记录rocketmq学习过程,分为实战与原理部分
实战与简介
一.配置与使用
1.1角色介绍
RocketMQ由四个部分组成,分别是发信者(Producer),收信者(Consumer),暂存,传输(Broker),管理者(NameServer).启动顺序是先启动NameServer,再启动Broker,这时消息队列已经可以提供服务了,发消息就用Producer来发送,接受消息就使用Consumer来接受.
Broker:负责存储消息,转发消息.具体提供业务的服务器,单个节点与所有nameServer保持长连接及心跳.
Topic:主题,在发送和接受消息前,先创建Topic针对某个Topic发送和接受消息.
Tag:子主题
Group:分组,一个组可以订阅多个topic,代表一类消费者或生产者
Queue:内部是有序的,分为读和写两种队列
Message Queue:如果一个Topic需要发送的数据量非常大,可以设置一个或多个Message Queue,类似分区或Partition,Topic有了queue以后可以并行的向各个Message Queue发送.
Offset:message Queue是一个长度无限的数组,offset就是下标.
1.2配置参数介绍
以一个master broker的配置为例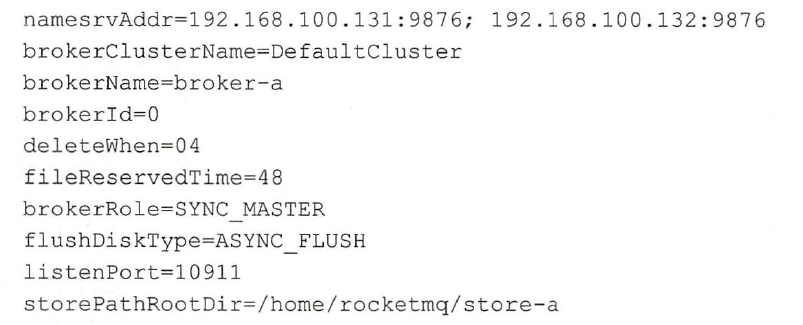
namesrvAddr:NamerServer的地址,可以是多个,brokerClusterName是cluster的地址,可以分成多个cluster,每个cluster供一个业务群使用.brokerName:Broker的名称,master和slave通过使用相同的名称来表明互相关系.brokerId:一个MasterBorker可以有多个Slave,0表示Master,大于0表示不同Slave的ID。fileReservedTime:在磁盘上保存消息的时长,单位是小时,自动删除超时的消息。brokerRole:有三种SYNC_MASTER,ASYNC_MASTER,SLAVE,关键词SYNC和ASYNC表示master和slave之间同步消息的机制,SYNC是同步完成后再返回发送成功的状态。flushDiskType:表示刷盘策略,有同步刷盘和异步刷盘。storePathRootDir:存储消息以及一些配置信息的根目录。
问:怎样消除单点故障实现高可用?
答:可以在多台机器上部署多个NameServer和Broker,在为每一个Broker部署一个或多个slave.
二.使用合适的方式收发消息
2.1消费者
消费者可分为两种类型,一个是DefaultMQPushConsumer,有系统控制读取操作,收到消息后自动调用传入的处理方法。另一个是DefaultMQPullConsumer,读取操作中大部分功能能由使用者自主控制。
push方式是server端接收到消息后,主动把消息推给客户端,实时性高.弊端是加大了server的工作量,影响性能,如果client不能及时处理Server的消息,会有潜在问题.
pull方式是client循环地从server拉取消息,主动权在client手里.问题是循环拉取消息地间隔不好设定.
消息模式:
Clustering:同一个ConsumerGroup里的每个Consumer只消费所订阅消息的一部分内容,同一个ConsumerGroup里所有的Consumer消费的内容合起来才是所订阅Topic内容的整体。
Broadcasting:同一个ConsumerGroup里的每个Consumer都能消费到所订阅Topic的全部消息,也就是一个消息会被多次分发,被多个Consumer消费。
2.1.1DefaultMQPushConsumer
主要参数:GroupName,NameServer的地址和端口号,Topic的名称。
GroupName:用于把多个Consumer组织到一起,提高并发处理能力,需要和消息模式配合使用。
NameServer的地址和端口号:可以填写多个,消除单点故障.
Topic的名称:用来标识消息类型,表示要消费的消息主题,在tag参数的位置可以标明消费的具体tag或者用*表示全部tag.
处理流程
消息处理逻辑是在pullMessage函数里的callback中,通过长轮询的方式达到push效果.长轮询地方式通过client端和server端地配合,达到既拥有pull的优点,又能保证实时性地目的.
流量控制
ProcessQueue用来解决如何得知当前消息堆积地数量,如何重复处理某些消息,如何延迟处理某些消息.在PushConsumer运行地时候,每个MessageQueue都会有个对应地ProcessQueue对象,保存这个队列处理状态地快照.主要的内容是一个TreeMap和一个读写锁,TreeMap以Message Queue的下标为key,内容为value,保存了所有获取到的但是还未被处理的消息.
