面试知识点总结

- 布局
- 弹性布局(display:flex;)属性详解
- Flexbox 是 flexible box 的简称(注:意思是“灵活的盒子容器”),是 CSS3 引入的新的布局模式。它决定了元素如何在页面上排列,使它们能在不同的屏幕尺寸和设备下可预测地展现出来。
- 它之所以被称为 Flexbox ,是因为它能够扩展和收缩 flex 容器内的元素,以最大限度地填充可用空间。与以前布局方式(如 table 布局和浮动元素内嵌块元素)相比,Flexbox 是一个更强大的方式:
- 在不同方向排列元素
- 重新排列元素的显示顺序
- 更改元素的对齐方式
- 动态地将元素装入容器
- 一、基本概念
- 采用 Flex 布局的元素,称为 Flex 容器(flex container),简称”容器”。它的所有子元素自动成为容器成员,称为 Flex 项目(flex item),简称”项目”。

1. 在 Flexbox 模型中,有三个核心概念:
1. – flex 项(注:也称 flex 子元素),需要布局的元素
1. – flex 容器,其包含 flex 项
1. – 排列方向(direction),这决定了 flex 项的布局方向
1. 二、容器属性

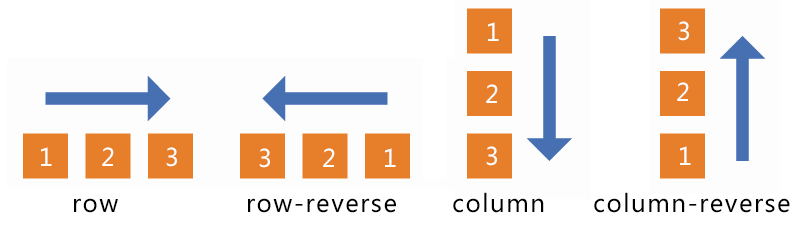
1. 2.1 flex-direction:
1. row(默认值):主轴为水平方向,起点在左端。
1. row-reverse:主轴为水平方向,起点在右端。
1. column:主轴为垂直方向,起点在上沿。
1. column-reverse:主轴为垂直方向,起点在下沿。
1. 2.2 flex-wrap:
1. nowrap(默认):不换行。
1. wrap:换行,第一行在上方。
1. wrap-reverse:换行,第一行在下方。
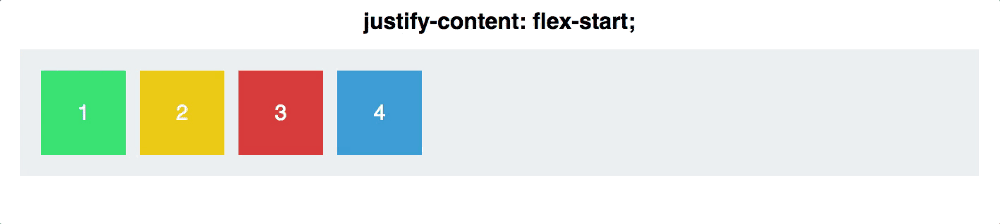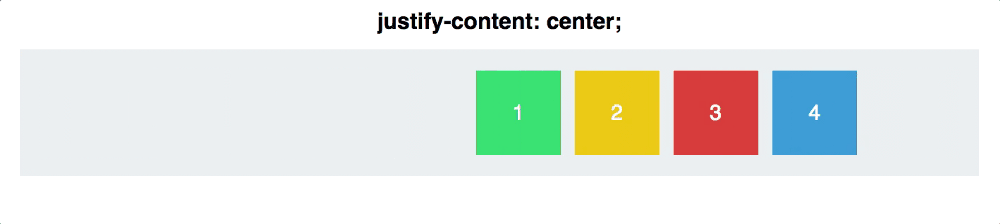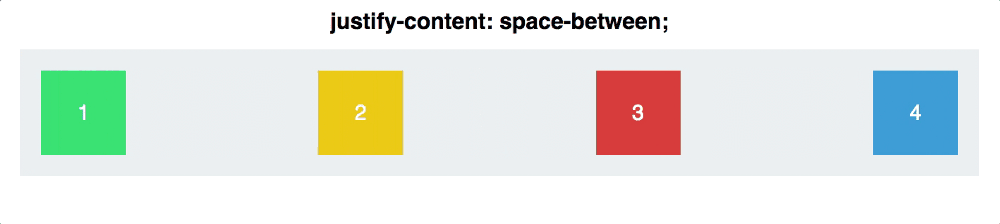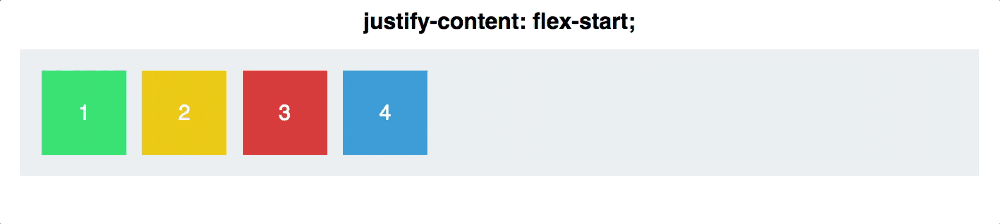
2. 2.3 justify-content:
1. flex-start(默认值):左对齐
1. flex-end:右对齐
1. center: 居中
1. space-between:两端对齐,项目之间的间隔都相等。
1. space-around:每个项目两侧的间隔相等。所以,项目之间的间隔比项目与边框的间隔大一倍。
1. 2.4 align-items:
1. flex-start:交叉轴的起点对齐。
1. flex-end:交叉轴的终点对齐。
1. center:交叉轴的中点对齐。
1. baseline: 项目的第一行文字的基线对齐。
1. stretch(默认值):如果项目未设置高度或设为auto,将占满整个容器的高度。

1. 2.5 align-content:
1. 定义了多根轴线的对齐方式,如果项目只有一根轴线,那么该属性将不起作用
1. flex-start:与交叉轴的起点对齐。
1. flex-end:与交叉轴的终点对齐。
1. center:与交叉轴的中点对齐。
1. space-between:与交叉轴两端对齐,轴线之间的间隔平均分布。
1. space-around:每根轴线两侧的间隔都相等。所以,轴线之间的间隔比轴线与边框的间隔大一倍。
1. stretch(默认值):轴线占满整个交叉轴。

1. 结合 justify-content和align-items,看看在 flex-direction 两个不同属性值的作用下,轴心有什么不同:

1. 三、项目属性
1. 3.1 order属性
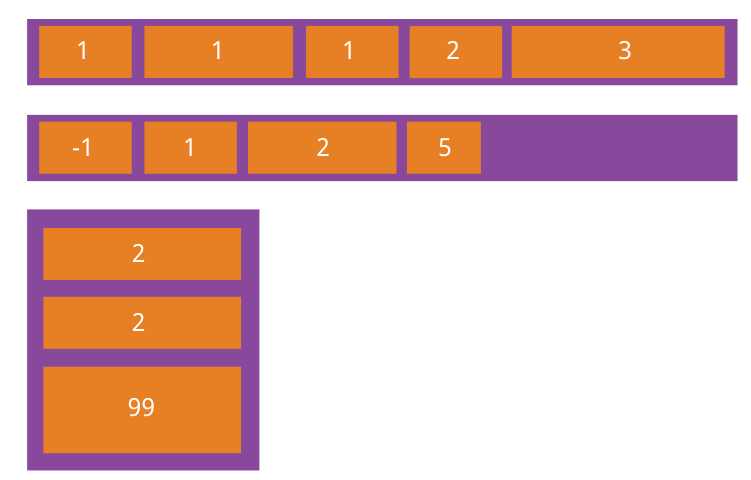
1. 3.2 flex-grow属性
1. flex-grow属性定义项目的放大比例,默认为0,即如果存在剩余空间,也不放大。
1. 如果所有项目的flex-grow属性都为1,则它们将等分剩余空间(如果有的话)。如果一个项目的flex-grow属性为2,其他项目都为1,则前者占据的剩余空间将比其他项多一倍。
1. 3.3 flex-shrink属性
1. flex-shrink属性定义了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。

.item { flex-shrink:
1. 如果所有项目的flex-shrink属性都为1,当空间不足时,都将等比例缩小。如果一个项目的flex-shrink属性为0,其他项目都为1,则空间不足时,前者不缩小。
1. 负值对该属性无效。
1. 3.4 align-self属性
1. align-self属性允许单个项目有与其他项目不一样的对齐方式,可覆盖align-items属性。默认值为auto,表示继承父元素的align-items属性,如果没有父元素,则等同于stretch。

1. .item { align-self: auto | flex-start | flex-end | center | baseline | stretch;}
1. **弹性布局默认不改变项目的宽度,但是它默认改变项目的高度。如果项目没有显式指定高度,就将占据容器的所有高度。**
- display:table的用法
- 为什么不用table系表格元素呢?
- 1、用DIV+CSS编写出来的文件k数比用table写出来的要小,不信你在页面中放1000个table和1000个div比比看哪个文件大
- 2、table必须在页面完全加载后才显示,没有加载完毕前,table为一片空白,也就是说,需要页面完毕才显示,而div是逐行显示,不需要页面完全加载完毕,就可以一边加载一边显示
- 3、非表格内容用table来装,不符合标签语义化要求,不利于SEO
- 4、table的嵌套性太多,用DIV代码会比较简洁
- 但是有的项目中又需要类似表格的布局怎么办呢?可以用display:table来解决
- display:table系列几乎是和table系的元素相对应的,请看下表:
- 为什么不用table系表格元素呢?

1. 目前display:table的应用场景也是比较广泛的,Google地图在搜索路线时,左侧的路线详情就是用的display:table来实现的。
1. 1.div模拟表格:
<!DOCTYPE html>
1. 2.**让块级标签实现行内效果,即浮动至同一横轴,并实现等高效果**
1. table表格中的单元格最大的特点之一就是同一行列表元素都等高。所以,很多时候,我们需要等高布局的时候,就可以借助display:table-cell属性。说到table-cell的布局,不得不说一下“匿名表格元素创建规则”:
1. CSS2.1表格模型中的元素,可能不会全部包含在除HTML之外的文档语言中。这时,那些“丢失”的元素会被模拟出来,从而使得表格模型能够正常工作。所有的表格元素将会自动在自身周围生成所需的匿名table对象,使其符合table/inline-table、table-row、table- cell的三层嵌套关系。
1. 举个例子吧,如果我们为元素使用“display:table-cell;”属性,而不将其父容器设置为“display:table-row;”属性,浏览器会默认创建出一个表格行,就好像文档中真的存在一个被声明的表格行一样。
<!DOCTYPE html>
1. 上例中div.row可以不要,效果一样
1. 3.结合vetical-align实现块级元素垂直居中
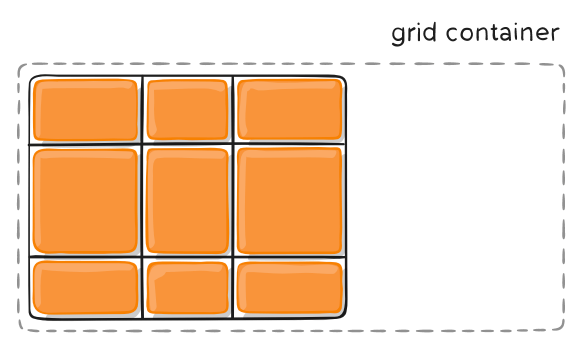
- Grid 网格布局
- 一、概述
- 网格布局(Grid)是最强大的 CSS 布局方案。
- 它将网页划分成一个个网格,可以任意组合不同的网格,做出各种各样的布局。以前,只能通过复杂的 CSS 框架达到的效果,现在浏览器内置了。
- 一、概述

1. 上图这样的布局,就是 Grid 布局的拿手好戏。
1. Grid 布局与 [Flex 布局](https://www.ruanyifeng.com/blog/2015/07/flex-grammar.html)有一定的相似性,都可以指定容器内部多个项目的位置。但是,它们也存在重大区别。
1. Flex 布局是轴线布局,只能指定"项目"针对轴线的位置,可以看作是**一维布局**。Grid 布局则是将容器划分成"行"和"列",产生单元格,然后指定"项目所在"的单元格,可以看作是**二维布局**。Grid 布局远比 Flex 布局强大。
1. 二、基本概念
1. 学习 Grid 布局之前,需要了解一些基本概念。
1. 2.1 容器和项目
1. 采用网格布局的区域,称为"容器"(container)。容器内部采用网格定位的子元素,称为"项目"(item)。
1
2
3
1. 上面代码中,最外层的<div>元素就是容器,内层的三个<div>元素就是项目。
1. 注意:项目只能是容器的顶层子元素,不包含项目的子元素,比如上面代码的<p>元素就不是项目。Grid 布局只对项目生效。
1. 2.2 行和列
1. 容器里面的水平区域称为"行"(row),垂直区域称为"列"(column)。

1. 上图中,水平的深色区域就是"行",垂直的深色区域就是"列"。
1. 2.3 单元格
1. 行和列的交叉区域,称为"单元格"(cell)。
1. 正常情况下,n行和m列会产生n x m个单元格。比如,3行3列会产生9个单元格。
2. 2.4 网格线
1. 划分网格的线,称为"网格线"(grid line)。水平网格线划分出行,垂直网格线划分出列。
1. 正常情况下,n行有n + 1根水平网格线,m列有m + 1根垂直网格线,比如三行就有四根水平网格线。

1. 上图是一个 4 x 4 的网格,共有5根水平网格线和5根垂直网格线。
1. 三、容器属性
1. Grid 布局的属性分成两类。一类定义在容器上面,称为容器属性;另一类定义在项目上面,称为项目属性。这部分先介绍容器属性。
1. 3.1 display 属性
1. display: grid指定一个容器采用网格布局。

div { display: grid; }
1. 上图是display: grid的[效果](https://jsbin.com/guvivum/edit?html,css,output)。
1. 默认情况下,容器元素都是块级元素,但也可以设成行内元素。
div { display: inline-grid; }
1. 上面代码指定div是一个行内元素,该元素内部采用网格布局。

1. 上图是display: inline-grid的[效果](https://jsbin.com/qatitav/edit?html,css,output)。
1. 注意,设为网格布局以后,容器子元素(项目)的float、display: inline-block、display: table-cell、vertical-align和column-*等设置都将失效。
1. 3.2 grid-template-columns 属性 , grid-template-rows 属性
1. 容器指定了网格布局以后,接着就要划分行和列。grid-template-columns属性定义每一列的列宽,grid-template-rows属性定义每一行的行高。
.container { display: grid; grid-template-columns: 100px 100px 100px; grid-template-rows: 100px 100px 100px; }
1. [上面代码](https://jsbin.com/qiginur/edit?css,output)指定了一个三行三列的网格,列宽和行高都是100px。

1. 除了使用绝对单位,也可以使用百分比。
.container { display: grid; grid-template-columns: 33.33% 33.33% 33.33%; grid-template-rows: 33.33% 33.33% 33.33%; }
1. **(1)repeat()**
有时候,重复写同样的值非常麻烦,尤其网格很多时。这时,可以使用repeat()函数,简化重复的值。上面的代码用repeat()改写如下。
.container { display: grid; grid-template-columns: repeat(3, 33.33%); grid-template-rows: repeat(3, 33.33%); }
repeat()接受两个参数,第一个参数是重复的次数(上例是3),第二个参数是所要重复的值。
repeat()重复某种模式也是可以的。
grid-template-columns: repeat(2, 100px 20px 80px);
上面代码定义了6列,第一列和第四列的宽度为100px,第二列和第五列为20px,第三列和第六列为80px。
1. **(2)auto-fill 关键字**
有时,单元格的大小是固定的,但是容器的大小不确定。如果希望每一行(或每一列)容纳尽可能多的单元格,这时可以使用auto-fill关键字表示自动填充。
.container { display: grid; grid-template-columns: repeat(auto-fill, 100px); }
上面代码表示每列宽度100px,然后自动填充,直到容器不能放置更多的列。
1. **(3)fr 关键字**
为了方便表示比例关系,网格布局提供了fr关键字(fraction 的缩写,意为”片段”)。如果两列的宽度分别为1fr和2fr,就表示后者是前者的两倍。
.container { display: grid; grid-template-columns: 1fr 1fr; }
上面代码表示两个相同宽度的列。
fr可以与绝对长度的单位结合使用,这时会非常方便。
.container { display: grid; grid-template-columns: 150px 1fr 2fr; }
上面代码表示,第一列的宽度为150像素,第二列的宽度是第三列的一半。
1. **(4)minmax()**
minmax()函数产生一个长度范围,表示长度就在这个范围之中。它接受两个参数,分别为最小值和最大值。
grid-template-columns: 1fr 1fr minmax(100px, 1fr);
上面代码中,minmax(100px, 1fr)表示列宽不小于100px,不大于1fr。
1. **(5)auto 关键字**
auto关键字表示由浏览器自己决定长度。
grid-template-columns: 100px auto 100px;
上面代码中,第二列的宽度,基本上等于该列单元格的最大宽度,除非单元格内容设置了min-width,且这个值大于最大宽度。
1. **(6)网格线的名称**
grid-template-columns属性和grid-template-rows属性里面,还可以使用方括号,指定每一根网格线的名字,方便以后的引用。
.container { display: grid; grid-template-columns: [c1] 100px [c2] 100px [c3] auto [c4]; grid-template-rows: [r1] 100px [r2] 100px [r3] auto [r4]; }
上面代码指定网格布局为3行 x 3列,因此有4根垂直网格线和4根水平网格线。方括号里面依次是这八根线的名字。
网格布局允许同一根线有多个名字,比如[fifth-line row-5]。
1. **(7)布局实例**
grid-template-columns属性对于网页布局非常有用。两栏式布局只需要一行代码。
.wrapper { display: grid; grid-template-columns: 70% 30%; }
上面代码将左边栏设为70%,右边栏设为30%。
传统的十二网格布局,写起来也很容易。
grid-template-columns: repeat(12, 1fr);
1. 3.3 grid-row-gap 属性 , grid-column-gap 属性, grid-gap 属性
1. grid-row-gap属性设置行与行的间隔(行间距),grid-column-gap属性设置列与列的间隔(列间距)。
.container { grid-row-gap: 20px; grid-column-gap: 20px; }
1. [上面代码](https://jsbin.com/mezufab/edit?css,output)中,grid-row-gap用于设置行间距,grid-column-gap用于设置列间距。

