1.提出问题
1.如何解决复杂的统计搜索? 数据聚合: 解决复杂的统计搜索问题
2.如何友好的搜索? 自动补全: 当用户在搜索框内输入相关的 词条 拼音 首字母 实时给与对应的提示
3.如何跟mysql数据同步? 数据同步: 当mysql中的数据发生改变时,将改变后的数据同步到ES中,保证ES中的数据与Mysql中的同步 集群: 解决单点故障,提高可用性
1.数据聚合
:::info 聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算
聚合常见的有三类:
- 桶(Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
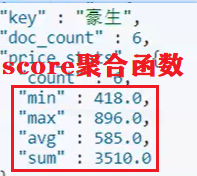
- 度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等 (聚合函数)
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
管道(pipeline)聚合:其它聚合的结果为基础做聚合(桶内再分桶) :::
注意:参加聚合的字段必须是keyword、日期、数值、布尔类型(可分词的字段不能参与聚合(会影响聚合的结果))!!!!!!!!!
2.Kibana浏览器-聚合分桶
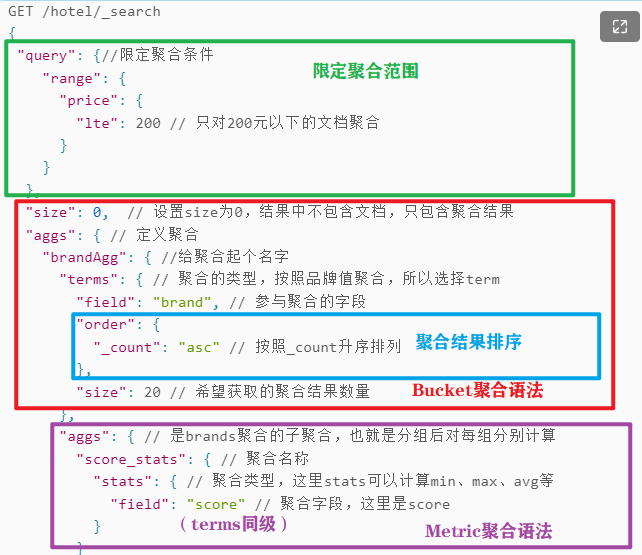
GET /hotel/_search{"query": {//限定聚合条件"range": {"price": {"gte": 200,"lte": 300 // 200以上300以下}}},"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果"aggs": { // 定义聚合"brandAgg": { //给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brand", // 参与聚合的字段"order": {"_count": "asc" // 按照_count升序排列 桶内数据数量},"order": {"price_status.avg": "desc"// 按照平均分降序排序"size": 20 // 希望获取的聚合结果数量},//....可以多个分桶//terms同级"aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算(度量)"score_stats": { // 聚合名称 如score_avg score_max 底下写_后面的"stats": { // 聚合类型,这里stats可以计算min、max、avg等"field": "score" // 聚合字段,这里是score}}}}}}
说明:
桶内分桶(管道)
3.java代码-聚合
注意:需要导包和初始化连接