在获取之后,如果值超过了设定的队列大小范围,就会隔一段时间再拉取消息.
2.1.2DefaultMQPullConsumer
首先逐个读取某Topic下所有的MessageQueue的内容.然后额外处理几件事情:1)获取message queue并遍历,2)维护offsetstore,3)根据不同的消息状态做不同的处理
pullConsumer自己遍历和处理MessageQueue保存Offset,所以有更多的自主性和灵活性.
2.1.2Consumer的启动,关闭流程
Consumer分为push和pull两种方式,pull的主动权很高,可以根据实际需要来操作,需要注意Offset的保存,要在程序异常处理部分增加把offset写入磁盘方面的处理.(消息的准确性)
pushConsumer:
1.启动的时候要做配置检查,然后连接NameServer获取信息,如果遇到异常仍然可以正常启动,这是为了在集群的环境下保持高可用.不会立即退出,会不断尝试重新连接.
2.在退出的时候要调用shutdown()函数,用来释放资源,保存offset
2.2生产者
2.2.1DefaultMQProducer
发消息要经过五个步骤:1)设置producer的groupName 2)设置InstanceName,当一个jvm需要启动多个producer的时候,通过设置不同的InstanceName来区分,不设置默认DEFAULT 3)设置发送失败重试次数 4)设置nameServer的地址 5)组装消息并发送
返回状态有以下几种:
发送延迟消息:broker收到这类消息后,延迟一段时间再处理,规定的一段时间后生效.用方法setDelayTimeLevel设置延迟时间.
自定义消息发送规则:如果要把消息发到指定的messageQueue中,可以使用messageQueueSelector.
对事物的支持:采用两阶段提交的方式实现事物消息,TransactionMQProducer处理的流程是,先发一条消息,发送成功后再做操作,根据操作是否成功,确定之前的消息是commit还是rollback
2.3存储队列位置信息
RocketMQ中,一种类型的消息会放到一个Topic中,为了能够并行,一般一个Topic会有多个MessageQueue,offset是指某个Topic下的一条消息在某个MessageQueue里的位置,通过值可以定位到这条消息。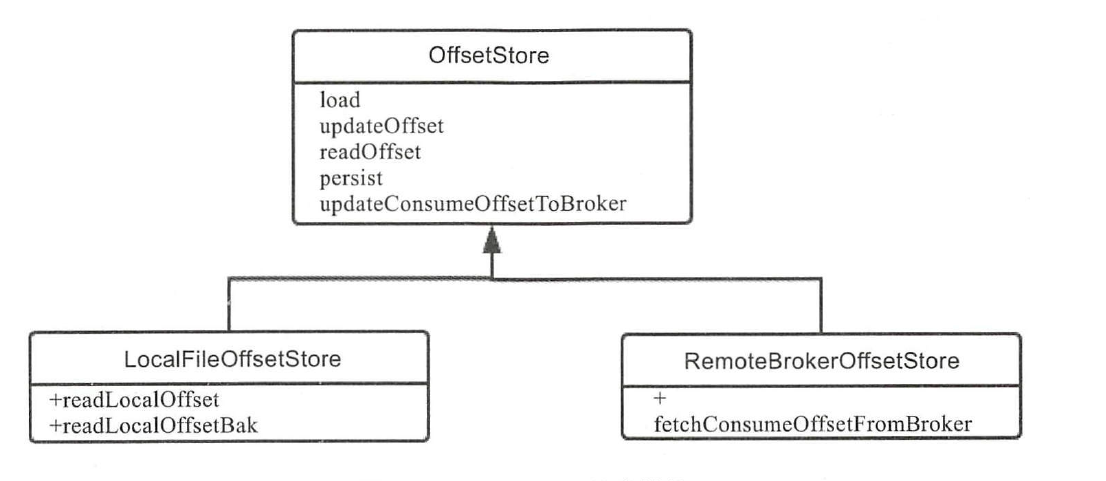
默认使用clustering消息模式,这种情况下由broker端存储和控制offset的值,使用remoteBrokerOffsetStore。broadcasting模式下,使用localFileOffsetStore,把Offset存到本地。
在使用pushConsumer的时候不需要关心offsetStore,pullConsumer要对offeset进行持久化存储。
三.分布式消息队列的协调者NameServer
NameServer 是整个消息队列中的状态服务器,各个角色的机器都要定期向NameServer 上报自己的状
态。NamServer 可以部署多个,相互之间独立,其他角色同时向多个NameServer机器上报状态信息,从而达到热备份的目的
3.1.1集群状态的存储结构



NameServer的主要工作就是维护这五个变量中存储的信息.
3.1.2状态维护
NameServer的主要逻辑在DefaultRequestProcessor类,当NameServer和Broker的长连接断掉以后,会把Broker的信息清除出去.