1. grid-gap属性是grid-column-gap和grid-row-gap的合并简写形式,语法如下。
grid-gap:
1. 因此,上面一段 CSS 代码等同于下面的代码。
.container { grid-gap: 20px 20px; }
1. 如果grid-gap省略了第二个值,浏览器认为第二个值等于第一个值。
1. 根据最新标准,上面三个属性名的grid-前缀已经删除,grid-column-gap和grid-row-gap写成column-gap和row-gap,grid-gap写成gap。
1. 3.4 grid-template-areas 属性
1. 网格布局允许指定"区域"(area),一个区域由单个或多个单元格组成。grid-template-areas属性用于定义区域。
.container { display: grid; grid-template-columns: 100px 100px 100px; grid-template-rows: 100px 100px 100px; grid-template-areas: ‘a b c’ ‘d e f’ ‘g h i’; }
1. 上面代码先划分出9个单元格,然后将其定名为a到i的九个区域,分别对应这九个单元格。
1. 多个单元格合并成一个区域的写法如下。
grid-template-areas: ‘a a a’ ‘b b b’ ‘c c c’;
1. 上面代码将9个单元格分成a、b、c三个区域。
1. 下面是一个布局实例。
grid-template-areas: “header header header” “main main sidebar” “footer footer footer”;
1. 上面代码中,顶部是页眉区域header,底部是页脚区域footer,中间部分则为main和sidebar。
1. 如果某些区域不需要利用,则使用"点"(.)表示。
grid-template-areas: ‘a . c’ ‘d . f’ ‘g . i’;
1. 上面代码中,中间一列为点,表示没有用到该单元格,或者该单元格不属于任何区域。
1. 注意,区域的命名会影响到网格线。每个区域的起始网格线,会自动命名为区域名-start,终止网格线自动命名为区域名-end。
1. 比如,区域名为header,则起始位置的水平网格线和垂直网格线叫做header-start,终止位置的水平网格线和垂直网格线叫做header-end。
1. 3.5 grid-auto-flow 属性
1. 划分网格以后,容器的子元素会按照顺序,自动放置在每一个网格。默认的放置顺序是"先行后列",即先填满第一行,再开始放入第二行,即下图数字的顺序。

1. ·这个顺序由grid-auto-flow属性决定,默认值是row,即"先行后列"。也可以将它设成column,变成"先列后行"。
grid-auto-flow: column;
1. [上面代码](https://jsbin.com/xutokec/edit?css,output)设置了column以后,放置顺序就变成了下图。

1. grid-auto-flow属性除了设置成row和column,还可以设成row dense和column dense。这两个值主要用于,某些项目指定位置以后,剩下的项目怎么自动放置。
1. [下面的例子](https://jsbin.com/wapejok/edit?css,output)让1号项目和2号项目各占据两个单元格,然后在默认的grid-auto-flow: row情况下,会产生下面这样的布局。

1. 上图中,1号项目后面的位置是空的,这是因为3号项目默认跟着2号项目,所以会排在2号项目后面。
1. 现在修改设置,设为row dense,表示"先行后列",并且尽可能紧密填满,尽量不出现空格。
grid-auto-flow: row dense;
1. [上面代码](https://jsbin.com/helewuy/edit?css,output)的效果如下。

1. 上图会先填满第一行,再填满第二行,所以3号项目就会紧跟在1号项目的后面。8号项目和9号项目就会排到第四行。
1. 如果将设置改为column dense,表示"先列后行",并且尽量填满空格。
grid-auto-flow: column dense;
1. [上面代码](https://jsbin.com/pupoduc/1/edit?html,css,output)的效果如下。

1. 上图会先填满第一列,再填满第2列,所以3号项目在第一列,4号项目在第二列。8号项目和9号项目被挤到了第四列。
1. 3.6 justify-items 属性, align-items 属性,place-items 属性
1. justify-items属性设置单元格内容的水平位置(左中右),align-items属性设置单元格内容的垂直位置(上中下)。
.container { justify-items: start | end | center | stretch; align-items: start | end | center | stretch; }
1. 这两个属性的写法完全相同,都可以取下面这些值。
start:对齐单元格的起始边缘。
end:对齐单元格的结束边缘。
center:单元格内部居中。
stretch:拉伸,占满单元格的整个宽度(默认值)。
1. .container { justify-items: start;}
1. [上面代码](https://jsbin.com/gijeqej/edit?css,output)表示,单元格的内容左对齐,效果如下图。

1. .container { align-items: start;}
1. [上面代码](https://jsbin.com/tecawur/edit?css,output)表示,单元格的内容头部对齐,效果如下图。

1. place-items属性是align-items属性和justify-items属性的合并简写形式。
place-items:
1. 下面是一个例子。
place-items: start end;
1. 如果省略第二个值,则浏览器认为与第一个值相等。
1. 3.7 justify-content 属性,align-content 属性,place-content 属性
1. justify-content属性是整个内容区域在容器里面的水平位置(左中右),align-content属性是整个内容区域的垂直位置(上中下)。
.container { justify-content: start | end | center | stretch | space-around | space-between | space-evenly; align-content: start | end | center | stretch | space-around | space-between | space-evenly; }
1. 这两个属性的写法完全相同,都可以取下面这些值。(下面的图都以justify-content属性为例,align-content属性的图完全一样,只是将水平方向改成垂直方向。)
1. start - 对齐容器的起始边框。
1. end - 对齐容器的结束边框。

1. center - 容器内部居中。

1. stretch - 项目大小没有指定时,拉伸占据整个网格容器。

1. space-around - 每个项目两侧的间隔相等。所以,项目之间的间隔比项目与容器边框的间隔大一倍。

1. space-between - 项目与项目的间隔相等,项目与容器边框之间没有间隔。

1. space-evenly - 项目与项目的间隔相等,项目与容器边框之间也是同样长度的间隔。

1. place-content属性是align-content属性和justify-content属性的合并简写形式。
place-content:
1. 下面是一个例子。
place-content: space-around space-evenly;
1. 如果省略第二个值,浏览器就会假定第二个值等于第一个值。
1. 3.8 grid-auto-columns 属性,grid-auto-rows 属性
1. 有时候,一些项目的指定位置,在现有网格的外部。比如网格只有3列,但是某一个项目指定在第5行。这时,浏览器会自动生成多余的网格,以便放置项目。
1. grid-auto-columns属性和grid-auto-rows属性用来设置,浏览器自动创建的多余网格的列宽和行高。它们的写法与grid-template-columns和grid-template-rows完全相同。如果不指定这两个属性,浏览器完全根据单元格内容的大小,决定新增网格的列宽和行高。
1. [下面的例子](https://jsbin.com/sayuric/edit?css,output)里面,划分好的网格是3行 x 3列,但是,8号项目指定在第4行,9号项目指定在第5行。
.container { display: grid; grid-template-columns: 100px 100px 100px; grid-template-rows: 100px 100px 100px; grid-auto-rows: 50px; }
1. 上面代码指定新增的行高统一为50px(原始的行高为100px)。

1. 3.9 grid-template 属性, grid 属性
1. grid-template属性是grid-template-columns、grid-template-rows和grid-template-areas这三个属性的合并简写形式。
1. grid属性是grid-template-rows、grid-template-columns、grid-template-areas、 grid-auto-rows、grid-auto-columns、grid-auto-flow这六个属性的合并简写形式。
1. 从易读易写的角度考虑,还是建议不要合并属性,所以这里就不详细介绍这两个属性了。
1. 四、项目属性
1. 下面这些属性定义在项目上面。
1. 4.1 grid-column-start 属性,grid-column-end 属性,grid-row-start 属性,grid-row-end 属性
1. 项目的位置是可以指定的,具体方法就是指定项目的四个边框,分别定位在哪根网格线。
grid-column-start属性:左边框所在的垂直网格线
grid-column-end属性:右边框所在的垂直网格线
grid-row-start属性:上边框所在的水平网格线
grid-row-end属性:下边框所在的水平网格线
1. .item-1 { grid-column-start: 2; grid-column-end: 4;}
1. [上面代码](https://jsbin.com/yukobuf/edit?css,output)指定,1号项目的左边框是第二根垂直网格线,右边框是第四根垂直网格线。

1. 上图中,只指定了1号项目的左右边框,没有指定上下边框,所以会采用默认位置,即上边框是第一根水平网格线,下边框是第二根水平网格线。
1. 除了1号项目以外,其他项目都没有指定位置,由浏览器自动布局,这时它们的位置由容器的grid-auto-flow属性决定,这个属性的默认值是row,因此会"先行后列"进行排列。读者可以把这个属性的值分别改成column、row dense和column dense,看看其他项目的位置发生了怎样的变化。
1. [下面的例子](https://jsbin.com/nagobey/edit?html,css,output)是指定四个边框位置的效果。

.item-1 { grid-column-start: 1; grid-column-end: 3; grid-row-start: 2; grid-row-end: 4; }
1. 这四个属性的值,除了指定为第几个网格线,还可以指定为网格线的名字。
.item-1 { grid-column-start: header-start; grid-column-end: header-end; }
1. 上面代码中,左边框和右边框的位置,都指定为网格线的名字。
1. 这四个属性的值还可以使用span关键字,表示"跨越",即左右边框(上下边框)之间跨越多少个网格。
.item-1 { grid-column-start: span 2;}
1. [上面代码](https://jsbin.com/hehumay/edit?html,css,output)表示,1号项目的左边框距离右边框跨越2个网格。

1. 这与[下面的代码](https://jsbin.com/mujihib/edit?html,css,output)效果完全一样。
.item-1 { grid-column-end: span 2;}
1. 使用这四个属性,如果产生了项目的重叠,则使用z-index属性指定项目的重叠顺序。
1. 4.2 grid-column 属性, grid-row 属性
1. grid-column属性是grid-column-start和grid-column-end的合并简写形式,grid-row属性是grid-row-start属性和grid-row-end的合并简写形式。
.item { grid-column:
1. 下面是一个例子。
.item-1 { grid-column: 1 / 3; grid-row: 1 / 2; } / 等同于 / .item-1 { grid-column-start: 1; grid-column-end: 3; grid-row-start: 1; grid-row-end: 2; }
1. 上面代码中,项目item-1占据第一行,从第一根列线到第三根列线。
1. 这两个属性之中,也可以使用span关键字,表示跨越多少个网格。
.item-1 { background: #b03532; grid-column: 1 / 3; grid-row: 1 / 3; } / 等同于 / .item-1 { background: #b03532; grid-column: 1 / span 2; grid-row: 1 / span 2; }
1. [上面代码](https://jsbin.com/volugow/edit?html,css,output)中,项目item-1占据的区域,包括第一行 + 第二行、第一列 + 第二列。

1. 斜杠以及后面的部分可以省略,默认跨越一个网格。
.item-1 { grid-column: 1; grid-row: 1;}
1. 上面代码中,项目item-1占据左上角第一个网格。
1. 4.3 grid-area 属性
1. grid-area属性指定项目放在哪一个区域。
1. .item-1 { grid-area: e;}
1. [上面代码](https://jsbin.com/qokexob/edit?css,output)中,1号项目位于e区域,效果如下图。

1. grid-area属性还可用作grid-row-start、grid-column-start、grid-row-end、grid-column-end的合并简写形式,直接指定项目的位置。
.item { grid-area:
1. 下面是一个[例子](https://jsbin.com/duyafez/edit?css,output)。
.item-1 { grid-area: 1 / 1 / 3 / 3;}
1. 4.4 justify-self 属性, align-self 属性,place-self 属性
1. justify-self属性设置单元格内容的水平位置(左中右),跟justify-items属性的用法完全一致,但只作用于单个项目。
1. align-self属性设置单元格内容的垂直位置(上中下),跟align-items属性的用法完全一致,也是只作用于单个项目。
1. .item { justify-self: start | end | center | stretch; align-self: start | end | center | stretch;}
1. 这两个属性都可以取下面四个值。
start:对齐单元格的起始边缘。
end:对齐单元格的结束边缘。
center:单元格内部居中。
stretch:拉伸,占满单元格的整个宽度(默认值)。
1. 下面是justify-self: start的例子。

.item-1 { justify-self: start;}
1. place-self属性是align-self属性和justify-self属性的合并简写形式。
place-self:
1. 下面是一个例子。
place-self: center center;
1. 如果省略第二个值,place-self属性会认为这两个值相等。
- 常规流
- 常规流布局
- 常规流、文档流、普通文档流、常规文档流
- 所有元素,默认情况下,都属于常规流布局
- 总体规则:块盒独占一行,行盒水平依次排列
- 包含块(containing block):每个盒子都有它的包含块,包含块决定了盒子的排列区域。
- 绝大部分情况下:盒子的包含块,为其父元素的内容盒
- 块盒
- 【水平方向】每个块盒的总宽度,必须刚好等于包含块的宽度
- 宽度的默认值是 auto
- margin 的取值也可以是 auto,默认值 0
- auto:将剩余空间吸收掉
- width 吸收能力强于 margin
- 若宽度、边框、内边距、外边距计算后,仍然有剩余空间,该剩余空间被 margin-right 全部吸收
- 在常规流中,块盒在其包含块中居中,可以定宽、然后左右 margin 设置为 auto。
- 每个块盒垂直方向上的 auto 值
- height:auto, 适应内容的高度
- margin:auto, 表示 0
- 百分比取值
- padding、宽、margin 可以取值为百分比
- 以上的所有百分比相对于包含块的宽度。
- 高度的百分比:
- 【水平方向】每个块盒的总宽度,必须刚好等于包含块的宽度
- 常规流布局
1)包含块的高度(是否)取决于子元素的高度,设置百分比无效
2)包含块的高度不取决于子元素的高度,百分比相对于父元素高度
1. 上下外边距的合并
1. 两个常规流块盒,上下外边距相邻,会进行合并。
1. 两个外边距取最大值。
1. 块级格式化上下文
1. 为使 overflow有效果,块级容器必须有一个指定的高度(height或者max-height)或者将white-space设置为nowrap。
- 浮动
- 浮动的基本特点
- 修改 float 属性值为:
- left:左浮动,元素靠上靠左
- right:右浮动,元素靠上靠右
- 默认值为 none
- 当一个元素浮动后,元素必定为块盒(更改 display 属性为 block)
- 浮动元素的包含块,和常规流一样,为父元素的内容盒
- 修改 float 属性值为:
- 盒子尺寸
- 宽度为 auto 时,适应内容宽度
- 高度为 auto 时,与常规流一致,适应内容的高度
- margin 为 auto,为 0.
- 边框、内边距、百分比设置与常规流一样
- 盒子排列
- 左浮动的盒子靠上靠左排列
- 右浮动的盒子考上靠右排列
- 1)【浮动盒子和常规流盒子】在包含块中排列时,常规流盒子放在前面,浮动盒子会避开常规流块盒(常规流在上)
- 2)常规流块盒放在后面,无视浮动盒子(常规流盒子在浮动盒子底部)
- 行盒在排列时,会避开浮动盒子
- 外边距合并不会发生
- 如果文字没有在行盒中,浏览器会自动生成一个行盒包裹文字,该行盒叫做匿名行盒。
- 高度坍塌
- 高度坍塌的根源:常规流盒子的自动高度,在计算时,不会考虑浮动盒子
- 清除浮动,涉及 css 属性:clear
- 默认值:none
- left:清除左浮动,该元素必须出现在前面所有左浮动盒子的下方
- right:清除右浮动,该元素必须出现在前面所有右浮动盒子的下方
- both:清除左右浮动,该元素必须出现在前面所有浮动盒子的下方
- 浮动(多个)排列原理:
- 浮动的基本特点
- 定位
- 定位:position
- 定位:手动控制元素在包含块中的精准位置
- 涉及的 CSS 属性:position
- position 属性
- 默认值:static,静态定位(不定位)
- relative:相对定位
- absolute:绝对定位
- fixed:固定定位
- 一个元素,只要 position 的取值不是 static,认为该元素是一个定位元素。
- 定位元素会脱离文档流(相对定位除外)
- 一个脱离了文档流的元素:
- 文档流中的元素摆放时,会忽略脱离了文档流的元素
- 文档流中元素计算自动高度时,会忽略脱离了文档流的元素
- 相对定位 (relative)
- 不会导致元素脱离文档流,只是让元素在原来位置上进行偏移。
- 可以通过四个 CSS 属性对设置其位置:
- left
- right
- top
- bottom
- 盒子的偏移不会对其他盒子造成任何影响。
- 绝对定位(absolute)
- 宽高为 auto,适应内容
- 包含块变化:找祖先中第一个定位元素,该元素的填充盒为其包含块。若找不到,则它的包含块为整个网页(初始化包含块)
- 固定定位(fixed)
- 其他情况和绝对定位完全一样。
- 包含块不同:固定为视口(浏览器的可视窗口)
- 定位下的居中
- 某个方向居中:
- 定宽(高)
- 将左右(上下)距离设置为 0
- 将左右(上下)margin 设置为 auto
- 绝对定位和固定定位中,margin 为 auto 时,会自动吸收剩余空间
- 某个方向居中:
- 多个定位元素重叠时
- 堆叠上下文
- 设置 z-index,通常情况下,该值越大,越靠近用户
- 只有定位元素设置 z-index 有效
- z-index 可以是负数,如果是负数,则遇到常规流、浮动元素,则会被其覆盖
- 补充
- 绝对定位、固定定位元素一定是块盒
- 绝对定位、固定定位元素一定不是浮动
- 没有外边距合并
- 定位:position
- 浮动、定位、弹性、table、Grid 网格布局 :优缺点
- 浮动
- 优点:兼容性好
- 缺点:清除浮动
- 绝对定位
- 优点:快捷
- 缺点:可用性差,脱离文档流
- 弹性
- 优点:
- 缺点:
- table
- 优点:兼容性好
- 缺点:单元格超出,每一个都必须调整
- Grid 网格布局
- 优点:代码量简化
- 缺点:
- 浮动
- 页面布局的变通
- 三栏布局
- 左右宽度固定,中间自适应
- 上下高度固定,中间自适应
- 两栏布局
- 左宽度固定,右自适应
- 右宽度固定,左自适应
- 上高度固定,下自适应
- 下高度固定,上自适应
- 三栏布局
- CSS的position定位
- css定位position值分别为:static, relative,absolute,fixed
- relative(相对定位):相对定位的偏移参考元素是元素本身,不会使元素脱离文档流。元素的初始位置占据的空间会被保留。相对定位元素常常作为绝对定位元素的父元素。并且定位元素经常与z-index属性进行层次分级
- 代码实例:
- css定位position值分别为:static, relative,absolute,fixed
<!DOCTYPE html>
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
1. 效果图:

