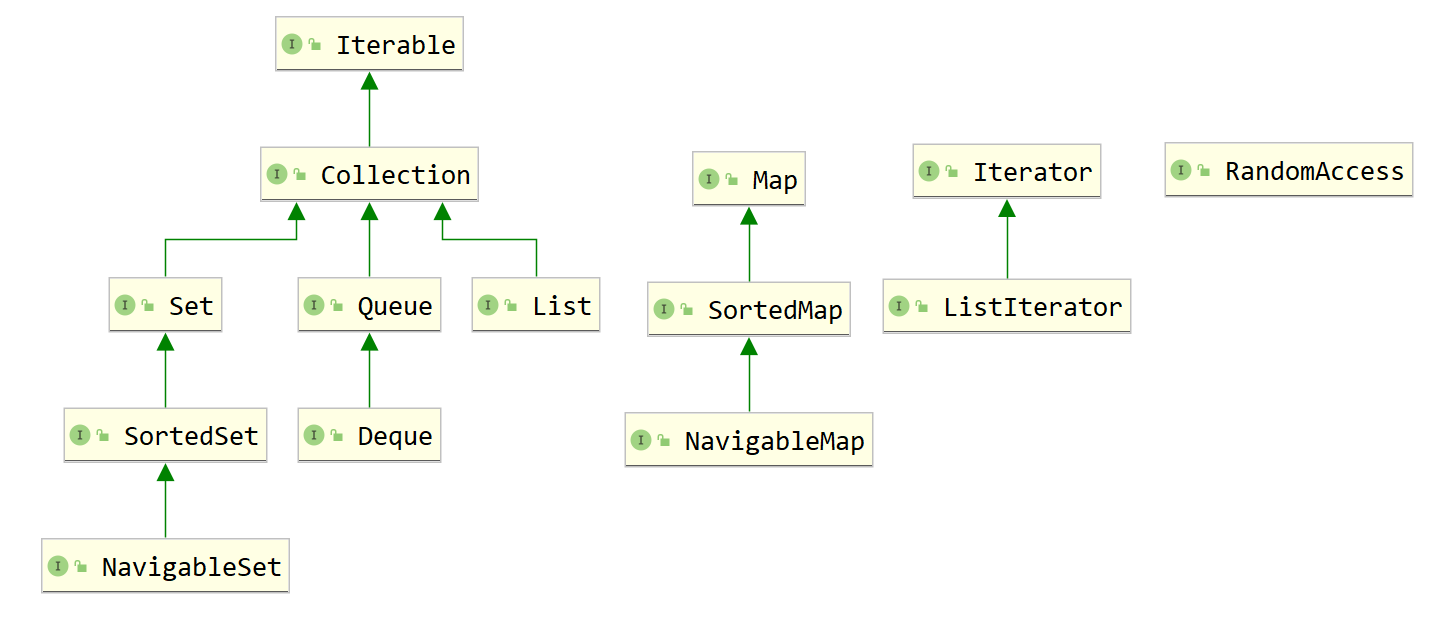
RandomAccess没有方法 用于判断而已 例如ArrayList实现了随机访问接口 提供了get(int index)方法
if (collection instanceof RandomAccess){collection.get(i);}
ListIterator
- 可向前遍历
- 在当前元素前添加元素 add
- 改变当前元素 set
Set 不允许重复 所以Set的元素最好重写equals和hashCode方法 equals方法保证判断是不重复 hashCode方法保证散列码不重复 相同元素处于相同位置
SortedSet 和 SortedMap 会排序 TreeSet 和 TreeMap实现了该接口
具体展示
- ArrayList 高效查询的索引序列
- LinkedList 高效插入删除的有序序列
- ArrayDeque 循环数组的双端队列
- HashSet 无重复的集合
- TreeSet 有序的Set
- EnumSet 包含枚举的Set
- LinkedHashSet 可以记住插入次序的Set
- PriorityQueue 可以高效删除最小元素的集合
- HashMap 键值对
- TreeMap 有序键值对
- EnumMap 枚举键值对
- LinkedHashMap 记录插入顺序的键值对
- WeakHashMap 没被强引用的键值对会被回收
- IdentityHashMap 键值用==而不是equals比较
链表
链表插入删除效率高 Java语言中所有链表都是双向的 LinkedList 书上都是基础 好像没什么记录的
数组列表
随机获取比较方便 ArrayList 书上都是基础 也没什么记录的
散列表 Hash