心跳机制:NameServer会定时检查时间戳,每次broker发送心跳之后会更新时间戳,如果检查到时间戳没有更新后,会触发清理逻辑.默认是10s检查一次,如果超过2min会认为已失效.
3.1.3角色间的交互流程
创建Topic:Upd ateTopicSubCommand 类中update Topic的参数,b 参数指定在哪个Broker 上创建本To pic 的Mes sage Queue , c 参数表示在这个Cluster 下面所有的Master Broker 上创建这个Topic 的Message Queue , 从而达到高可用性的目的
Option ("b","BrokerAddr", true,"create topic to which Broker" ) ;Option ("c","ClusterName", true," create topic to which Cluster ");
创建Topic的命令被发往对应的Broker,接到创建Topic的请求后执行具体的创建逻辑,先更新本地的config,最后向NameServer发送注册消息,NameServer完成创建的逻辑后,其他客户端才能发现新的Topic
问:为什么不用ZooKeeper?
答:RocketMQ的架构设计决定了它不需要进行master选举,只需要一个轻量级的元数据服务器就足够了,中间件对稳定性要求很高。
3.1.4底层通信机制
Rocket的通信相关在Remoting模块里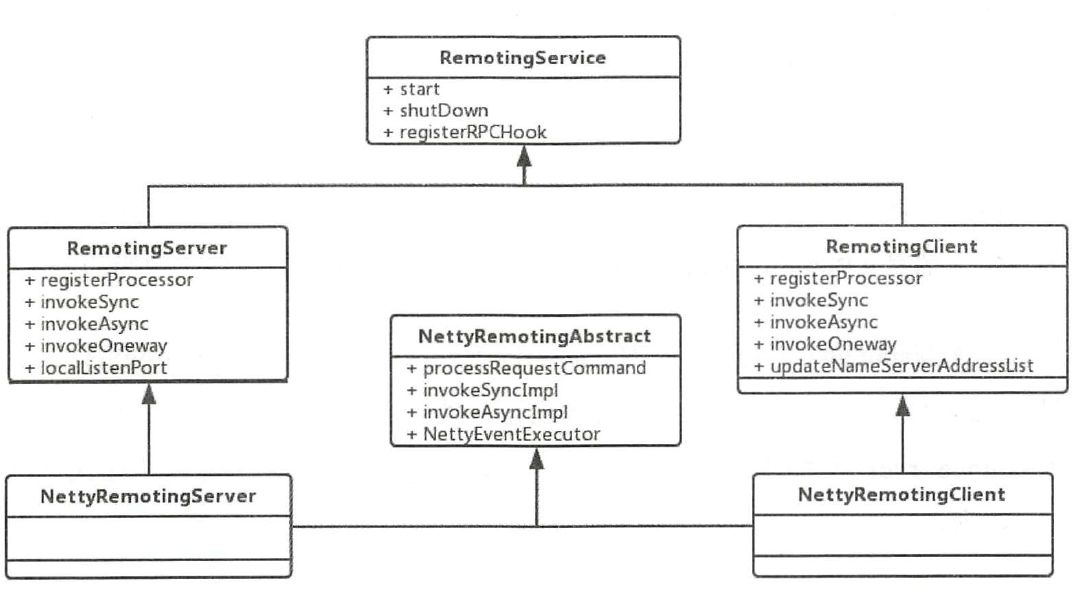
通过上面的封装RocketMQ各个模块间的通信,可以通过发送统一格式的自定义消息(RemotingCommand)来完成。例如在NameServer中,有一个remotingServer变量,启动之后用发送,接受,处理RemotingCommand来完成通信.
协议设计和编解码:通信协议的模块如下
1.第一部分是大端四个字节整数,值等于第二,三,四部分长度的总和 2.第二部分是大端四个字节整数,值等于第三部分的长度 3.第三部分是通过json序列化的数据 4.第四部分是通过应用自定义二进制序列化的数据.