1. 尽管rel元素产生了偏移,但是文字并没有填补它的原来的位置,可以看出相对定位元素没有脱离文档流,原来的位置依然会被保留。
1. 2. absolute(绝对定位)绝对定位元素以父辈元素中最近的定位元素为参考坐标,如果绝对定位元素的父辈元素中没有采用定位的,那么此绝对定位元素的参考对象是html,元素会脱离文档流。就好像文档流中被删除了一样。并且定位元素经常与z-index属性进行层次分级
1. 代码实例:
<!DOCTYPE html>
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
1. 效果图:

1. 在此辟谣一下哈!如果绝对定位元素的父辈元素中没有采用定位的,那么此绝对定位元素的参考对象是谁呢,有的人说是body,有的人会说是document,其实都不是,看了MDN上的介绍,以initial containing block为参考,它的尺寸是和视口是一致的,但不是由Viewport所产生的,而是由根元素<html>所产生的。
1. 代码实例:
<!DOCTYPE html>
1. 实例效果图:

1. 如果参考对象是body或者document的话,div元素肯定要位于页面的最底部,注意到这里有滚动条,元素只是位于视口的最底部。
1. 3. fixed (固定定位)位移的参考坐标是可视窗口,使用fixed的元素脱离文档流。并且定位元素经常与z-index属性进行层次分级
1. 实例代码:
<!DOCTYPE html>
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
阿什顿发斯蒂芬阿斯蒂芬阿斯蒂芬阿斯蒂芬
1. 实例效果图:

1. fixed固定定位和absolute绝对定位比较类似,它们都能够让元素产生位移上面演示了固定定位;如果到目前为止还没有看到与绝对定位的区别,那么我们可以在文中多加些文字是浏览器产生滚动条,拖动滚动条就可以看到两个定位方式的区别,固定定位的元素如其名一样,能够固定在某个位置。而绝对定位就会随着滚动条滚动而移动位置。
1. 4.static (静态定位)默认值,元素框正常生成的,top left bottom right这几个偏移属性不会影响其静态定位的正常显示
1. 不常用的四种
1. 1.inherit
1. 规定应该从父元素继承 position 属性的值
1. inherit 关键字可用于任何 HTML 元素上的任何 CSS 属性
1. 兼容:ie7及以下版本不支持此属性
2. 2.initial
1. 设置positon的值为默认值(static)
1. 兼容:ie不支持此属性
1. 问:有了static为什么还会存在此属性,不是多此一举?
1. 答:initial 关键字可用于任何 HTML 元素上的任何 CSS 属性,不是postion特有的
3. 3.unset
1. 设置positon的值为不设置:
1. 如果该属性的默认属性是 继承属性(例如字体相关的默认属性基本都是继承),该值等同于 inherit
1. 如果该属性的默认属性 不是继承属性(例如pisition的默认属性为static),该值等同于 initial
1. 兼容:ie不支持此属性
4. 4.sticky
1. css3新属性,它的表现就像position:relative和position:fixed的合体:
1.在目标区域在屏幕中可见时,它的行为就像position:relative;
2.页面滚动时
当父元素是body时
a.滚动距离小于屏幕高度或宽度,它会固定在目标位置
b.滚动距离大于屏幕高度或宽度,它的表现就像position:relative和1一样
当父元素不是body,在父元素高度内滚动时它会固定在目标位置,就像fixed
1. 在父元素滚动为不可视时它的表现就像position:relative和1一样
1. 兼容: ie不兼容、google不完全兼容(thead、tr标签不支持)、firefox59以后兼容,之前版本不完全兼容(table标签不支持)
1. HTML5高级之position(定位)
1. position 属性规定元素的定位类型,定义建立元素布局所用的定位机制。任何元素都可以定位,不过绝对或固定元素会生成一个块级框,而不论该元素本身是什么类型。相对定位元素会相对于它在正常流中的默认位置偏移。
1. position一般分为三种,一种是相对定位relative,一种是绝对定位absolute,一种是固定定位fixed,接下来分别说明这三个属性的用法以及相对应的特性,并举例说明。
1. 1、position:relative 相对定位
特点:
1)不影响元素本身的特性;
2)不使元素脱离文档流(元素移动之后原始位置会被保留);
3)如果没有定位偏移量,对元素本身没有任何影响;
4)提升层级。
注:定位元素位置控制:top/right/bottom/left 定位元素偏移量
1. 2、position:absolute 绝对定位
特点:
1)使元素完全脱离文档流;
2)使内嵌支持宽高;
3)块属性标签内容撑开宽度;
4)如果有定位父级相对于定位父级发生偏移,没有定位父级相对于document发生偏移;
5)相对定位一般都是配合绝对定位元素使用;
6)提升层级
注意:
z-index:[number]; 定位层级
a、定位元素默认后者层级高于前者;
b、建议在兄弟标签之间比较层级
接下来用一个例子进行使用说明。
例子要求:如何将左边的三个div变成右边的三个div布局,即将div2的位置移动到如图的位置。
代码如下:
<!DOCTYPE html>
这里做几点解释:
1)为什么body需要添加position:relative?
因为position:absolute这个属性会根据父级进行定位,如果没有定位父级则会相对于document发生偏移。而body在chrome浏览器中带有默认的样式,即带有margin属性,所以需要给body定义定位,这样后面的div就会根据body进行定位。
2)为什么div3中也需要添加position:absolute?
因为div2中添加属性position:absolute之后,就直接完全脱离文档流,那么div3的位置就会往上移动,为了实现效果,也需要在div3中添加同样的属性。
1. 3、position:fixed 固定定位
与绝对定位的特性基本一致,唯一的差别是始终相对整个文档进行定位;
问题:IE6不支持固定定位;
1. 4、其他定位
position:static ; 默认值
position:inherit ; 从父元素继承定位属性的值 (不兼容)、
1. 5、综合例子说明
做一个类似的弹窗效果。
代码:
我用了两种方法实现,一种就是上面总结的,都是利用div和position定位实现的,一种就是直接利用box-shadow属性实现的.
1)利用div和position定位实现
<!DOCTYPE html>
其中用到了三个比较重要的属性:
a】position 定位
b】z-index 定位层级
c】opacity 透明度
标准 不透明度: opacity:0~1;
IE 滤镜: filter:alpha(opacity=0~100);
2)利用box-shadow属性实现
box-shadow 向框添加一个或多个阴影。该属性是由逗号分隔的阴影列表,每个阴影由 2-4 个长度值、可选的颜色值以及可选的 inset 关键词来规定。省略长度的值是 0。
<!DOCTYPE html>
1. css粘性定位position:sticky问题采坑
1. 前言:
1. position:sticky是css定位新增属性;可以说是相对定位relative和固定定位fixed的结合;它主要用在对scroll事件的监听上;简单来说,在滑动过程中,某个元素距离其父元素的距离达到sticky粘性定位的要求时(比如top:100px);position:sticky这时的效果相当于fixed定位,固定到适当位置。
2. **使用:**
sticky-nav { position : sticky ; top : 100px ; }
1. 设置position:sticky同时给一个(top,bottom,right,left)之一即可
1. 使用条件:
1、父元素不能overflow:hidden或者overflow:auto属性。
2、必须指定top、bottom、left、right4个值之一,否则只会处于相对定位
3、父元素的高度不能低于sticky元素的高度
4、sticky元素仅在其父元素内生效
1. 例子:
1. css代码:
{ margin: 0; padding: 0 } html body { height: 100vh; width: 100% } h1 { height: 200px; position: relative; background-color: lightblue; } h1:after { content: ‘’; position: absolute; top: 100px; left: 0; width: 100%; height: 2px; background-color: red; } #sticky-nav { position: sticky; /position: absolute; left: 0;*/ top: 100px; width: 100%; height: 80px; background-color: yellowgreen; } .scroll-container { height: 600px; width: 100%; background-color: lightgrey; }
1. html代码:
高200px;距顶部100px
发生滚动
发生滚动
1. 项目中遇到的坑:
先来看看各大内核对position:sticky的支持情况
1. 问题描述:
在一个小程序开发项目中;tabs组件使用了粘性定位,其中有tab栏的切换;tab栏底部是大段列表内容list-container内容的展示;其中展示内容有click事件(或者说是touch事件);ios以及pc浏览器中对点击的测试是正常的;但在安卓手机中!!!!我的天,点击穿透了!!并且,尝试去掉list-container中的item的点击跳转,发现tab切换的点击没有了反应,事件消失了!!!
设置断点,查看事件流的走向:首先事件捕获—>目标节点tab—>事件冒泡;这个泡居然冒到了container-list中的item。。。简直噩梦
大致的项目结构:
html结构:
解决办法:
1.在使用组件库的tab时,外层套一个div,防止点击穿透和不正常的事件流走向或者(一个治标不治本的方法,具体看业务场景)
2.组件库的样式无法改,sticky作为tab组件的行内样式,因为我使用这个tab时是直接在viewpoint的顶部的,这是完全可以用fixed达到效果。我在调用类的外部设置了position:fixed !import;样式最高优先级去覆盖了组件库中的定位样式,就正常了。
一点想法:
position:sticky对安卓的兼容简直让人想哭,目前手机端的用户非常多,要做到兼顾,由于安卓系统对sticky粘性定位的惨淡支持;如果业务场景可以用其它定位解决,那就还是不要用sticky吧。。。。留下心酸的泪水。。。。
- 布局
- 圣杯布局、双飞翼布局、Flex布局和绝对定位布局
- 圣杯布局与双飞翼布局针对的都是三列左右栏固定中间栏边框自适应的网页布局(想象一下圣杯是主体是加上两个耳朵;鸟儿是身体加上一对翅膀)
- 圣杯布局的出现是来自由 Matthew Levine 在 2006 年写的一篇文章 《In Search of the Holy Grail》。 比起双飞翼布局,它的起源不是源于对页面的形象表达。在西方,圣杯是表达“渴求之物”的意思。
- 而双飞翼布局则是源于淘宝的UED,可以说是灵感来自于页面渲染。
- 布局要求有几点:
- 三列布局,中间宽度自适应,两边定宽;
- 中间栏要在浏览器中优先展示渲染;
- 允许任意列的高度最高;
- 可以看出我们题目的要求跟圣杯布局和双飞翼布局要求一样。
- 圣杯布局
- 效果图
- 圣杯布局、双飞翼布局、Flex布局和绝对定位布局

缩放页面可以发现随着页面的宽度的变化,这三栏布局是中间盒子优先渲染,两边的盒子框子宽度固定不变,即使页面宽度变小,也不影响我们的浏览。注意:为了安全起见,最好还是给body加一个最小宽度!
1. 圣杯布局要求
header和footer各自占领屏幕所有宽度,高度固定。
中间的container是一个三栏布局。
三栏布局两侧宽度固定不变,中间部分自动填充整个区域。
中间部分的高度是三栏中最高的区域的高度。
1. 圣杯布局的三种实现
【1】浮动
<!DOCTYPE html>
先定义好header和footer的样式,使之横向撑满。
在container中的三列设为浮动和相对定位(后面会用到),center要放在最前面,footer清除浮动。
三列的左右两列分别定宽200px和150px,中间部分center设置100%撑满
这样因为浮动的关系,center会占据整个container,左右两块区域被挤下去了
接下来设置left的 margin-left: -100%;,让left回到上一行最左侧
但这会把center给遮住了,所以这时给外层的container设置 padding-left: 200px;padding-right: 150px;,给left和right空出位置
这时left并没有在最左侧,因为之前已经设置过相对定位,所以通过 left: -200px; 把left拉回最左侧
同样的,对于right区域,设置 margin-left: -150px; 把right拉回第一行
这时右侧空出了150px的空间,所以最后设置 right: -150px;把right区域拉到最右侧就行了。
【2】flex弹性盒子
<!DOCTYPE html>
header和footer设置样式,横向撑满。
container中的left、center、right依次排布即可
给container设置弹性布局 display: flex;
left和right区域定宽,center设置 flex: 1; 即可
【3】grid布局

<!DOCTYPE html>
如上图所示,我们把body划分成三行四列的网格,其中有5条列网格线
给body元素添加display: grid;属性变成一个grid(网格)
给header元素设置grid-row: 1; 和 grid-column: 1/5; 意思是占据第一行网格的从第一条列网格线开始到第五条列网格线结束
给footer元素设置grid-row: 1; 和 grid-column: 1/5; 意思是占据第三行网格的从第一条列网格线开始到第五条列网格线结束
给left元素设置grid-row: 2; 和 grid-column: 1/2; 意思是占据第二行网格的从第一条列网格线开始到第二条列网格线结束
给center元素设置grid-row: 2; 和 grid-column: 2/4; 意思是占据第二行网格的从第二条列网格线开始到第四条列网格线结束
给right元素设置grid-row: 2; 和 grid-column: 4/5; 意思是占据第二行网格的从第四条列网格线开始到第五条列网格线结束
1. 题目要求:针对如下DOM结构,编写CSS,实现三栏水平布局,其中left、right分别位于左右两侧,left宽度为200px,right宽度为300px,main处在中间,宽度自适应。 要求:允许增加额外的DOM节点,但不能修改现有节点顺序。
方法一:圣杯布局
1.设置基本样式
/3.圣杯布局法/ .left, .main, .right { min-height: 130px; } .left { background: green; width: 200px; } .main { background-color: blue; } .right { background-color: red; width: 300px; }
为了高度保持一致给left main right都加上min-height:130px。

2.圣杯布局是一种相对布局,首先设置父元素container的位置:
.container { padding: 0 300px 0 200px; }
实现效果是左右分别空出200px和300px区域,效果如图:

3.将主体部分的三个子元素都设置左浮动
.left, .main, .right { min-height: 130px; float: left; }
出现了如下情况,怎么办,别着急慢慢来:

4.设置main宽度为width:100%,让其单独占满一行

.main { background-color: blue; width: 100%; }
5.设置left和right 负的外边距
我们的目标是让left、main、right依次并排,但是上图中left和right都是位于下一行,这里的技巧就是使用负的margin-left:
.left { margin-left: -100%; background-color: green; width: 200px; } .right { margin-left: -300px; background-color: red; width: 300px; }
负的margin-left会让元素沿文档流向左移动,如果负的数值比较大就会一直移动到上一行。关于负的margin的应用也是博大精深,这里肯定是不能详细介绍了。
设置left部分的margin-left为-100%,就会使left向左移动一整个行的宽度,由于left左边是父元素的边框,所以left继续跳到上一行左移,一直移动到上一行的开头,并覆盖了main部分(仔细观察下图,你会发现main里面的字“main”不见了,因为被left遮住了),left上移过后,right就会处于上一行的开头位置,这时再设置right部分margin-left为负的宽度,right就会左移到上一行的末尾。

6.接下来只要把left和right分别移动到这两个留白就可以了。可以使用相对定位移动 left和right部分。

.left, .main, .right { position: relative; min-height: 130px; float: left; } .left { left: -200px; margin-left: -100%; background: green; width: 200px; } .right { right: -300px; margin-left: -300px; background-color: red; width: 300px; }
至此,我们完成了三列中间自适应的布局,也就是传说中的圣杯布局。完整的代码如下:
<!DOCTYPE html>
方法二:双飞翼布局
圣杯布局和双飞翼布局解决问题的方案在前一半是相同的,也就是三栏全部float浮动,但左右两栏加上负margin让其跟中间栏div并排,以形成三栏布局。不同在于解决 “中间栏div内容不被遮挡”问题的思路不一样。
他的HTML结构发生了变化:
直接贴出代码,读者可以自行参透他们的异同:
<!DOCTYPE html>
双飞翼布局比圣杯布局多使用了1个div,少用大致4个css属性(圣杯布局container的 padding-left和padding-right这2个属性,加上左右两个div用相对布局position: relative及对应的right和left共4个属性,;而双飞翼布局子div里用margin-left和margin-right共2个属性,比圣杯布局思路更直接和简洁一点。简单说起来就是:双飞翼布局比圣杯布局多创建了一个div,但不用相对布局了。
方法三:Flex布局
Flex 是 Flexible Box 的缩写,意为”弹性布局”,用来为盒状模型提供最大的灵活性。
任何一个容器都可以指定为 Flex 布局,所以Flex 布局将成为未来布局的首选方案。
阮一峰老师的教程http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html
Flex布局制作了 Demo,:http://static.vgee.cn/static/index.html
接下来讲一下此实例的具体实现:
1.首先将container块设置为一个Flex容器
.container{ display: flex; min-height: 130px; }
那么container下属的main、left和right这三个子元素自动成为容器成员,称为 Flex 项目(flex item),简称”项目”。
2.对这三个项目做初始设置
.main{ background-color: blue; } .left{ background-color: green; } .right{ background-color: red; }
项目根据内容进行弹性布局:

