


总结
一、Pandas库
import numpy as npimport pandas as pd
二、Pandas库数据结构——Series, DataFrame
a = pd.Series([1, 2, 3, 4, 5])
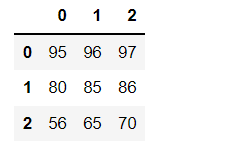
data = np.array([[95, 96, 97], [80, 85, 86], [56, 65, 70]])frame = pd.DataFrame(data)frame
1.Series——索引 index,值 values
a = pd.Series([1, 2, 3, 4, 5], index = ['a', 'b', 'c', 'd', 'e'])a
2.DataFrame——索引index, columns,值 values
frame = pd.DataFrame(data, index=['xiaoming', 'xiaohong', 'xiaohei'],columns=['yuwen', 'yingyu', 'shuxue'])frame
指定或修改索引方法
创建时:
index, columns 指定索引,已经有索引可以按索引重新排序
创建后:
reindex方法,重新建立索引或指定索引排序
rename 修改索引
frame_.rename(index={"xiaohong":"damao","xiaoming":"ermao","xiaohei":"Nicolas Cage"},columns={"yingyu":"English", "yuwen":"Literature", "shuxue":"Maths"})
Series.index = []
DataFrame.columns = []
三、Series, DataFrame运算
1.基本运算
按照索引位置进行计算
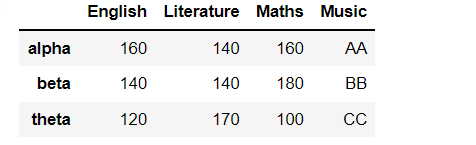
data = {"English":[80,70,60],"Literature":[70,70,85],"Maths":[80,90,50],"Music":["A","B","C"]}df = pd.DataFrame(data,index = ["alpha", "beta","theta"])df * 2
DataFrame、Series “相加”时,按照DF的columns(列)进行匹配
data1 = {"English":[80,70,60],"Literature":[70,70,85],"Maths":[80,90,50],}df1 = pd.DataFrame(data1,index = ["alpha", "beta","theta"])add_ = {'Maths':10,'English':10,'Literature':20,'Gym':"A"}add_ = pd.Series(add_)df1 + add_

2.矩阵运算、通用函数
df.T

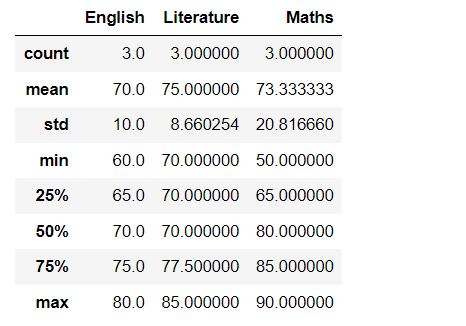
3.基本统计方法 axis指定操作轴
df.describe()
四、Series, DataFrame 索引与切片
1.Series 索引与切片 Index索引/数字索引/布尔值索引
add_ = {'Maths':10,'English':10,'Literature':20,'Gym':"A"}add_ = pd.Series(add_)add_['Maths']

2.DataFrame 索引与切片
Index索引 列:df['Maths'] 行:df.loc[‘alpha’]数字索引 df.iloc[] 特别的行可以直接用数字切片索引布尔值索引
五、Series, DataFrame 删除操作
1.Series删除操作 pop/drop/del
2.DataFrame删除操作 pop/drop/del
六、Series, DataFrame 合并操作
1.Series合并操作
pd.concat() combine_first()
2.DataFrame合并操作
pd.concat() combine_first()pd.merge() join()
七、Pandas库其他常用函数或方法
head() info() describe()sort_index() sort_values()is_unique value_counts()rank()

若有收获,就点个赞吧
0 人点赞