消息的解码与编码都在RemotingCommand进行
四.消息队列的核心机制Broker
Broker完成大部分的工作,包括接受Producer发过来的消息,处理Consumer的消费消息请求,消息的持久化存储,服务端过滤功能
4.1消息存储结构
面试题:如何持久化消息
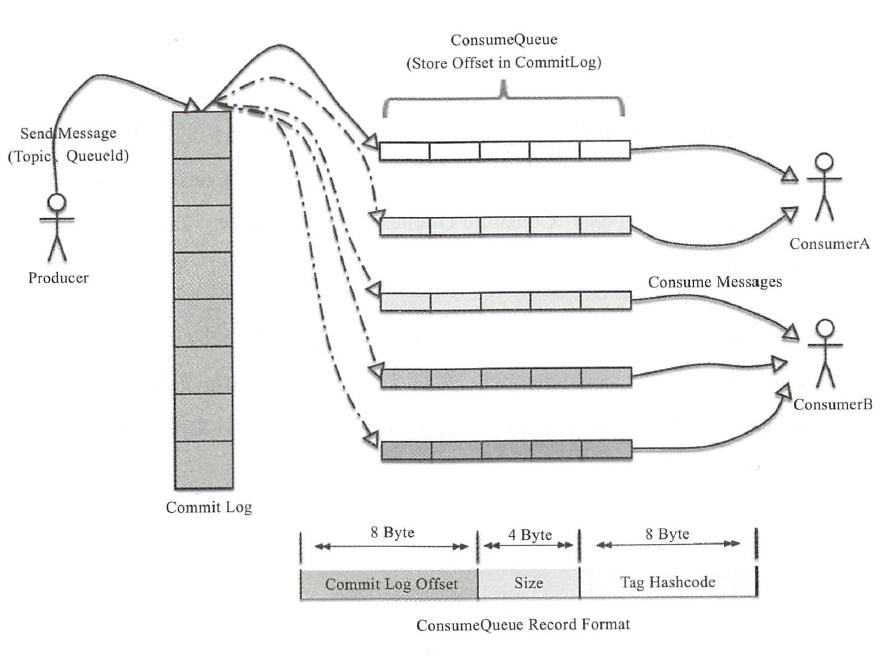
上图是RocketMQ的存储结构,消息的存储是由ConsumeQueue和CommitLog配合完成的,消息真正的物理存储文件是CommitLog, ConsumeQueue 是消息的逻辑队列,类似数据库的索引文件,存储的是指向物理存储的地址.每个Topic 下的每个Message Queue 都有一个对应的ConsumeQueue 文件。
CommitLog 以物理文件的方式存放,每台Broker 上的CommitLog 被本机器所有ConsumeQueue 共享,MQ尽量向Log中顺序写,但是随机读,这么做的好处有以下几点:
1)CommitLog 顺序写,可以大大提高写人效率。
2)虽然是随机读,但是利用操作系统的pagecache 机制,可以批量地从磁盘读取,作为cache 存到内存中,加速后续的读取速度。
3)为了保证完全的顺序写,需要ConsumeQueue 这个中间结构,因为ConsumeQueue 里只存偏移量信息,所以尺寸是有限的,在实际情况中,大部分的ConsumeQueue 能够被全部读人内存,所以这个中间结构的操作速度很快,可以认为是内存读取的速度。此外为了保证CommitLog 和ConsumeQueue 的一致性,CommitLog 里存储了Consume Queues 、Message key、Tag 等所有信息,即使ConsumeQueue 丢失,也可以通过commitLog 完全恢复出来。(保证消息不丢失)
消息首先会由broker存储到commitlog里,ReputMessageService会不断的查询commitlog中是否有新的消息,如果有就会通知consumeQueue,根据topic和ConsumeQueueId找到对应的consumeQueue,如果没有就创建一个。然后更新consumeQueue里的信息。
4.2高可用性机制
分布式集群是通过master和slave达到高可用的.Broker配置中,brokerId为0表示是Master,大于0是Slave.Master角色支持读写,slave仅支持读.
面试题:如何保证高可用
问:如何支持消费端的高可用?
答:consumer中,不需要设置是从master还是slave读,如果master不可用或者繁忙,会自动切换到slave.
问:如何支持发送端的高可用?
答:在创建Topic 的时候,把Topic 的多个Message Queue 创建在多个Broker 组上(相同Broker 名称,不同broker Id 的机器组成一个Broker 组),这样当一个Broker 组的Master 不可用后,其他组的Master 仍然可用.
4.3同步刷盘和异步刷盘
消息在通过Producer写入MQ的时候,有两种刷盘的方式:异步刷盘,同步刷盘.通过Broker配置文件里flushDiskType参数设置
1)异步刷盘方式:在返回写成功状态时,消息可能只是被写人了内存的PAGECACHE ,写操作的返回快,吞吐量大;当内存里的消息量积累到一定程度时,统一触发写磁盘动作,快速写入.
