1、简述
收集算法是内存回收的方法论,垃圾回收器就是内存回收的具体体现。Java虚拟机规范中对垃圾收集器如何实现并没有任何规定。因此不同的厂商、不同版本提供的垃圾回收器都可能会有很大差别。一般会根据自己应用的特点组合出各个年代所使用的收集器。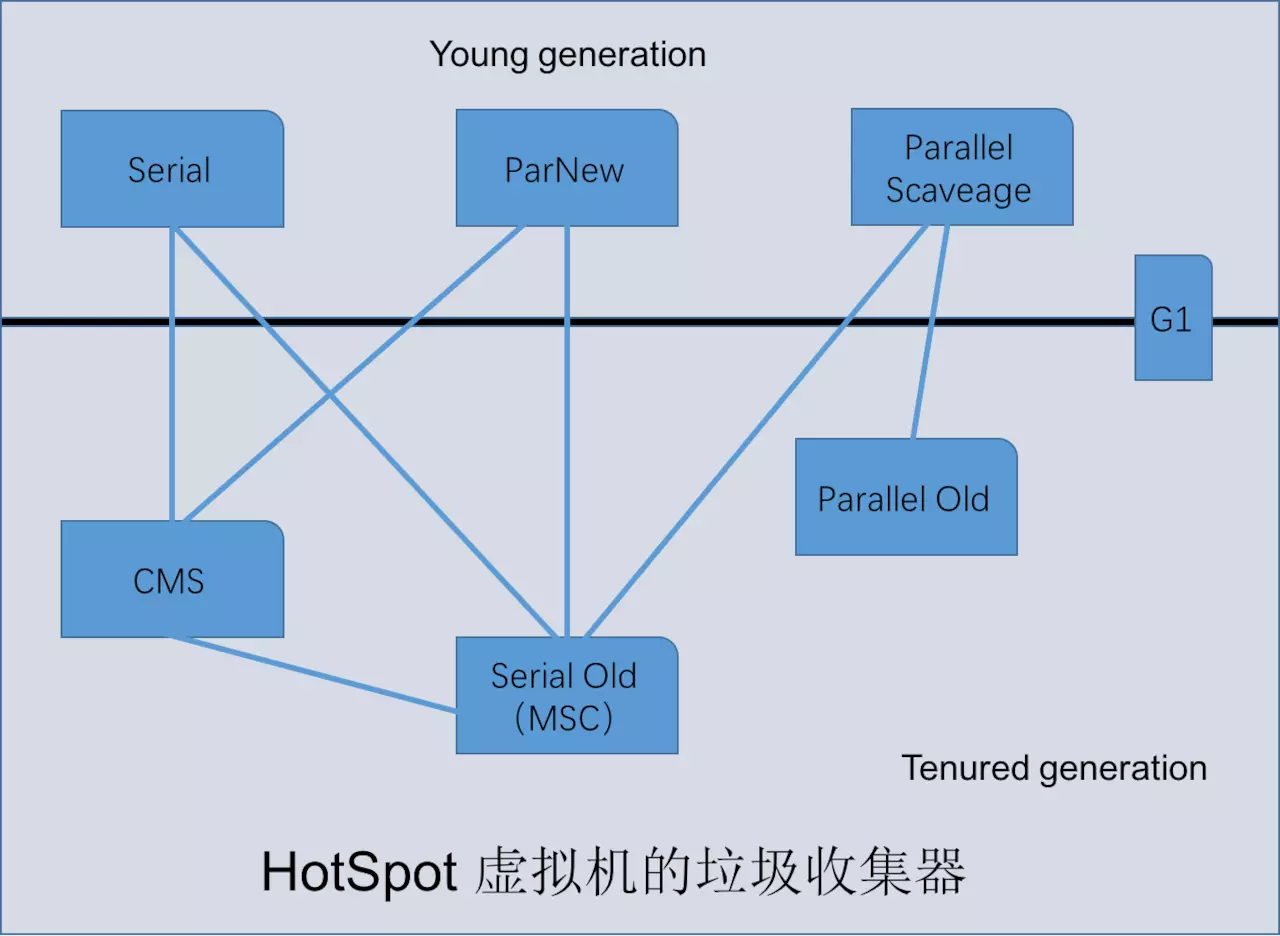
2、类别
2.1 Serial 收集器
这是一个单线程收集器。意味着它只会使用一个 CPU 或一条收集线程去完成收集工作,并且在进行垃圾回收时必须暂停其它所有的工作线程直到收集结束。
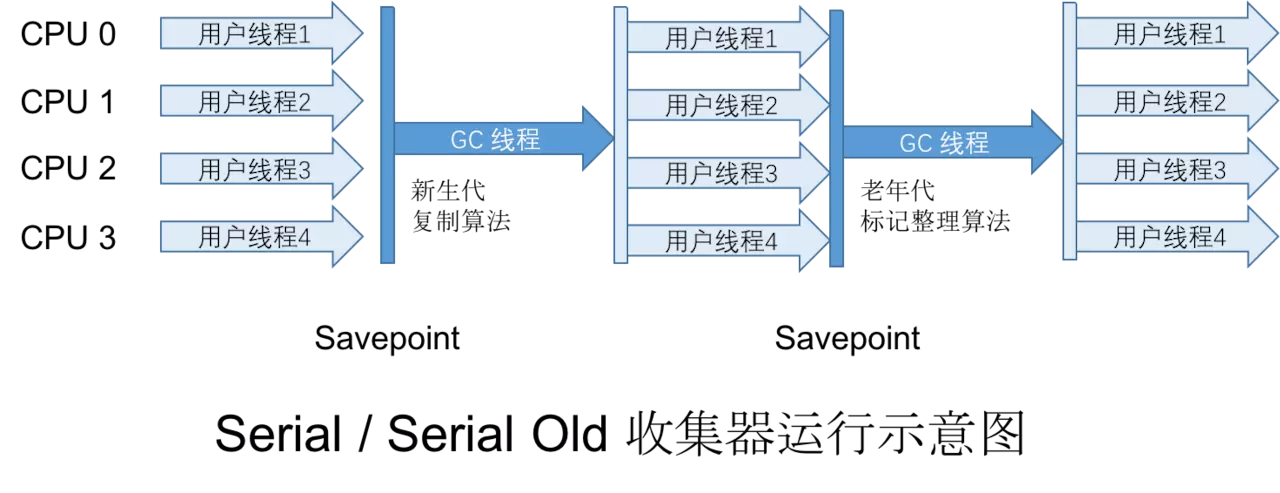
虽然说Serial收集器在收集的时候需要暂停其它所有工作的线程,但到现在仍然被使用。对比其它的有点就是:简单而高效。在用户的桌面应用场景中,分配给虚拟机管理的内存一般来说不会很大,回收几十兆的新生代,停顿的时间很短,完全可以接受。
