Java集合框架总结
推荐相关文章
Java集合框架图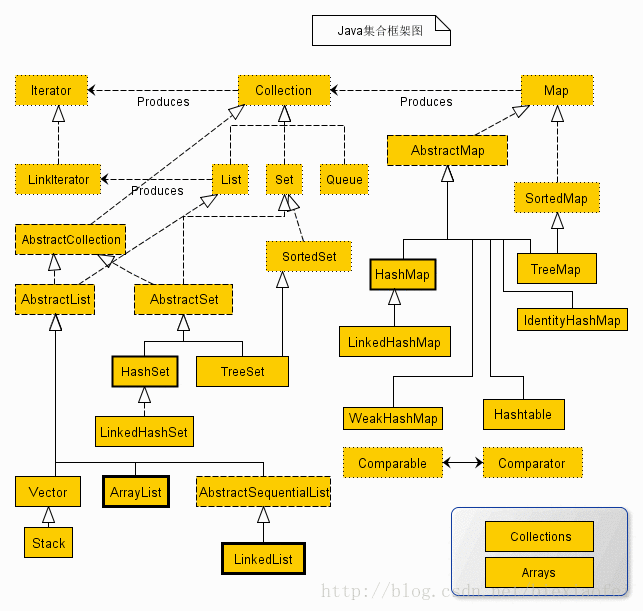
Collection
ArrayList
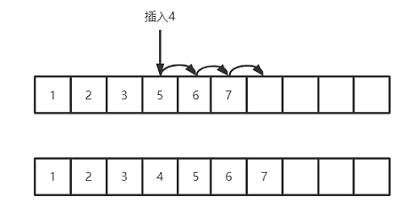
ArrayList 基于数组实现,访问快,插入慢。
ArrayList 默认容量为10,每次扩容至少为原来的1.5倍。只有在第一次添加元素的时候,ArrayList才会扩容默认容量10,之后满了才会扩容。
ArrayList 增删操作会先通过index找到这个位置(时间复杂度O(1)),然后添加或删除,后面的元素需要向前/后移动一位(时间复杂度O(n))
线程不安全。
可以存储null值。
LinkedList
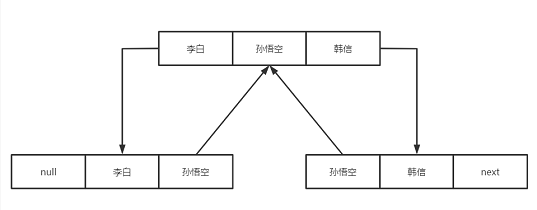
LinkedList 是一个双向链表,插入删除快,访问慢。
LinkedList 没有初始容量,也没有扩容机制,添加就在前后加就行了。
(一个Node为一个元素,Node包含头节点,数据,尾节点)
线程不安全。
可以存储null值。
问:在内存空间占用度来说,哪个更占用内存?
一般情况来说 LinkedList一个元素包含两个节点信息,一个数据,更占内存。当超过LinkedList和ArrayList的临界值时,ArrayList的扩容机制浪费原来数组一半的内存空间,会更浪费内存。但ArrayList的数组变量用了transient修饰,需要序列化的时候这部分多余的空间不会被序列化。
ArrayList基于数组,是可以随机存取的。而链表是顺序存取,需要遍历才能找到。
Vector
Vector 也是基于数组实现,内部加了很多synchronized(所以被弃用了)是线程安全的。Vector 初始容量为10,不足时扩容为原来的2倍。
线程安全。
可以存储null值。
问:Vector和ArryList的区别是什么?
