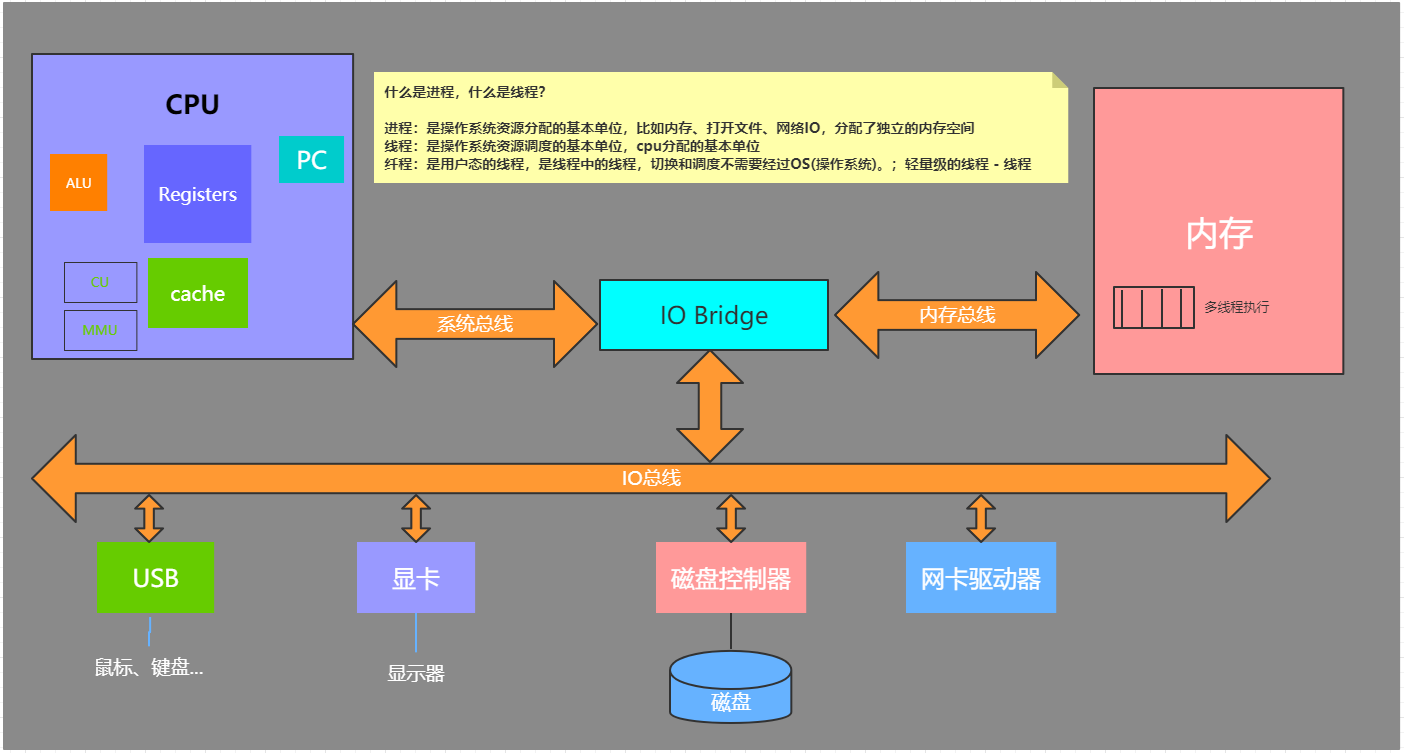
一些重要的概念
进程,线程,协程,纤程,子例程,管程
- 进程:是操作系统资源分配的基本单位,比如内存、打开文件、网络IO、分配了独立内存空间
- 线程:是操作系统资源调度的基本单位,CPU分配的基本单位
- 纤程:是用户态的线程,是线程中的线程,切换和调度不需要经过OS(操作系统)
- 协程:执行过程更类似于子例程,或者说不带返回值的
- 子例程:子例程是某个主程序的一部分代码,该代码执行特定的任务并且与主程序中的其他代码相对独立,子例程又被称为子程序、过程、方法、函数等
- 管程:管程是由局部于自己的若干公共变量及其说明和所有访问这些公共变量的过程所组成的软件模块
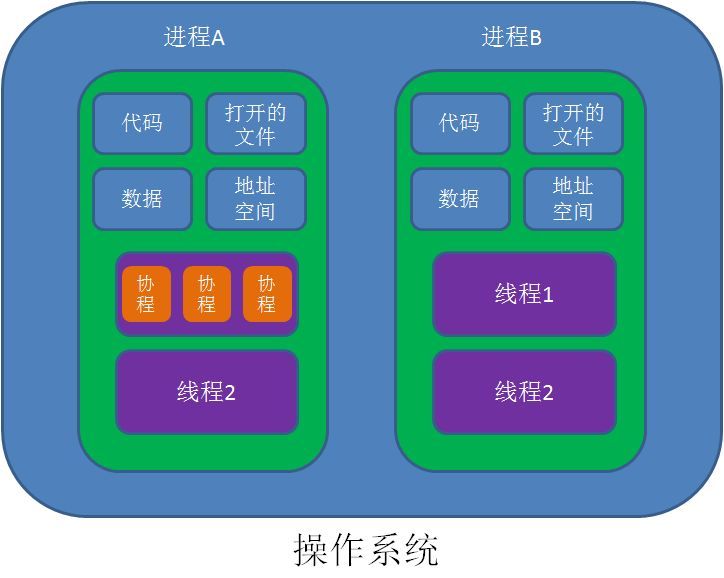
进程,线程,协程对比
- 协程既不是进程也不是线程,协程仅仅是一个特殊的函数,协程它进程和进程不是一个维度的
- 一个进程可以包含多个线程,一个线程可以包含多个协程
- 一个线程内的多个协程虽然可以切换,但是多个协程是串行执行的,只能在一个线程内运行,没法利用CPU多核能力。
- 协程与进程一样,切换是存在上下文切换问题的
- 进程的切换者是操作系统,切换时机是根据操作系统自己的切换策略,用户是无感知的。进程的切换内容包括页全局目录、内核栈、硬件上下文,切换内容保存在内存中。进程切换过程是由“用户态到内核态到用户态”的方式,切换效率低
- 线程的切换者是操作系统,切换时机是根据操作系统自己的切换策略,用户无感知。线程的切换内容包括内核栈和硬件上下文。线程切换内容保存在内核栈中。线程切换过程是由“用户态到内核态到用户态”, 切换效率中等
- 协程的切换者是用户(编程者或应用程序),切换时机是用户自己的程序所决定的。协程的切换内容是硬件上下文,切换内存保存在用户自己的变量(用户栈或堆)中。协程的切换过程只有用户态,即没有陷入内核态,因此切换效率高
进程
进程是系统进行资源分配和调度的一个独立单位,程序段、数据段、PCB三部分组成了进程实体(进程映像),PCB是进程存在的唯一标准
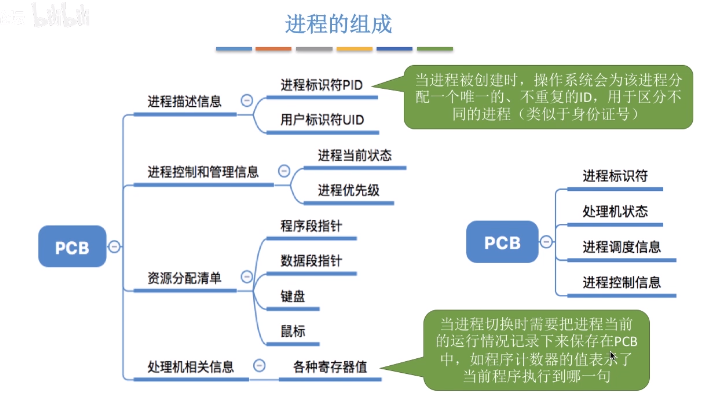
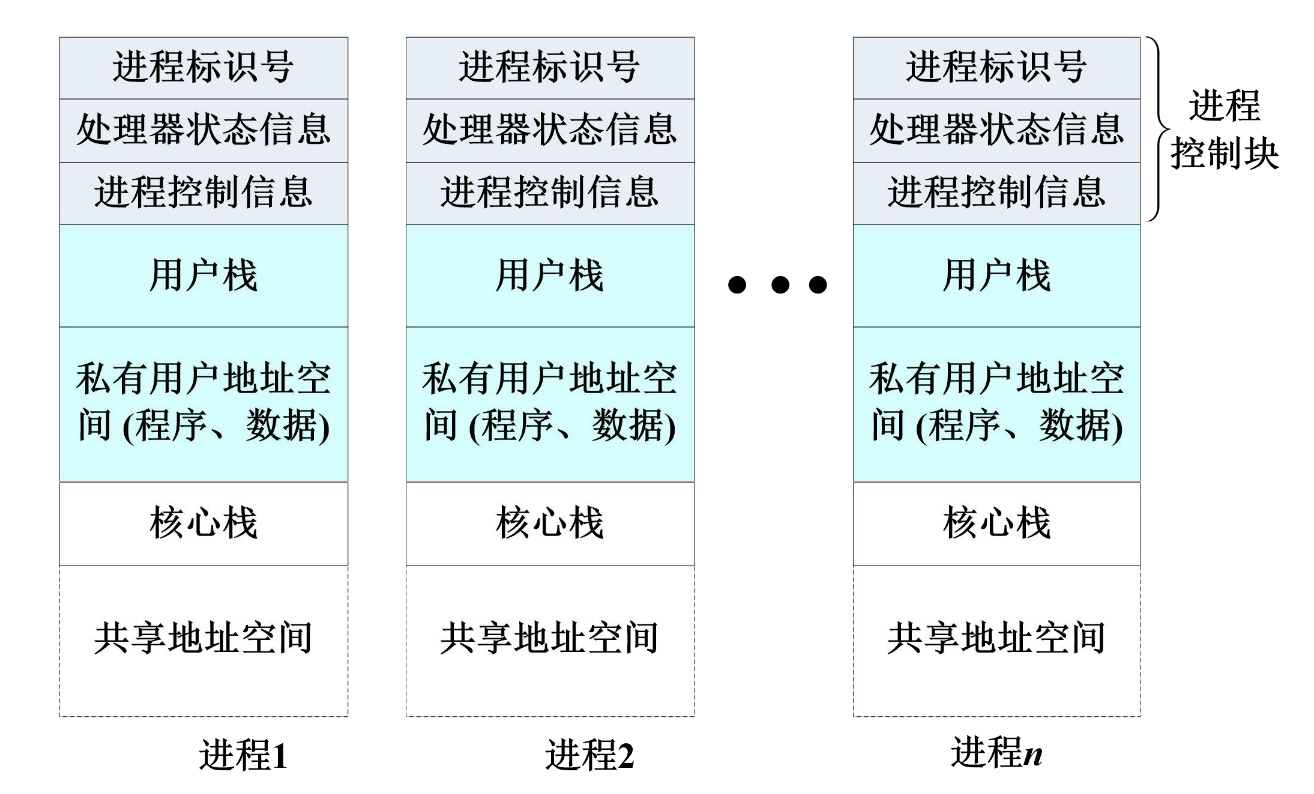