2.2 ParNew收集器
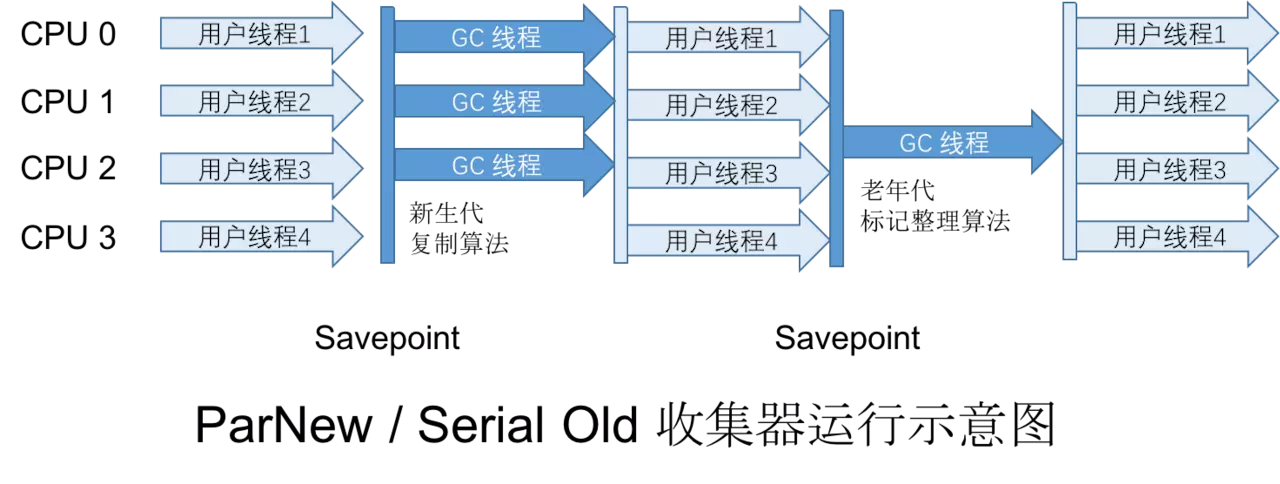
ParNew收集器可以认为是Serial收集器的多线程版本。
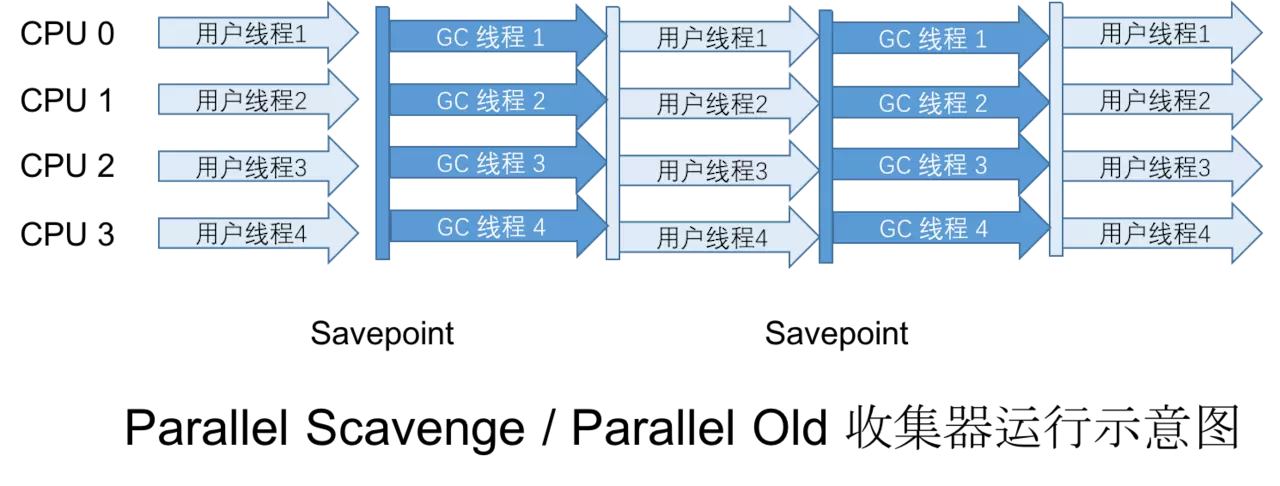
2.3 Parallel Scavenge收集器
这是一个新生代收集器,也是使用复制算法实现,同时也是并行的多线程收集器。
CMS 等收集器的关注点是尽可能地缩短垃圾收集时用户线程所停顿的时间,而 Parallel Scavenge 收集器的目的是达到一个可控制的吞吐量(Throughput = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间))。也就是说:如果虚拟机总共运行了100分钟,其中垃圾回收花掉1分钟,吞吐量就是99%