散列表用 数组-链表 实现 链表称为桶(bucket)数组个数就是桶子个数 元素存放时先计算hash值 再取余桶子的个数 最终得到数组索引 最终以链表的形式插入索引对于的数组 其中需要遍历链表 有相同元素就替换插入 处于相同链表称为hash冲突 jdk8以后当桶满时会将链表变为平衡二叉树 降低访问层数 提高效率 HashMap 默认桶数为16 桶容量为8 填装因子为 0.75 即当桶子内元素大于8 就是用平衡二叉树代替 当75%的桶子都填满了 就会创建新表来替换
树集 TreeSet
利用红黑树达到有序的效果 元素必须可比较
队列与双端队列
queue add remove 失败抛异常 offer poll 失败返回false null element peek 第一个失败抛异常 第二个返回null Deque 基本同上
优先队列
有优先级的队列 每次返回队列中最小的 运算需要可排序 利益了堆的数据结构
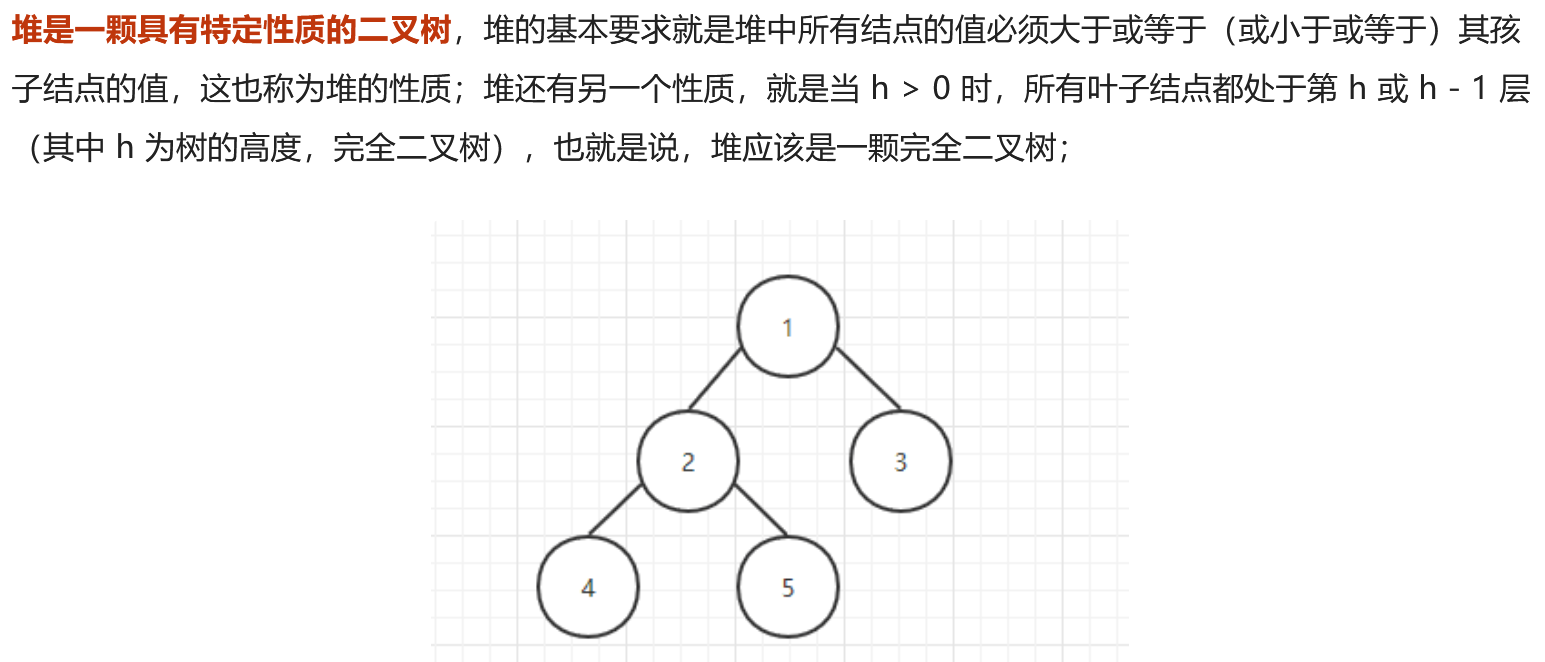
PriorityQueue<Integer> queue = new PriorityQueue<>();queue.add(5);queue.add(2);queue.add(11);while (!queue.isEmpty()){System.out.println(queue.remove());}// 2 5 11
Map
键值对 根据键来区分
map.forEach((k, v) -> {System.out.println("键:" + k + " 值:" + v);});
getOrDefault 防止第一个获取没结果导致的空指针异常 putIfAbsent 跟redis的setnx差不多
map.put("key",map.getOrDefault("key", 0)+1);map.putIfAbsent("key",0);
键集 值集 键值集
