MVCC多版本并发控制机制
Mysql在可重复读隔离级别下如何保证事务较高的隔离性,同样的sql查询语句在一个事务里多次执行查询结果相同,就算其它事务对数据有修改也不会影响当前事务sql语句的查询结果。隔离性就是靠MVCC(**Multi-Version Concurrency Control 多版本并发控制**)机制来保证的,对一行数据的读和写两个操作默认是不会通过加锁互斥来保证隔离性,避免了频繁加锁互斥。<br /> 而在串行化隔离级别为了保证较高的隔离性是通过将所有操作加锁互斥来实现的。<br /> **Mysql在读已提交和可重复读隔离级别下都实现了MVCC机制。**
undo日志版本链与read view机制详解
undo日志版本链是指一行数据被多个事务依次修改过后,在每个事务修改完后,Mysql会保留修改前的数据undo回滚日志,并且用两个隐藏字段trx_id和roll_pointer把这些undo日志串联起来形成一个历史记录版本链(见下图,需参考视频里的例子理解)<br /> MySQL存储行数据的时候还会为其分配trx_id和roll_pointer,图中最下面的是最老的也是最开始时候的数据,每一次修改都将trx_id写入并且将roll_pointer指向上一次的老版本。roll_pointer指向的是老的版本存放的位置。<br />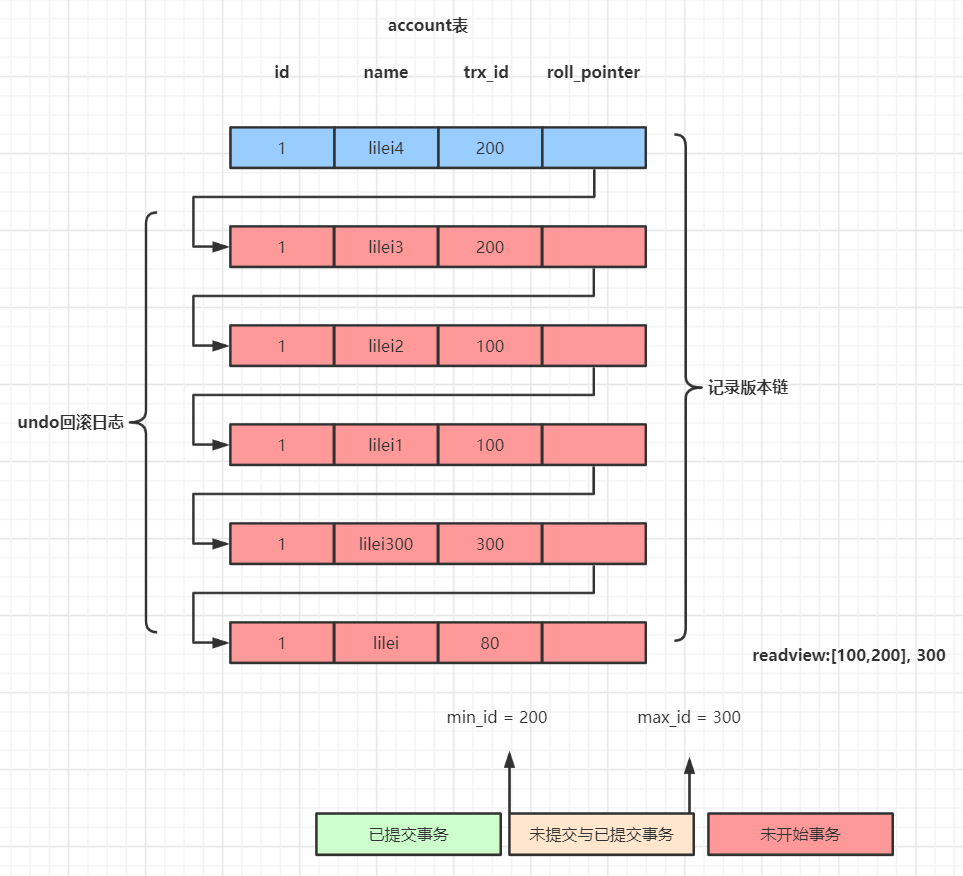
read-view
read-view图解(图太长,放在最后)
# 事务A
begin;
update account
set name = 'lilei300' where id = 1;
commit;
end;
# 事务B
begin;
select name
from account where id = 1;
commit;
end;
上面两个语句,假设现在id = 1对应的name = lilei。如果都先执行begin,但是事务B没有执行查询,事务A在事务B查询之前先修改并且提交。这时事务B已经开始,但是什么都没做,如果在事务A提交后再查询,得出的结果是最开始的lilei,还是事务A修改提交后的lilei300?看起来由于可重复读级别的隔离性,既然事务B是在事务A执行update之前开启的,虽然没有进行查询,那也应该遵守可重复读的特性,查出的结果应该是最开始的lilei。但是答案是lilei300,其原因是read-view。<br /> 查询时会把undo日志版本链与read-view进行比对,按照一定的规则将数据返回展示。