停顿时间越短就越适合需要与用户交互的程序,而吞吐量则可以最高效率的利用CPU时间,尽快完成运算任务。适合后台运算,没有太多交互的任务。
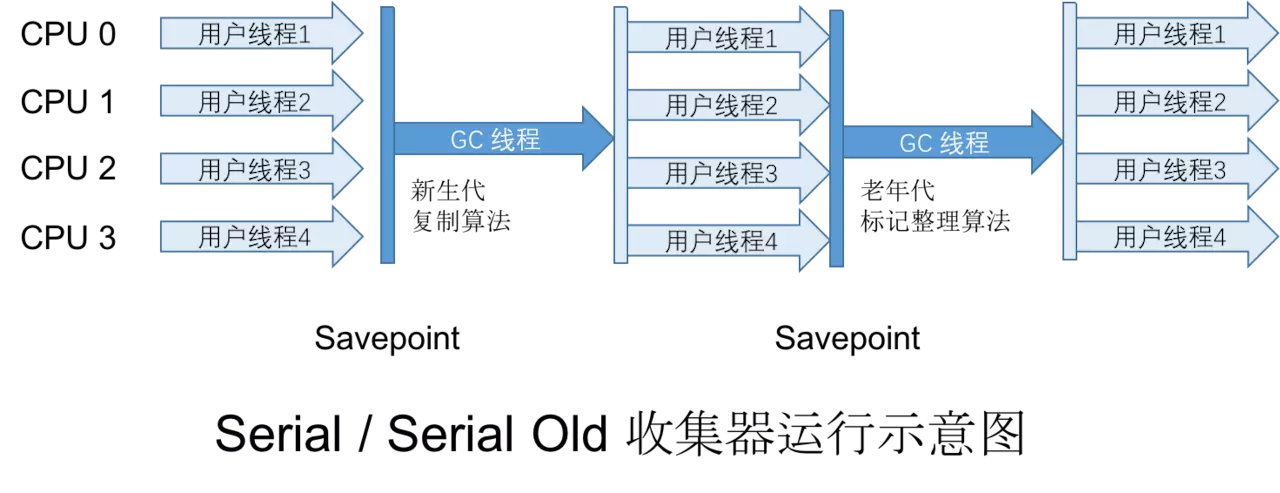
2.4 Serial Old 收集器
收集器的老年代版本,单线程,使用 标记-整理算法。
2.5 Parallel Old 收集器
Parallel Old 是 Parallel Scavenge 收集器的老年代版本。多线程,使用 标记-整理算法。
2.6 CMS收集器
CMS收集器是一种以获取最短回收停顿时间为目标的收集器。适用于希望系统停顿时间端,给用户良好体验的引用。CMS收集器是基于 “标记-清除”算法实现的,它的运作过程分为四个步骤:
- 初始标记(CMS initial mark):标记 GC Roots 能直接关联到的对象
