1.HashMap的个线数据机构详解
HashMap数据机构 = 数组 + 线性链表 + 红黑数(当数组长度>=8的时候链表会转红黑树)
数组查询时间复杂度 = O(1)
链表查询时间复杂度 = O (N)-> 红黑树诞生 -> 问题:当插入多的时候,很容易打破树的平衡性 -> 维持再平衡(左旋、右旋)以及重新作色
数组长度必须是2的指数次幂,默认情况下,hashmap进行初始化操作的时候,会把数组长度和加载因子传递进来,如果传进来的数组长度不是2的指数次幂,会自动改成大于这个容量最接近的2的指数次幂的数,它为什么要去这么做呢?保证hashmap在获取下标的时候,数组下标在容量大小的范围内,位运算的特特点,还有就是如果不是2的次幂,那么位运算的结果会导致和取模结果不等价。哇,对,就是这两个原因。
加载因子为什么是0.75?因为hashmap为了使数据能够更加的散列,避免产生大量的hash碰撞,以空间换时间的方式,使得数据能够分散到容器当中去。
hashmap8中为什么当链表长度>=8的时候,会将链表转换成红黑数?概率统计学的算法,【泊松分布】算法,这个算法,可以使得一个链表形成之后,重复的定位在同一个桶里的概率,会成指数级的越来越小。
hashmap8比7性能高的并不多,8%-10%
hashmap产生循环链的原因是什么?
扩容前 = 容器大小 = 4

线程1 执行 => Entry
线程2 第一次遍历,此时的 e 和 next 同时指向了B节点
线程2 执行第2次循环 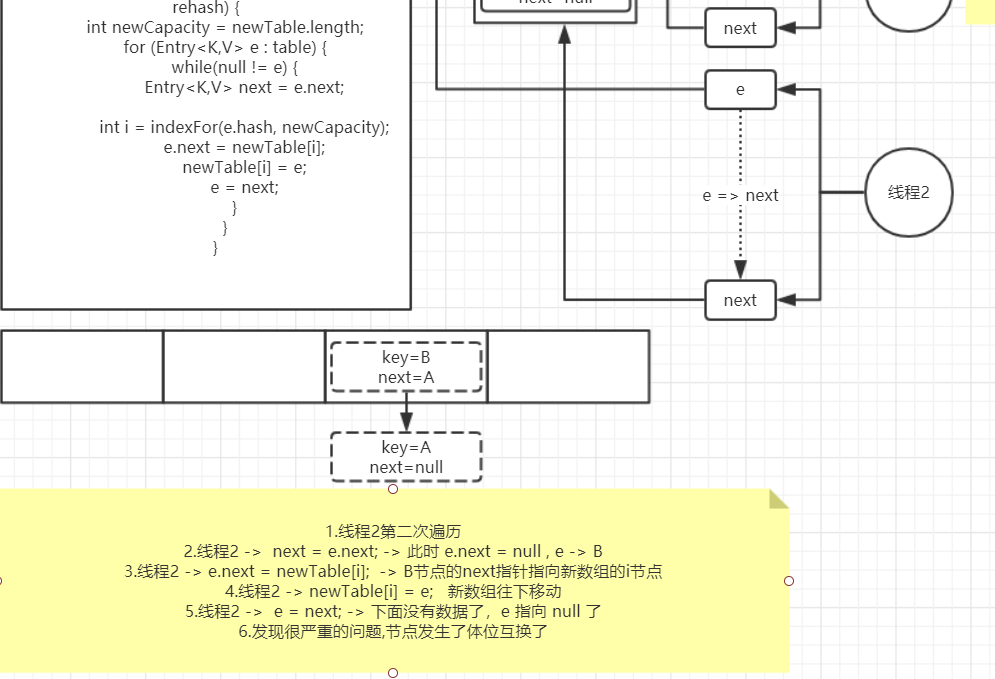
此时,造成了链表中的数据,发生了体位互换了
线程1 此时被唤醒,继续开始执行,由于迁移的时候,链表中的数据发生了体位互换,当指针指来指去的时候,就形成了链表环
hashmap8 提供了4组指针,2组高位,2组地位指针,同时把高位和低位的指针断掉,转移到同数组下标的新容器当中去,这样做的好处就是,不会形成循环链表了,同时扩容的时候不需要重新hash取下标,大大提高了性能。这里面还有一个点就是高位在进行迁移的时候是数组下标+老数组大小,所以说,这也是为什么,数组长度必须是2的指数次幂。但hashmap8还不是线程安全的,hashmap没有考虑在初始化阶段保证线程安全的。
2.为何初始化容量要是2的指数幂?加载因子为什么是0.75
3.Java7的hashmap扩容死锁演示与环链分析
4.Jdk8的hashmap扩容优化,如何做到扩容无需rehash?