会从undo日志的最新的数据开始查找,决定当前事务应该读取什么数据<br /> 在**可重复读隔离级别**,当事务开启,**执行任何查询sql**时会生成当前事务的**一致性视图read-view,如果事务执行期间没有修改行为,**该视图在事务结束之前都不会变化,**否则会重新生成**(**如果是读已提交隔离级别在每次执行查询sql时都会重新生成**)。read-view是在事务有查询InnoDB表的时候生成,但不特别绑定查询的表。例如下面的语句,前两行查询film表,account表 没有修改。在第4行其他事务修改account,然后在当前事物查询,查询到的不是修改后的值,而是开始的值。原因就是在查询film的时候read-view已经生成。
begin;
select * from film where id = 1;
# 在此处修改了account
select * from account where id =1;
commit;
end;
在读已提交级别,由于每次查询时read-view都会重新生成,因此读已提交级别有可能读到其他事务修改后提交的数据。<br />** 这个视图由执行查询时所有未提交事务id数组(数组里最小的id为min_id)和已创建的最大事务id(max_id)组成**,事务里的任何sql查询结果需要从对应版本链里的最新数据开始逐条跟read-view做比对从而得到最终的快照结果。关于这个最大事务id可能下面的定义是正确的,他应该是要分配给下一个事务的最大id而不是已生成的最大的事务id。<br /> 对于使用**READ COMMITTED和REPEATABLE READ**隔离级别的事务来说,都**必须保证读到已经提交了的事务修改过的记录**,也就是说假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的,核心问题就是:需要判断一下版本链中的哪个版本是当前事务可见的。为此,设计InnoDB的大叔提出了一个ReadView的概念,这个ReadView中主要包含4个比较重要的内容:
- m_ids:表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。
- min_trx_id:表示在生成ReadView时当前系统中活跃的读写事务中最小的事务id,也就是m_ids中的最小值。
max_trx_id:表示生成ReadView时系统中应该分配给下一个事务的id值。