3.通过order属性设置排列顺序
可以看出三个项目的排序方式不一样了,main排在了第一个,要让main在中间,left在左边,可以通过Flex容器下的项目的属性“order”属性来设置:
.left{ order: -1; background-color: green; }
对于order属性:定义项目的排列顺序,越小越靠前,默认为0。

4.通过项目属性flex-grow设置main的放大比例,将空余的空间用main来填充,使三个项目不满一整行;默认为0,也就是对剩余空间不做处理。

.main{ flex-grow:1; background-color: blue; }
5.通过项目属性flex-basis 设置left和right的固定宽度
.left{ order: -1; flex-basis: 200px; background-color: green; } .right{ flex-basis: 300px; background-color: red; }
这样就实现了我们的目标,是不是很简单?这就是flex布局的魅力。。。

6.最后,完整的代码如下:
<!DOCTYPE html>
方法四:绝对定位布局
绝对定位使元素的位置与文档流无关,因此不占据空间。这一点与相对定位不同,相对定位实际上被看作普通流定位模型的一部分,因为元素的位置相对于它在普通流中的位置。
提示:因为绝对定位的框与文档流无关,所以它们可以覆盖页面上的其它元素。可以通过设置 z-index 属性来控制这些框的堆放次序。
言归正传:
<!DOCTYPE html>
实现结果当然是一样的啦!
 1. 水平居中、 垂直居中、 垂直水平居中
1. 水平居中
1. 方法一:在父容器上定义固定宽度,margin值设成auto
1. 水平居中、 垂直居中、 垂直水平居中
1. 水平居中
1. 方法一:在父容器上定义固定宽度,margin值设成auto

<!DOCTYPE html>

<!DOCTYPE html>
如果不是,则先将其父元素设置为块级元素,再给父元素设置 text-align: center;
我是行内元素
效果:
 1. 块级元素
方案一:(分宽度定不定两种情况)
1. 块级元素
方案一:(分宽度定不定两种情况)定宽度:需要谁居中,给其设置 margin: 0 auto; (作用:使盒子自己居中)
效果:

不定宽度:默认子元素的宽度和父元素一样,这时需要设置子元素为display: inline-block; 或 display: inline;即将其转换成行内块级/行内元素,给父元素设置 text-align: center;
效果:(将#son转换成行内元素,内容的高度撑起了#son的高度,设置高度无用)

方案二:使用定位属性
首先设置父元素为相对定位,再设置子元素为绝对定位,设置子元素的left:50%,即让子元素的左上角水平居中;
定宽度:设置绝对子元素的 margin-left: -元素宽度的一半px; 或者设置transform: translateX(-50%);
不定宽度:利用css3新增属性transform: translateX(-50%);
效果:

方案三:使用flexbox布局实现(宽度定不定都可以)
使用flexbox布局,只需要给待处理的块状元素的父元素添加属性 display: flex; justify-content: center;
效果:
 1. 1
居中效果主要分为三大类:水平居中、垂直居中和水平垂直居中。
1. 1
居中效果主要分为三大类:水平居中、垂直居中和水平垂直居中。水平居中的实现方案,大家最熟悉的莫过开给元素定一个显示式的宽度,然后加上margin的左右值为auto。如:
.center { width: 960px; margin-left: auto; margin-right: auto; }
这种方法给知道了宽度的元素设置居中是最方便不过的了,但有很多情况之下,我们是无法确定元素容器的宽度。换句话说,未有明确宽度的时候,上面的方法无法让我们实现元素水平居中。那要怎么办呢?这也就是我们今天需要讨论的问题。
为了更好的说明问题,我们来看一个制作分页效果的代码:
HTML
给分页加上样式:
.pagination li { line-height: 25px; } .pagination a { display: block; color: #f2f2f2; text-shadow: 1px 0 0 #101011; padding: 0 10px; border-radius: 2px; box-shadow: 0 1px 0 #5a5b5c inset,0 1px 0 #080808; background: linear-gradient(top,#434345,#2f3032); } .pagination a:hover { text-decoration: none; box-shadow: 0 1px 0 #f9bd71 inset,0 1px 0 #0a0a0a; background: linear-gradient(top,#f48b03,#c87100); }
这是一个极普通的样式代码,初步的效果:

这很显然不是我们需要的效果,接下来我们分几种方案来制作:
一、margin和width实现水平居中
第一种方法是最古老的实现方案,也是大家最常见的方案,在分页容器上定义一个宽度,然后配合margin的左右值为“auto”实现效果:
.pagination { width: 293px; margin-left: auto; margin-right: auto; } .pagination li { line-height: 25px; display: inline; float: left; margin: 0 5px; } .pagination a { display: block; color: #f2f2f2; text-shadow: 1px 0 0 #101011; padding: 0 10px; border-radius: 2px; box-shadow: 0 1px 0 #5a5b5c inset,0 1px 0 #080808; background: linear-gradient(top,#434345,#2f3032); } .pagination a:hover { text-decoration: none; box-shadow: 0 1px 0 #f9bd71 inset,0 1px 0 #0a0a0a; background: linear-gradient(top,#f48b03,#c87100); }
代码中绿色部分是为了实现分页居中效果而添加的代码。(下文中没有特殊声明,绿色部分代码表示新增加的代码。),先来看看效果:

效果是让我们实现了,但其扩展性那就不一定强了。示例中只显示了五页和向前向后的七个显项,但往往我们很多情况下是不知道会有多少个分页项显示出来,而且也无法确定每个分页选项的宽度是多少,也就无法确认容器的宽度。
优点:实现方法简单易懂,浏览器兼容性强;
缺点:扩展性差,无法自适应未知项情况。
二、inline-block实现水平居中方法
这个方法早期在《如何解决inline-block元素的空白间距》和《CSS3制作的分页导航》中都有涉及到,但未单独提取出来。此次,将这种方法拿出来说。
仅inline-block属性是无法让元素水平居中,他的关键之处要在元素的父容器中设置text-align的属性为“center”,这样才能达到效果:
.pagination { text-align: center; font-size: 0; letter-spacing: -4px; word-spacing: -4px; } .pagination li { line-height: 25px; margin: 0 5px; display: inline-block; display: inline; zoom:1; letter-spacing: normal; word-spacing: normal; font-size: 12px; } .pagination a { display: block; color: #f2f2f2; text-shadow: 1px 0 0 #101011; padding: 0 10px; border-radius: 2px; box-shadow: 0 1px 0 #5a5b5c inset,0 1px 0 #080808; background: linear-gradient(top,#434345,#2f3032); } .pagination a:hover { text-decoration: none; box-shadow: 0 1px 0 #f9bd71 inset,0 1px 0 #0a0a0a; background: linear-gradient(top,#f48b03,#c87100); }
效果如下:

这个方法相对来说也是简单易懂,但使用了inline-block解决了水平居中的问题,却又产生了一个新的问题,就是分页项与分页项由回车符带来的空白间距,那么不知情的同学就会不知道如何解决?(而且这个间距并不是所有浏览器都有),所以需要解决下inline-block带来的间距,详细的解决方法可以阅读《如何解决inline-block元素的空白间距》一文。
做点:简单易懂,扩展性强;
缺点:需要额外处理inline-block的浏览器兼容性。
三、浮动实现水平居中的方法
刚看到标题,大家可能会感到很意外,元素都浮动了,他还能水平居中?大家都知道,浮动要么靠左、要么靠右,还真少见有居中的。其实略加处理就有了。
.pagination { float: left; width: 100%; overflow: hidden; position: relative; } .pagination ul { clear: left; float: left; position: relative; left: 50%;/整个分页向右边移动宽度的50%/ text-align: center; } .pagination li { line-height: 25px; margin: 0 5px; display: block; float: left; position: relative; right: 50%;/将每个分页项向左边移动宽度的50%/ } .pagination a { display: block; color: #f2f2f2; text-shadow: 1px 0 0 #101011; padding: 0 10px; border-radius: 2px; box-shadow: 0 1px 0 #5a5b5c inset,0 1px 0 #080808; background: linear-gradient(top,#434345,#2f3032); } .pagination a:hover { text-decoration: none; box-shadow: 0 1px 0 #f9bd71 inset,0 1px 0 #0a0a0a; background: linear-gradient(top,#f48b03,#c87100); }
效果如下所示:

这种方法实现和前面的与众不同,使用了浮动配合position定位实现。下面简单的介绍了一下这种方法实现原理,详细的可以阅读Matthew James Taylor写的《Horizontally Centered Menus with no CSS hacks》一文。
没有浮动的div:大家都知道div是一个块元素,其默认的宽度就是100%,如图所示:

如果div设置了浮动之后,他的内容有多宽度就会撑开有多大的容器(除显式设置元素宽度值之外),这也是我们实现让分页导航居中的关键所在:

接下来使用传统的制作方法,我们会让导航浮动到左边,而且每个分页项也进行浮动,就如下图所示一样:

现在要想的办法是让分页导航居中的效果了,在这里是通过“position:relative”属性实现,首先在列表项“ul”上向右移动50%(left:50%;),看到如下图所示:

如上图所示一样,整个分页向右移动了50%的距离,紧接着我们在“li”上也定义“position:relative”属性,但其移动的方向和列表“ul”移动的方向刚好是反方向,而其移动的值保持一致:

这样一来就实现了float浮动居中的效果。
特别声明:方法三思想来源于Matthew James Taylor写的《Horizontally Centered Menus with no CSS hacks》一文,并且引用其文中演示的示意图。
优点:兼容性强,扩展性强;
缺点:实现原理较复杂。
四、绝对定位实现水平居中
绝对定位实现水平居中,我想大家也非常的熟悉了,并且用得一定不少,早期是这样使用的:
.ele { position: absolute; width: 宽度值; left: 50%; margin-left: -(宽度值/2); }
但这种实现我们有一个难题,我并不知道元素的宽度是多少,这样也就存在如方法一所说的难题,但我们可以借助方法三做一点变通:
.pagination { position: relative; } .pagination ul { position: absolute; left: 50%; } .pagination li { line-height: 25px; margin: 0 5px; float: left; position: relative;/注意,这里不能是absolute,大家懂的/ right: 50%; } .pagination a { display: block; color: #f2f2f2; text-shadow: 1px 0 0 #101011; padding: 0 10px; border-radius: 2px; box-shadow: 0 1px 0 #5a5b5c inset,0 1px 0 #080808; background: linear-gradient(top,#434345,#2f3032); } .pagination a:hover { text-decoration: none; box-shadow: 0 1px 0 #f9bd71 inset,0 1px 0 #0a0a0a; background: linear-gradient(top,#f48b03,#c87100); }
效果如下所示:

优点:扩展性强,兼容性强;
缺点:理解性难。
五、CSS3的flex实现水平居中方法
CSS3的flex是一个很强大的功能,她能让我们的布局变得更加灵活与方便,唯一的就是目前浏览器的兼容性较差。那么第五种方法,我们就使用flex来实现,其实这种方法早在《CSS3实现水平垂直居中》一文有介绍,我们把水平居中的部分代码取出来:
.pagination { display: -webkit-box; -webkit-box-orient: horizontal; -webkit-box-pack: center; display: -moz-box; -moz-box-orient: horizontal; -moz-box-pack: center; display: -o-box; -o-box-orient: horizontal; -o-box-pack: center; display: -ms-box; -ms-box-orient: horizontal; -ms-box-pack: center; display: box; box-orient: horizontal; box-pack: center; } .pagination li { line-height: 25px; margin: 0 5px; float: left; } .pagination a { display: block; color: #f2f2f2; text-shadow: 1px 0 0 #101011; padding: 0 10px; border-radius: 2px; box-shadow: 0 1px 0 #5a5b5c inset,0 1px 0 #080808; background: linear-gradient(top,#434345,#2f3032); } .pagination a:hover { text-decoration: none; box-shadow: 0 1px 0 #f9bd71 inset,0 1px 0 #0a0a0a; background: linear-gradient(top,#f48b03,#c87100); }
效果如下:

优点:实现便捷,扩展性强
缺点:兼容性差。
六、CSS3的fit-content实现水平居中方法
今天看《Horizontal centering using CSS fit-content value》一文,让我体验了一下”fit-content”制作水平居中的方法。我也将这种方法收进来。
“fit-content”是CSS中给“width”属性新加的一个属性值,他配合margin可以让我轻松的实现水平居中的效果:
.pagination ul { width: -moz-fit-content; width:-webkit-fit-content; width: fit-content; margin-left: auto; margin-right: auto; } .pagination li { line-height: 25px; margin: 0 5px; float: left; } .pagination a { display: block; color: #f2f2f2; text-shadow: 1px 0 0 #101011; padding: 0 10px; border-radius: 2px; box-shadow: 0 1px 0 #5a5b5c inset,0 1px 0 #080808; background: linear-gradient(top,#434345,#2f3032); } .pagination a:hover { text-decoration: none; box-shadow: 0 1px 0 #f9bd71 inset,0 1px 0 #0a0a0a; background: linear-gradient(top,#f48b03,#c87100); }
效果如下:

优点:简单易懂,扩展性强;
缺点:浏览器兼容性差 1. 2 一、对于行内元素:
text-align:center;
二、对于确定宽度的块级元素:
(1)margin和width实现水平居中
常用(前提:已设置width值):margin-left:auto; margin-right:auto;
(2)绝对定位和margin-left: -(宽度值/2)实现水平居中
固定宽度块级元素水平居中,通过使用绝对定位,以及设置元素margin-left为其宽度的一半
.content{ width: 200px; position: absolute; left: 50%; margin-left: -100px; // 该元素宽度的一半,即100px background-color: aqua; }
(3)position:absolute + (left=0+top=0+right=0+bottom=0) + margin:auto
.content{ position: absolute; width: 200px; top: 0; right: 0; bottom: 0; left: 0; margin: auto; }
三、对于未知宽度的块级元素:
(1)table标签配合margin左右auto实现水平居中
使用table标签(或直接将块级元素设值为display:table),再通过给该标签添加左右margin为auto
(2)inline-block实现水平居中方法
display:inline-block;(或display:inline)和text-align:center;实现水平居中
存在问题:需额外处理inline-block的浏览器兼容性(解决inline-block元素的空白间距)
(3)绝对定位实现水平居中
绝对定位+transform,translateX可以移动本省元素的50%
.content{ position: absolute; left: 50%; transform: translateX(-50%); / 移动元素本身50% / background: aqua; }
(4)相对定位实现水平居中
用float或者display把父元素变成行内块状元素
.contentParent{ display: inline-block; / 把父元素转化为行内块状元素 / /float: left; 把父元素转化为行内块状元素 / position: relative; left: 50%; } /目标元素/ .content{ position: relative; right: 50%; background-color:aqua; }
(5)CSS3的flex实现水平居中方法,法一
.contentParent{ display: flex; flex-direction: column; } .content{ align-self:center; }
(6)CSS3的flex实现水平居中方法,法二
.contentParent{ display: flex; } .content{ margin: auto; }
(7)CSS3的fit-content配合左右margin为auto实现水平居中方法
.content{ width: fit-content; margin-left: auto; margin-right: auto; } 1. 元素水平居中 当然最好使的是:
margin: 0 auto;
居中不好使的原因:
1、元素没有设置宽度,没有宽度怎么居中嘛!
2、设置了宽度依然不好使,你设置的是行内元素吧,行内元素和块元素的区别以及如何将行内元素转换为块元素
示例 1:

效果:
 1. 多行的行内元素
使用给父元素设置display:table-cell;和vertical-align: middle;属即可;
1. 多行的行内元素
使用给父元素设置display:table-cell;和vertical-align: middle;属即可;效果:
 1. 块级元素
方案一:使用定位
1. 块级元素
方案一:使用定位首先设置父元素为相对定位,再设置子元素为绝对定位,设置子元素的top: 50%,即让子元素的左上角垂直居中;
定高度:设置绝对子元素的 margin-top: -元素高度的一半px; 或者设置transform: translateY(-50%);
不定高度:利用css3新增属性transform: translateY(-50%);
效果:

方案二:使用flexbox布局实现(高度定不定都可以)
使用flexbox布局,只需要给待处理的块状元素的父元素添加属性 display: flex; align-items: center;
效果:
 1. 垂直水平居中
1. 方式1:绝对定位
1. 垂直水平居中
1. 方式1:绝对定位

<!DOCTYPE html>

<!DOCTYPE html> 1. 方式3:使用translate实现平移 <!DOCTYPE html>
下面的transform代码可以更换为transform: translate(-50%,-50%); 1. 方式4:通过设置bottom top left right margin来实现

<!DOCTYPE html>
最长使用,设置 display: flex;justify-content: center;align-items: center;三个属性;
方案3:flex布局
示例 4:

示例 5:table-cell布局
因为table-cell相当与表格的td,td为行内元素,无法设置宽和高,所以嵌套一层,嵌套一层必须设置display: inline-block;td的背景覆盖了橘黄色,不推荐使用

效果:

方案二:设置父元素为相对定位,给子元素设置绝对定位,left: 50%; top: 50%; margin-left: —元素宽度的一半px; margin-top: —元素高度的一半px;
效果:

方案1:position 元素已知宽度
父元素设置为:position: relative;子元素设置为:position: absolute;距上50%,据左50%,然后减去元素自身宽度的距离就可以实现
示例 2:

设置父元素为相对定位,给子元素设置绝对定位,left: 50%; top: 50%; transform: translateX(-50%) translateY(-50%);
效果:

方案二:使用flex布局实现
设置父元素为flex定位,justify-content: center; align-items: center;
效果:

方案2:position transform 元素未知宽度
如果元素未知宽度,只需将上面例子中的margin: -50px 0 0 -50px;替换为:transform: translate(-50%,-50%);
效果如上!
示例 3:

1. 平时是这样的,上下排列~

1. float 浮动
div1{ float: left; } #div2 { float: right; } #div3 { float: right; }
1. 然后这样了