2)同步刷盘方式:在返回写成功状态时,消息已经被写人磁盘。具体流程是,消息、写入内存的PAGECACHE后,立刻通知刷盘线程刷盘,然后等待刷盘完成,刷盘线程执行完成后唤醒等待的线程,返回消息写成功的状态。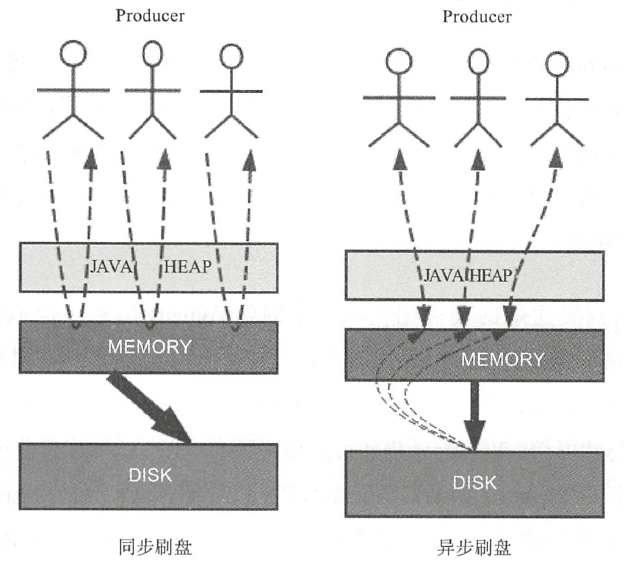
4.4同步复制和异步复制
如果一个Broker 组有Master 和Slave, 消息需要从Master 复制到Slave上,有同步和异步两种复制方式。同步复制方式是等Master 和Slave 均写成功后才反馈给客户端写成功状态;异步复制方式是只要Master 写成功即可反馈给
客户端写成功状态。
异步的好处是吞吐量大,低延迟但是master挂了以后不能恢复.同步的好处是数据容易恢复但是延迟和吞吐量低
五.可靠性优先的场景
5.1顺序消息
顺序消息是指消息的消费顺序和产生顺序相同,分为全局顺序消息和部分顺序消息.全局顺序消息指某个Topic下的所有消息都要保证顺序;部分顺序消息只要保证每一组消息被顺序消费即可.
面试题:如何保证消费顺序
全局顺序消息:如果要保证全局顺序消息,要把读写队列数设置为1,然后生产和消费的并发设置也要是1,要消除所有的并发处理.
部分顺序消息:需要发送端和消费端配合处理.在发送端要做到把同一业务ID的消息发送到同一个MessageQueue;(发送端使用MessageQueueSelector来控制消息发到哪个Queue)在消费的过程中,要做到从同一个MessageQueue读取的消息不被并发处理,这样才能达到部分有序.(消费的时候使用MessageListenerOrderly,实现的时候为每个ConsumerQueue加个锁,消费消息前需要先获得这个消息对应的ConsumerQueue的锁,保证了同一个queue的消息不被并发消费,不同Queue的消息可以并发处理)
5.2消息重复问题
RocketMQ选择了确保一定投递,保证消息不丢失,但有可能造成消息重复.
面试题:消息重复消费
第一种方法是保证消费逻辑的幂等性(多次调用和一次调用的效果相同)另一种方法是维护一个已消费消息的记录,消费前查询这个消息是否被消费过.
5.3消息优先级
RocketMQ是个先入先出的队列,不支持消息级别或者Topic级别的优先级。业务中简单的优先级需求,可以通过间接的方式解决。
第一种是比较简单的情况,如果当前Topic 里有多种相似类型的消息,比如类型AA 、AB 、AC ,当AB 、AC 的消息量很大,但是处理速度比较慢的时候,队列里会有很多AB 、AC 类型的消息在等候处理,这个时候如果有少量AA 类型的消息加入,就会排在AB 、AC 类型消息后面,需要等候很长时间才能被处理。
如果业务需要AA 类型的消息被及时处理,可以把这三种相似类型的消息分拆到两个Topic 里,比如AA 类型的消息在一个单独的Topic, AB 、AC 类型的消息在另外一个Topic 。把消息分到两个Topic 中以后,应用程序创建两个Consumer ,分别订阅不同的Topic ,这样消息AA 在单独的Topic 里,不会因为AB 、AC 类型的消息太多而被长时间延时处理。
第二种情况和第一种情况类似,但是不用创建大量的Topic 。举个实际应用场景:一个订单处理系统,接收从100 家快递门店过来的请求,把这些请求通过Producer 写人RocketMQ ;订单处理程序通过Consumer 从队列里读取消息并处理,每天最多处理1 万单。如果这100 个快递门店中某几个门店订单量大增,比如门店一接了个大客户,一个上午就发出2 万单消息请求,这样其他的99 家门店可能被迫等待门店一的2 万单处理完,也就是两天后订单才能被处理,显然很不公平。
这时可以创建一个Topic , 设置Topic 的MessageQueue 数量超过100 个,Producer 根据订单的门店号,把每个门店的订单写人一个MessageQueue 。DefaultMQPushConsumer 默认是采用循环的方式逐个读取一个Topic 的
所有MessageQueue ,这样如果某家门店订单量大增,这家门店对应的MessageQueue 消息数增多,等待时间增长,但不会造成其他家门店等待时间增长。
第三种情况是强优先级需求,上两种情况对消息的“优先级”要求不高,更像一个保证公平处理的机制,避免某类消息的增多阻塞其他类型的消息。现在有一个应用程序同时处理TypeA 、TypeB 、TypeC 三类消息。TypeA 处于第一优先级,要确保只要有TypeA 消息,必须优先处理; TypeB 处于第二优先级; TypeC 处于第三优先级。对这种要求,或者逻辑更复杂的要求,就要用户自己编码实现优先级控制,如果上述的三类消息在一个Topic 里,可以使
用PullConsumer ,自主控制MessageQueue 的遍历,以及消息的读取;如果上述三类消息在三个Topic 下,需要启动三个Consumer , 实现逻辑控制三个Consumer 的消费。
六.吞吐量优先的使用场景
6.1在Broker端进行消息过滤
可以减少无效消息发送到Consumer,有三种方式进行消息过滤
6.1.1消息Tag和Key
对一个应用来说,尽可能只用一个Topic,不同消息用Tag来标识.消费方在订阅消息时,可以利用Tag在Broker端做消息过滤.对发送的消息设置好Key ,以后可以根据这个Key 来查找消息。这个Key 一般用消息在业务层面的唯一标识码来表示.