注意:max_trx_id并不是m_ids中的最大值,事务id是递增分配的。比方说现在有id为1,2,3这三个事务,之后id为3的事务提交了。那么一个新的读事务在生成ReadView时,m_ids就包括1和2,min_trx_id的值就是1,max_trx_id的值就是4。creator_trx_id:表示生成该ReadView的事务的事务id。
前边说过,只有在对表中的记录做改动时(执行INSERT、DELETE、UPDATE这些语句时)才会为事务分配事务id,否则在一个只读事务中的事务id值都默认为0。
版本链比对规则: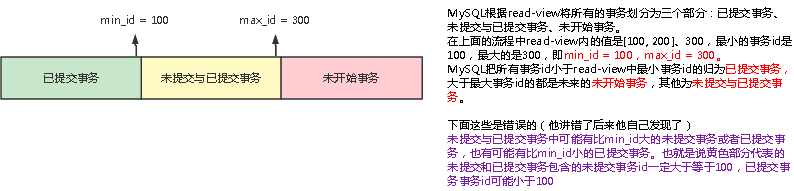
1. 如果 row 的 trx_id 落在绿色部分( trx_id
3. 如果 row 的 trx_id 落在黄色部分(min_id <=trx_id<= max_id),那就包括两种情况
a. 若 row 的 trx_id 在视图数组(由所有未提交事务组成,不包括最大事务id)中,表示这个版本是由还没提交的事务生成的,不可见(若 row 的 trx_id 就是当前自己的事务是可见的);
b. 若 row 的 trx_id 不在视图数组(由所有未提交事务组成,不包括最大事务id)中,表示这个版本是已经提交了的事务生成的,可见。
对于删除的情况可以认为是update的特殊情况,会将版本链上最新的数据复制一份,然后将trx_id修改成删除操作的trx_id,同时在该条记录的头信息(record header)里的(deleted_flag)标记位写上true,来表示当前记录已经被删除,在查询时按照上面的规则查到对应的记录如果delete_flag标记位为true,意味着记录已被删除,则不返回数据。
注意:begin/start transaction 命令并不是一个事务的起点(不会生成真正的事务id,而是生成一个虚拟的事务id,虚拟的id没什么用)。在执行到它们之后的第一个修改操作InnoDB表的语句(增删改操作),事务才真正启动,才会向mysql申请事务id,mysql内部是严格按照事务的启动顺序来分配事务id的。两个事务之间没有其他事务那么他们的事务id应该是连续的。下面的MVCC机制举例中事务id不连续是为了区分度更高。
总结:
事务中如果前面没有修改,那么第一次查询的值肯定是数据库中的真正的值
MVCC机制的实现就是通过read-view机制与undo版本链比对机制,使得不同的事务会根据数据版本链对比规则读取同一条数据在版本链上的不同版本数据。