1. float 的特点:
多个 div 右浮动时,顺序会颠倒,请注意看 div2 和 div3,可以通过将它们再用一个 div 包起来,然后对它们设置左浮动,对父 div 设置右浮动来解决。
脱离文档流,若父元素高度由内容撑开,那么就撑不开,从图中可以看到 wrap 没了,因为高度变为了 0,可通过清浮动来解决。
文字会环绕在浮动元素周围,图中未表现出来。
不能换行,图中未表现出来。
1. inline-block 行块标签

#div1, #div2, #div3{ display: inline-block; }
1. inline-block 特点:
元素间会有空白。这个空白其实是空白符,因为 inline-block 会使元素在行内排列,也就是跟文字在一起排列,而我们源代码中 div 和 div 之间的空格、Tab、换行符在浏览器里会被合并成一个空白符,所以就会出现缝隙,常见的解决方案有:
1. 通过给父元素设置 font-size: 0; ,使空白符不可见。但会导致子元素中继承的字体大小也为 0,解决方案:
1. 可以明确子元素内字体大小的,为其单独设置文字大小。
2. 可以使用 rem 作为字体大小单位来继承 HTML 根元素的字体大小属性。
2. 在源代码里把前一个 div 的结束标签和后一个 div 的开始标签贴在一起。可读性极差,丑拒。
3. 不用 inline-block,嘿嘿~
可以换行,如下图

1. flex 弹性盒模型
1. 最爱的解决方案,给父元素设置 display: flex; 即可。
wrap{ display: flex; }
1. 效果图:

1. 还可以通过 justify-content 属性调整子元素的水平对齐方式:
wrap{ display: flex; justify-content: flex-start; }
1. **flex-start:**
1. 默认,图同上。
1. **flex-end:**

1. **center:**

1. **space-around:**

1. **space-between:**

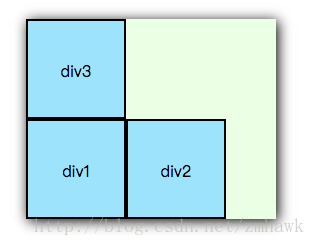
1. 不过当父元素宽度不够时, flex 默认是不会换行的,而是会等比例压缩,缩放比例 flex-shrink 属性或复合属性 flex 相关

1. 通过 flex-wrap 属性可以使其换行,该值有三个取值 nowrap、 wrap、 wrap-reverse,默认为 nowrap。
wrap{ display: flex; flex-wrap: nowrap; }
1. **nowrap**
1. 默认,图略。
1. **wrap**

1. **wrap-reverse**
1. flex 使用不再深入探讨,推荐阮一峰写的教程 [http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html?utm_source=tuicool](http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html?utm_source=tuicool)
1. 三栏布局
1. **实现效果:** 左右栏定宽,中间栏自适应

1. 1、绝对定位布局:position + margin
html结构:
css样式:
body,html{ height: 100%; padding: 0; margin: 0; overflow: hidden; } /左右进行绝对定位/ .left,.right{ position: absolute; height:100%; top: 0; background: #ff69b4; } .left{ left: 0; width: 100px; } .right{ right: 0; width: 200px; } /中间用margin空出左右元素所占的空间/ .main{ height:100%; margin: 0 100px 200px 0; background: #659; }
缺点: 如果中间栏含有最小宽度限制,或是含有宽度的内部元素,当浏览器宽度小到一定程度,会发生层重叠的情况。
1. 2、浮动布局: float + margin
html结构:
css样式:
body,html{ height: 100%; padding:0; margin: 0; } /左边栏左浮动/ .left{ float:left; height:100%; width:100px; background:#ff69b4; } /中间栏自适应/ .main{ height:100%; margin:0 200px 0 100px; background: #659; } /右边栏右浮动/ .right{ float:right; height:100%; width:200px; background:#ff69b4; }
1. 3、flex布局
html结构:
css样式:
.container{ display: flex; } .left{ width:200px; background: red; } .main{ flex: 1; background: blue; } .right{ width:200px; background: red; }
这种布局方式,高度由内容决定。
1. 4、table布局
html结构:
css样式:
.container{ display: table; width:100%; } .container>div{ display: table-cell; } .left{ width: 100px; background: red; } .main{ background: blue; } .right{ width: 200px; background: red; }
高度由内容决定。
1. 5、Grid网格布局
html结构:
css样式:
.container{ display: grid; width: 100%; grid-template-rows: 100px; /设置行高/ grid-template-columns: 100px auto 200px; /设置列数属性/ } .left{ background: red; } .main{ background: blue; } .right{ background:red; }
1. 6、圣杯布局
html结构:
css样式:
/ 两边定宽,中间自适用 / body,html,.container{ height: 100%; padding:0; margin: 0; } .col{ float: left; / 三个col都设置float: left,为了把left和right定位到左右部分 / position:relative; } /父元素空出左右栏位子: 因为上一步中,左右栏定位成功了,但是中间栏的内容会被遮盖住/ .container{ padding:0 200px 0 100px; } /左边栏/ .left{ left:-100px; width: 100px; height:100%; margin-left: -100%; background: #ff69b4; } /中间栏/ .main{ width:100%; height: 100%; background: #659; } /右边栏/ .right{ right:-200px; width:200px; height:100%; margin-left: -200px; background: #ff69b4; }
总结:圣杯布局用到了浮动float、负边距、相对定位relative,不添加额外标签
1. 7、双飞翼布局
html结构:
css样式:
body,html,.container{ height: 100%; padding:0; margin: 0; } .col{ float: left; / 把left和right定位到左右部分 / } .main{ width:100%; height:100%; background: #659; } .main_inner{ / 处理中间栏的内容被遮盖问题 / margin:0 200px 0 100px; } .left{ width: 100px; height: 100%; margin-left: -100%; background: #ff69b4; } .right{ height:100%; width:200px; margin-left: -200px; background: #ff69b4; }
双飞翼布局的好处:
(1)主要的内容先加载的优化。
(2)兼容目前所有的主流浏览器,包括IE6在内。
(3)实现不同的布局方式,可以通过调整相关CSS属性即可实现。
1. 8、对比圣杯布局和双飞翼布局:
(1)都是左右栏定宽,中间栏自适应的三栏布局,中间栏都放到文档流前面,保证先行渲染。
(2)解决方案基本相似:都是三栏全部设置左浮动float:left,然后分别结局中间栏内容被覆盖的问题。
(3)解决中间栏内容被覆盖问题时,圣杯布局设置父元素的padding,双飞翼布局在中间栏嵌套一个div,内容放到新的div中,并设置margin,实际上,双飞翼布局就是圣杯布局的改进方案。
1. 假设高度已知,请写出三栏布局,左栏、右栏宽度300px,中间宽度自适应。

1. 样式
1. 1. 浮动布局
三栏布局
浮动解决方案
1.这是三栏布局的浮动解决方案; 2.这是三栏布局的浮动解决方案;浮动布局是有局限性的,浮动元素是脱离文档流,要做清除浮动,这个处理不好的话,会带来很多问题,比如高度塌陷等。
浮动布局的优点就是比较简单,兼容性也比较好。只要清除浮动做的好,是没有什么问题的。
延伸:你知道哪些清除浮动的方案?每种方案的有什么优缺点?
1. 2.绝对定位布局
三栏布局
绝对定位解决方案
1.这是三栏布局的绝对定位解决方案; 2.这是三栏布局的绝对定位解决方案;绝对定位布局优点,很快捷,设置很方便,而且也不容易出问题,你可以很快的就能想出这种布局方式。
缺点就是,绝对定位是脱离文档流的,意味着下面的所有子元素也会脱离文档流,这就导致了这种方法的有效性和可使用性是比较差的。
1. 3.flex布局
三栏布局
flexbox解决方案
1.这是三栏布局的felx解决方案; 2.这是三栏布局的flex解决方案;felxbox布局是css3里新出的一个,它就是为了解决上述两种方式的不足出现的,是比较完美的一个。目前移动端的布局也都是用flexbox。
felxbox的缺点就是不能兼容IE8及以下浏览器
1. 4.表格布局
三栏布局
表格布局解决方案
1.这是三栏布局的表格解决方案; 2.这是三栏布局的表格解决方案;表格布局在历史上遭到很多人的摒弃,说表格布局麻烦,操作比较繁琐,其实这是一种误解,在很多场景中,表格布局还是很适用的,比如这个三栏布局,用表格布局就轻易写出来了。还有表格布局的兼容性很好,在flex布局不兼容的时候,可以尝试表格布局。
表格布局也是有缺陷的,当其中一个单元格高度超出的时候,两侧的单元格也是会跟着一起变高的,而有时候这种效果不是我们想要的。
1. 5.网格布局
三栏布局
网格布局解决方案
1.这是三栏布局的网格布局解决方案; 2.这是三栏布局的网格布局解决方案;网格布局也是新出的一种布局方式,如果你答出这种方式,也就证明了你的实力,证明你对技术热点是有追求的,也说明你有很强的学习能力。
效果图

最后这个问题还有很多延伸问题的,比如,
高度已知换为高度未知呢?
块内内容超出会是怎样的效果?
如果是上下高度已知,中间自适应呢?
如果是两栏布局呢?
如果是上下左右混合布局呢?
1. 已知布局元素的高度,写出三栏布局,要求左栏、右栏宽度各为300px,中间自适应。
1. 一、浮动布局
<!DOCTYPE html>
浮动布局的兼容性比较好,但是浮动带来的影响比较多,页面宽度不够的时候会影响布局
1. 二、绝对定位布局
<!DOCTYPE html>
绝对定位布局快捷,但是有效性比较差,因为脱离了文档流。
1. 三、flex布局
<!DOCTYPE html>
自适应好,高度能够自动撑开
1. 四、table-cell表格布局
<!DOCTYPE html>
兼容性好,但是有时候不能固定高度,因为会被内容撑高。
1. 五、网格布局
<!DOCTYPE html>
比较新的一种布局方式,兼容性没那么好。
- ul、li导航栏居中的两种办法
- 总结了下导航栏的制作方法:一种是用float设计,提前设置好高度与宽度,然后将要显示的元素设置为float::left依次显示。
- 一、float方法
- 界面html

1. css代码
.topbar-container{ background-color: #222222; } .topbar-wrap{ width:1200px; height:60px; margin:0 auto; overflow: hidden; } .logo{ height:50px; width: 50px; float: left; margin:5px 5px; } .nav{ float: left; height: 60px;; } .nav li{ float: left; width: 100px; margin:0 10px; list-style: none; } .nav a{ text-decoration: none; height: 100%; width: 100%; display: block; font-size: 18px; color: #dadada; text-align: center; line-height: 60px; } .nav a:hover{ background: #333; }
1. **二、inline-block居中**
1. 其中左边的img设置为a'bsolute是为了让img不占位置,从而让右侧的nav居中
1. html代码
1. css代码
.topbar-container2{ background-color: #222222; } .topbar-wrap2{ height: 60px; width: 1200px; margin:0 auto; position: relative; } .logo2{ position: absolute; height:50px; width: 50px; margin:5px 5px; left:-0px; top:0; } .nav2{ height: 60px; width:1200px; } .nav2 ul{ text-align: center; height:100%; width: 100%; list-style: none; } .nav2 li{ display:inline-block; } .nav2 ul li a{ text-decoration: none; font-size: 18px; color: #dadada; text-align: center; line-height: 60px; margin:0 20px; }
1. **重点是ul设置text-align:center,这样才会居中**
- 盒模型

- 标准盒模型

1. width和height =content宽度/高度
- IE盒模型

1. width和height =content+padding+border宽度/高度
- 如何设置box-sizing:content-box 【border-box不包含margin】, box-sizing:border-box
- content-box 是默认值。如果你设置一个元素的宽为100px,那么这个元素的内容区会有100px 宽,并且任何边框和内边距的宽度都会被增加到最后绘制出来的元素宽度中。
- width 与 height 只包括内容的宽和高, 不包括边框(border),内边距(padding),外边距(margin)。注意: 内边距、边框和外边距都在这个盒子的外部。 比如说,.box {width: 350px; border: 10px solid black;} 在浏览器中的渲染的实际宽度将是 370px。
- 尺寸计算公式:
- width 与 height 只包括内容的宽和高, 不包括边框(border),内边距(padding),外边距(margin)。注意: 内边距、边框和外边距都在这个盒子的外部。 比如说,.box {width: 350px; border: 10px solid black;} 在浏览器中的渲染的实际宽度将是 370px。
- content-box 是默认值。如果你设置一个元素的宽为100px,那么这个元素的内容区会有100px 宽,并且任何边框和内边距的宽度都会被增加到最后绘制出来的元素宽度中。
width = 内容的宽度
height = 内容的高度
1. 宽度和高度的计算值都不包含内容的边框(border)和内边距(padding)。
1. border-box 告诉浏览器:你想要设置的边框和内边距的值是包含在width内的。也就是说,如果你将一个元素的width设为100px,那么这100px会包含它的border和padding,内容区的实际宽度是width减去(border + padding)的值。大多数情况下,这使得我们更容易地设定一个元素的宽高。
1. [width] 和 [height] 属性包括内容,内边距和边框,但不包括外边距。这是当文档处于 Quirks模式 时Internet Explorer使用的[盒模型](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Box_Model/Introduction_to_the_CSS_box_model)。注意,填充和边框将在盒子内 , 例如, .box {width: 350px; border: 10px solid black;} 导致在浏览器中呈现的宽度为350px的盒子。内容框不能为负,并且被分配到0,使得不可能使用border-box使元素消失。
1. 尺寸计算公式:
1. _width = border + padding + 内容的宽度_
1. _height = border + padding + 内容的高度_
- JS如何设置获取盒模型对应的宽和高
- dom.style.width/height 只能取到内联样式的尺寸
- dom.currentStyle.width/height 得到的是渲染的尺寸 【只有IE支持】
- window.getComputedStyle(dom).width/height 【支持谷歌和safari】
- dom.getBoundingClientRect().width/height 计算元素的绝对位置 【据窗口左上角的位置】

- BFC(边距重叠解决方案)
- BFC概念:块级格式化上下文
- 父子元素、兄弟元素、空元素会出现【边距重叠】
- BFC原理:
- BFC垂直方向的边距会出现重叠
- BFC区域不会与浮动元素重叠
- BFC在页面上是一个独立的容器,外边与里面的元素不会相互影响
- 计算BFC高度时,浮动元素会参与计算
- 如何创建BFC:
- float 的值不是 none
- position 的值不是static或者relative。(absolute,fixed)
- display的值是inline-block、table-cell、flex、table-caption或者inline-flex
- overflow 的值不是 visible(hidden,auto,scroll)
- BFC的使用场景
- 运算符

- 会发生类型转换
- 字符串拼接
- ==运算符
- if语句
- 逻辑运算
- 算术运算符【+ - / % * 幂 ++ —】
- 0除以正数,得到结果 Infinity (正无穷)
- 0除以负数,得到结果 -Infinity (负无穷)
- 0除以0,得到结果 NaN (Not a Number,非数字)
- %,求模
- 余数的符号,与被除数相同。
- 除加号之外的算术运算符
- 将原始类型转换为数字类型(自动完成转换),然后进行运算。
- boolean: true -> 1, false -> 0
- string: 如果字符串内部是正确的数字,直接变为数字,如果是一个非数字,则得到NaN(能识别Infinity,不能把字符串内部的东西当作表达式),如果字符串是一个空字符串(没有任何内容),转换为0. 字符串转换时,会忽略前后空格。
- NaN虽然是数字,与任何数字作任何运算,得到的结果都是NaN
- null:null -> 0
- undefined: undefined -> NaN
- 将对象类型先转换为字符串类型,然后再将该字符串转换为数字类型
- 对象类型 -> “[object Object]” -> NaN
- 加号运算符
- 加号一边有字符串,含义变为字符串拼接
- 将另一边的其他类型,转换为字符串
- 数字 -> 数字字符串
- boolean -> boolean字符串
- null -> “null”
- undefined -> “undefined”
- 对象 -> “[object Object]”
- 加号两边都没有字符串,但一边有对象,将对象转换为字符串,然后按照上面的规则进行
- 自增和自减
- 基本功能
- 一元运算符
- ++:将某个变量的值自增1
- —:将某个变量的值自减1
- 细节
- x++: 将变量x自增1,得到的表达式的值是自增之前的值。
- ++x: 将变量x自增1,得到的表达式的值是自增之后的值。
- x—: 将 变量x自减1,得到的表达式的值是自减之前的值。
- —x: 将变量x自减1,得到的表达式的值是自减之后的值。
- 比较运算符
- 大小比较:> < >= <=
- 相等比较:== != === !==
- 比较运算符的返回类型:boolean
- 算术运算符的优先级高于比较运算符
- NaN与任何数字比较,得到的结果都是false
- Infinity比任何数字都大
- -Infinity比任何数字都小
- 细节
- 两个字符串比较大小,比较的是字符串的字符编码。
- 如果一个不是字符串,并且两个都是原始类型,将它们都转换为数字进行比较
- ‘1’ -> 1
- ‘’ -> 0
- ‘ ‘ -> 0
- ‘ a’ -> NaN
- ‘3.14’ -> 3.14
- null -> 0
- undefined -> NaN
- 如果其中一个是对象,将对象转换为原始类型然后,按照规则1或规则2进行比较
- 目前,对象转换为原始类型后,是字符串 “[object Object]” ->NaN
- == 和 != (相等比较 和 不相等比较)
- ==: 比较两个数据是否相等
- 何时使用===和==|
if (obj.a == null) { //这里相当于obj.a === null || obj.a === undefined,简写形式 //这是jquery源码中推荐的写法 }
1. !=: 比较两个数据是否不相等
1. **细节**
1. 两端的类型相同,直接比较两个数据本身是否相同(两个对象比较的地址)
1. 两端的类型不同
1. 1). null 和 undefined, 它们之间相等, 和其他原始类型比较, 则不相等。
1. 2). 其他原始类型,比较时先转换为数字,再进行比较
1. 3). NaN与任何数字比较,都是false,包括自身
1. 4). Infinity和-Infinity,只能和自身相等
1. 5). 对象比较时,要先转换为原始类型后,再进行比较
3. === 和 !== (严格相等 和 严格不相等)
1. === : 两端的数据和类型必须相同
1. !== : 两端的数据或类型不相同
1. 两端类型相同,规则和相等比较一致。
1. 两端类型不同,为false。
1. 数字规则:
1. 1). NaN与任何数字比较,都是false,包括自身
1. 2). Infinity和-Infinity,自能和自身相等
- 逻辑运算符