- 并发标记(CMS concurrent mark):进行 GC Roots Tracing
- 重新标记(CMS remark):修正并发标记期间的变动部分
- 并发清除(CMS concurrent sweep)
其中初始标记、重新标记这两个步骤仍然需要 暂停其它工作线程。初始标记只是标记GCRoot能关联的对象,过程很快。并发标记阶段进行GCRoot Tracing 时间较长,重新标记这个阶段停顿的时间比初始标记阶段的时间要长,但远比并发标记阶段的停顿时间要短。
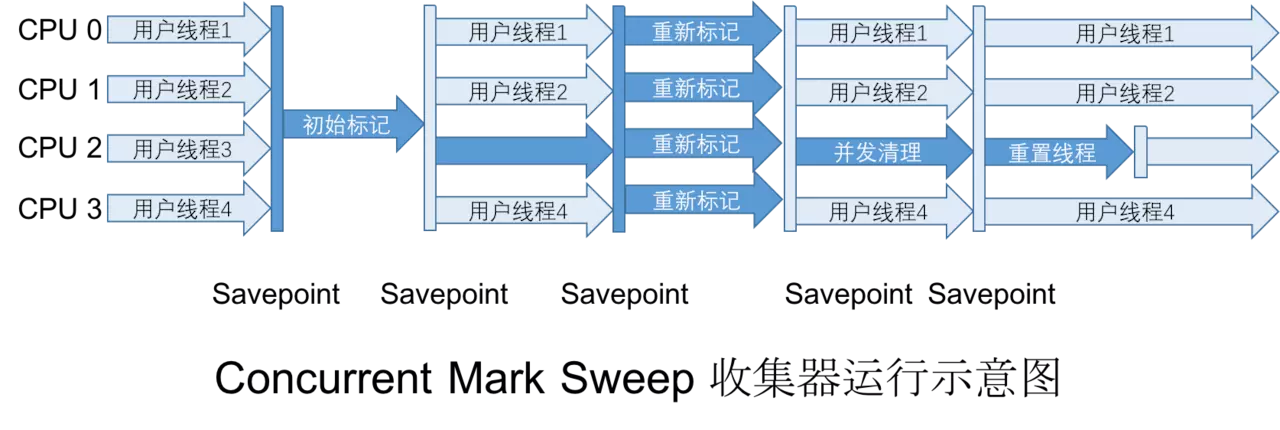
CMS的主要优点是:并发收集、低停顿。
缺点:对 CPU 资源敏感、无法收集浮动垃圾、标记-清除 算法带来的空间碎片。