1.聚合查询
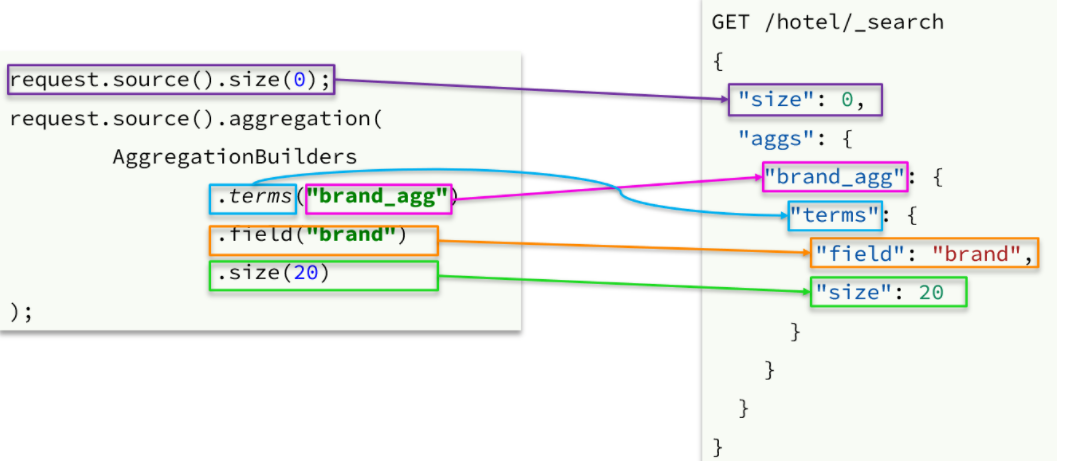
```java // 聚合查询—aggregation @Test public void aggregation() throws IOException { // 1.创建 SearchRequest 对象 SearchRequest request = new SearchRequest(“hotel”); // 2.组织 DSL 参数 request.source().size(0);// 设置size为0,结果中不包含文档,只包含聚合结果 // 定义聚合 request.source().aggregation(AggregationBuilders
.terms("brand_agg")// 聚合名称 获取聚合数据时使用 .field("brand")// 参与聚合的字段 .order(BucketOrder.aggregation("_count",true)) // 按照_count升序排列 .size(20));// 显示聚合数量/*桶中桶或度量写法 request.source().aggregation(AggregationBuilders
.terms("brand_agg")// 聚合名称 获取聚合数据时使用 .field("brand")// 参与聚合的字段 .order(BucketOrder.aggregation("_count",true)) // 按照_count升序排列 .size(20).subAggregation(AggregationBuilders .terms("brand_agg")// 聚合名称 获取聚合数据时使用 .field("brand")// 参与聚合的字段 .order(BucketOrder.aggregation("_count",true)) // 按照_count升序排列 .size(20)));// 显示聚合数量*/

// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应结果
handleResponse(response);
}
<a name="OQ92u"></a>
### 说明:
<a name="Y54tJ"></a>
## 2.响应结果解析
```java
// 响应结果解析
private void handleResponse(SearchResponse response) {
// 4.解析聚合响应结果
Aggregations aggregations = response.getAggregations();
// 根据名称获得聚合结果 Aggregatinns接口方法太少
Terms brandTerms = aggregations.get("brand_agg");
// 获取桶
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