1. 与(并且)【&&】
1. 书写方式: 表达式1 && 表达式2
1. 将表达式1 进行 boolean 判定
1. **以下数据均判定为false:**
1. **null**
1. **undefined**
1. **false**
1. **NaN**
1. **''**
1. **0**
4. **其他数据全部为真**
4. 如果表达式1的判定结果为假,则直接返回表达式1,而不执行表达式2;否则,返回表达式2的结果。 (短路规则)
2. 或【||】
1. 写法:表达式1 || 表达式2
1. 将表达式1 进行 boolean 判定
1. 如果表达式1为真,直接返回表达式1,不运行表达式2;否则,返回表达式2
3. 非【!】
1. 写法: !数据
1. **将数据的boolean判定结果直接取反,非运算符一定返回boolean类型。**
4. **三目运算符**
1. 书写方式: 表达式1 ? 表达式2 : 表达式3
1. 对表达式1进行boolean判定
1. 如果判定结果为真,返回表达式2;否则,返回表达式3。
5. **类型转换不会影响原本的数据**
5. void 运算符
1. 普通写法: void 表达式
1. 函数写法: void(表达式)
1. 运行表达式,然后返回undefined
1. 这个运算符能向期望一个表达式的值是[undefined]的地方插入会产生副作用的表达式。
1. void 运算符通常只用于获取 undefined的原始值,一般使用void(0)(等同于void 0)。在上述情况中,也可以使用全局变量[undefined] 来代替(假定其仍是默认值)。
1. [立即调用的函数表达式](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Operators/void#%E7%AB%8B%E5%8D%B3%E8%B0%83%E7%94%A8%E7%9A%84%E5%87%BD%E6%95%B0%E8%A1%A8%E8%BE%BE%E5%BC%8F)
1. 在使用[立即执行的函数表达式](https://developer.mozilla.org/zh-CN/docs/Glossary/IIFE)时,可以利用 void 运算符让 JavaScript 引擎把一个function关键字识别成函数表达式而不是函数声明(语句)。
void function iife() { };
1. [在箭头函数中避免泄漏](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Operators/void#%E5%9C%A8%E7%AE%AD%E5%A4%B4%E5%87%BD%E6%95%B0%E4%B8%AD%E9%81%BF%E5%85%8D%E6%B3%84%E6%BC%8F)
1. 箭头函数标准中,允许在函数体不使用括号来直接返回值。 如果右侧调用了一个原本没有返回值的函数,其返回值改变后,则会导致非预期的副作用。 安全起见,当函数返回值是一个不会被使用到的时候,应该使用 void 运算符,来确保返回 [undefined](如下方示例),这样,当 API 改变时,并不会影响箭头函数的行为。
button.onclick = () => void doSomething();
1. 确保了当 doSomething 的返回值从 [undefined] 变为 true 的时候,不会改变函数的行为
1. typeof 运算符
1. 普通写法: typeof 表达式
1. 函数写法: typeof(表达式)
1. typeof运算,返回表达式的类型,是一个字符串。
1. <br />

- 字符串拼接
- 使用加号运算符
- 连接字符串最简便的方法是使用加号运算符。
- 示例1
- 下面代码使用加号运算符连接两个字符串。
- 使用加号运算符
var s1 = “abc” , s2 = “def”; console.log(s1 + s2); //返回字符串“abcdef”
1. 使用concat()方法
1. 使用字符串 concat() 方法可以把多个参数添加到指定字符串的尾部。该方法的参数类型和个数没有限制,它会把所有参数都转换为字符串,然后按顺序连接到当前字符串的尾部最后返回连接后的字符串。
1. 示例2
1. 下面代码使用 concat() 方法把多个字符串连接在一起。
var s1 = “abc”; var s2 = s1.concat(“d” , “e” , “f”); //调用concat()连接字符串 console.log(s2); //返回字符串“abcdef” concat() 方法不会修改原字符串的值,与数组的 concat() 方法操作相似。
1. 使用join()方法
1. 在特定的操作环境中,也可以借助数组的 join() 方法来连接字符串,如 HTML 字符串输出等。
1. 示例3
1. 下面代码演示了如何借助数组的方法来连接字符串。
var s = “JavaScript” , a = []; for (var i = 0; i < 1000; i ++) { a.push(s); var str = a.join(“”); a = null; document.write(str);
1. 在上面示例中,使用 for 语句把 1000 个 “JavaScript”字符串装入数组,然后调用数组的 join() 方法把元素的值连接成一个长长的字符串。使用完毕应该立即清除数组,避免占用系统资源。
1. 在传统浏览器中,使用数组的 join() 方法连接超大字符串时,速度会很快,是推荐的最佳方法。随着现代浏览器优化了加号运算符的算法,使用加号运算符连接字符串速度也非常快,同时使用简单。一般推荐使用加号运算符来连接字符串,而 concat() 和 join() 方法可以用在特定的代码环境中。
- 随机排序
- 一、顺序排序
- 1、按字符编码排序:sort()
- 一、顺序排序
var testArray=[23,500,1000,300,34,-2]; testArray.sort(); alert(testArray); //-2,1000,23,300,34,500
1. 2、将数组元素倒序排:reverse()
var testArray=[-2,53,34,300,500,1000]; testArray.reverse(); alert(testArray); //1000,500,300,34,53,-2
1. 3、在sort()里面加个比较函数(从小到大排)
var testArray=[23,500,1000,300,34,-2]; //传给sort一个比较函数,如果比较函数return值小于0,则表示a必须出现在b前面,否则在b后面。 testArray.sort(function(a,b){return a-b;}); alert(testArray); //-2,23,34,300,500,1000
1. 4、快速排序
1. 效率相比上面的方法最高。
1. 看不懂下面代码的话可以参考:快速排序(Quicksort)的Javascript实现
var testArray=[‘df’, ‘rtr’, ‘wy’, ‘dafd’, ‘dfs’, ‘wefa’, ‘tyr’, ‘rty’, ‘rty’, ‘ryt’, ‘afds’, ‘wer’, ‘te’]; var testArray2=[23,500,1000,300,34,-2]; //快速排序函数 var quickSort = function(arr) { if (arr.length <= 1) { return arr; } var pivotIndex = Math.floor(arr.length / 2); var pivot = arr.splice(pivotIndex, 1);//将基准分离出 var left = []; var right = []; for (var i = 0; i < arr.length; i++){ if (arr[i] < pivot) { left.push(arr[i]); } else { right.push(arr[i]); } } return quickSort(left).concat([pivot], quickSort(right)); }; //调用输出 alert(quickSort(testArray));//afds,dafd,df,dfs,rtr,rty,rty,ryt,te,tyr,wefa,wer,wy alert(quickSort(testArray2)); //-2,23,34,300,500,1000
1. 二、随机打乱排序(乱序)
1. 1、低效版:
1. 原理:和上面数组排序的2原理一样,让比较函数随机传回-1或1即可。
1. 这种方法打乱10000个元素的数组,所用时间大概在35ms上下,比较低效。
var testArray=[-2,23,34,300,500,1000]; testArray.sort(function(){return Math.random()>0.5?-1:1;}); alert(testArray); //结果不唯一
1. 2、高效版:
1. (1)洗牌算法:
这种方法打乱10000个元素的数组来测试仅需要7,8毫秒的时间。
var testArray=[-2,23,34,300,500,1000]; if (!Array.prototype.derangedArray) { Array.prototype.derangedArray = function() { for(var j, x, i = this.length; i; j = parseInt(Math.random() * i), x = this[—i], this[i] = this[j], this[j] = x); return this; }; } alert(testArray.derangedArray());//结果不唯一
1. (2)这个简单明了,且复杂度为 O(n)
function shuffle(arr) { var len = arr.length; for (var i = 0; i < len - 1; i++) { var index = parseInt(Math.random() * (len - i)); var temp = arr[index]; arr[index] = arr[len - i - 1]; arr[len - i - 1] = temp; } return arr; } var arr = [-2,1,3,4,5,6,7,8,9]; console.log(shuffle(arr));//结果不唯一
- JSON 【不过是一个JS对象】
- JSON.stringify({a:10,b:20}) //把对象变为字符串
- JSON.parse(‘{“a”:10,”b”:20}’) //把字符串变为对象
- 构造函数、原型、原型



1. var arr =[]; arr instanceof Array //ture typeof arr //object typeof是无法判断数组的 2、 function Elem(id) { this.elem = document.getElementById(id) } Elem.prototype.html = function (val) { var elem = this.elem; if (val) { elem.innerHTML = val; return this // } else { return elem.innerHTML } } Elem.prototype.on = function (type, fn) { var elem = this.elem; elem.addEventListener(type, fn) } var div1 = new Elem('div') console.log(div1.html(<p>hello imooc</p>).on('click', function () { alert('clicked') })) 3、创建一个新对象 this指向新对象 执行代码,即对this赋值 返回this
- 构造函数




- 原型 prototype
- 所有函数都有一个属性:prototype,称之为函数原型
- 默认情况下,prototype 是一个普通的 Object 对象
- 默认情况下,prototype 中有一个属性,constructor,它也是一个对象,它指向构造函数本身。

1. 函数是通过new Function创建
1. <br />

1. 每个函数都有原型对象型中的constructor指向函数本身
- 隐式原型 proto。
- 所有的引用类型(数组、对象、函数),都具有对象特性,即可自由扩展属性(除了“null”除外)
- 所有的对象都有一个属性:proto,称之为隐式原型
- 默认情况下,隐式原型指向创建该对象的函数的原型。
- 所有对象的隐式原型指向创建该对象的函数的原型
- 当访问一个对象的成员时:
- 看该对象自身是否拥有该成员,如果有直接使用
- 在原型链中依次查找是否拥有该成员,如果有直接使用

- 原型链



1. 特殊点:
1. Function 的**proto**指向自身的 prototype
1. Object 的 prototype 的**proto**指向 null
2. <br />

1. 原型链的应用
1. 基础方法
1. W3C 不推荐直接使用系统成员**proto**
1. **Object.getPrototypeOf(对象)**
获取对象的隐式原型
1. **Object.prototype.isPrototypeOf(对象)**
判断当前对象(this)是否在指定对象的原型链上
1. **对象 instanceof 函数**
判断函数的原型是否在对象的原型链上
1. **Object.create(对象)**
创建一个新对象,其隐式原型指向指定的对象
1. **Object.prototype.hasOwnProperty(属性名)**
判断一个对象自身是否拥有某个属性
- 执行上下文、this、作用域、作用域链、闭包


- 执行上下文
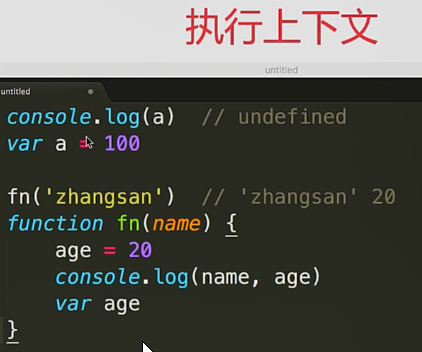
1. 执行上下文
1. 范围:一段<script>或者一个函数
1. 全局:变量定义、函数声明
1. 函数:变量定义、函数声明、this、arguments
1. PS:注意“函数声明”和“函数表达式”的区别
- this
- this要在执行时才能确认值,定义时无法确认
var a = { name: ‘A’, fn: function () { console.log(this.name) } } a.fn() // this === a a.fn.call({name: ‘B’}) // this === {name: ‘B’) var fnl = a.fn fnl() // this === window
1. 说明this几种不同的使用场景
1. 作为构造函数执行
1. 作为对象属性执行
1. 作为普通函数执行
1. call apply bind
- 作用域

1. 自由变量
1. 作用域链,即自由变量的查找
1. 闭包的两个场景
1. 团数作为返回值(上一个demo)
1. 团数作为参数传递(自己思考)
- 作用域链

- 闭包
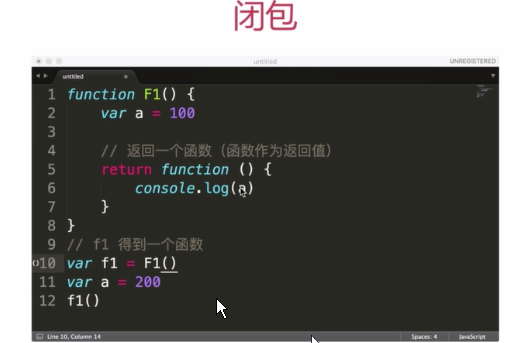

- 异步、单线程
- 同步和异步的区别是什么?分别举一个同步和异步的例子
- 同步会阻塞代码执行,而异步不会
- alert是同步的,setTimeout是异步的
- 一个关于setTimeout的笔试题
- 同步和异步的区别是什么?分别举一个同步和异步的例子

- 前端使用异步的场景有哪些
- 定时任务:setTimeout, setlnverval
- JS setTimeout 和 setInterval 的区别
- setTimeout 和 setInterval 都属于 JS 中的定时器,可以规定延迟时间再执行某个操作,不同的是 setTimeout 在规定时间后执行完某个操作就停止了(setTimeout 只执行一次那段代码。),而 setInterval 在执行完一次代码之后,经过了那个固定的时间间隔,它还会自动重复执行代码。
- JS setTimeout 和 setInterval 的区别
- 定时任务:setTimeout, setlnverval
function **fun**() { **alert**("hello"); } setTimeout(fun, 1000); //*参数是函数名* setTimeout("fun()", 1000); //*参数是字符串* setInterval(fun, 1000); setInterval("fun(),1000"); 在上述代码中,无论是 setTimeout 还是 setInterval,在使用函数名作为调用句柄时不能带参数,使用字符串调用时可以带参数。例如:setTimeout(‘fun(name)’,1000);
它们都有两个参数,一个是将要执行的代码字符串,还有一个是以毫秒为单位的时间间隔,当过了那个时间段之后就将执行那段代码。
window.setTimeout(“function”,time);//设置一个超时对象,只执行一次,无周期-
window.setInterval(“function”,time);//设置一个超时对象,周期=’交互时间’
停止定时:
window.clearTimeout(对象) 清除已设置的 setTimeout 对象
window.clearInterval(对象) 清除已设置的 setInterval 对象
1. 不再单独再定义一个函数,直接将函数调用放在一个函数里面,可以使用函数名作为调用调用句柄。
function **fun**(*name*) { **alert**("hello" + " " + name); } setTimeout(function () { **fun**("Tom"); }, 1000); //*参数是函数名* 在上述代码中,setTimeout 和 setInterval 的区别就是 setTimeout 延迟一秒弹出’hello’,之后便不再运行;而 setInterval 则会隔一秒弹出’hello’,直至用 clear 来清除定时器的语法。
1. requestAnimationFrame,与 setTimeout 相比 requestAnimationFrame 最大的优势是由系统来决定回调函数的执行时机,它能保证回调函数在屏幕每一次的刷新间隔中只被执行一次,这样就不会引起丢帧现象,常用于动画场景。
window.requestAnimationFrame(callback);
1. 实例
实现一个打点计时器,要求
1、从 start 到 end(包含 start 和 end),每隔 100 毫秒 console.log 一个数字,每次数字增幅为 1;
2、返回的对象中需要包含一个 cancel 方法,用于停止定时操作;
3、第一个数需要立即输出.
function **count**(*start*, *end*) { //*立即输出第一个数* console.**log**(start++); //* 重复执行函数* var timer = setInterval(function () { //* 判断首是否小于尾* if (start <= end) { console.**log**(start++); }else { clearInterval(timer); } },100); //* 返回对象* return{ **cancel**: function () { clearInterval(timer); } } } **count**(2,6);
1. 网络请求:ajax请求,动态<img>加载
1. 事件绑定
- 日期、Math
- 获取2017-06-10格式的日期