MVCC机制举例.xlsx
Innodb引擎SQL执行的BufferPool缓存机制
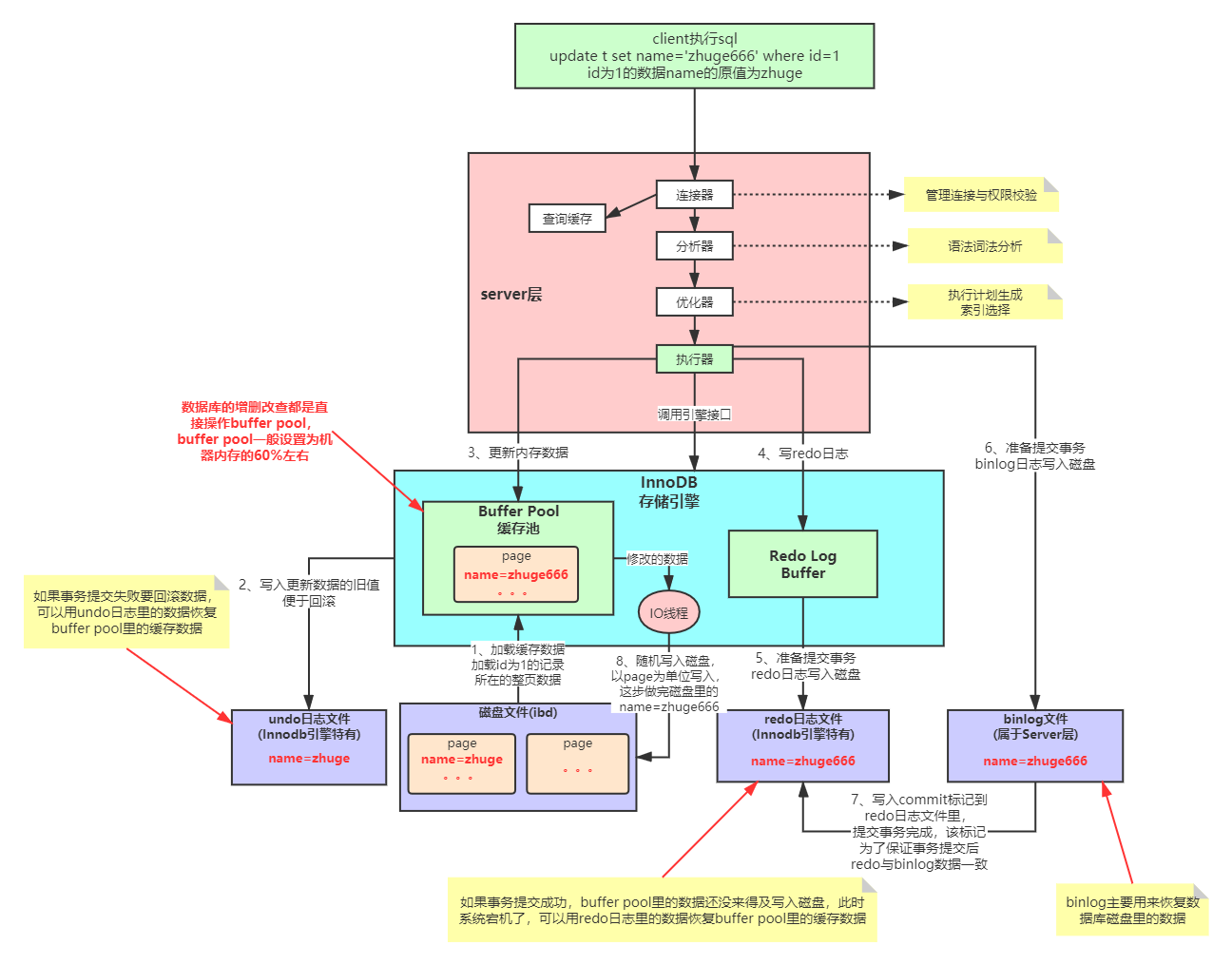
1、MySQL把要修改的数据所在的整个页从磁盘加载到Buffer Pool缓存
2、将旧数据写入undo log用于回滚
3、将数据更新到Buffer Pool
4、写入redo log buffer
5、事务提交前redo log buffer中的redo log写入磁盘,写入的方式可能是批量写入或者到一定的数量会去写
6、写入bin log,bin log是server层的,server层对所有存储引擎共享,也就是说所有存储引擎都有这一步。
7、bin log写入完成会向redo log中写入commit标记,然后提交事务
写入commit是为了保证bin log和redo log的内容一致
8、Buffer Pool中的数据以页为单位随机写入磁盘
MySQL(至少是InnDB)的增删改查都是根据Buffer Pool来操作的,他们操作的都是Buffer Pool。这样数据是没有问题的,因为无论何种操作都会先存到Buffer Pool,即使其他事务可能修改了当前事务需要的数据但是磁盘上的数据可能还是老的数据,当前事务会从Buffer Pool读取。
为什么Mysql不能直接更新磁盘上的数据而且设置这么一套复杂的机制来执行SQL?
- 因为来一个请求就直接对磁盘文件进行随机读写,然后更新磁盘文件里的数据性能可能相当差。
- 因为磁盘随机读写的性能是非常差的,所以直接更新磁盘文件是不能让数据库抗住很高并发的。
- Mysql这套机制看起来复杂,但它可以保证每个更新请求都是更新内存BufferPool,然后顺序写日志文件,同时还能保证各种异常情况下的数据一致性。
更新内存的性能是极高的,然后顺序写磁盘上的日志文件的性能也是非常高的,要远高于随机读写磁盘文件
正是通过这套机制,才能让我们的MySQL数据库在较高配置的机器上每秒可以抗下几干甚至上万的读写请求。<br /> 这种机制下,binlog是server层所有存储引擎都要写,undo日志也勉强可以说都需要维护,但是redo日志则可以说是额外需要写的了,为什么不用更方便的写入磁盘?<br /> 因为先写入redo日志文件是顺序IO,而如果直接写磁盘就是随机IO,后者效率远小于前者。如果来一条就写一下磁盘效率将非常低。
read-view图解

若有收获,就点个赞吧
0 人点赞
