开局之前
这很明显啊 因为hash冲突到了一个桶 你必然要链表啊,或者红黑树
链表+散列表的用武之地
把查找插入,删除的时间复杂度降到o(1)—->LRU
为什么用双向链表
这个说过好多次了啊,就是因为双向链表可以方便的知道前驱和后继
这样就方便删除一个节点,如果是单链表 给你一个节点 你能在o1的时间复杂度内删除?
因为删除本质上就是前驱指向了后继
查找
因为hashmap的查找复杂度是o(1),所以直接在hashmap中查
然后链表先删后增即可
删除
增加
加到链表头部和map中
如果满了就删除尾部
Java的linkedhashmap也是双链表+hashmap
课后思考
今天讲的几个散列表和链表结合使用的例子里,我们用的都是双向链表。如果把双向链表改成单链表,还能否正常工作呢?为什么呢?
方便删除
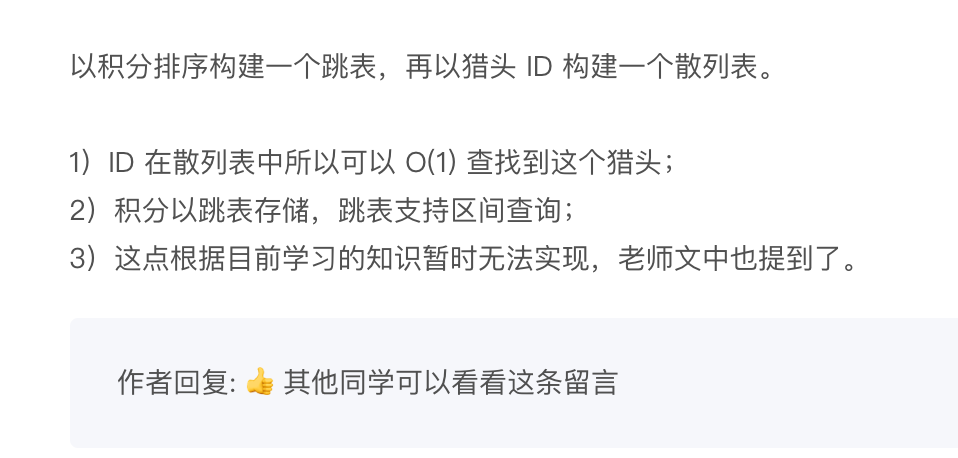
假设猎聘网有 10 万名猎头,每个猎头都可以通过做任务(比如发布职位)来积累积分,然后通过积分来下载简历。假设你是猎聘网的一名工程师,如何在内存中存储这 10 万个猎头 ID 和积分信息,让它能够支持这样几个操作:
根据猎头的 ID 快速查找、删除、更新这个猎头的积分信息;
单纯这个操作就是key-value即可
查找积分在某个区间的猎头 ID 列表;
全遍历一次?
查找按照积分从小到大排名在第 x 位到第 y 位之间的猎头 ID 列表。
全部排序遍历?或者使用redis的zset?

若有收获,就点个赞吧
0 人点赞