6.1.2通过Tag进行过滤
一个Message只能有一个Tag.Broker端可以在ConsumeQueue中做这种过滤,只从CommitLog里读取过滤后被命中的消息.Consume Queue 的第三部分存储的是Tag 对应的hash code ,是一个定长的字符串,通过Tag 过滤的过程就是对比定长的hashcode
6.1.3用SQL表达式的方式进行过滤
TODO
6.2提高Consumer处理能力
( 1 )提高消费并行度在同一个ConsumerGroup 下( Clustering 方式),可以通过增加Consumer
实例的数量来提高并行度,通过加机器,或者在已有机器中启动多个Consumer进程都可以增加Consumer 实例数。注意总的Con sumer 数量不要超过Topic 下Read Queue 数量,超过的C onsumer 实例接收不到消息。此外,通过提高单个Consumer 实例中的并行处理的线程数可以在同一个Consumer 内增加并行度来提高吞吐量(设置方法是修改consumeThreadMin 和consumeThreadMax ) 。
( 2 )以批量方式进行消费某些业务场景下,多条消息同时处理的时间会大大小于逐个处理的时间总和,比如消费消息中涉及update 某个数据库, 一次update 10 条的时间会大大小于十次update 1 条数据的时间。这时可以通过批量方式消费来提高消费的吞吐量。实现方法是设置Consumer 的consumeMessageBatchMaxSize 这个参数,默认是1 ,如果设置为N,在消息多的时候每次收到的是个长度为N 的消息链表。
( 3 )检测延时情况,跳过非重要消息Consumer 在消费的过程中,如果发现由于某种原因发生严重的消息堆积,短时间无法消除堆积,这个时候可以选择丢弃不重要的消息,使Consumer 尽快追上Producer 的进度
6.3Consumer负载均衡
6.4提高Producer的发送速度
TODO
七.NameServer源码
7.1入口函数
NamesrvStartup是模块的启动入口,Controller是协调各个模块功能的代码。NamesrvStartup里的main函数主要负责解析命令行参数,重点是解析-c和-p参数,另一个功能是初始化Controller,调用controller.initialize()来初始化,然后调用controIler.start()让NameServer 开始服务。
7.2总控逻辑
NameServer是集群的协调者,简单地接受其他角色报上来的状态,然后根据请求返回相应的状态,首先会启动一个八个线程的线程池,其中一个用来扫描失效的Broker,另一个用来打印配置信息。然后负责通信的remotingServer监听端口,根据请求,调用不同的Processor来处理。
7.3核心业务逻辑
在DefaultRequestProcessor中,主体是一个switch语句,根据不同的RequestCode调用不同的函数处理。
7.4集群状态存储
NameServer作为集群的协调者,需要保存和维护集群的各种元数据。通过RoutelnfoManager类来实现
主要就是这些map来保存信息。
RoutelnfoManager 中使用的是可重人的读写锁( private final ReadWriteLock lock = new ReentrantReadWriteLock())
八.client源码
使用Consumer的时候,一般流程是设置好GroupName,NameServer地址,以及订阅的Topic名称,然后填充Message处理函数,最后调用start()。
8.1实现Consumer
DefaultMQPushConsumerlmpl具体实现了业务逻辑,首先初始化MqClientInstance,并且设置好rebalane策略和pullApiWraper,然后是确定OffsetStore,这是存储了当前消费者所消费消息在队列中的偏移量,然后是初始化consumeMessageService,根据消息顺序需求的不同,使用不同的Service类型。
获取消息的逻辑实现在public void pullMessage ( final PullRequest pullRequest)函数中,这是一个很大的函数,前半部分是进行一些判断, 是进行流量控制的逻辑;中间是对返回消息结果做处理的逻辑;后面是发送获取消息请求的逻辑。通过判断未处理消息的个数和总大小来控制是否继续请求消息。对于顺序消息还有一些特殊判断逻辑。获取的消息返回后,根据返回状态,调用相应的处理方法。最后是发送获取消息请求。
8.2并发处理消息
主要是由ConsumeMessageConcurrentlyService完成,它定义了三个线程池,一个主线程池用来正常执行收到的消息,另外两个都是单线程的线程池,一个用来执行推迟消费的消息,另一个用来定期清理超时消息。
从Broker获取到一批消息以后,根据BatchSize的设置,把一批消息封装到一个ConsumeRequest中,然后把这个ConsumeRequest提交到consumeExecutor线程池中执行.根据消息处理结果的不同值,会有不同的执行,如果消费不成功,要把消息提交到上面说的scheduledExecutorService 线程池中, 5 秒后再执行;如果消费模式是CLUSTERING
模式,未消费成功的消息会先被发送回Broker ,供这个ConsumerGroup 里的其他Consumer 消费,如果发送回B roker 失败, 再调用RECONSUME_LATER.