进程的组织方式
- 链接方式
- 按照进程状态将PCB分为多个队列,就绪队列,阻塞队列等
- 操作系统持有指向各个队列的指针
- 索引方式
- 根据进程状态的不同,建立几张索引表
- 操作系统持有指向各个索引表的指针
进程的状态
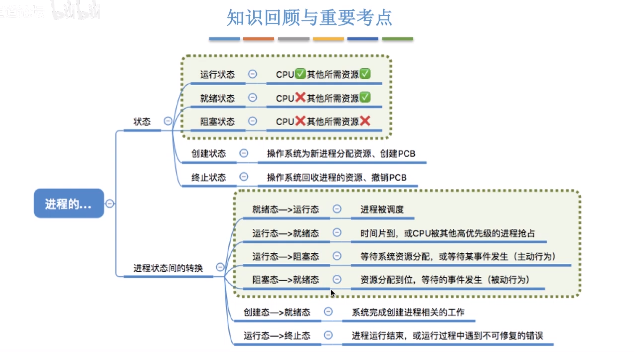
- 创建态: 操作系统为进程分配资源,初始化PCB
- 就绪态:运行资源等条件都满足,存储在就绪队列中,等待CPU调度
- 运行态:CPU正在执行进程
- 阻塞态:等待某些条件满足,等待消息回复,等待同步锁,sleep等,阻塞队列
- 终止态 :回收进程拥有的资源,撤销PCB
进程的切换和调度
备注:进程在操作系统内核程序临界区中不能进行调度和切换
概念
- 临界资源:一个时间段内只允许一个进程使用的资源,各进程需要互斥的访问临界资源
- 临界区:访问临界资源的代码
内核程序临界区:访问某种内核数据结构,如进程的就绪队列(存储各进程的PCB)
进程的调度方式
非剥夺调度方式(非抢占方式),只允许进程主动放弃处理机,在运行过程中即便有更紧迫的任务到达,当前进程依然会继续使用处理机,直到该进程终止或者主动要求进入阻塞态
- 剥夺调度方式(又称抢占方式)当一个进程正在处理机上执行时,如果有一个优先级更高的进程需要处理机,则立即开中断暂停正在执行的进程,将处理机饭呢陪给优先级高的那个进程
进程的切换与过程
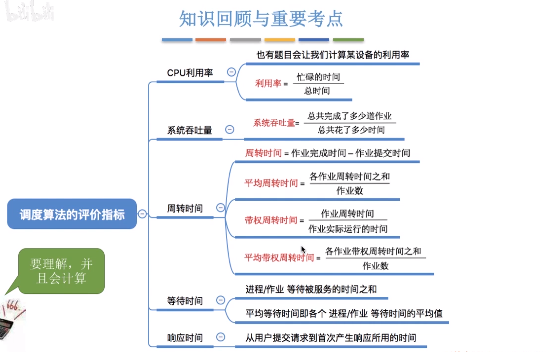
- CPU利用率:CPU忙碌时间/作业完成的总时间
- 系统吞吐量:单位时间内完成作业的数量
- 周转时间:从作业被提交给系统开始,到作业完成为止的时间间隔 = 作业完成时间-作业提交时间
- 带权周转时间:(由于周转时间相同的情况下,可能实际作业的运行时间不一样,这样就会给用户带来不一样的感觉) 作业周转时间/作业实际运行时间, 带权周转时间>=1, 越小越好
- 平均带权周转时间:各作业带权周转时间之和/作业数
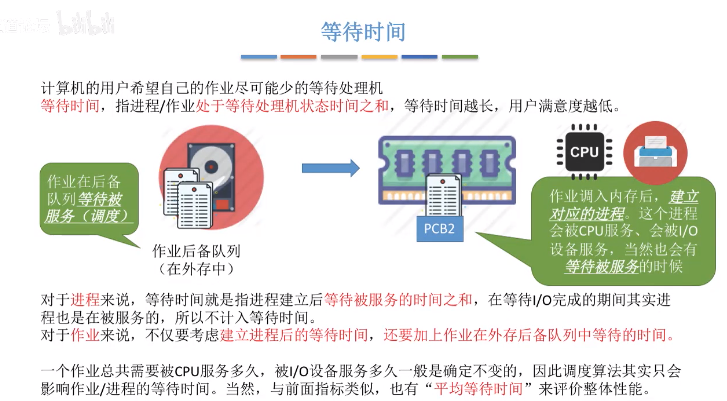
- 等待时间
- 响应时间
调度算法
- 调度思想:用于解决什么问题?
- 算法规则:用于作业(PCB作业)调度还是进程调度?
- 抢占式还是非抢占式的?
- 优缺点:是否会导致饥饿?
