一、概念
ShardingSphere 采用一套自动化的执行引擎,负责将路由和改写完成之后的真实 SQL 安全且高效发送到 底层数据源执行。它不是简单地将 SQL 通过 JDBC 直接发送至数据源执行;也并非直接将执行请求放入 线程池去并发执行。它更关注平衡数据源连接创建以及内存占用所产生的消耗,以及最大限度地合理利 用并发等问题。执行引擎的目标是自动化的平衡资源控制与执行效率。
二、连接模式(官方描述)
从资源控制的角度看,业务方访问数据库的连接数量应当有所限制。它能够有效地防止某一业务操作过 多的占用资源,从而将数据库连接的资源耗尽,以致于影响其他业务的正常访问。特别是在一个数据库实 例中存在较多分表的情况下,一条不包含分片键的逻辑 SQL 将产生落在同库不同表的大量真实 SQL ,如 果每条真实 SQL 都占用一个独立的连接,那么一次查询无疑将会占用过多的资源。
从执行效率的角度看,为每个分片查询维持一个独立的数据库连接,可以更加有效的利用多线程来提升 执行效率。为每个数据库连接开启独立的线程,可以将 I/O 所产生的消耗并行处理。为每个分片维持一个独立的数据库连接,还能够避免过早的将查询结果数据加载至内存。独立的数据库连接,能够持有查询 结果集游标位置的引用,在需要获取相应数据时移动游标即可。
以结果集游标下移进行结果归并的方式,称之为流式归并,它无需将结果数据全数加载至内存,可以有效 的节省内存资源,进而减少垃圾回收的频次。当无法保证每个分片查询持有一个独立数据库连接时,则 需要在复用该数据库连接获取下一张分表的查询结果集之前,将当前的查询结果集全数加载至内存。因 此,即使可以采用流式归并,在此场景下也将退化为内存归并。
一方面是对数据库连接资源的控制保护,一方面是采用更优的归并模式达到对中间件内存资源的节省,如 何处理好两者之间的关系,是 ShardingSphere 执行引擎需要解决的问题。
如果一条 SQL 在经 过 ShardingSphere 的分片后,需要操作某数据库实例下的 200 张表。那么,是选择创建 200 个连接并行 执行,还是选择创建一个连接串行执行呢?效率与资源控制又应该如何抉择呢? 针对上述场景,ShardingSphere 提供了一种解决思路。它提出了连接模式(Connection Mode)的概念, 将其划分为内存限制模式(MEMORY_STRICTLY)和连接限制模式(CONNECTION_STRICTLY)这两种 类型。
1 内存限制模式
此模式的前提是,ShardingSphere 对一次操作所耗费的数据库连接数量不做限制。如果实际执行的 SQL 需要对某数据库实例中的 200 张表做操作,则对每张表创建一个新的数据库连接,并通过多线程的 方式并发处理,以达成执行效率最大化。并且在 SQL 满足条件情况下,优先选择流式归并,以防止出现 内存溢出或避免频繁垃圾回收情况。
2 连接限制模式
此模式的前提是,ShardingSphere 严格控制对一次操作所耗费的数据库连接数量。如果实际执行的 SQL 需要对某数据库实例中的 200 张表做操作,那么只会创建唯一的数据库连接,并对其 200 张表串行 处理。如果一次操作中的分片散落在不同的数据库,仍然采用多线程处理对不同库的操作,但每个库的 每次操作仍然只创建一个唯一的数据库连接。这样即可以防止对一次请求对数据库连接占用过多所带来 的问题。该模式始终选择内存归并。
3 总结
1 内存限制模式适用于 OLAP 操作,可以通过放宽对数据库连接的限制提升系统吞吐量;
2 连接限制模式适 用于 OLTP 操作,OLTP 通常带有分片键,会路由到单一的分片,因此严格控制数据库连接,以保证在线 系统数据库资源能够被更多的应用所使用,是明智的选择。
三、自动化执行引擎
自动化执行引擎将连接模式的选择粒度细化至每一次 SQL 的操作。针对每次 SQL 请求,自动化执行引擎 都将根据其路由结果,进行实时的演算和权衡,并自主地采用恰当的连接模式执行,以达到资源控制和 效率的最优平衡。针对自动化的执行引擎,用户只需配置 maxConnectionSizePerQuery 即可,该参数表 示一次查询时每个数据库所允许使用的最大连接数。
1 准备阶段
1 此阶段用于准备执行的数据。它分为结果集分组和执行单元创建两个步骤
2 结果集分组是实现内化连接模式概念的关键。执行引擎根据 maxConnectionSizePerQuery 配置项,结合 当前路由结果,选择恰当的连接模式。
准备步骤
1 将 SQL 的路由结果按照数据源的名称进行分组。
2 获得每个数据库实例在 maxConnectionSizePerQuery 的允许范围内,每 个连接需要执行的 SQL 路由结果组,并计算出本次请求的最优连接模式。