一般用键值集
Set<String> keySet = map.keySet();Collection<Integer> values = map.values();Set<Map.Entry<String, Integer>> entries = map.entrySet();for (Map.Entry<String, Integer> entry : entries) {if ("key".equals(entry.getKey())){System.out.println(entry.getValue());}}
WeakHashMap
弱引用Map 当键的值不再被除Map以外的对象引用 就可以被回收 如果是普通的Map 键不再被栈中的对象引用(无价值了) 但是Map还引用他 所以不会被回收 会导致内存渗透
LinkedHashSet 和 LinkedHashMap
能记住插入顺序 原理如下:
键集 值集 键值集遍历的结果是和插入顺序一样的 可以设置按照访问顺序存放而不是插入顺序 : new LinkedHashMap<>(16,0.75f,true);
//设置按访问顺序返回//缓存 最大存100个 多了就删除最早的Map<String, Integer> map =new LinkedHashMap<>(16, 0.75f, true);Set<String> set = map.keySet();if (set.size() > 100) {int size = set.size();Iterator<String> iterator = set.iterator();for (int i = 0; i < size - 100; i++) {String key = iterator.next();iterator.remove();}}//自动设置就重写removeEldestEntry方法
EnumSet 和 EnumMap
EnumSet 和 EnumMap 十分高效 用位来存放枚举类型
enum Weekday {MONDAY,TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY}EnumSet<Weekday> all = EnumSet.allOf(Weekday.class);EnumSet<Weekday> never = EnumSet.noneOf(Weekday.class);EnumSet<Weekday> range = EnumSet.range(Weekday.TUESDAY,Weekday.SUNDAY);EnumSet<Weekday> some = EnumSet.of(Weekday.SUNDAY,Weekday.SATURDAY);EnumMap<Weekday,Student> map =new EnumMap<Weekday, Student>(Weekday.class);map.put(Weekday.SUNDAY,new Student("小明"));map.put(Weekday.WEDNESDAY,new Student("小红"));
IdentityHashMap
调用的是== 而不是equals 意思是只要内存地址不相等 哪怕数据一模一样也算两个键
IdentityHashMap<Student,Object> map =new IdentityHashMap<>();
视图与包装类
视图:通过集合获取的新集合 但操作的是原来的集合对象
子范围视图
List : List