ProcessQueue:每个Message Queue都会有一个对应的ProcessQueue对象,保存这个MessageQueue消息处理状态的快照.用来处理超时的情况.获取当前消息堆积的数量.
对象里面主要的内容是一个TreeMap和一个读写锁。TreeMap里以MessageQueue的Offset作为Key,以消息内容的引用为Value,保存了所有从MessageQueue获取到但是还未被处理的消息,读写锁控制多个线程对TreeMap对象的并发访问。
8.3生产者消费者的底层类
生产者和消费者底层都是和Broker打交道。MQClientinstance是客户端各种类型的Consumer和Producer的底层类。这个类会获取并保存NameServer的配置信息。还会和Broker交互来实现收发消息。一个对象可以被多个消费者或生产者公用,但是并不是单例模式,是工厂类构建的。
基于RocketMQ的分布式事务解决方案
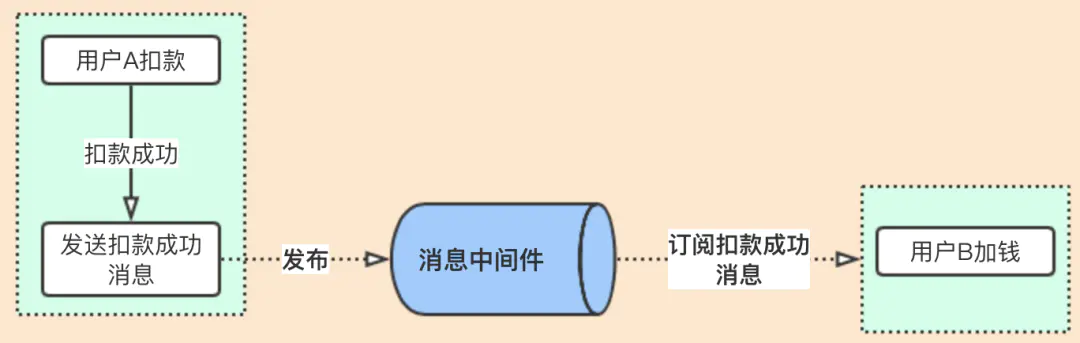
基于消息中间件实现会有的问题就是,先扣款后发消息和先发消息后扣款都会有失败的可能性,没办法保证同事.因为这个问题,RocketMQ把消息分为了两个阶段:Prepared阶段和确认阶段Prepared阶段(预备阶段)
Prepared阶段:该阶段主要发一个消息到rocketmq,但该消息只储存在commitlog中,但consumeQueue中不可见,也就是消费端(订阅端)无法看到此消息。