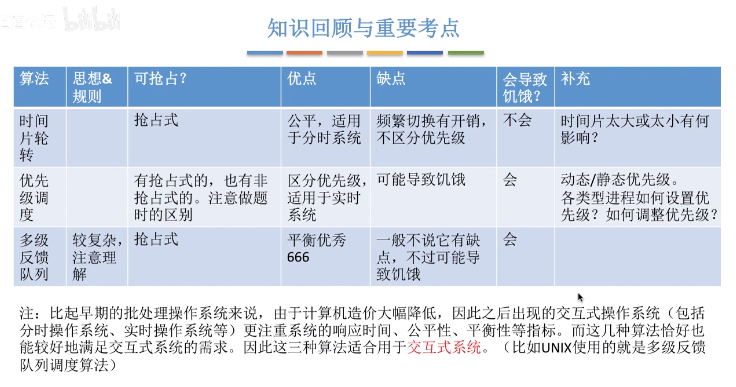
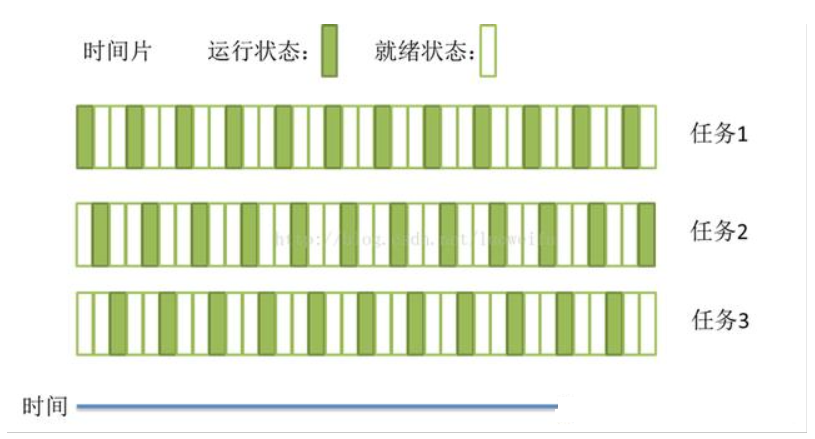
时间片轮流(Round_Robin)
- 算法思想:公平地、轮流地为各个进程服务,让每个进程在一定时间间隔内可以得到相应
- 算法规则:按照各进程到达就绪队列的顺序,轮流让各个进程执行一个时间片(如100ms)。若进程未在一个时间片内执行完,则剥夺处理机,将进程重新放到就绪队列队尾重新排队。
- 用于作业/进程调度:用于进程的调度(只有作业放入内存建立相应的进程后,才会被分配处理机时间片)
- 是否可抢占?若进程未能在规定时间片内完成,将被强行剥夺处理机使用权,由时钟装置发出时钟中断信号来通知CPU时间片到达
- 优缺点:适用于分时操作系统,由于高频率的进程切换,因此有一定开销;不区分任务的紧急程度
-
优先级调度算法
算法思想:随着计算机的发展,特别是实时操作系统的出现,越来越多的应用场景需要根据任务的进程成都决定处理顺序
- 算法规则:每个作业/进程有各自的优先级,调度时选择优先级最高的作业/进程
- 用于作业/进程调度:即可用于作业调度(处于外存后备队列中的作业调度进内存),也可用于进程调度(选择就绪队列中的进程,为其分配处理机),甚至I/O调度
- 是否可抢占? 具有可抢占版本,也有非抢占式的
- 优缺点:适用于实时操作系统,用优先级区分紧急程度,可灵活地调整对各种作业/及进程的偏好程度。缺点:若源源不断地提供高优先级进程,则可能导致饥饿
-
多级反馈队列调度算法

算法思想:综合FCFS、SJF(SPF)、时间片轮转、优先级调度
- 算法规则:
- 1.设置多级就绪队列,各级别队列优先级从高到底,时间片从小到大
- 2.新进程到达时先进入第1级队列,按照FCFS原则排队等待被分配时间片,若用完时间片进程还未结束,则进程进入下一级队列队尾
- 3.只有第k级别队列为空时,才会为k+1级对头的进程分配时间片
- 用于作业/进程调度:用于进程调度
- 是否可抢占? 抢占式算法。在k级队列的进程运行过程中,若更上级别的队列(1-k-1级)中进入一个新进程,则由于新进程处于优先级高的队列中,因此新进程会抢占处理机,原理运行的进程放回k级队列队尾。
- 优缺点:对各类型进程相对公平(FCFS的有点);每个新到达的进程都可以很快就得到相应(RR优点);短进程只用较少的时间就可完成(SPF)的有点;不必实现估计进程的运行时间;可灵活地调整对各类进程的偏好程度,比如CPU密集型进程、I/O密集型进程(拓展:可以将因I/O而阻塞的进程重新放回原队列,这样I/O型进程就可以保持较高优先级)
-
进程间通信方式
在计算机系统同,进程之间有时需要进行数据的通信,单是不同进程之间的数据存储是相互隔离的,每一个进程只能访问自己占有的数据,这时候,我们就需要使用用于进程间通信的机制了。不过,除了套接字外,进程间通信的前提是两进程必须是父子进程关系,没有这种关系的进程间不能直接进行通信,而是需要利用其共同的父进程进行信息的中转。
管道
- FIFO有名管道
- 消息队列
- 信号量
- 共享内存
- 套接字 Socket
信号通信
即父进程创建一个有名事件,子进程发送事件信号,然后父进程取到事件信号后,执行相应的代码。信号通信时最古老的进程间通信的方法之一,系统内核中内置了一些常见的有名信号,不过不同的系统和硬件具体的内置信号不太一样**
- 父进程创建一个有名事件
- 由子进程发送事件信号
- 父进程接收信号后进行相应的处理
代码实现(C++):
/* 父进程 windows 1.cpp */#include "process.h"#include "windows.h"#include <iostream>using namespace std;int main(){CreateEvent(NULL, FALSE, FALSE, "Event_of_my");/*创建一个有名事件*/PROCESS_INFORMATION pi;STARTUPINFO sui;//创建进程的准备工作ZeroMemory(&sui, sizeof(sui));sui.cb = sizeof(STARTUPINFO);if (!CreateProcess("1_child.exe", NULL, NULL, NULL, FALSE, CREATE_NEW_CONSOLE, NULL, NULL, &sui, &pi)) /*创建子进程*/{/*打印“创建子进程失败!”*/printf("Failed to create a process!\n");/*退出*/return 0;}else //创建成功 父进程继续执行{/*打印"Wait for event."*/printf("Wait for event\n");if (WAIT_FAILED == WaitForSingleObject(pi.hProcess, INFINITE))/*等待事件信号*/{printf("Failed to get the signal of event");//打印“等待事件信号失败!”return 0;/*退出*/}else{/*打印"Get the event"*/printf("Get the event\n");}}system("pause");return 0;}
/* 子进程 windows 1_child.cpp */#include "process.h"#include "windows.h"#include <iostream>using namespace std;int main(){//LPCTSTR lpName;HANDLE E;char Sig_Flag;E = OpenEvent(EVENT_ALL_ACCESS, TRUE, "Event_of_my");Sleep(3000);printf("Signal the event to Parent?[y\\n]\n");//There should be double"\" to print a'"\"scanf_s("%c", &Sig_Flag);if (Sig_Flag == 'y'){SetEvent(E);}CloseHandle(E);Sleep(3000);system("pause");return 0;}
管道通信(匿名管道,命名管道)
管道通信在系统中,是以文件的方式进行读写的,匿名管道在物理上由文件系统的高速缓冲区构成,而命名管道则可在系统的临时文件中找到具体的文件,相当于通过外部文件来交流信息。父子进程间以比特流,字符流的方式传送信息。管道属于半双工通信,在父子进程中同时创建一堆管道,然后利用其中一段(0端)来读数据,另一端(1端)来写数据。
匿名管道
- 由父进程创建一个匿名管道
- 父子进程向匿名管道写入和读取数据
分析:
首先定义一对管道pipe_default和缓冲区buffer,并使用pipe()和memset()函数获取一堆管道以及对缓冲区初始化,使用fork()函数产生一个子进程,并在父子进程中分别使用close()函数关闭管道的读端和写端,然后分别使用write()和read()函数进行进程间管道通信的读写操作。信息读写完毕后,关闭管道,然后再父进程中使用waitpid()函数等待子进程的退出,当子进程退出后,父进程才退出。
代码实现(C++):
/* 2.cpp */#include <stdio.h>#include <unistd.h>#include <stdlib.h>#include <string.h>#include <sys/wait.h>int pipe_default[2];int main(){pid_t pid;char buffer[32];memset(buffer, 0, 32);if(pipe(pipe_default) < 0){printf("Failed to create pipe!\n");return 0;}if(0 == (pid = fork())){close(pipe_default[1]); //关闭写端sleep(2);if(read(pipe_default[0], buffer, 32) > 0){printf("[Client] Receive data from server: %s \n", buffer);}close(pipe_default[0]);}else{close(pipe_default[0]); //关闭读端char msg[32]="== hello world ==";if(-1 != write(pipe_default[1], msg, strlen(msg))){printf("[Server] Send data to client: %s \n",msg);}close(pipe_default[1]);waitpid(pid, NULL, 0);}return 1;}
代码实现(Python):