5.CurrentHashMap线程安全吗?为什么是分段锁?
红黑树:接近于平衡的二叉树(O(logn))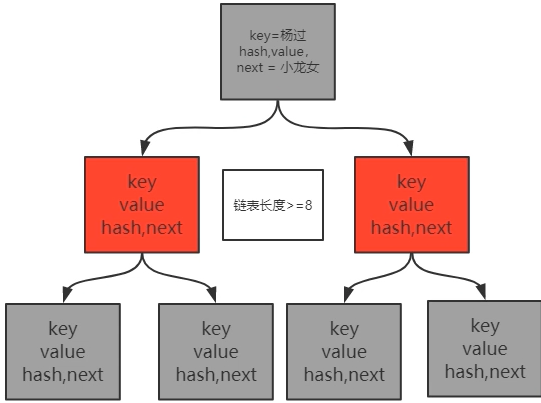
2.ConcurrentHashMap讲解
class Node(){private String key;private String value;private Node next; //单项链表方式}
class TreeNode(){private Node left; //左子树private Node right; //右子树private boolean red; //是否红}
1.先有数组:一定是在线程中执行的 main进行进行初始化的操作,单线程,多线程呢?Node[] table = new Node(16);resize() -> 对数组进行初始化static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;//16-> newCap = DEFAULT_INITIAL_CAPACITY; //设置大小-> newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); //设置阀值-> Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; //初始化操作table = newTab; //其中的1<<4的意思就是1向右位移四位,在1的后面补上4个0,也就是2^4次方2.key,value--Node();Node对象put数组中
Node[] table = new Node(16); //单线程情况下,无论怎么折腾,都不会有问题的T1:执行Task 16T2:执行Task 32在多线程的情况下操作,有可能和单线程的结果不一致。所以:HashTable 在put/get的时候使用了synchroized(lock)保证线程安全,但是效率很低。如何使用无锁化机制CAS,保证线程安全 -> Compare And Swap:比较并替换 -> 保证对某个线程操作安全Cas是一种乐观锁的机制int a = 内存当中有自己的值T1 -> a 修改成bT2 -> a 修改成cConcurrentHashMap使用了Cas无锁化机制保证了线程安全的机制
ConcurrentHashMap
//保证线程可见性transient volatile Node<K,V>[] table;if (tab == null || (n = tab.length) == 0)tab = initTable();private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;while ((tab = table) == null || tab.length == 0) {//线程1如果完成了初始化操作,线程2会进行一个让步,不会再进行初始化了if ((sc = sizeCtl) < 0)//让出现线程的执行权Thread.yield(); // lost initialization race; just spin//(U.compareAndSwapInt 无锁化线程保障//操作数// SIZECTL:内存当中的值// sc:预期值// -1:新值// 初始化值操作只有一次会操作成功else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {//此时:SIZECTL = -1if ((tab = table) == null || tab.length == 0) {int n = (sc > 0) ? sc : DEFAULT_CAPACITY;@SuppressWarnings("unchecked")//进行初始化Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = tab = nt;sc = n - (n >>> 2);}} finally {sizeCtl = sc;}break;}}return tab;}
hash 函数1.得到一个整形值 hash函数(key.hashCode()-> 高低16位运算)是一个随机值,保证了取模算法后取得的数组下标是一定在这个容器大小的范围之内的。如何保证数组下标不一样,让数组均匀的分布在容器中,就是这个hash函数的取值结构。
final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable();//线程安全else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}//判断当前头节点的hash值如果MOVED=-1的话,让当前线程暂停,去帮忙搬数组else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;//同步数组索引的头节点,和分段锁是不一样的synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek//替换key值if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;//按链表方式,放入一个最新的节点if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}//红黑树放节点else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;}//保证线程可见性、防止指令重排序//使用cas保证原子性,比如初始化操作的时候//数组索引的头节点上锁

若有收获,就点个赞吧
0 人点赞