// 遍历
for (Terms.Bucket bucket : buckets) {
// 获取品牌信息
String brandName = bucket.getKeyAsString();
long count = bucket.getDocCount();
System.out.println(brandName+":"+count);
}
}
说明:
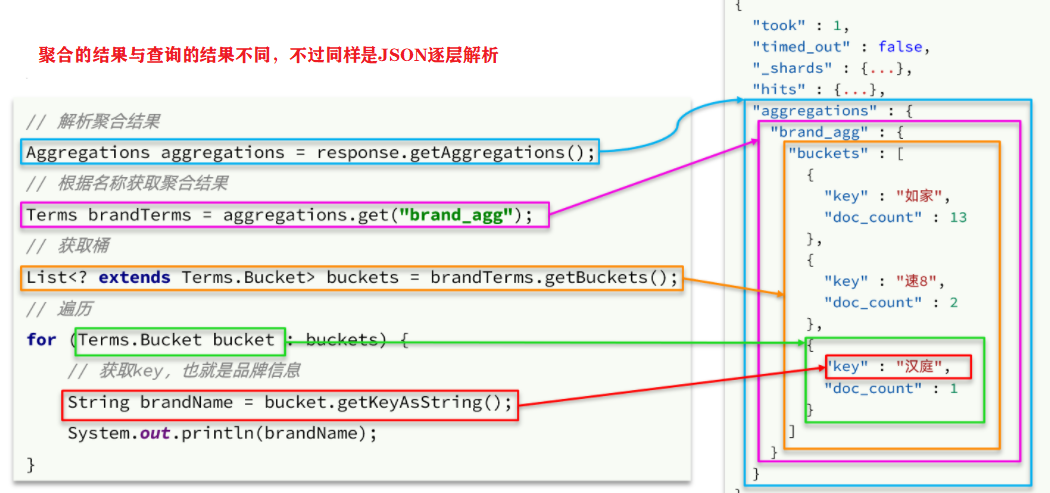
数据聚合样例
4.自动补全
1.拼音分词器(根据字母做补全)
拼音分词插件
:::info
安装方式与IK分词器一样,分三步:
①解压
②上传到虚拟机中,elasticsearch的plugin目录
③重启elasticsearch
④测试
:::
使用

2.自定义分词器(了解)
:::info elasticsearch中分词器(analyzer)的组成包含三部分
- character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等 :::
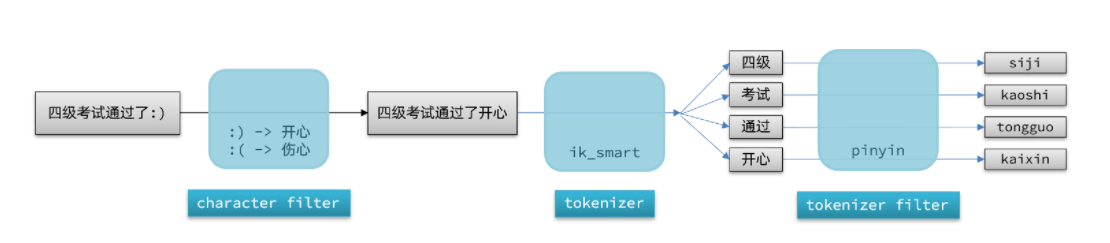
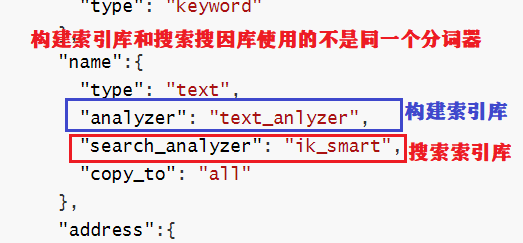
PUT /test { "settings": { "analysis": { "analyzer": { // 自定义分词器 "my_analyzer": { // 分词器名称 "tokenizer": "ik_max_word", "filter": "py" } }, "filter": { // 自定义tokenizer filter "py": { // 过滤器名称 "type": "pinyin", // 过滤器类型,这里是pinyin "keep_full_pinyin": false, "keep_joined_full_pinyin": true, "keep_original": true, "limit_first_letter_length": 16, "remove_duplicated_term": true, "none_chinese_pinyin_tokenize": false } } } }, "mappings": { "properties": { "name": { "type": "text", "analyzer": "my_analyzer", "search_analyzer": "ik_smart" } } } }注意:只能在创建自定义分词器的索引库里使用
配置
注意:构建索引库和搜索搜因库使用的不是同一个分词器
3.Kibana浏览器-自动补全查询
:::info elasticsearch提供了Completion Suggester查询来实现自动补全功能 :::
注意:为了提高补全查询的效率,对于文档中字段的类型有一些约束