#coding:utf-8import multiprocessingimport timedef proc1(pipe0,pipe1):for i in range(100):print("[proc1] 发送: ",i)pipe0.send(i)pipe1.send(i)print('[proc1] proc2 接收:',pipe0.recv())print('[proc1] proc3 接收:',pipe1.recv())time.sleep(1)def proc2(pipe):while True:msg=pipe.recv()print('[proc2] proc2 接收:',msg)pipe.send('proc2收到数据:' + str(msg))time.sleep(1)def proc3(pipe):while True:msg=pipe.recv()print('[proc3] proc3 接收:',msg)pipe.send('proc3收到数据:' + str(msg))time.sleep(1)# Build a pipepipe0 = multiprocessing.Pipe()pipe1 = multiprocessing.Pipe()print(pipe0)print(pipe1)# Pass an end of the pipe to process 1p1 = multiprocessing.Process(target=proc1, args=(pipe0[0],pipe1[0],))# Pass the other end of the pipe to process 2p2 = multiprocessing.Process(target=proc2, args=(pipe0[1],))# Pass the other end of the pipe to process 3p3 = multiprocessing.Process(target=proc3, args=(pipe1[1],))p1.start()p2.start()p3.start()p1.join()p2.join()p3.join()
(父进程**中转**实现进程间匿名管道通信)
代码实现(Python):
#coding:utf-8import multiprocessingimport threadingimport timedef threadfun(pipe0,pipe1): #线程任务函数 threadfun()while(True):pipe0.send(pipe1.recv())def proc1(pipe0,pipe1):t1 = threading.Thread(target=threadfun,args=(pipe0,pipe1)) #创建一个线程t1,执行 threadfun()t2 = threading.Thread(target=threadfun,args=(pipe1,pipe0)) #创建一个线程t2,执行threadfun()t1.start() #调用start(),运行线程t2.start() #调用start(),运行线程t1.join() #主线程等待 t1线程结束才继续执行t2.join() #主线程等待 t1线程结束才继续执行time.sleep(1)def proc2(pipe):for i in range(0,100):print("[proc2] 发送: ",i)pipe.send(i)msg=pipe.recv()print('[proc2] proc2 接收:',msg)time.sleep(1)def proc3(pipe):for i in range(-100,0):print("[proc3] 发送: ",i)pipe.send(i)msg=pipe.recv()print('[proc3] proc3 接收:',msg)time.sleep(1)# Build a pipepipe0 = multiprocessing.Pipe()pipe1 = multiprocessing.Pipe()print(pipe0)print(pipe1)# Pass an end of the pipe to process 1p1 = multiprocessing.Process(target=proc1, args=(pipe0[0],pipe1[0],))# Pass the other end of the pipe to process 2p2 = multiprocessing.Process(target=proc2, args=(pipe0[1],))# Pass the other end of the pipe to process 3p3 = multiprocessing.Process(target=proc3, args=(pipe1[1],))p1.start()p2.start()p3.start()p1.join()p2.join()p3.join()
命名管道
代码实现(C++):
/*Linux*/#include <stdio.h>#include <sys/types.h>#include <sys/stat.h>#include <limits.h>#include <fcntl.h>#include <unistd.h>#include <stdlib.h>#include <string.h>#include <time.h>#include<iostream>#define PIPE_NAME "/tmp/dpfifo"#define BUFFER_SIZE PIPE_BUFusing namespace std;//PIPE_BUF为limits.h定义的管道最大容量int main(void){pid_t pid;pid = fork();if(pid < 0){cout << "Create Error!" << endl;return 0;}else if(pid == 0){//子进程//写端,写数据int pipe_fd;int res;int len;int alllen;char buffer[BUFFER_SIZE+1];//每次写数据用的缓冲区int bytes_sent=0;if (access(PIPE_NAME,F_OK)==-1){//如果不存在PIPE_NAME,则建立res=mkfifo(PIPE_NAME,0777);//命名管道if (res!=0){perror("create pipe error!");exit(1);}}strcpy(buffer,"ailemon.me\n");printf("[writer] message: %s\n",buffer);len=strlen(buffer);alllen= len*2;//打开管道,管道都是FIFOprintf("[writer] process %d opening pipe !\n",getpid());pipe_fd=open(PIPE_NAME,O_WRONLY);printf("[writer] process %d result %d\n",getpid(),pipe_fd);if (pipe_fd!=-1){//发送数据while (bytes_sent<alllen){sleep(1);printf("[writer] %d bytes sending........\n",len);res=write(pipe_fd,buffer,len);printf("[writer] current %d bytes sended\n",res);if (res==-1){perror("write error on pipe\n");exit(1);}bytes_sent+=res;//res为本次写的字节数,bytes_sent为总字节数}close(pipe_fd);}else{exit(1);}printf("[writer] %d bytes sended!\n",bytes_sent);}else if(pid > 0){//父进程//读端,读取数据int pipe_fd;int res;int len;int alllen=20;char buffer[BUFFER_SIZE+1];//每次写数据用的缓冲区int bytes_read=0;memset(buffer,'\0',BUFFER_SIZE+1);sleep(1);//打开管道,管道都是FIFOprintf("[reader] read process %d opening pipe !\n",getpid());pipe_fd=open(PIPE_NAME,O_RDONLY);printf("[reader] read process %d result %d\n",getpid(),pipe_fd);if (pipe_fd!=-1){//发送数据do{sleep(1);res=read(pipe_fd,buffer,BUFFER_SIZE);printf("[reader] %s",buffer);bytes_read+=res;//res为本次写的字节数,bytes_sent为总字节数} while (bytes_read<=alllen);close(pipe_fd);}else{exit(1);}printf("[reader] %d bytes readed!\n",bytes_read);unlink(PIPE_NAME);}return 0;}
信号量
信号量主要用来解决进程和线程间并发执行时的同步问题,进程同步是并发进程为了完成共同任务采用某个条件来协调他们的活动,这是进程之间发生的一种直接制约关系。
对信号量的操作分为P操作和V操作,P操作时将信号量的值减1,V操作是将信号量的值加1。当信号量的值小于等于0之后,在进行P操作时,当前进程或线程会被阻塞,知道另一个进程或线程执行了V操作将信号量的值增加到大于0之时。锁也是用的这种原理实现的。
信号量我们需要定义其数量,设置初始值,以及决定合适进程PV操作。
- 生产者进程生产产品,消费者进程消费产品
- 当生产者进程生产产品时,如果没有空缓冲区可用,那么生产者进程必须等待消费者进程释放出一个缓冲区