- 获取随机数,要求是长度一致的字符串格式

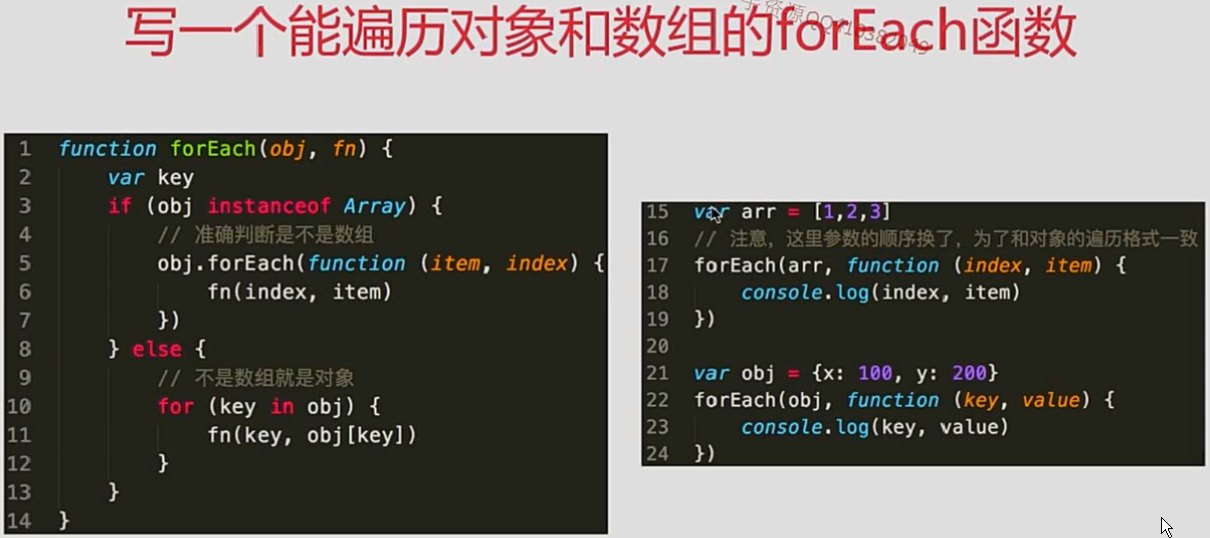
- 写一个能遍历对象和数组的通用forEach涵数
- 日期
- Date.now() // 获取当前时间毫秒
- var dt = new Date()
- dt.getTime() //获取豪秒数
- dt.getFullYear() // 年
- dt.getMonth() //月(0-11)
- dt.getDate() // 日(0 - 31)
- dt.getHours() // 小时(0 - 23)
- dt.getMinutes() // 分钟(0 - 59)
- dt.getSeconds() //秒(0-59)
- 数组、对象
- 数组的所有方法
- JavaScript中创建数组有两种方式
- (一)使用 Array 构造函数:
- JavaScript中创建数组有两种方式
var arr1 = new Array(); //创建一个空数组 var arr2 = new Array(20); // 创建一个包含20项的数组 var arr3 = new Array(“lily”,“lucy”,“Tom”); // 创建一个包含3个字符串的数组
1. (二)var 创建数组
var arr4 = []; //创建一个空数组 var arr5 = [20]; // 创建一个包含1项的数组 var arr6 = [“lily”,“lucy”,“Tom”]; // 创建一个包含3个字符串的数组
1. 1、join()
1. 通过join()方法可以实现重复字符串,只需传入字符串以及重复的次数,就能返回重复后的字符串,函数如下:
function repeatString(str, n) { return new Array(n + 1).join(str); } console.log(repeatString(“abc”, 3)); // abcabcabc console.log(repeatString(“Hi”, 5)); // HiHiHiHiHi
1. 2、push()和pop()
1. push(): 可以接收任意数量的参数,把它们逐个添加到数组末尾,并返回修改后数组的长度。
1. pop():数组末尾移除最后一项,减少数组的 length 值,然后返回移除的项。
var arr = [“Lily”,“lucy”,“Tom”]; var count = arr.push(“Jack”,“Sean”); console.log(count); // 5 console.log(arr); // [“Lily”, “lucy”, “Tom”, “Jack”, “Sean”] var item = arr.pop(); console.log(item); // Sean console.log(arr); // [“Lily”, “lucy”, “Tom”, “Jack”]
1. 3、shift() 和 unshift()
1. shift():删除原数组第一项,并返回删除元素的值;如果数组为空则返回undefined 。
1. unshift:将参数添加到原数组开头,并返回数组的长度 。
1. 这组方法和上面的push()和pop()方法正好对应,一个是操作数组的开头,一个是操作数组的结尾。
var arr = [“Lily”,“lucy”,“Tom”]; var count = arr.unshift(“Jack”,“Sean”); console.log(count); // 5 console.log(arr); //[“Jack”, “Sean”, “Lily”, “lucy”, “Tom”] var item = arr.shift(); console.log(item); // Jack console.log(arr); // [“Sean”, “Lily”, “lucy”, “Tom”]
1. 4、sort()
1. sort():按升序排列数组项——即最小的值位于最前面,最大的值排在最后面。
1. 在排序时,sort()方法会调用每个数组项的 toString()转型方法,然后比较得到的字符串,以确定如何排序。即使数组中的每一项都是数值, sort()方法比较的也是字符串,因此会出现以下的这种情况:
var arr1 = [“a”, “d”, “c”, “b”]; console.log(arr1.sort()); // [“a”, “b”, “c”, “d”] arr2 = [13, 24, 51, 3]; console.log(arr2.sort()); // [13, 24, 3, 51] console.log(arr2); // 13, 24, 3, 51
1. 为了解决上述问题,sort()方法可以接收一个比较函数作为参数,以便我们指定哪个值位于哪个值的前面。比较函数接收两个参数,如果第一个参数应该位于第二个之前则返回一个负数,如果两个参数相等则返回 0,如果第一个参数应该位于第二个之后则返回一个正数。以下就是一个简单的比较函数:
function compare(value1, value2) { if (value1 < value2) { return -1; } else if (value1 > value2) { return 1; } else { return 0; } } arr2 = [13, 24, 51, 3]; console.log(arr2.sort(compare)); // [3, 13, 24, 51]
1. 如果需要通过比较函数产生降序排序的结果,只要交换比较函数返回的值即可:
function compare(value1, value2) { if (value1 < value2) { return 1; } else if (value1 > value2) { return -1; } else { return 0; } } arr2 = [13, 24, 51, 3]; console.log(arr2.sort(compare)); // [51, 24, 13, 3]
1. 5、reverse():反转数组项的顺序。
var arr = [13, 24, 51, 3]; console.log(arr.reverse()); //[3, 51, 24, 13] console.log(arr); //3, 51, 24, 13
1. 6、concat()
1. concat() :将参数添加到原数组中。这个方法会先创建当前数组一个副本,然后将接收到的参数添加到这个副本的末尾,最后返回新构建的数组。在没有给 concat()方法传递参数的情况下,它只是复制当前数组并返回副本。
var arr = [1,3,5,7]; var arrCopy = arr.concat(9,[11,13]); console.log(arrCopy); //[1, 3, 5, 7, 9, 11, 13] console.log(arr); // 1, 3, 5, 7
1. 从上面测试结果可以发现:传入的不是数组,则直接把参数添加到数组后面,如果传入的是数组,则将数组中的各个项添加到数组中。但是如果传入的是一个二维数组呢?
var arrCopy2 = arr.concat([9,[11,13]]); console.log(arrCopy2); //[1, 3, 5, 7, 9, Array[2]] console.log(arrCopy2[5]); //[11, 13]
1. 上述代码中,arrCopy2数组的第五项是一个包含两项的数组,也就是说concat方法只能将传入数组中的每一项添加到数组中,如果传入数组中有些项是数组,那么也会把这一数组项当作一项添加到arrCopy2中。
1. 7、slice()
1. slice():返回从原数组中指定开始下标到结束下标之间的项组成的新数组。slice()方法可以接受一或两个参数,即要返回项的起始和结束位置。在只有一个参数的情况下, slice()方法返回从该参数指定位置开始到当前数组末尾的所有项。如果有两个参数,该方法返回起始和结束位置之间的项——但不包括结束位置的项。
var arr = [1,3,5,7,9,11]; var arrCopy = arr.slice(1); var arrCopy2 = arr.slice(1,4); var arrCopy3 = arr.slice(1,-2); var arrCopy4 = arr.slice(-4,-1); console.log(arr); //1, 3, 5, 7, 9, 11 console.log(arrCopy); //[3, 5, 7, 9, 11] console.log(arrCopy2); //[3, 5, 7] console.log(arrCopy3); //[3, 5, 7] console.log(arrCopy4); //[5, 7, 9]
1. arrCopy只设置了一个参数,也就是起始下标为1,所以返回的数组为下标1(包括下标1)开始到数组最后。
1. arrCopy2设置了两个参数,返回起始下标(包括1)开始到终止下标(不包括4)的子数组。
1. arrCopy3设置了两个参数,终止下标为负数,当出现负数时,将负数加上数组长度的值(6)来替换该位置的数,因此就是从1开始到4(不包括)的子数组。
1. arrCopy4中两个参数都是负数,所以都加上数组长度6转换成正数,因此相当于slice(2,5)。
1. 8、splice()
1. splice():很强大的数组方法,它有很多种用法,可以实现删除、插入和替换。
1. 删除:可以删除任意数量的项,只需指定 2 个参数:要删除的第一项的位置和要删除的项数。例如, splice(0,2)会删除数组中的前两项。
1. 插入:可以向指定位置插入任意数量的项,只需提供 3 个参数:起始位置、 0(要删除的项数)和要插入的项。例如,splice(2,0,4,6)会从当前数组的位置 2 开始插入4和6。
1. 替换:可以向指定位置插入任意数量的项,且同时删除任意数量的项,只需指定 3 个参数:起始位置、要删除的项数和要插入的任意数量的项。插入的项数不必与删除的项数相等。例如,splice (2,1,4,6)会删除当前数组位置 2 的项,然后再从位置 2 开始插入4和6。
1. splice()方法始终都会返回一个新数组,该数组中包含从原始数组中删除的项,如果没有删除任何项,则返回一个空数组。
var arr = [1,3,5,7,9,11]; var arrRemoved = arr.splice(0,2); console.log(arr); //[5, 7, 9, 11] console.log(arrRemoved); //[1, 3] var arrRemoved2 = arr.splice(2,0,4,6); console.log(arr); // [5, 7, 4, 6, 9, 11] console.log(arrRemoved2); // [] var arrRemoved3 = arr.splice(1,1,2,4); console.log(arr); // [5, 2, 4, 4, 6, 9, 11] console.log(arrRemoved3); //[7]
1. 9、indexOf()和 lastIndexOf()
1. indexOf():接收两个参数:要查找的项和(可选的)表示查找起点位置的索引。其中, 从数组的开头(位置 0)开始向后查找。
1. lastIndexOf:接收两个参数:要查找的项和(可选的)表示查找起点位置的索引。其中, 从数组的末尾开始向前查找。
1. 这两个方法都返回要查找的项在数组中的位置,或者在没找到的情况下返回1。在比较第一个参数与数组中的每一项时,会使用全等操作符。
var arr = [1,3,5,7,7,5,3,1]; console.log(arr.indexOf(5)); //2 console.log(arr.lastIndexOf(5)); //5 console.log(arr.indexOf(5,2)); //2 console.log(arr.lastIndexOf(5,4)); //2 console.log(arr.indexOf(“5”)); //-1
1. 10、forEach()
1. forEach():对数组进行遍历循环,对数组中的每一项运行给定函数。这个方法没有返回值。参数都是function类型,默认有传参,参数分别为:遍历的数组内容;第对应的数组索引,数组本身。
var arr = [1, 2, 3, 4, 5]; arr.forEach(function(x, index, a){ console.log(x + ‘|’ + index + ‘|’ + (a === arr)); }); // 输出为: // 1|0|true // 2|1|true // 3|2|true // 4|3|true // 5|4|true
1. 11、map()
1. map():指“映射”,对数组中的每一项运行给定函数,返回每次函数调用的结果组成的数组。
1. 下面代码利用map方法实现数组中每个数求平方。
var arr = [1, 2, 3, 4, 5]; var arr2 = arr.map(function(item){ return item*item; }); console.log(arr2); //[1, 4, 9, 16, 25]
1. 12、filter()
1. filter():“过滤”功能,数组中的每一项运行给定函数,返回满足过滤条件组成的数组。
var arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; var arr2 = arr.filter(function(x, index) { return index % 3 === 0 || x >= 8; }); console.log(arr2); //[1, 4, 7, 8, 9, 10]
1. 13、every()
1. every():判断数组中每一项都是否满足条件,只有所有项都满足条件,才会返回true。
var arr = [1, 2, 3, 4, 5]; var arr2 = arr.every(function(x) { return x < 10; }); console.log(arr2); //true var arr3 = arr.every(function(x) { return x < 3; }); console.log(arr3); // false
1. 14、some()
1. some():判断数组中是否存在满足条件的项,只要有一项满足条件,就会返回true。
var arr = [1, 2, 3, 4, 5]; var arr2 = arr.some(function(x) { return x < 3; }); console.log(arr2); //true var arr3 = arr.some(function(x) { return x < 1; }); console.log(arr3); // false
1. 15、reduce()和 reduceRight()
1. 这两个方法都会实现迭代数组的所有项,然后构建一个最终返回的值。reduce()方法从数组的第一项开始,逐个遍历到最后。而 reduceRight()则从数组的最后一项开始,向前遍历到第一项。
1. 这两个方法都接收两个参数:一个在每一项上调用的函数和(可选的)作为归并基础的初始值。
1. 传给 reduce()和 reduceRight()的函数接收 4 个参数:前一个值、当前值、项的索引和数组对象。这个函数返回的任何值都会作为第一个参数自动传给下一项。第一次迭代发生在数组的第二项上,因此第一个参数是数组的第一项,第二个参数就是数组的第二项。
1. 下面代码用reduce()实现数组求和,数组一开始加了一个初始值10。
var values = [1,2,3,4,5]; var sum = values.reduceRight(function(prev, cur, index, array){ return prev + cur; },10); console.log(sum); //25
- 数组去重的方法
- 双重for循环去重
- 原理 两两比较如果相等的话就删除第二个
- 例如: 1 1 1 3 2 1 2 4
- 先让第一个1 即arr[0]与后面的一个个比较 如果后面的值等于arr[0] 删除后面的值
- 第一次结束后的结果是 1 3 2 2 4 删除了后面所有的1
- 同理 第二次 第三会删除与自己相同的元素
function noRepeat1(arr){ // 第一层for用来控制循环的次数 for(var i=0; i //第二层for 用于控制与第一层比较的元素 for(var j=i+1; j //如果相等 if(arr[i] == arr[j]){ //删除后面的 即第 j个位置上的元素 删除个数 1 个 arr.splice(j,1); // j—很关键的一步 如果删除 程序就会出错 //j—的原因是 每次使用splice删除元素时 返回的是一个新的数组 // 这意味这数组下次遍历是 比较市跳过了一个元素 / 例如: 第一次删除后 返回的是 1 1 3 2 1 2 4 但是第二次遍历是 j的值为2 arr[2] = 3 相当于跳过一个元素 因此要 j— */ j—; } } } return arr; }
1. 2. 单层for循环
1. 原理和方法一相似
function norepeat(arr){ arr.sort(); //先排序让大概相同的在一个位置,这里为什么说是大概相同 是因为sort排序是把元素当字符串排序的 它和可能排成 1 1 10 11 2 20 3 … 不是我们想要的从小到大 for(var i = 0; i < arr.length-1;i++){ //还是两两比较 一样删除后面的 if(arr[i]==arr[i+1]){ arr.splice(i,1); //i— 和j—同理 i—; } } return arr; }
1. 3. 原理:用一个空数组去存首次 出现的元素
1. 利用 indexOf 属性 indexOf是返回某个指定的字符在字符串中出现的位置,如果没有就会返回-1
1. 因此我们可以很好的利用这个属性 当返回的是 -1时 就让其存入数组
1. <br />
function noRepeat2(arr){ var newArr = []; for(var i = 0; i < arr.length; i++){ if(newArr.indexOf(arr[i]) == -1){ newArr.push(arr[i]); } } return newArr; }
1. 4. 原理:利用对象的思想 如果对象里没有这个属性的话就会返回undefined
1. 利用这个原理当返回的是undefined时 让其放入数组 然后在给这个属性赋值
function norepeat3(arr) { var obj = {}; var newArr = []; for(var i = 0; i < arr.length; i++) { if(obj[arr[i]] == undefined) { newArr.push(arr[i]); obj[arr[i]] = 1; } } return newArr; }
1. 5. 原理:循环比较如果相等的让后面的元素值为0 最后在输出的时候删除为0的 这个前提是你的数据里不能有0 但是凡事可以变通你可以设置任何值替代这个0
1. 这个方法是我当时想到实现的所以没有进行很好的优化
var newArr = []; //控制外循环 for(var i=0; i //内存循环 只比较后面的 for(j=i+1;j //如果相等就让其值等于0 if(arr[i]==arr[j]){ arr[j]=0; } } //去除值为0的 if(arr[i]==0){ continue; }else{ //放入新的数组 newArr.push(arr[i]); } }
1. 6. for循环嵌套,利用splice去重
1. 此方法是比较常用的方法之一,也是es5中比较实用的方法之一。话不多说,上代码:
function newArr(arr){ for(var i=0;i for(var j=i+1;j if(arr[i]==arr[j]){ //如果第一个等于第二个,splice方法删除第二个 arr.splice(j,1); j—; } } } return arr; } var arr = [1,1,2,5,6,3,5,5,6,8,9,8]; console.log(newArr(arr))
1. 7. 建新数组,利用indexOf去重
1. 此方法也是es5中比较简单的方法之一,基本思路是新建一个数组,原数组遍历传入新数组,判断值是否存在,值不存在就加入该新数组中;值得一提的是,方法“indexOf”是es5的方法,IE8以下不支持。话不多说,上代码:
function newArr(array){ //一个新的数组 var arrs = []; //遍历当前数组 for(var i = 0; i < array.length; i++){ //如果临时数组里没有当前数组的当前值,则把当前值push到新数组里面 if (arrs.indexOf(array[i]) == -1){ arrs.push(array[i]) }; } return arrs; } var arr = [1,1,2,5,5,6,8,9,8]; console.log(newArr(arr))
1. 8. ES6中利用Set去重
1. 此方法是所有去重方法中代码最少的方法,代码如下:
function newArr(arr){ return Array.from(new Set(arr)) } var arr = [1,1,2,9,6,9,6,3,1,4,5]; console.log(newArr(arr))
- 数组遍历的几种方法及用法
- 1、forEach方法
- forEach是最简单、最常用的数组遍历方法,它提供一个回调函数,可用于处理数组的每一个元素,默认没有返回值。
- 1、forEach方法

1. 以上是个简单的例子,计算出数组中大于等于3的元素的个数。
1. 回调函数的参数,第一个是处于当前循环的元素,第二个是该元素下标,第三个是数组本身。三个参数均可选。
1. 2、map方法
1. map,从字面上理解,是映射,即数组元素的映射。它提供一个回调函数,参数依次为处于当前循环的元素、该元素下标、数组本身,三者均可选。默认返回一个数组,这个新数组的每一个元素都是原数组元素执行了回调函数之后的返回值。
1. map方法不改变原数组。