:::success
参与补全查询的字段必须是completion类型。
字段的内容一般是用来补全的多个词条形成的数组。 :::
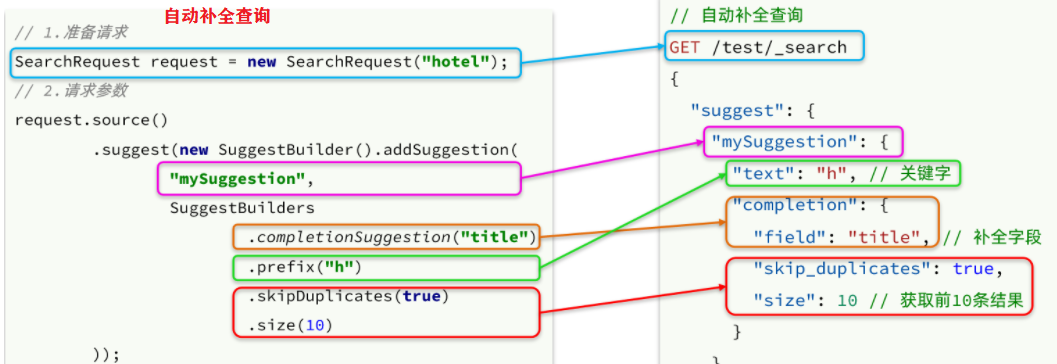
# 自动补全查询 GET /test/_search { "suggest": { "title_suggest": { "text": "n", // 关键字 "completion": { "field": "title", // 补全查询的字段 "skip_duplicates": true, // 跳过重复的 "size": 10 // 获取前10条结果 } } } }4.java代码-自动补全查询
注意:需要添加实体类自动补全字段,将需要自动补全的字段放到集合中
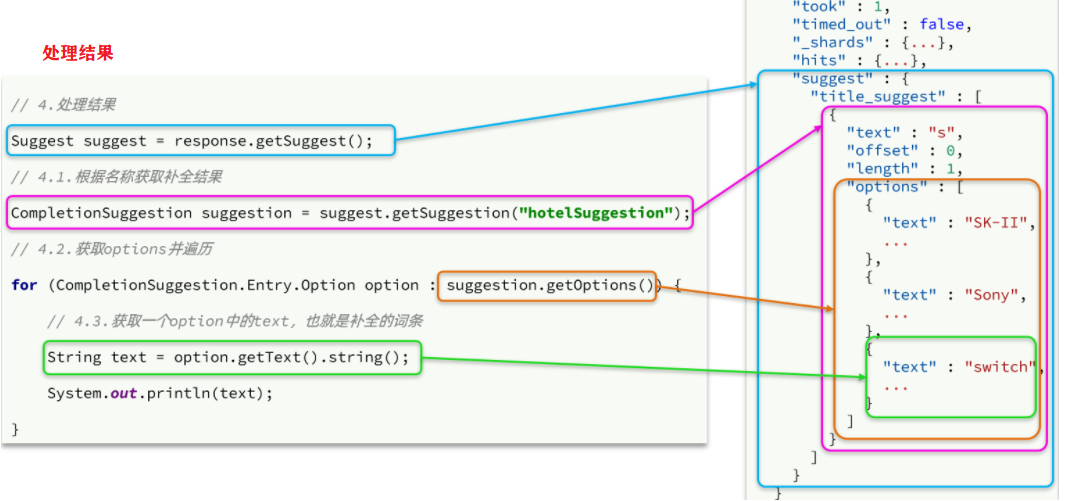
@Test public void test01() throws IOException { //1.创建请求语义对象 SearchRequest request = new SearchRequest("hotel"); //2.自动补全 request.source().suggest( new SuggestBuilder().addSuggestion( "mySuggestion",//用于解析 SuggestBuilders.completionSuggestion("suggestion")//补全的字段 .prefix("s")//关键字 .skipDuplicates(true).size(10))//获取前10条 ); //3.发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); //4.解析结果 Suggest suggest = response.getSuggest(); CompletionSuggestion suggestion = suggest.getSuggestion("mySuggestion"); // 遍历自动补全结果 for (CompletionSuggestion.Entry.Option option : suggestion.getOptions()) { System.out.println(option.getText().string()); } }说明:
搜索自动补全样例
5.数据同步
:::info 常见的数据同步方案有三种:
同步调用
- 优点:实现简单,粗暴
- 缺点:业务耦合度高
异步通知
- 优点:低耦合,实现难度一般
- 缺点:依赖mq的可靠性
监听binlog
- 优点:完全解除服务间耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高
:::
1.同步调用

2.异步通知
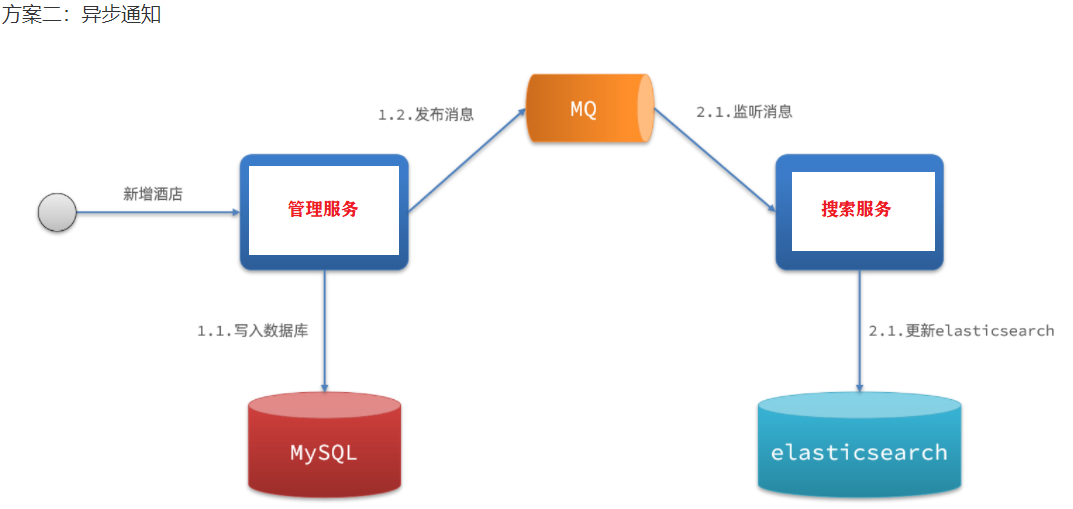