subList = list.subList(2, 5);//包左不包右 subList.clear(); //此时操作的是原来视图 有序Set: SortedSet subSet = set.subSet(2, 3); SortedSet headSet = set.headSet(2); SortedSet tailSet = set.tailSet(2); 有序Map: SortedMap subMap = map.subMap(2, 3); SortedMap headMap = map.headMap(2); SortedMap tailMap = map.tailMap(2);
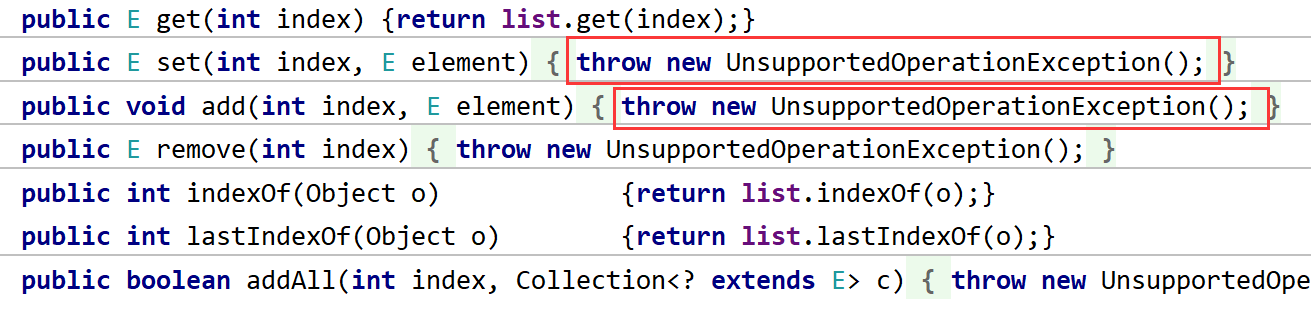
不可修改视图
//其他集合同理List<Integer> unmodifiableList =Collections.unmodifiableList(list);List<Integer> subList = unmodifiableList.subList(0, 2);subList.clear();
unmodifiable方法本质上是返回了一个Collections的内部类 这个类对修改操作进行了包装
同步视图
同步视图同理 对增删改差加入了锁机制 具体间十二章
List<Integer> list = Collections.synchronizedList(list);
算法
泛型算法
封装方法时尽量用泛型 这样更通用 例如用Collection 而不是 ArrayList 并且善于使用 Iterator
public static <T extends Comparable> T max(Collection<T> c){if (c == null || c.isEmpty())throw new NoSuchElementException();Iterator<T> iterator = c.iterator();T max = iterator.next();while (iterator.hasNext()){T next = iterator.next();if (next.compareTo(max) > 0){max = next;}}return max;}