1. <br />

1. 以上是一个简单的例子,把原数组的每一项乘以自身下标+1的数。
1. 3、filter方法
1. filter,过滤,即对数组元素的一个条件筛选。它提供一个回调函数,参数依次为处于当前循环的元素、该元素下标、数组本身,三者均可选。默认返回一个数组,原数组的元素执行了回调函数之后返回值若为true,则会将这个元素放入返回的数组中。
1. filter方法不改变原数组

1. <br />

1. 以上是一个简单的例子,筛选出原数组中,自身乘以下标大于等于3的元素。
1. 4、some、every方法
1. some方法和every的用法非常类似,提供一个回调函数,参数依次为处于当前循环的元素、该元素下标、数组本身,三者均可选。
1. 数组的每一个元素都会执行回调函数,当返回值全部为true时,every方法会返回true,只要有一个为false,every方法返回false。当有一个为true时,some方法返回true,当全部为false时,every方法返回false。
1. some、every方法不改变原数组。

1. <br />
1. 5、reduce方法
1. reduce方法有两个参数,第一个参数是一个回调函数(必须),第二个参数是初始值(可选)。回调函数有四个参数,依次为本轮循环的累计值、当前循环的元素(必须),该元素的下标(可选),数组本身(可选)。
1. reduce方法,会让数组的每一个元素都执行一次回调函数,并将上一次循环时回调函数的返回值作为下一次循环的初始值,最后将这个结果返回。
1. 如果没有初始值,则reduce会将数组的第一个元素作为循环开始的初始值,第二个元素开始执行回调函数。
1. 最常用、最简单的场景,是数组元素的累加、累乘。

1. <br />

1. reduce方法不改变原数组
1. 6、for of方法
1. es6新增了interator接口的概念,目的是对于所有数据结构提供一种统一的访问机制,这种访问机制就是for of。
1. 即:所有有interator接口的数据,都能用for of遍历。常见的包括数组、类数组、Set、Map等都有interator接口。

1. <br />

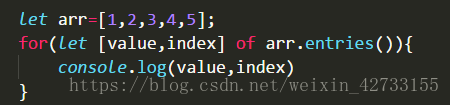
1. 如果想用for of的方法遍历数组,又想用Index,可以用for of遍历arr.entries()
1. <br />
- javascript中的关联数组
- 基本概念:
- “关联数组”是一种具有特殊索引方式的数组。不仅可以通过整数来索引它,还可以使用字符串或者其他类型的值(除了NULL)来索引它。关联数组的索引值是任意的标量,这些标量称为Keys,可以在以后用于检索数组中的数值。关联数组的元素没有特定的顺序。
- 关联数组长成什么样?
- 基本概念:
var defs = [W3C: “World Wide Web Consortium”, DOM: “Document Object Model”];
1. 如何定义关联数组?
var defs = []; defs[key] = value; 备注:key 和 value 需要分别赋予不同的值。
1. 如何遍历关联数组?
for (key in defs) { // 变量 key 可以直接使用。 var value = defs[key]; //每个key对于的值。 }
- 什么是类数组?
- 数组的特征有:可以通过角标调用,如 array[0];具有长度属性 length;可以通过 for 循环或 forEach 方法,进行遍历。
- 那么,类数组是什么呢?顾名思义,就是具备与数组特征类似的对象。比如,下面的这个对象,就是一个类数组。
let arrayLike = { 0: 1, 1: 2, 2: 3, length: 3, };
1. 类数组 arrayLike 可以通过角标进行调用,具有 length 属性,同时也可以通过 for 循环进行遍历。
1. 类数组,还是比较常用的,只是我们平时可能没注意到。比如,我们获取 DOM 节点的方法,返回的就是一个类数组。再比如,在一个方法中使用 arguments 获取到的所有参数,也是一个类数组。
1. 但是需要注意的是:类数组无法使用 forEach、splice、push 等数组原型链上的方法,毕竟它不是真正的数组。
- forEach 遍历所有元素

- every 判断所有元素是否都符合条件

- some 判断是否有至少一个元素符合条件

- sort 排序

- map 对元素重新组装,生成新数组

- filter 过滤符合条件的元素


- DOM、BOM
- DOM


1、树
1. DOM事件级别

1. DOM事件模型
1. prototype

1. Attribute


1. DOM事件流

1. 描述DOM事件捕获的具体流程

1. Event对象的常见应用
1. event.preventDefault() 阻止默认事件
1. event.stopPropagation() 阻止冒泡
1. event.stopImmediatePropagation() 事件响应
1. event.currentTarget()
1. event.target()
2. 自定义事件

1. 自定义事件 Event 与 CustomEvent
1. window.addEventListener() 添加事件监听
1. window.dispatchEvent() 抛出事件
1. Event算是一个顶级接口,CustomEvent基于Event,增加了部分参数
1. Event
event = new Event(typeArg, eventInit);
typeArg
是DOMString 类型,表示所创建事件的名称。
eventInit可选
是 EventInit 类型的字典,接受以下字段:
“bubbles”,可选,Boolean类型,默认值为 false,表示该事件是否冒泡。
“cancelable”,可选,Boolean类型,默认值为 false, 表示该事件能否被取消。
“composed”,可选,Boolean类型,默认值为 false,指示事件是否会在影子DOM根节点之外触发侦听器。
window.addEventListener(‘custom’, customHandler) function customHandler(params) { // 打印事件对象 在5秒后 出现打印,可以看到我们自定义的参数 console.log(params) } setTimeout(() => { // 创建自定义事件 let event = new Event(‘custom’); // 如果希望事件带参数,可以把参数放在事件对象上 event.name = ‘custom-name’; event.detail = { age: 20 } event.ppp = ‘这是一个锅’ // dispatchEvent 返回一个 boolean 值 let result = window.dispatchEvent(event) console.log(result); }, 5000)
1. CustomEvent
event = new CustomEvent(typeArg, customEventInit);
typeArg
一个表示 event 名字的字符串
customEventInit可选
一个字典类型参数,有如下字段
“detail”, 可选的默认值是 null 的任意类型数据,是一个与 event 相关的值
在展示使用detail作为第二个参数的例子前,要先注意一件事:CustomEventInit字典也可以接受EventInit字典的参数,就像一开始的例子一样,我传递了EventInit字典的bubbles、cancelable、composed。
bubbles 一个布尔值,表示该事件能否冒泡。 来自 EventInit。注意:测试chrome默认为不冒泡。
cancelable 一个布尔值,表示该事件是否可以取消。 来自 EventInitwindow.addEventListener('custom', customHandler) function customHandler(params) { // 打印事件对象 在5秒后 出现打印,可以看到我们自定义的参数 console.log(params) } setTimeout(() => { // 创建事件对象 let event = new CustomEvent('Eric', { // 这里可直接传入 自定义的事件参数 detail: { height: 100, widht: 100, rect: 10000 } }) // 同样 我们也可以直接在事件对象上绑定 参数 [event.name](http://event.name/) = 'custom-event' window.dispatchEvent(event) }, 5000)<script type="text/javascript"> /* 创建一个事件对象,名字为newEvent,类型为build */ var newEvent = new CustomEvent('build', { bubbles:true,cancelable:true,composed:true }); /* 给这个事件对象创建一个属性并赋值,这里绑定的事件要和我们创建的事件类型相同,不然无法触发 */ [newEvent.name](http://newevent.name/) = "新的事件!"; /* 将自定义事件绑定在document对象上 */ document.addEventListener("build",function(){ alert("你触发了使用CustomEvent创建的自定义事件!" + [newEvent.name](http://newevent.name/)); },false) /* 触发自定义事件 */ document.dispatchEvent(newEvent); </script>
下面将展示使用detail参数的例子,使用到detail的部分我会加粗处理(为了看着方便,这回就不传递EventInit字典中的参数了)
- BOM

1. 如何检测浏览器类型

1. 拆解url各部分

1. <br />



- 事件绑定、事件冒泡、代理、事件节流


- 通用事件绑定

- 事件冒泡

- 代理

1. 代理的好处
1. 代码简洁
1. 减少浏览器内存占用
- 事件节流

- Ajax、跨域、Http协议



- 跨域
- 什么是跨域
- 浏览器是有同源策略的,不允许ajax访问其他域接口
- 跨域条件:协议、域名、端口,有一个不同就跨域
- 允许跨域加载资源的标签 ,标签的使用场景
用于打点统计,统计网站可能是其他域
- // b.html window.onmessage = function(e) { console.log(e.data) //我爱你 e.source.postMessage(‘我不爱你’, e.origin) }
1. WebSocket 1. CORS- 安全

- CSRF
- 基本概念和缩写
- CSRF ,通俗称为跨站请求伪造,英文名Cross-site request forgery 缩写CSRF
- 攻击原理
- 网站存在漏洞,并用户登陆过
- 基本概念和缩写

1. 防御措施 1. Token验证 1. Referer验证 1. 隐藏令牌- XSS
- 基本概念和缩写
- XSS(cross-site scripting跨域脚本攻击)
- 攻击原理
- 向页面注入JS
- 防御措施
- 让XSS不可执行
- XSS跨站请求攻击
- 新浪博客写一篇文章,同时偷偷插入一段
 1. 可以捕获异常:
1. 由于网络请求异常不会事件冒泡,因此必须在捕获阶段将其捕捉到才行,但是这种方式虽然可以捕捉到网络请求的异常,但是无法判断 HTTP 的状态是 404 还是其他比如 500 等等,所以还需要配合服务端日志才进行排查分析才可以。
1. 注意:
1. 不同浏览器下返回的 error 对象可能不同,需要注意兼容处理。
1. 需要注意避免 window.addEventListener 重复监听。
3. 到此为止,我们学到了:在开发的过程中,对于容易出错的地方,可以使用try{}catch(){}来进行错误的捕获,做好兜底处理,避免页面挂掉。而对于全局的错误捕获,在现代浏览器中,我倾向于只使用使用window.addEventListener('error'),window.addEventListener('unhandledrejection')就行了。如果需要考虑兼容性,需要加上window.onerror,三者同时使用,window.addEventListener('error')专门用来捕获资源加载错误。
1. Promise Catch
1. 我们知道,在 promise 中使用 catch 可以非常方便的捕获到异步 error 。
1. 没有写catch的promise中抛出的错误无法被onerror或try...catch捕获到,所以务必在promise中写catch做异常处理。
1. 有没有一个全局捕获promise的异常呢?答案是有的。 Uncaught Promise Error就能做到全局监听,使用方式:
window.addEventListener("unhandledrejection", function(e){ // e.preventDefault(); // 阻止异常向上抛出 console.log('捕获到异常:', e); }); Promise.reject('promise error');
1. 同样可以捕获错误:
1. 所以,正如我们上面所说,为了防止有漏掉的 promise 异常,建议在全局增加一个对 unhandledrejection 的监听,用来全局监听 Uncaught Promise Error。
1. iframe 异常
1. 对于 iframe 的异常捕获,我们还得借力 window.onerror:
window.onerror = function(message, source, lineno, colno, error) { console.log('捕获到异常:',{message, source, lineno, colno, error}); }
1. 下面一个简单的例子:
1. 可以捕获异常:

1. 由于网络请求异常不会事件冒泡,因此必须在捕获阶段将其捕捉到才行,但是这种方式虽然可以捕捉到网络请求的异常,但是无法判断 HTTP 的状态是 404 还是其他比如 500 等等,所以还需要配合服务端日志才进行排查分析才可以。
1. 注意:
1. 不同浏览器下返回的 error 对象可能不同,需要注意兼容处理。
1. 需要注意避免 window.addEventListener 重复监听。
3. 到此为止,我们学到了:在开发的过程中,对于容易出错的地方,可以使用try{}catch(){}来进行错误的捕获,做好兜底处理,避免页面挂掉。而对于全局的错误捕获,在现代浏览器中,我倾向于只使用使用window.addEventListener('error'),window.addEventListener('unhandledrejection')就行了。如果需要考虑兼容性,需要加上window.onerror,三者同时使用,window.addEventListener('error')专门用来捕获资源加载错误。
1. Promise Catch
1. 我们知道,在 promise 中使用 catch 可以非常方便的捕获到异步 error 。
1. 没有写catch的promise中抛出的错误无法被onerror或try...catch捕获到,所以务必在promise中写catch做异常处理。
1. 有没有一个全局捕获promise的异常呢?答案是有的。 Uncaught Promise Error就能做到全局监听,使用方式:
window.addEventListener("unhandledrejection", function(e){ // e.preventDefault(); // 阻止异常向上抛出 console.log('捕获到异常:', e); }); Promise.reject('promise error');
1. 同样可以捕获错误:

1. 所以,正如我们上面所说,为了防止有漏掉的 promise 异常,建议在全局增加一个对 unhandledrejection 的监听,用来全局监听 Uncaught Promise Error。
1. iframe 异常
1. 对于 iframe 的异常捕获,我们还得借力 window.onerror:
window.onerror = function(message, source, lineno, colno, error) { console.log('捕获到异常:',{message, source, lineno, colno, error}); }
1. 下面一个简单的例子:
- Script error
- 在进行错误捕获的过程中,很多时候并不能拿到完整的错误信息,得到的仅仅是一个”Script Error”。
- 产生原因
- 由于12年前这篇文章里提到的安全问题:blog.jeremiahgrossman.com/2006/12/i-k…
- 当加载自不同域的脚本中发生语法错误时,为避免信息泄露,语法错误的细节将不会报告,而是使用简单的”Script error.”代替。
- 一般而言,页面的JS文件都是放在CDN的,和页面自身的URL产生了跨域问题,所以引起了”Script Error”。
- 解决办法
- 一般情况,如果出现 Script error 这样的错误,基本上可以确定是跨域问题。这时候,是不会有其他太多辅助信息的,但是解决思路无非如下:
- 跨源资源共享机制( CORS ):我们为 script 标签添加 crossOrigin 属性。
1. 崩溃和卡顿 1. 卡顿也就是网页暂时响应比较慢, JS可能无法及时执行。但崩溃就不一样了,网页都崩溃了,JS都不运行了,还有什么办法可以监控网页的崩溃,并将网页崩溃上报呢? 1. 1.利用 window 对象的 load 和 beforeunload 事件实现了网页崩溃的监控。window.addEventListener(‘load’, function () { sessionStorage.setItem(‘good_exit’, ‘pending’); setInterval(function () { sessionStorage.setItem(‘time_before_crash’, new Date().toString()); }, 1000); }); window.addEventListener(‘beforeunload’, function () { sessionStorage.setItem(‘good_exit’, ‘true’); }); if(sessionStorage.getItem(‘good_exit’) && sessionStorage.getItem(‘good_exit’) !== ‘true’) { / insert crash logging code here / alert(‘Hey, welcome back from your crash, looks like you crashed on: ‘ + sessionStorage.getItem(‘time_before_crash’)); }
1. 不错的文章,推荐阅读:[Logging Information on Browser Crashes](http://jasonjl.me/blog/2015/06/21/taking-action-on-browser-crashes/)。 1. 2.基于以下原因,我们可以使用 Service Worker 来实现[网页崩溃的监控](https://juejin.im/entry/5be158116fb9a049c6434f4a?utm_source=gold_browser_extension): 1. Service Worker 有自己独立的工作线程,与网页区分开,网页崩溃了,Service Worker一般情况下不会崩溃 1. Service Worker 生命周期一般要比网页还要长,可以用来监控网页的状态 1. 网页可以通过 navigator.serviceWorker.controller.postMessage API 向掌管自己的 SW 发送消息- VUE errorHandler
- 在Vue中,异常可能被Vue自身给try…catch了,不会传到window.onerror事件触发。不过不用担心,Vue提供了特有的异常捕获,比如Vux2.x中我们可以这样用:
Vue.config.errorHandler = function (err, vm, info) { let { message, // 异常信息 name, // 异常名称 script, // 异常脚本url line, // 异常行号 column, // 异常列号 stack // 异常堆栈信息 } = err; // vm为抛出异常的 Vue 实例 // info为 Vue 特定的错误信息,比如错误所在的生命周期钩子 }
- React 异常捕获
- 在React,可以使用ErrorBoundary组件包括业务组件的方式进行异常捕获,配合React 16.0+新出的componentDidCatch API,可以实现统一的异常捕获和日志上报。
- 我们来举一个小例子,在下面这个 componentDIdCatch(error,info) 里的类会变成一个 error boundary:
class ErrorBoundary extends React.Component { constructor(props) { super(props); this.state = { hasError: false }; } componentDidCatch(error, info) { // Display fallback UI this.setState({ hasError: true }); // You can also log the error to an error reporting service logErrorToMyService(error, info); } render() { if (this.state.hasError) { // You can render any custom fallback UI return Something went wrong. ; } return this.props.children; } }
1. 然后我们像使用普通组件那样使用它:1. componentDidCatch() 方法像JS的 catch{} 模块一样工作,但是对于组件,只有 class 类型的组件(class component )可以成为一个 error boundaries 。 1. 实际上,大多数情况下我们可以在整个程序中定义一个 error boundary 组件,之后就可以一直使用它了! 1. 需要注意的是:error boundaries并不会捕捉下面这些错误: 1. 事件处理器 1. 异步代码 1. 服务端的渲染代码 1. 在 error boundaries 区域内的错误- 总结
- 可疑区域增加 try…catch
- 全局监控JS异常: window.onerror
- 全局监控静态资源异常: window.addEventListener
- 全局捕获没有 catch 的 promise 异常:unhandledrejection
- iframe 异常:window.error
- VUE errorHandler 和 React componentDidCatch
- 监控网页崩溃:window 对象的 load 和 beforeunload
- Script Error跨域 crossOrigin 解决
- js延迟加载的六种方式
- defer 属性
- HTML 4.01 为
- Script error
- 新浪博客写一篇文章,同时偷偷插入一段
- 基本概念和缩写
- // b.html window.onmessage = function(e) { console.log(e.data) //我爱你 e.source.postMessage(‘我不爱你’, e.origin) }
- 什么是跨域

若有收获,就点个赞吧
0 人点赞