3.监听binlog
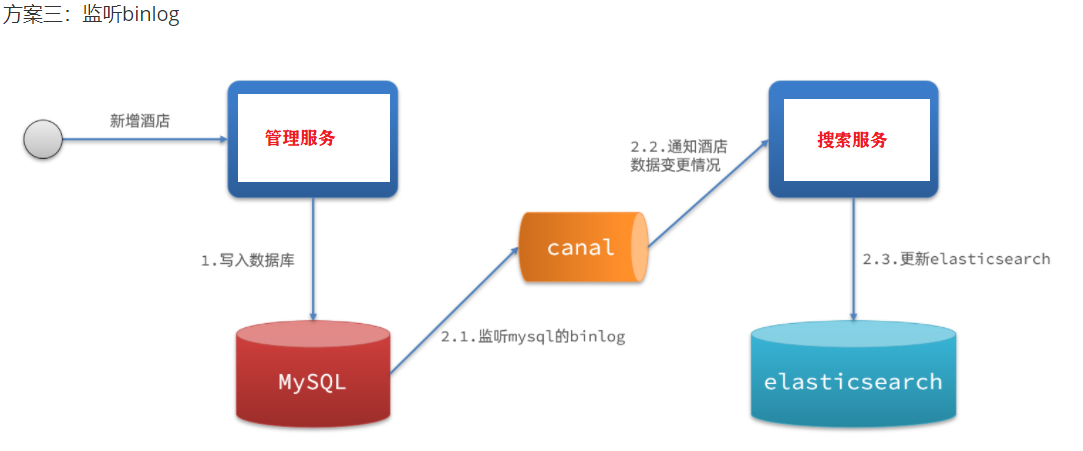
实现数据同步样例(异步通知MQ)
6.ES集群
注意:

:::info 单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。
- 海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点(node-集群下的一台服务器)
单点故障问题:将分片数据在不同节点备份(replica ) :::
1.ES集群相关概念
:::info
集群(cluster):一组拥有共同的 cluster name 的 节点。
- 节点(node) :集群中的一个 Elasticearch 实例
分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
- 主分片(Primary shard):相对于副本分片的定义。
- 副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样。
:::
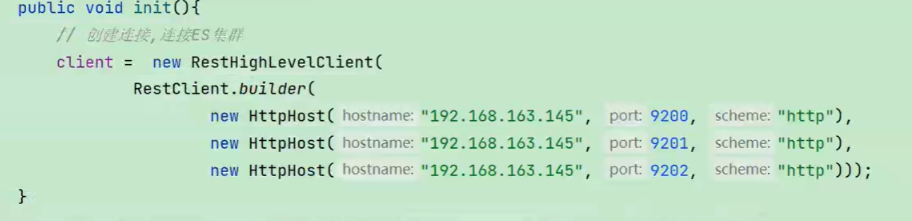
2.搭建ES集群
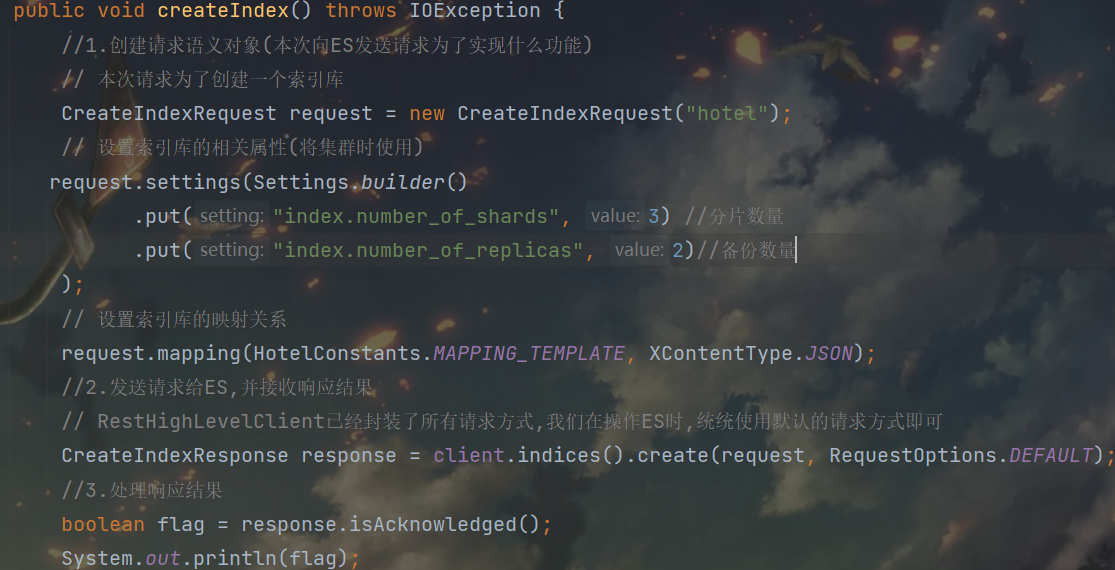
集群搭建java代码连接es集群并创建索引库
3.集群脑裂问题
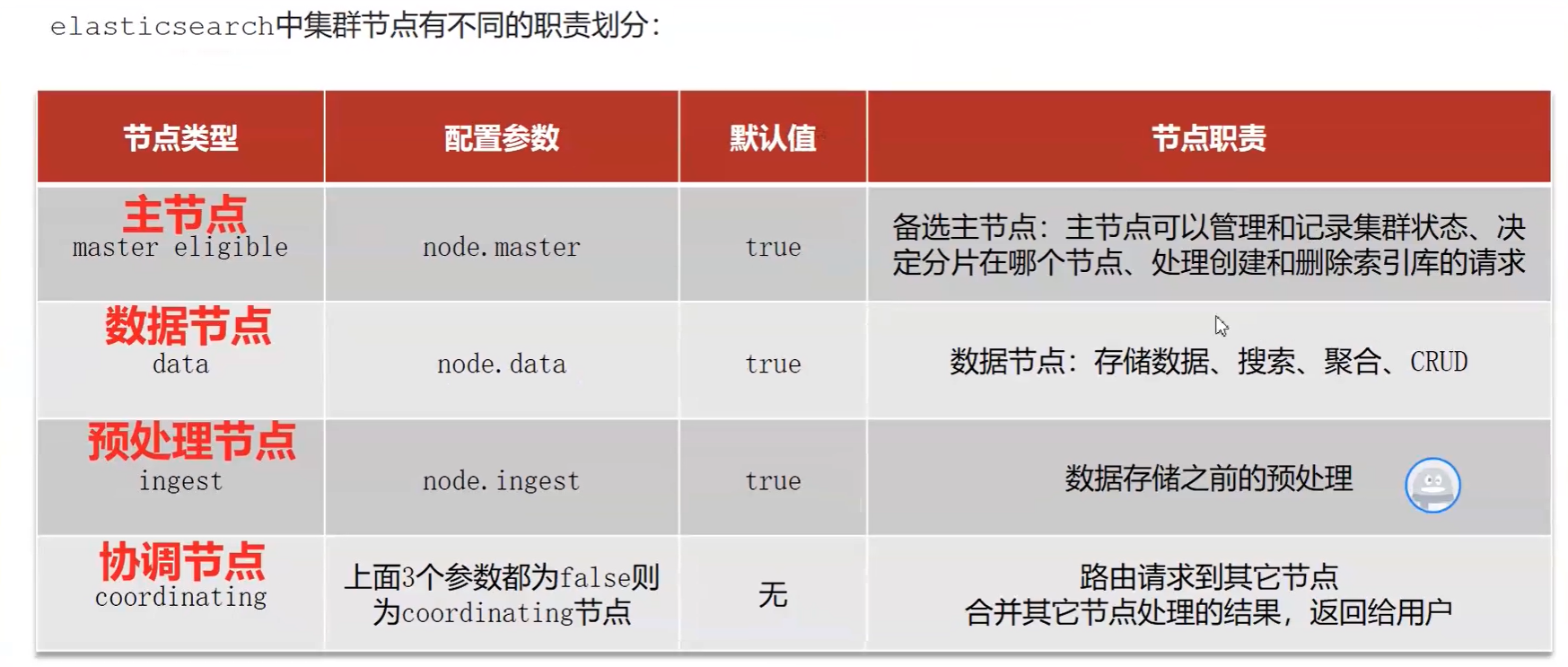
1.集群职责划分
:::info 真实的集群一定要将集群职责分离:
master节点:对CPU要求高,但是内存要求低
- data节点:对CPU和内存要求都高
- coordinating节点:对网络带宽、CPU要求高
默认情况下,集群中的任何一个节点都同时具备上述四种角色。
:::
2.脑裂问题
:::info 脑裂是因为集群中的节点失联导致的。
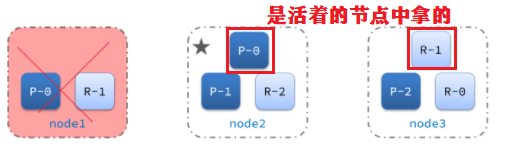
例如一个集群中,node1主节点与node2和node3节点失联,
此时,node2和node3认为node1宕机,就会重新选主,
当node3当选后,集群继续对外提供服务,node2和node3自成集群,node1自成集群,两个集群数据不同步,出现数据差异。
当网络恢复后,因为集群中有两个master节点,集群状态的不一致,出现脑裂的情况
解决脑裂的方案:要求选票超过 ( eligible节点数量 + 1 )/ 2 才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题
:::
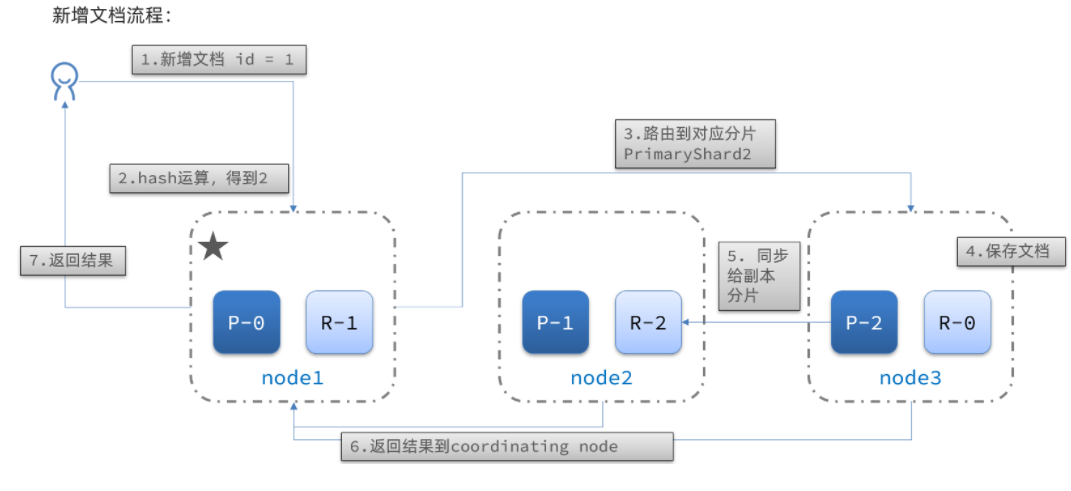
4.集群分布式存储算法&流程

说明:
:::success
- _routing默认是文档的id