排序与打乱
Collections.sort(list); Collections.shuffle(list);
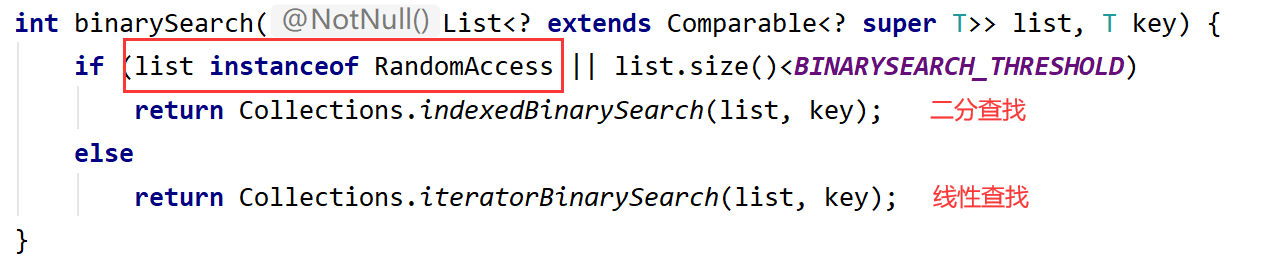
二分查找
1.有序的集合才能二分查找 不然结果是错的 2.可随机访问的二分查找才有意义
Collections.binarySearch(list, 2); 返回元素索引
如果 i > 0 则是找到了 i < 0 则在 -i-1 位置插入元素可以保证元素有序因此 插入元素并且保证集合有序的代码
int i = Collections.binarySearch(list, 2);if (i > 0){list.add(i, x);}else {list.add(-i-1, x);}
当查找的集合不支持随机访问 则二分查找退化成线性查找
批操作
list.removeAll(list2); 补集 list.retainAll(list2);交集 list.addAll(list2);全部添加 重复的会保留
集合与数组

遗留的集合
Vector 线程安全 被List取代 Enumeration 名字太长 被Iterator取代
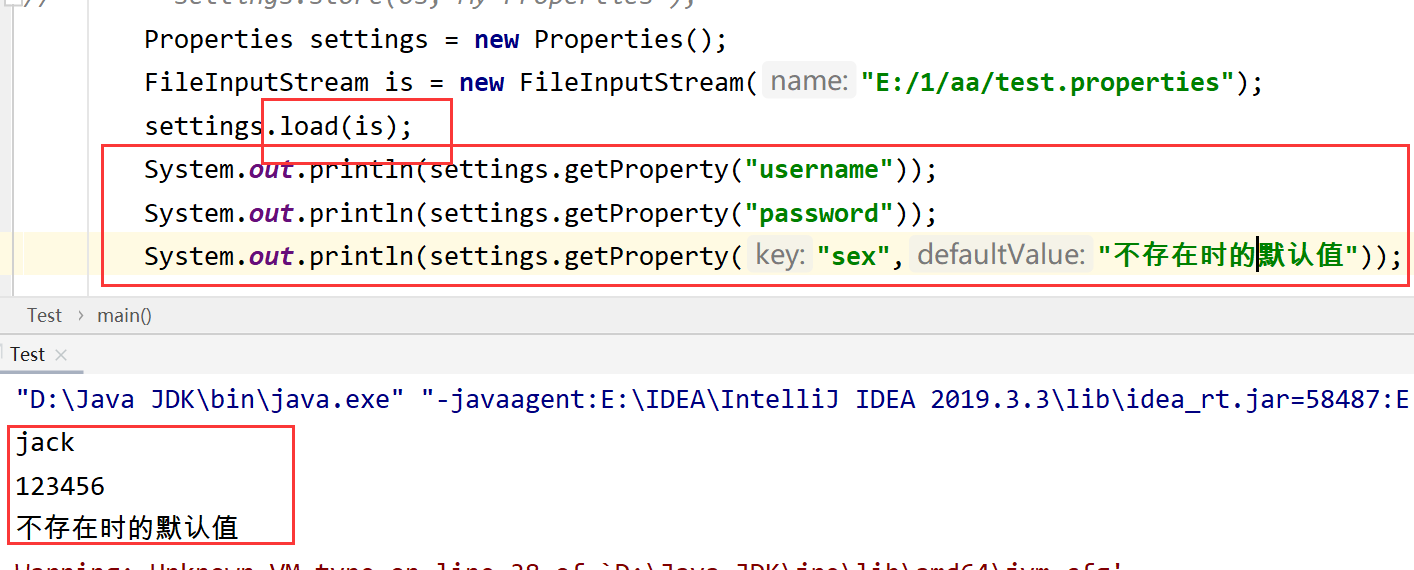
属性文件
键值对都是字符串的时候可以用
读取
store load

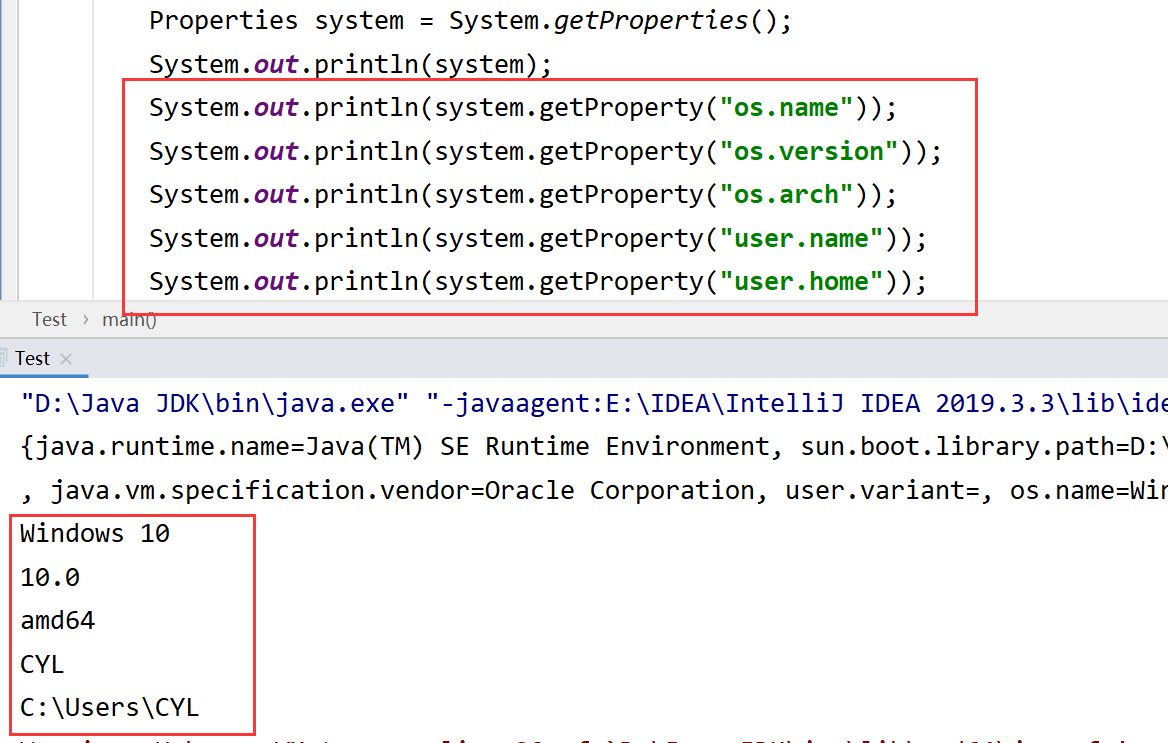
系统配置
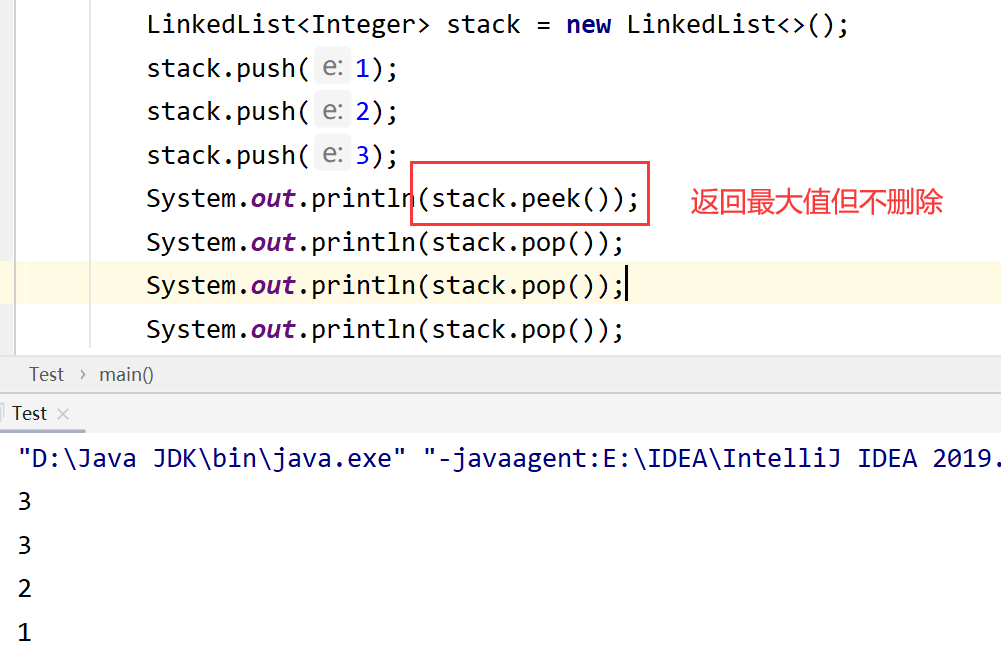
栈
先进后出 一般用LinkedList来做

若有收获,就点个赞吧
0 人点赞