1. 线程的区别,ArrayList是线程不安全,Vector线程安全。
2. 扩容的区别,ArrayList扩容每次为原来的1.5倍,而Vector默认扩容2倍。
Queue 一般都是先进先出的,应用场景及框架选型:
实现 [ 普通队列-先进先出 ] 就用 LinkedList 或 ArrayDeque 来实现。
实现 [ 优先队列 ] 就用 PriorityQueue。
实现 [ 栈 ] (后进先出)就用 ArrayDeque。
Queue 接口实现定义了两组API功能相同,一组抛异常,一组返回特殊值。
ArrayDeque
ArrayDeque 是双向队列基于数组,初始容量为16,每次扩容2倍。JDK1.6版本才有此框架。
ArrayDeque 可以当队列(先进先出),可以当栈使用(后进先出)。
(指定容量若不是2的n次方数值,则自动取数值最近的2的n次方数值。)
线程不安全。
不能存储null值,会报空指针异常。
问:ArrayDeque 和 LinkedList的区别?
1. ArrayDeque 是双向数组,LinkedList 是链表结构。
2. ArrayDeque 不能存null值,LinkedList 可以。
3. ArrayDeque 操作头尾端的增删操作时更高效(移动的元素少),但 LinkedList 是要移除中间某个元素才是O(1)
4. ArrayDeque 一般情况下内存占用更少,更高效。
Stack
栈,继承Vector,后进先出的线性结构,官方明确不让用了。
接水问题,最优解是双指针,最直观解法可以用栈。想实现 Stack 语义,可用 ArrayDeque 实现。
HashSet
HashSet 底层是一个 HashMap,采用 HashMap 的key来存储元素,HashMap的key是不可重复的,所以HashSet的值就是不重复的,是无序的。
基本操作都是O(1)时间复杂度,很快很高效。
初始容量16,加载因子0.75(元素个数超过容量的0.75倍开始扩容),每次扩容原来的2倍。
线程不安全。
可以存null值。
LinkedHashSet
LinkedHashSet 实现基于HashSet + LinkedList。
拥有O(1)的时间复杂度和保证插入顺序。
初始容量16,加载因子0.75,每次扩容原来的2倍。
线程不安全。