算法与分片数量有关,因此索引库一旦创建,分片数量不能修改! :::
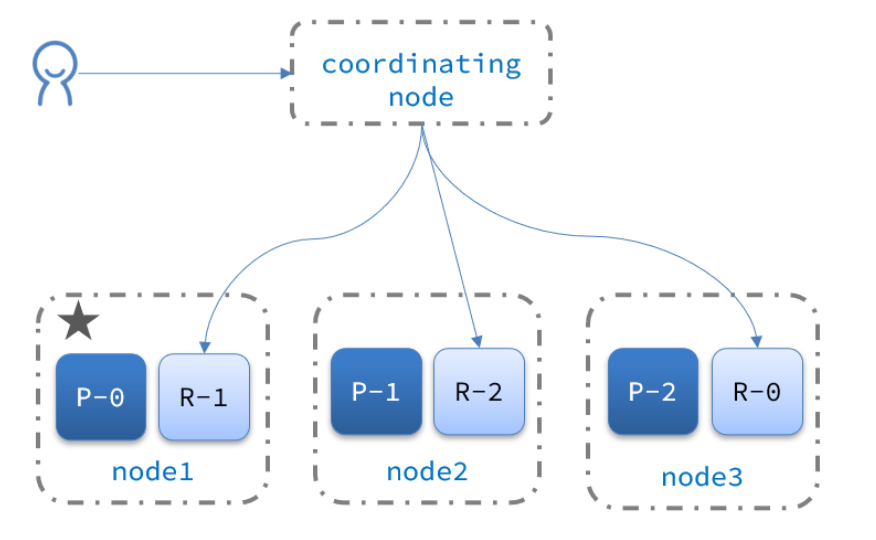
5.集群分布式查询
:::info elasticsearch的查询分成两个阶段:
scatter phase:分散阶段,coordinating node会把请求分发到每一个分片
- gather phase:聚集阶段,coordinating node汇总data node的搜索结果,并处理为最终结果集返回给用户
:::
6.集群故障转移
 :::info
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据安全,这个叫做故障转移。
:::
:::info
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据安全,这个叫做故障转移。
:::
7.集群自动伸缩
:::info 伸:添加节点
缩:减少节点
Elasticsearch索引实际上只是一个或多个物理分片的逻辑分组,其中每个碎片实际上是一个独立的索引。通过在多个分片之间的索引中分配文档,并在多个节点之间分配这些分片,Elasticsearch可以确保冗余,这既可以防止硬件故障,又可以在将节点添加到集群中时提高查询能力。随着集群的增长(或收缩),Elasticsearch会自动迁移分片以重新平衡集群。 :::1.数据聚合
:::tips 聚合分桶:用来对文档做分组
- TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
聚合度量: 聚合:用以计算一些值,比如:最大值、最小值、平均值等
管道: 聚合:其它聚合的结果为基础做聚合
注意:参加聚合的字段必须是keyword、日期、数值、布尔类型
可分次的字段不能参与聚合(会影响聚合的结果) :::2.数据聚合DSL格式
【Bucket聚合语法】
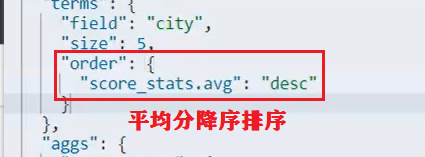
GET /hotel/_search { "size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果 "aggs": { // 定义聚合 "brandAgg": { //给聚合起个名字 "terms": { // 聚合的类型,按照品牌值聚合,所以选择term "field": "brand", // 参与聚合的字段 "size": 20 // 希望获取的聚合结果数量 } } } } (2)聚合结果排序 GET /hotel/_search { "size": 0, "aggs": { "brandAgg": { "terms": { "field": "brand", "order": { "_count": "asc" // 按照_count升序排列 }, "size": 20 } } } } (3)限定聚合范围 GET /hotel/_search { "query": { "range": { "price": { "lte": 200 // 只对200元以下的文档聚合 } } }, "size": 0, "aggs": { "brandAgg": { "terms": { "field": "brand", "size": 20 } } } }【Metric聚合语法】