- 当消费者进程消费产品时,如果缓冲区中没有产品,那么消费者进程将被阻塞,直到新的产品被生产出来
分析:
首先,通过semget()函数创建一个信号量集合并返回信号量的id,然后分别定义三个信号量作为mutex、empty和full,并分别设置初始值为1、N和0。然后使用semctl()函数创建这三个信号量,通过fork()函数产生一个父进程的两个子进程,分别作为生产者和消费者,通过按一定顺序控制信号量进行PV操作来实现进程间的同步。C/C++中并没有直接提供PV操作函数,不过为了方便使用,我们可以通过semop()函数来自己定义PV操作函数
代码实现(C++):
#include <unistd.h>#include <sys/types.h>#include <sys/stat.h>#include <fcntl.h>#include <stdlib.h>#include <stdio.h>#include <string.h>#include <sys/sem.h>#define KEY (key_t)15030110070#define N 20static void p(int semid ,int semNum);static void v(int semid ,int semNum);union semun {int val;struct semid_ds *buf;ushort *array;};int main(int argc ,char* argv[]){int i;int semid;semid = semget(KEY,3,IPC_CREAT|0660);union semun arg[3];arg[0].val = 1; //mutex [0] 对缓冲区进行操作的互斥信号量arg[1].val = N; //empty [1] 缓冲区空位个数narg[2].val = 0; //full [2] 产品个数for(i=0;i<3;i++)semctl(semid,i,SETVAL,arg[i]);pid_t p1,p2;if((p1=fork()) == 0){//子进程1,消费者while(1){printf("消费者 1 等待中...\n");sleep(2);int product = rand() % 2 + 1;for(int i = 0; i < product; i++){p(semid ,2); //消费p(semid ,0); //加锁printf(" [消费者 1] 消费产品 1. 剩余: %d\n", semctl(semid, 2, GETVAL, NULL));v(semid ,0); //开锁v(semid ,1); //释放空位}sleep(2);}}else{if((p2=fork()) == 0){//子进程2,消费者while(1){printf("消费者 2 等待中...\n");sleep(2);int product = rand() % 2 + 1;for(int i = 0; i < product; i++){p(semid ,2); //消费p(semid ,0); //加锁printf(" [消费者 2] 消费产品 1. 剩余: %d\n", semctl(semid, 2, GETVAL, NULL));v(semid ,0); //开锁v(semid ,1); //释放空位}sleep(2);}}else{//父进程,生产者while(1){printf("生产者开始生产...\n");int product = rand() % 5 + 1;for(int i = 0; i < product; i++){p(semid ,1); //占用空位p(semid ,0); //加锁printf(" [生产者] 生产产品 1. 剩余: %d\n", semctl(semid, 2, GETVAL, NULL) + 1);v(semid ,0); //开锁v(semid, 2); //生产}sleep(2);}}}return 0;}/* p操作 */void p(int semid ,int semNum){struct sembuf sb;sb.sem_num = semNum;sb.sem_op = -1;sb.sem_flg = SEM_UNDO;semop(semid, &sb, 1);}/* v操作 */void v(int semid ,int semNum){struct sembuf sb;sb.sem_num = semNum;sb.sem_op = 1;sb.sem_flg = SEM_UNDO;semop(semid, &sb, 1);}
代码实现(Python):
#!/usr/bin/env python# -*- coding: utf-8 -*-import multiprocessingimport timeimport randomfrom multiprocessing.sharedctypes import RawArraya = RawArray( 'i', [i for i in range(2)] ) #共享内存a[0]=0a[1]=0semaphore_num = multiprocessing.Semaphore(0) #产品个数semaphore_empty = multiprocessing.Semaphore(20) #缓冲区空位个数nsemaphore_mutex = multiprocessing.Semaphore(1) #对缓冲区进行操作的互斥信号量def consumer(flag):global numglobal notime.sleep(3)while(True):time.sleep(1)print("消费者 " + str(flag) +" 等待中...")item = random.randint(1, 3)for i in range(item):semaphore_num.acquire() #消费semaphore_mutex.acquire() #加锁no=a[0]num=a[1]num -= 1no+=1a[0]=noa[1]=numprint(str(no)+" [消费者 " + str(flag) +"] 消费产品 1. 剩余: " + str(num))semaphore_mutex.release() #开锁semaphore_empty.release() #释放空位def producer():global numglobal nowhile(True):time.sleep(1)print("生产者开始生产...")item = random.randint(1, 6)for i in range(item):semaphore_empty.acquire() #占用空位for i in range(item):semaphore_mutex.acquire() #加锁no=a[0]num=a[1]num += 1no+=1a[0]=noa[1]=numprint(str(no)+" [生产者] 生产产品 1. 剩余: "+str(num) )semaphore_mutex.release() #开锁semaphore_num.release() #生产if __name__ == "__main__":p1 = multiprocessing.Process(target=producer)p2 = multiprocessing.Process(target=consumer,args=("0"))p3 = multiprocessing.Process(target=consumer,args=("1"))p1.start()p2.start()p3.start()p1.join()p2.join()p3.join()print("程序结束")
共享内存
进程间本身的内存时相互隔离的,而共享内存机制相当于给两个进程开辟了一块二者均可访问的内存空间,这时,两个进程便可以共享一些数据了。但是,多进程同时占用资源会带来一些意料之外的情况,这时,我们往往会采用上述的信号量来控制多个进程对共享内存空间的访问。
- 写者进程创建一个共享主存,并向其中写入数据
- 读者进程随后从该共享主存区中访问数据
分析:
首先使用ftok()函数,通过命名的键创建一块共享内存,返回一个key,然后使用fork()函数产生父子进程,并将子进程定义为写者,父进程定义为读者。通过shmget()函数,通过得到的那个key,获取共享内存的id,然后使用shmat()函数,通过共享内存的id获得内存的地址。然后,在写者进程中,就可以使用strcpy()函数将一段字符串写入共享内存中,在读者进程中,通过共享内存的地址,可以直接获取到内容并输出。读写完毕后,可以使用shmdt()函数断开与共享内存的连接
代码实现(C++):