可以存null值。
TreeSet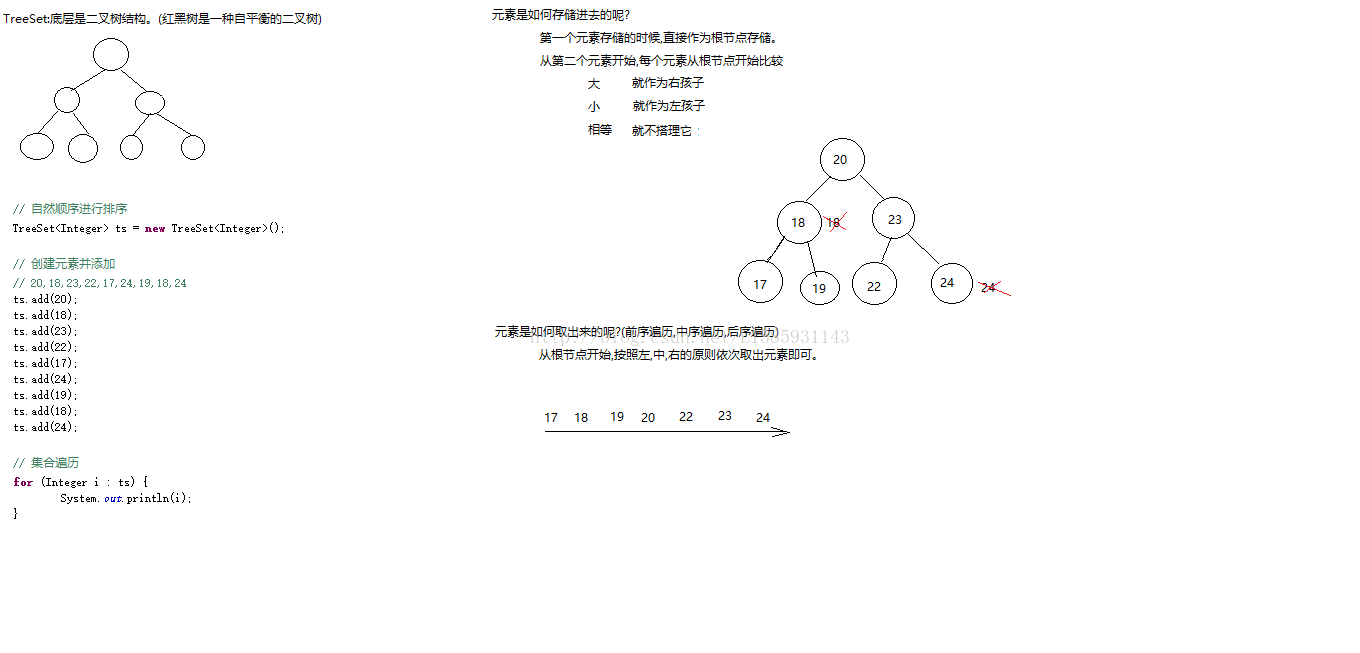
TreeSet 采用红黑树结构,基于TreeMap,特点是可以有序,可以自然排序,可以自定义比较器来排序,缺点是查询比HashSet慢。
初始容量16,加载因子0.75,每次扩容原来的2倍。
线程不安全。
可以存null值。
Map
HashMap
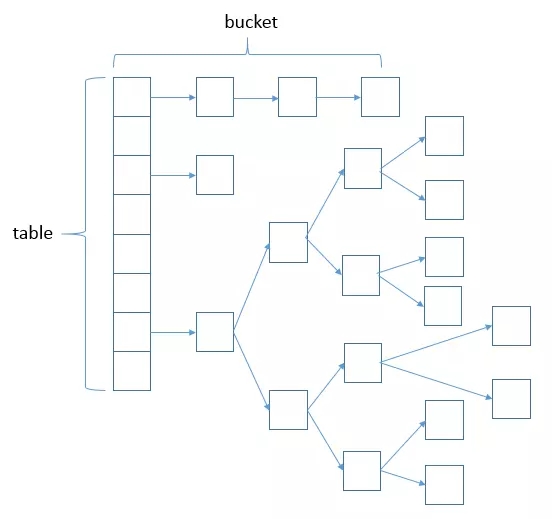
HashMap 在JDK1.8版本之前是基于数组 + 链表的数据结构,链表元素的插入是用的头插法,这样存在死链问题。
而 JDK1.8版本开始,底层是基于数组+链表+红黑树的结构,改为尾插法,链表长度小于等于6时使用的是链表结构,大于8使用的是红黑树结构。
初始容量16,扩容因子0.75,每次扩容2倍。
可以存null。
问:HashMap的Key是怎么保证唯一的?
HashMap在存数据的时候,会对存入的key进行hash值的比较,相同则重复不存储,不相同则调equals()方法判断是否相等。因为基本数据类型没有hashcode()和equals()方法,所以key不支持基本数据类型。
1.7 -> 1.8 主要三点优化:
1. 数组+链表改为数组+链表+红黑树,防止hash冲突,链表长度过长,时间复杂度O(n)降O(logn)
2. 链表插入方式从头插改尾插,规避了死链问题。
3. 扩容时1.7需要对原数组元素重新hash定位新数组位置,1.8用简单的判断逻辑,位置不变或索引+旧容量大小。
4. 插入时,1.7先判断,在插入,1.8先插入再判断是否扩容。
HashMap put的时候,1. 首先看table数组是否为null或未在内存分配空间,是就初始化resize一下。2. 再判断hash值数组中位置是否为空,空就在此位置新建一个Node节点插入数组。
3.此位置不为空,判断此位置Node节点元素和插入元素是否相同。4.不相同,且当前节点已在TreeNode,就用红黑树方式存储。5.不相同,也不在TreeNode节点,就存链表。
LinkedHashMap
TreeMap
HashTable
ConCurrentHashMap
补充说明
- Map不是集合,但整合在集合中。

若有收获,就点个赞吧
0 人点赞