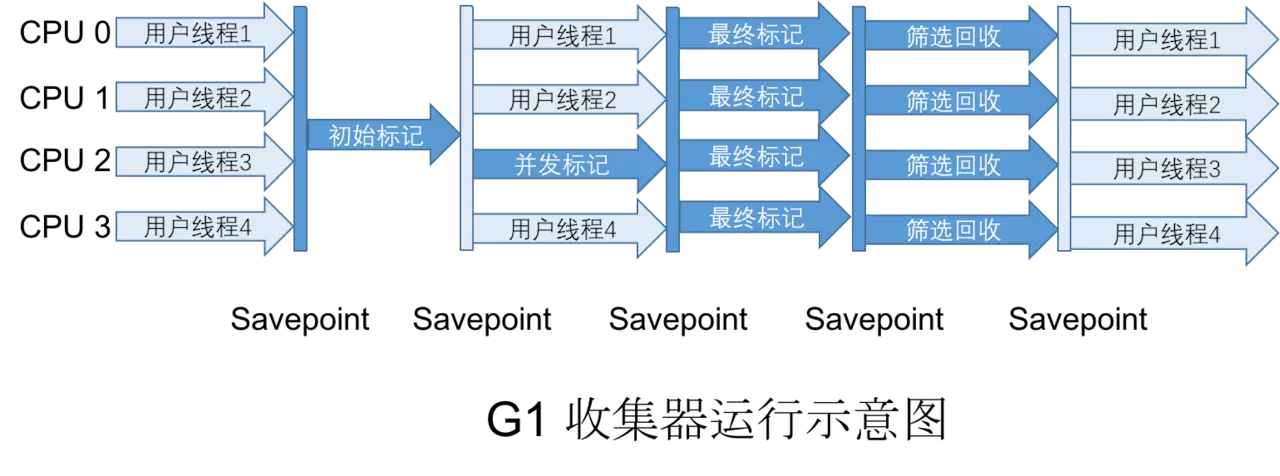
2.7 G1收集器
G1收集器是垃圾收集器理论进一步发展的产物,一是基于 “标记-整理” 算法实现的收集器。也就是说不会产生空间碎片。二是它可以非常精确的控制停顿。
G1收集器可以实现在基本不牺牲吞吐量的前提下完成低提顿的内存回收,因为它极力避免全区域的垃圾回收,G1将整个Java堆(新生代、老年代)划分为多个大小固定的独立区域,并且跟踪这些区域里面的垃圾堆积程度,在后台维护一个优先列表,每次根据允许的收集时间,优先回收垃圾最多的区域。
运作步骤:
- 初始标记(Initial Marking)
- 并发标记(Concurrent Marking)
- 最终标记(Final Marking)
- 筛选回收(Live Data Counting and Evacuation)

若有收获,就点个赞吧
0 人点赞