GET /hotel/_search { "size": 0, "aggs": { "brandAgg": { "terms": { "field": "brand", "size": 20 }, "aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算 "score_stats": { // 聚合名称 "stats": { // 聚合类型,这里stats可以计算min、max、avg等 "field": "score" // 聚合字段,这里是score } } } } } }【管道聚合语法】
GET /hotel/_search { "size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果 "aggs": { // 定义聚合 "brandAgg": { //给聚合起个名字 "terms": { // 聚合的类型,按照品牌值聚合,所以选择term "field": "brand", // 参与聚合的字段 "size": 20 // 希望获取的聚合结果数量 }, "aggs": { "terms": { "filed": "city", "size": 5 } } } } }3.RestAPI实现数据聚合
//分桶数据 private void bucketData(RequestParams params, SearchRequest request, String brand, String star, String city) { //品牌分桶 buildBasicQuery(request, params); request.source().size(0); request.source().aggregation(AggregationBuilders .terms(brand) .field("brand") .size(20)); //星级分桶 request.source().size(0); request.source().aggregation(AggregationBuilders .terms(star) .field("starName") .size(20)); //城市分桶 request.source().size(0); request.source().aggregation(AggregationBuilders .terms(city) .field("city") .size(5)); } /** * 根据关键字搜索酒店信息 * * @param params 请求参数对象,包含用户输入的关键字 * @return 酒店文档列表 */ @Override public Map<String, List<String>> searchALLFilter(RequestParams params) { //创建一个map集合进行数据封装 Map<String, List<String>> map = new HashMap<>(); ; try { //创建请求对象 SearchRequest request = new SearchRequest("hotel"); String brand = "brandAgges"; String star = "starAgges"; String city = "cityAgges"; //分桶数据 bucketData(params, request, brand, star, city); //发送请求到ES SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4.解析响应 // 获取所有的聚合结果 Aggregations aggregations = response.getAggregations(); //获取桶中的数据 List<String> brandList = handResponse(aggregations, brand); List<String> starList = handResponse(aggregations, star); List<String> cityList = handResponse(aggregations, city); map.put("brand", brandList); map.put("starName", starList); map.put("city", cityList); } catch (Exception e) { e.printStackTrace(); } return map; } //分桶响应结果处理 private List<String> handResponse(Aggregations aggregations, String brand) { // 根据聚合名称获取指定的聚合结果 Terms aggregation = aggregations.get(brand); // 获取桶数据 List<String> list = new ArrayList<>(); for (Terms.Bucket bucket : aggregation.getBuckets()) { String json = bucket.getKeyAsString(); list.add(json); } return list; }4.什么是自动补全?
当用户在搜索框输入字符时,下拉框自动显示信息

若有收获,就点个赞吧
0 人点赞