/* Linux 6.cpp */#include <iostream>#include <stdlib.h>#include <string.h>#include <sys/shm.h>#include <sys/ipc.h>#include <unistd.h>using namespace std;int main(){char *shmaddr;char *shmaddread;char str[]="Hello, I am a processing. \n";int shmid;key_t key = ftok(".",1);pid_t pid1 = fork();if(pid1 == -1){cout << "Fork error. " << endl;exit(1);}else if(pid1 == 0){//子进程shmid = shmget(key,1024,IPC_CREAT | 0600);shmaddr = (char*)shmat(shmid, NULL, 0);strcpy(shmaddr, str);cout << "[Writer] write: " << shmaddr << endl;shmdt(shmaddr);}else{//父进程pid_t pid2 = fork();if(pid2 == -1){cout << "Fork error. " << endl;exit(1);}else if(pid2 == 0){//子进程sleep(2);shmid = shmget(key,1024,IPC_CREAT | 0600);shmaddread = (char*)shmat(shmid, NULL, 0);cout << "[Reader] read: " << shmaddread << endl;shmdt(shmaddread);}}sleep(3);return 0;}
代码实现(Python):
#coding:utf-8import multiprocessingimport timesize = 8*1024 # 32KBdef proc1(a):passdef proc2(a):for i in range(0,size):print("[proc2] 写入: ",i)a[i]=itime.sleep(0.5)def proc3(a):for i in range(0,size):msg=a[i]print('[proc3] proc3 读出:',msg)time.sleep(0.5)from multiprocessing.sharedctypes import RawArraya = RawArray( 'i', [i for i in range(size)] )# Pass an end of the pipe to process 1p1 = multiprocessing.Process(target=proc1, args=(a,))# Pass the other end of the pipe to process 2p2 = multiprocessing.Process(target=proc2, args=(a,))# Pass the other end of the pipe to process 3p3 = multiprocessing.Process(target=proc3, args=(a,))p1.start()p2.start()p3.start()p1.join()p2.join()p3.join()
socket套接字
套接字时网络进程通信的机制,一般时用于位于不同机器上的进程间的通信。很多网络程序(如进士通讯软件,游戏,浏览器,数据库等)都往往采用了这种机制。
服务器/客户机模型(C/s)模型
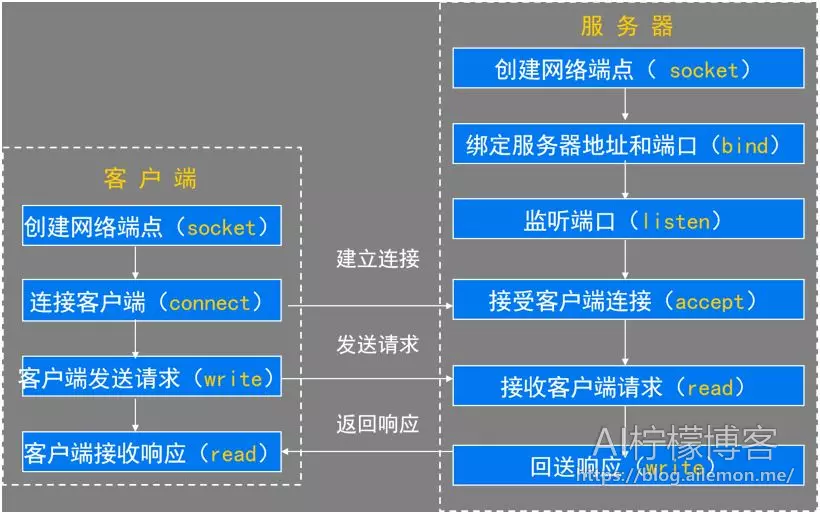
两种服务器模型
循环服务器
即在任一时刻只处理一个客户机的请求,处理该请求的过程中,下一请求处于等待状态。优点是节省服务器资源,缺点是响应时间长,适合处理非耗时的请求
并发服务器
即并发执行,服务器每收到一个连接请求就创建一个进程(或线程)处理该连接,服务器继续等待下一连接。优点是响应速度快,缺点是占用系统资源多
Python通过socket套接字实现通信
python可以用来实现两个主机进程之间的TCP通信,就是通过使用socket套接字来实现的,我们可以基于此,来实现一些应用层协议,以达到不同主机之间的进程通信的目的。这一点,除了普通的网络应用程序(如聊天工具和游戏等)之外,在分布式系统中,也有着很大的用途,比如机器学习需要在多台计算机中进行并行计算的时候
演示示例:多进程TCP并发服务
(我们要使用到的包是socket和multiprocessing)
服务器端:
首先使用socket对象的socket()方法获取一个套接字对象,再使用bind()方法绑定服务器端的IP地址和端口号,接着调用listen()方法开始监听,使用阻塞式的accept()方法获取每一个传入的客户端连接对象conn和信息。
当每收到一个客户端连接后,我们就创建一个进程来专门处理这个客户端连接,在python中可以将要创建进程的类从multiprocessing.Process父类中继承,在子类中的init()函数里传入启动进程时用到的参数并初始化配置,在run()函数中处理相关事情,在父进程中使用start()方法启动这个进程。
对于客户端的连接对象conn可以使用settimeout()方法设置超时时间,使用recv()方法接收客户端发来的数据,作为回应,可以使用sendall()方法回应客户端,给客户端发数据。
当我们不再需要客户端的时候,服务器端可以使用close()方法关闭该连接。
import multiprocessingimport socketclass ClientProcess(multiprocessing.Process):def __init__(self,conn,addr):multiprocessing.Process.__init__(self)self.conn = connself.addr = addrdef run(self):self.conn.sendall(bytes("你好,我是AI柠檬~",encoding="utf-8"))ret_timeout = str(self.conn.recv(1024),encoding="utf-8")self.conn.settimeout(int(ret_timeout))while(True):try:ret = str(self.conn.recv(1024),encoding="utf-8")self.conn.sendall(bytes("我收到了你的信息:"+ret,encoding="utf-8"))if(ret==":q"):self.conn.close()breakexcept Exception as ex:self.conn.close()breakif __name__ == '__main__':s = socket.socket()inp_addr = input("Please input this server's ip address:\n>>>")inp_port = input("Please input this server's port:\n>>>")s.bind((inp_addr,int(inp_port)))s.listen()print("服务器已开启")users = []while(True):conn,addr=s.accept()p = ClientProcess(conn,addr)p.start()users.append(p)print("有一个新用户连接,进程号pid:", p.pid)num = 0tmp_users=[]for i in range(len(users)):if(users[i].is_alive()==True):tmp_users.append(users[i])users = tmp_usersprint("当前用户数:", len(users))s.close()
客户端:
同样,首先先使用socket对象的socket()方法获取一个套接字对象,然后使用connect()方法连接到指定IP地址和端口的服务器端程序。
其他如同服务器端,使用sendall()方法写出数据,使用settimeout()方法设置超时时间,使用recv()方法接收服务器端发来的数据。
当我们不再需要服务器端的时候,客户端可以使用close()方法关闭该连接。
import socketobj = socket.socket()inp_addr = input("Please input server's ip address:\n>>>")inp_port = input("Please input server's port:\n>>>")obj.connect((inp_addr,int(inp_port)))inp_timeout = input("Please input timeout(s):\n>>>")obj.sendall(bytes(inp_timeout,encoding="utf-8"))obj.settimeout(int(inp_timeout))msg = str(obj.recv(1024),encoding="utf-8")print(msg)while True:inp = input("Please(:q\退出):\n>>>")if(inp!=""):obj.sendall(bytes(inp,encoding="utf-8"))if(inp == ":q"):obj.close()breaktry:ret = str(obj.recv(1024),encoding="utf-8")print(ret)except socket.timeout:print("[Error]Network Connection Time Out!")breakexcept:print("[Error]Unknown Network Connection Error!")break
进程分类
- 孤儿进程
- 僵尸进程
- 守护进程
- 特殊进程
孤儿进程
如果父进程先退出,子进程还没退出,那么子进程将被托孤给init进程,这时子进程的父进程就是init进程(1号进程) 孤儿进程无危害危害