commit/rollback阶段(确认阶段):该阶段主要是把prepared消息保存到consumeQueue中,即让消费端可以看到此消息,也就是可以消费此消息。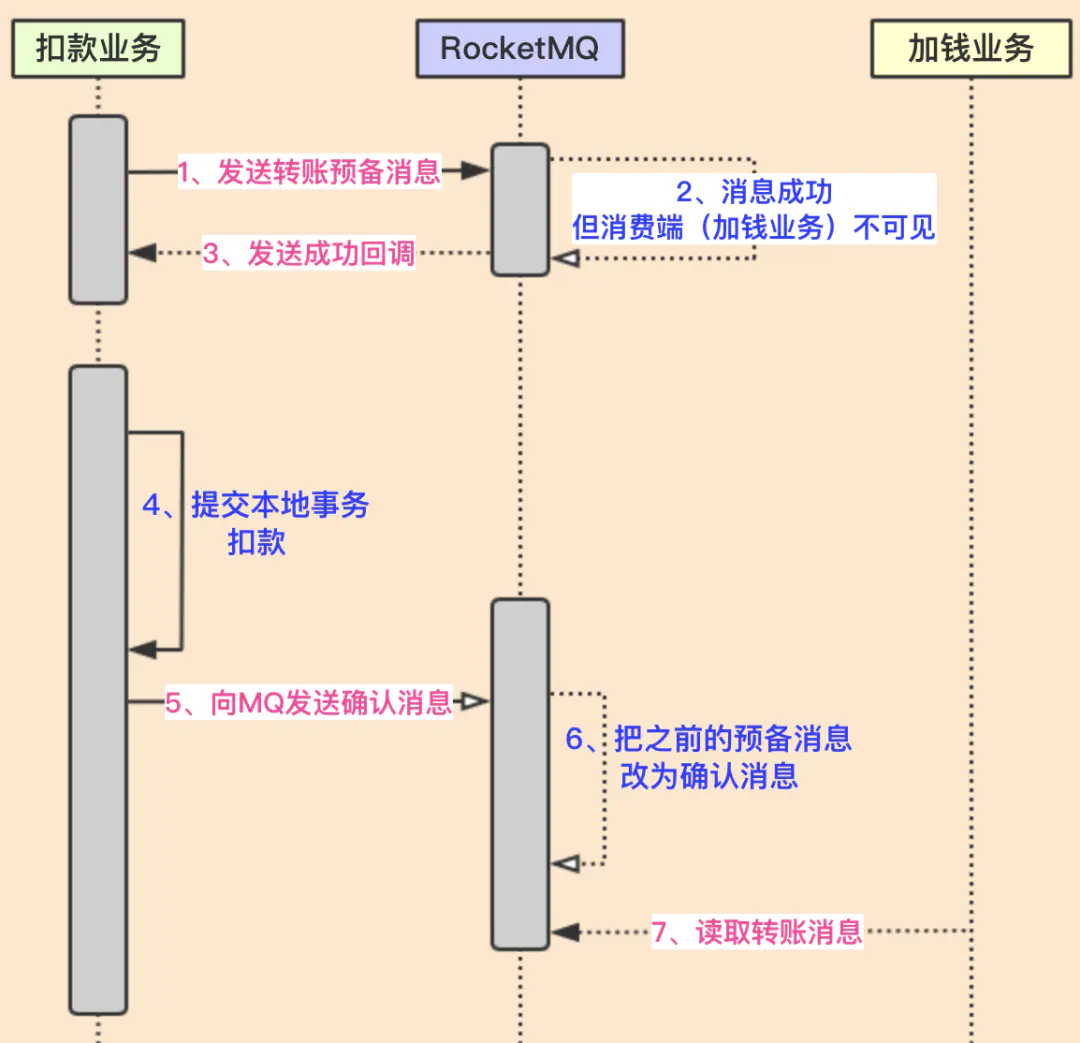
异常情况:如果发送预备消息成功,执行本地事务成功,但发送确认消息失败;这个就有问题了,因为用户A扣款成功了,但加钱业务没有订阅到确认消息,无法加钱。这里出现了数据不一致。
RocketMQ回查: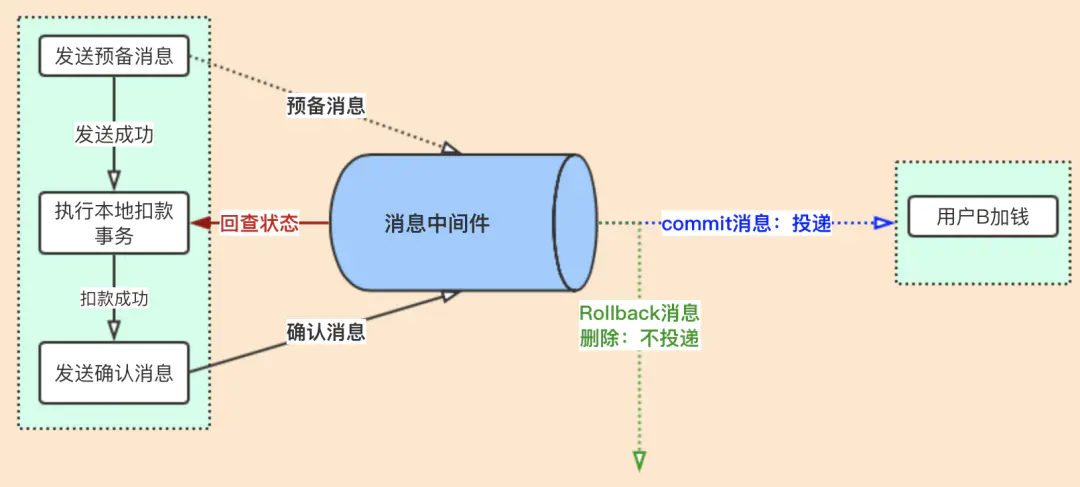
RocketMQ会定时遍历commitlog中的预备消息,因为预备消息最终肯定会变为commit消息或Rollback消息,所以遍历预备消息去回查本地业务的执行状态,如果发现本地业务没有执行成功就rollBack,如果执行成功就发送commit消息。
根据上面的异常情况发送预备消息成功,本地扣款事务成功,但发送确认消息失败;因为RocketMq会进行回查预备消息,在回查后发现业务已经扣款成功了,就补发“发送commit确认消息”;这样加钱业务就可以订阅此消息了。
注:判断业务是否执行成功,可以设计一张事物表,和业务表绑在一个事物里,业务执行成功以后会在事物表根据唯一id更新执行状态,也可以更好的与业务解耦。

若有收获,就点个赞吧
0 人点赞