3 连接模式计算公式
4 连接创建说明
在 maxConnectionSizePerQuery 允许的范围内,当一个连接需要执行的请求数量大于 1 时,意味着当前 的数据库连接无法持有相应的数据结果集,则必须采用内存归并;反之,当一个连接需要执行的请求数 量等于 1 时,意味着当前的数据库连接可以持有相应的数据结果集,则可以采用流式归并。
每一次的连接模式的选择,是针对每一个物理数据库的。也就是说,在同一次查询中,如果路由至一个 以上的数据库,每个数据库的连接模式不一定一样,它们可能是混合存在的形态。
通过上一步骤获得的路由分组结果创建执行的单元。当数据源使用数据库连接池等控制数据库连接数量 的技术时,在获取数据库连接时,如果不妥善处理并发,则有一定几率发生死锁。在多个请求相互等待 对方释放数据库连接资源时,将会产生饥饿等待,造成交叉的死锁问题。

假设一次查询需要在某一数据源上获取两个数据库连接,并路由至同一个数据库的两个分表 查询。则有可能出现查询 A 已获取到该数据源的 1 个数据库连接,并等待获取另一个数据库连接;而查 询 B 也已经在该数据源上获取到的一个数据库连接,并同样等待另一个数据库连接的获取。如果数据库 连接池的允许最大连接数是 2,那么这 2 个查询请求将永久的等待下去。下图描绘了死锁的情况。
5 避免死锁
ShardingSphere 为了避免死锁的出现,在获取数据库连接时进行了同步处理。它在创建执行单元时,以 原子性的方式一次性获取本次 SQL 请求所需的全部数据库连接,杜绝了每次查询请求获取到部分资源的 可能。由于对数据库的操作非常频繁,每次获取数据库连接时时都进行锁定,会降低 ShardingSphere 的 并发。
ShardingSphere 在这里进行了 2 点优化:
1)避免锁定一次性只需要获取 1 个数据库连接的操作。因为每次仅需要获取 1 个连接,则不会发生两 个请求相互等待的场景,无需锁定。对于大部分 OLTP 的操作,都是使用分片键路由至唯一的数据 节点,这会使得系统变为完全无锁的状态,进一步提升了并发效率。除了路由至单分片的情况,读 写分离也在此范畴之内。
2)仅针对内存限制模式时才进行资源锁定。在使用连接限制模式时,所有的查询结果集将在装载至内 存之后释放掉数据库连接资源,因此不会产生死锁等待的问题。
2 执行阶段
1 分组执行
分组执行将准备执行阶段生成的执行单元分组下发至底层并发执行引擎,并针对执行过程中的每个关键 步骤发送事件。
如:执行开始事件、执行成功事件以及执行失败事件。执行引擎仅关注事件的发送,它并 不关心事件的订阅者。ShardingSphere 的其他模块,如:分布式事务、调用链路追踪等,会订阅感兴趣 的事件,并进行相应的处理。
2 归并结果集生成
ShardingSphere 通过在执行准备阶段的获取的连接模式,生成内存归并结果集或流式归并结果集,并将 其传递至结果归并引擎。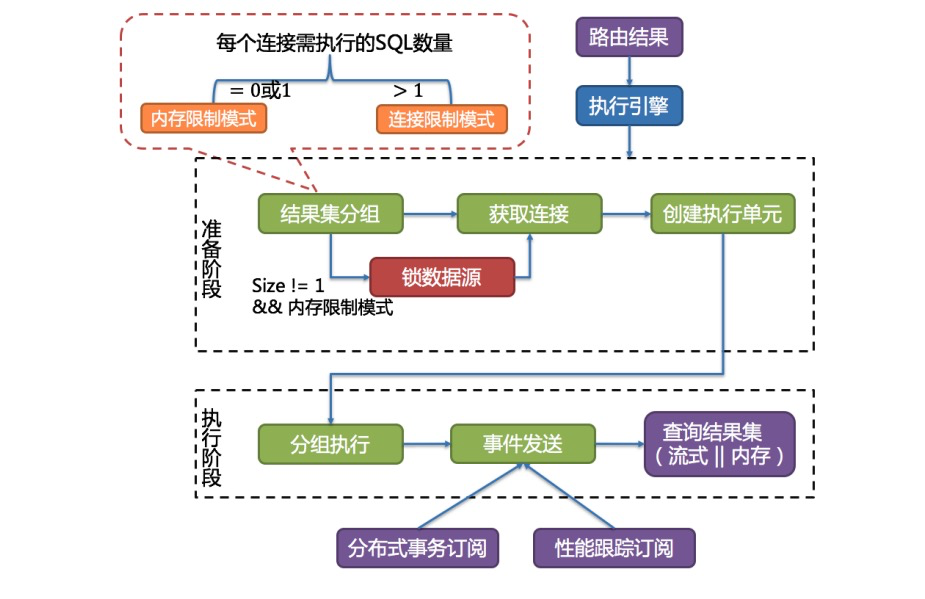

3 执行流程
以查询为demo


若有收获,就点个赞吧
0 人点赞