孤儿进程结束后会被init进行善后,并没有危害僵尸进程
如果我们了解过linux进程状态及转换关系,我们应该知道进程这么多状态中有一种状态是僵尸状态,就是进程终止后进入僵尸状态(zombie),等待告知父进程自己终止,后才能完全消失.但是如果一个进程已经终止了,但是其父进程还没有获取其状态,那么这个进程就称之为僵尸进程.僵尸进程还会消耗一定的系统资源,并且还保留一些概要信息供父进程查询子进程的状态可以提供父进程想要的信息.一旦父进程得到想要的信息,僵尸进程就会结束. 一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait和waitpi获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵尸进程危害
会一直占着进程号,操作系统的进程数量有限解决僵尸进程
一般僵尸进程的产生都是因为父进程的原因,则可以通过kill父进程进行解决,这时候僵尸进程就变成了孤儿进程,被init进程接收守护进程
守护进程就是在后台运行,不与任何终端关联的进程,通常情况下守护进程在系统启动时就在运行,它们以root用户或者其他特殊用户(apache和postfix)运行,并能处理一些系统级的任务。习惯上守护进程的名字通常以d结尾(sshd),但这些不是必须的特殊的进程
- 0 号进程负责进程间的切换,解决CPU占用
1号进程,直接或者间接的创建进程,负责进程的创建和孤儿进程的善后
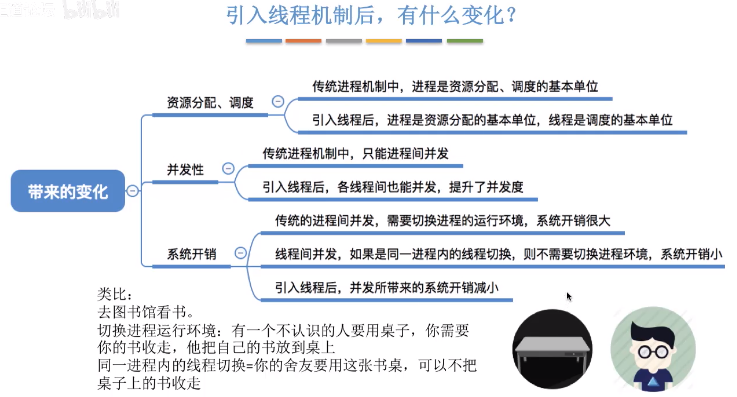
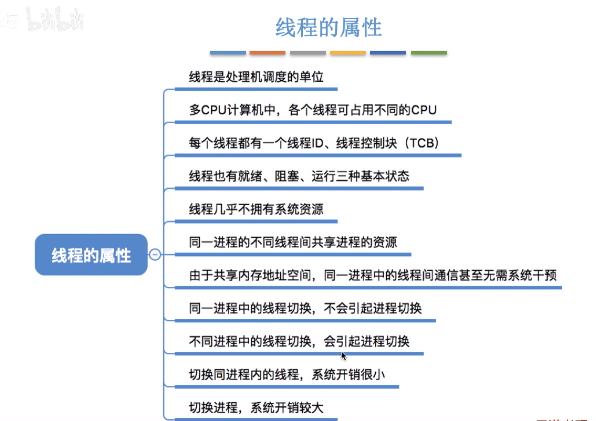
线程
引入线程之后,进程只作为除CPU之外的系统资源的分配单元(如:打印机,内存地址空间等都是分配给进程的)
线程的实现方式:
用户级线程(User-Level Thread),用户级线程由应用程序通过线程库是实现如python (import thread), 线程的管理工作由应用程序负责
- 内核级线程(kernel-Level Thread),内核级线程的管理工作由操作系统内核完成,线程调度,切换等工作都由内核负责,因此内核级线程的切换必然需要在核心态下才能完成
进程和线程的关系:一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。CPU的最小调度单元是线程,所以单进程多线程是可以利用多核CPU的。
多线程与多核心
多核(心)处理器是指一个处理器上集成多个运算核心从而提高计算能力,也就是有多个真正并行计算的处理核心,每一个处理核心对应一个内核线程
- 内核线程(Kernel Thread,KLT)线程是直接由操作系统内核支持的线程,这种线程由内核来完成线程切换,内核通过操作系统对线程进行调度,并负责将线程的任务映射到各个处理器上。
- 单核处理器对应一个内核线程,双核对应两个内核线程,四核处理器对应四个内核线程
双核四线程处理器对应四个内核线程,四核八线程处理器对应八个内核线程(超线程技术将一个物理处理核心模拟成两个逻辑处理核心)
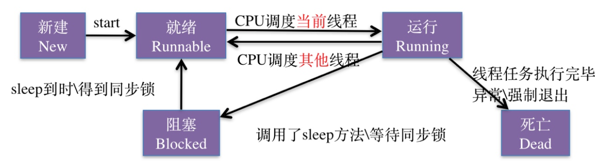
线程的基本状态
新建(New):线程在进程内派生出来,它即可由进程派生,也可由线程派生
- 阻塞(blocked):线程运行过程中,可能由于各种原因进入阻塞状态
- 通过sleep方法进入睡眠状态
- 线程调用一个在I/O上被阻塞的操作,即该操作在输入输出操作完成之前不会返到它的调用者
- 试图得到一个锁,而该锁被其他线程持有
- 等待某个出发条件
- 就绪(read):一个新创建的线程并不自动开始运行,要执行线程,必须调用线程的start()方法。当线程对象调用start()方法即启动了线程,start()方法创建线程运行的系统资源,并调度线程运行run()方法。当start()方法返回后,线程就处于就绪状态。处于就绪状态的线程并不一定立即运行run()方法,线程还必须同其他线程竞争CPU时间,只有获得CPU时间才可以运行线程
- 运行(running):线程后的CPU时间后,进入运行状态,真正开始执行run()方法
- 结束(dead):征程退出自然死亡,或者异常终止导致线程猝死
线程模型
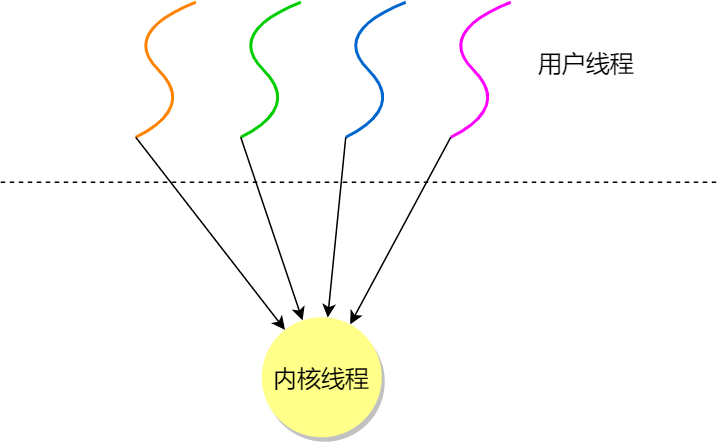
- 如果CPU没有采用超线程技术,一个用户线程就唯一的映射到一个物理CPU的内核线程,线程之间的并发是真正的并发
- 一对一模型使用用户线程具有与内核线程一样的优点,一个线程因某种原因阻塞时其他线程的执行不受影响
-
缺点
许多操作系统限制了内核线程的数量,因此一对一模型会使用户线程的数量收到限制
- 许多操作系统内核线程调度时,上下文切换的开销大,导致用户线程的执行效率下降
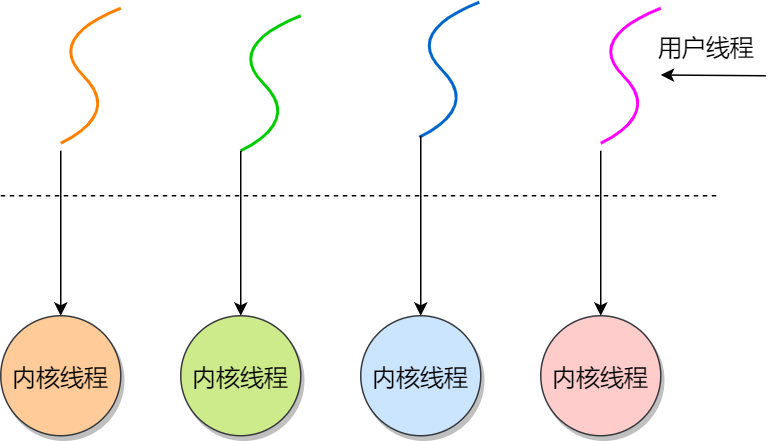
多对一模型
优点
- 线程之间的切换由用户态的代码来进行,系统内核感受不到线程的实现方式。
- 用户线程的建立,同步,销毁等都在用户态中完成,不需要内核的介入。
- 因此相对于一对一模型,多对一模型的线程上下文切换要快很多
-
缺点
如果一个用户线程阻塞,那么其他所有线程都将无法执行,因此此时内核线程也随之阻塞了
- 在多喝处理器上,处理器数量的增加对多对一模型的线程性能不会由明显的增加,因为所有的用户线程都映射到一个处理器上
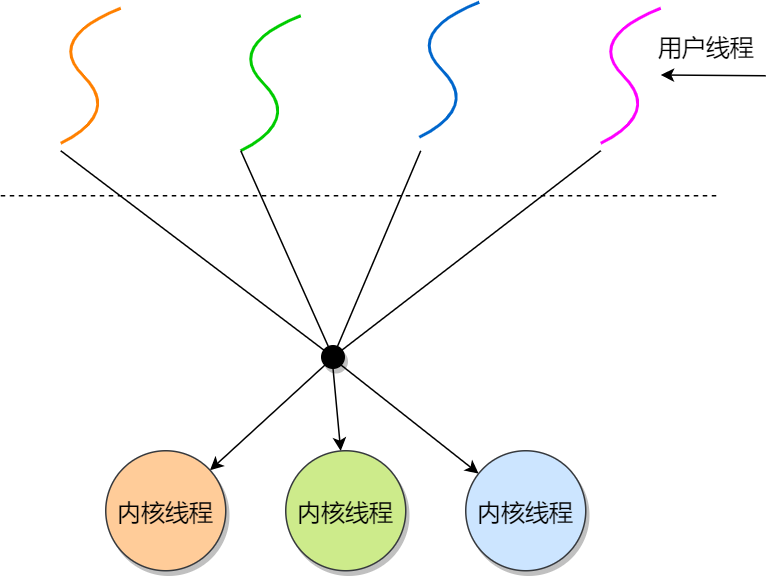
多对多模型
将多个用户线程映射到多个内核线程上。多对多模型结合了一对一模型和多对一模型的优点。
优缺点
- 由线程库负责在可用的可调度实体上调度用户线程,这使得线程的上下文切换非常快(因为它避免了系统调用。但是增加了复杂性和优先级倒置的可能性,以及在用户态调度程序和内核调度程序之间没有广泛(且高昂)协调的次优调度)
- 一个用户线程的阻塞不会导致所有线程的阻塞,因为此时还有别的内核线程被调度来执行
- 多对多模型对用户线程的数量没有限制
- 在多处理器的操作系统中,多对多模型的线程也能得到一定的性能提升,但提升的幅度不如一对一模型的高
协程
协程通过在线程中实现调度,避免了陷入内核级别的上下文切换造成的性能损失,进而突破了线程在IO上的性能瓶颈。协程本质上来说是一种用户态的线程,不需要系统来执行抢占式调度,而是在语言测个面实现线程的调度
Python协程
python的协程源于yield指令
- yield item 用于产出一个值,反馈给next()的调用方法
- 让出处理机,暂停执行生成器,让调用方继续工作,直到需要使用另一个值时再调用next()
协程式对线程的调度,yield类似惰性求职方式可以视为一种流程控制工具,实现协作式多任务,python3.5引入了async/await表达式,使得协程证实在语言层面得到支持和优化,大大简化之前的yield写法。线程正式在语言层面得到支持和优化。线程是内核进行抢占式调度的,这样就确保每个线程都有执行的机会。而coroutine运行在同一个线程中,有语言层面运行时中的EventLoop(事件循环)来进行调度。在python中协程的调度是非抢占式的,也就是说一个协程必须主动让出执行机会,其他协程才有机会运行。让出执行的关键字 await, 如果一个协程阻塞了,持续不让出CPU处理机,那么整个线程就卡住了,没有任何并发。
作为服务端,event loop最核心的就是I/O多路复用技术,所有来自客户端的请求都由I/O多路复用函数来处理;作为客户端,event loop的核心在于Future对象延迟执行,并使用send函数激发协程,挂起,等待服务端处理完成返回后再调用Callback函数继续执行
Golang协程
Go 天生在语言层面支持,和python类似都是用关键字,而GO语言使用了go关键字,go协程之间的通信,采用了channel关键字。
两种并发形式
- 多线程共享内存:如Java 或者C++在多线程中共享数据的时候,通过锁来访问
CSP(communicating sequential processes)并发模型:Go语言特有的,也是Go语言推荐的
CSP使如何实现的?
Go的CSP并发模型是通过goroutine 和 channel来实现的
- goroutine是go语言中并发的执行单位。
- channel是Go语言中各个并发结构体之间的通信机制。
- channel -< data 写数据
- <- channel 读数据 ```go package main
import (“fmt”)
func main() { jobs := make(chan int) done := make(chan bool) // end flag
go func() {for {j, ok := <- jobsfmt.Println("---->:", j, ok)if ok {fmt.Println("received job")} else {fmt.Println("end received jobs")done <- truereturn}}}()go func() {for j:= 1; j <= 3; j++ {jobs <-jfmt.Println("sent job", j)}close(jobs)fmt.Println("close(jobs)")}()fmt.Println("sent all jobs")<-done // 阻塞 让main等待协程完成
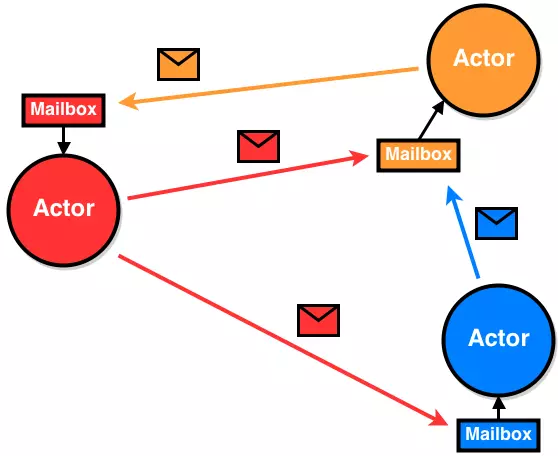
CSP和Actor模型的区别?
- CSP并不Focus发送消息的实体/Task, 而是关注发送消息时消息所使用的载体,即channel。
- 在Actor的设计中,Actor与信箱是耦合的,而在CSP中channel是作为first-class独立存在的
Actor中有明确的send/receive关系,而channel中并不区分这样的关系,执行快可以任意选择发送或者取消息
Actor模型
Go协程调度器GPM
G 指的是Goroutine,其本质上也是一种轻量级的线程
- P proessor, 代表M所需要的上下文环境,也是处理用户级代码逻辑处理器。同一时间只有一个线程(M)可以拥有P, P中的数据都是锁自由(lock free)的, 读写这些数据的效率会非常的高
- M Machine,一个M直接关联一个内核线程,可以运行go代码 即goroutine, M运行go代码需要一个P, 另外就是运行原生代码,如 syscall。运行原生代码不需要P
一个M会对应一个内核线程,一个M也会连接一个上下文P,一个上下文P相当于一个处理器,一个上下文连接一个或者多个Goroutine。P(Processor)的数量是在启动时被设置为环境变量GOMAXPROCS的值,或者通过运行时调用函数runtime.GOMAXPROCS()进行设置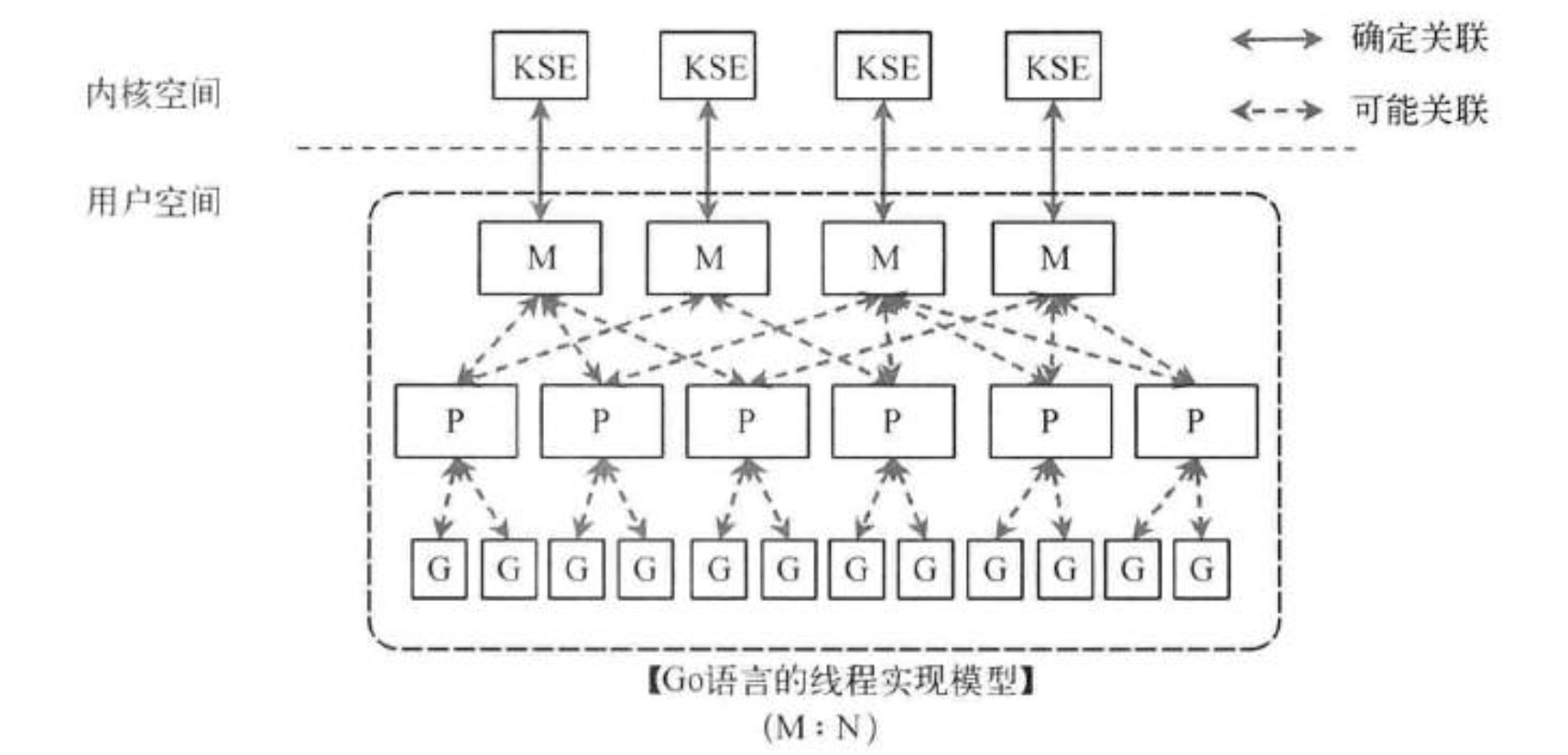
扩展
- erlang和golang都是采用CSP模型,python中协程是eventloop模型。但是erlang是基于进程的消息通信,go是基于goroutine和channel通信。
- python和golang都引入了消息调度系统模型,来避免锁的影响和进程线程的开销问题
- 计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决 — G-P-M模型正是此理论践行者,此理论也用到了python的asyncio对地狱回调的处理上(使用Task+Future避免回调嵌套),是不是巧合?
- 其实异步≈可中断的函数+事件循环+回调,go和python都把嵌套结构转换成列表结构有点像算法中的递归转迭代
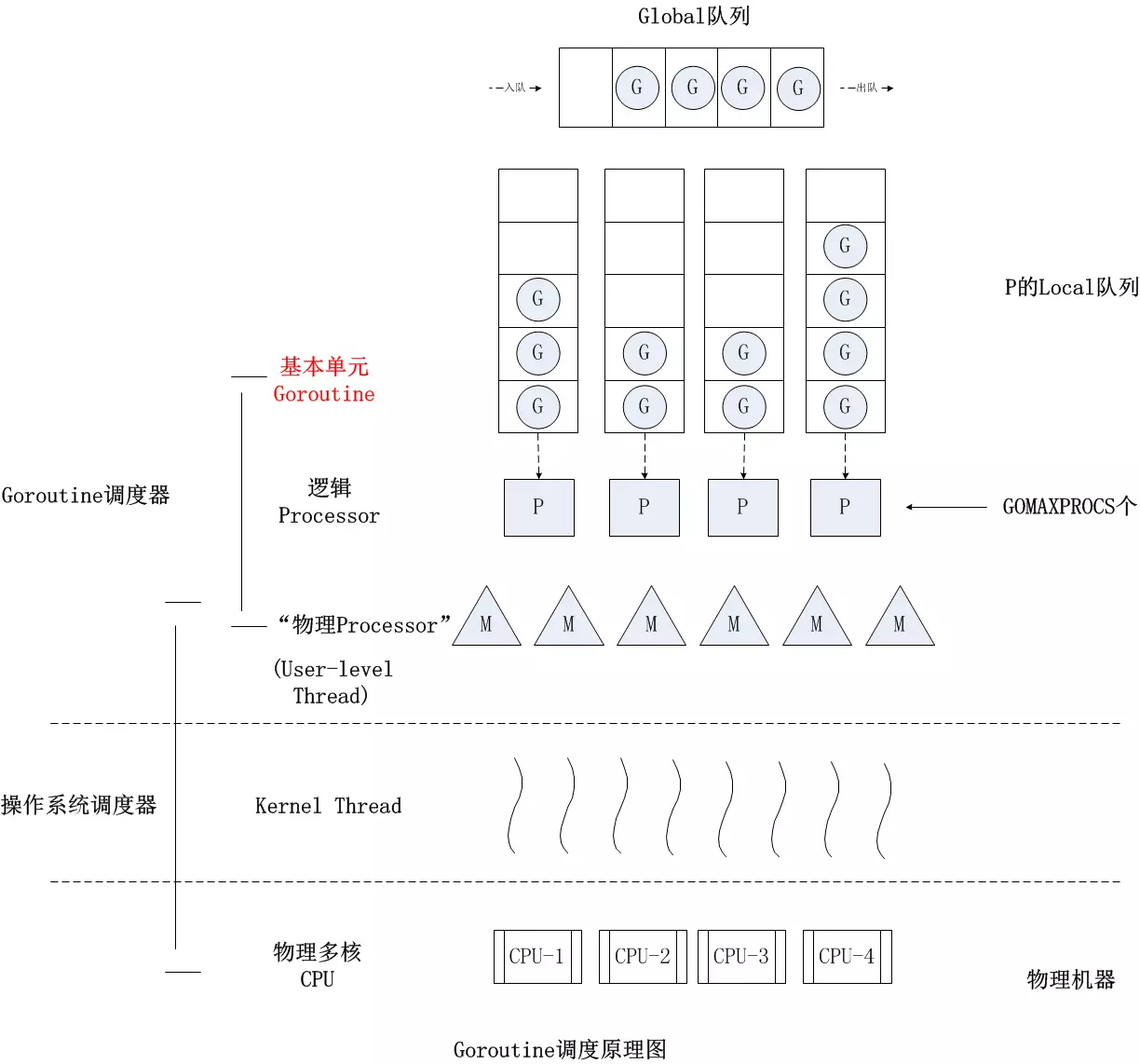
调度器在计算机中是分配工作时所需要的资源,Linux的调度是CPU找到可运行的线程,Go的调度是为M线程找到P(内存,执行票据)和可运行的G(协程)
Go协程是轻量级的,栈初始2KB(OS操作系统的线程一般都是固有的栈内存2M), 调度不涉及系统调用,用户函数调用前会检查栈空间是否足够,不够的话,会进行站扩容,栈大小限制可以达到1GB。
Go的网络操作是封装了epoll, 为NonBlocking模式,切换协程不阻塞线程。
Go语言相比起其他语言的优势在于OS线程是由OS内核来调度的,goroutine则是由Go运行时(runtime)自己的调度器调度的,这个调度器使用一个称为m:n调度的技术(复用/调度m个goroutine到n个OS线程)。 其一大特点是goroutine的调度是在用户态下完成的, 不涉及内核态与用户态之间的频繁切换,包括内存的分配与释放,都是在用户态维护着一块大的内存池, 不直接调用系统的malloc函数(除非内存池需要改变),成本比调度OS线程低很多。 另一方面充分利用了多核的硬件资源,近似的把若干goroutine均分在物理线程上, 再加上本身goroutine的超轻量,以上种种保证了go调度方面的性能。点我了解更多

若有收获,就点个赞吧
0 人点赞
