- 57%的用户更在乎网页在3秒内完成加载;
- 52%的在线用户认为网页在打开速度影响到他们对网站的忠诚;
- 每慢1秒造成页面PV降低11%,用户满意度也随之降低,降低16%;
- 近半数移动用户在10秒内仍未打开页面从而放弃。
性能优化入门级别
用户体验FPS
FPS是图像领域中的定义,是指画面每秒传输帧数,通俗来讲就是指动画或视频的画面数。FPS是测量用于保存、显示动态视频的信息数量。每秒钟帧数愈多,所显示的动作就会越流畅。通常,要避免动作不流畅的最低是30。某些计算机视频格式,每秒只能提供15帧。FPS也可以理解为我们常说的“[刷新率](https://baike.baidu.com/item/%E5%88%B7%E6%96%B0%E7%8E%87/605917)(单位为Hz)”。
方式
1. 压缩合并打包MD5
对静态文件(比如:HTML、CSS、JS等所有能进行压缩的文件)进行压缩合并打包;压缩是为了缩小HTTP请求文件的大小,合并是为了减少HTTP请求的数量;请求数量越少、越小,页面加载的速度就越快。 加MD5的原因是为了文件缓存。然而这样就会有一个冲突,合并必然会引起文件变大,那么这里需要一个规定:**合并后的文件大小不能超过28k~30k,合并后的请求文件不能多于5个**。一般的浏览器平均并发量是5,一旦超过了这些标准,网站的性能肯定会有或多或少的问题。
2. 开启多个CDN
开启CDN的好处是当我们获取静态资源文件的时候,CDN会让我们获取到就近的文件,这样就会减少文件传递的时间。我们在请求静态资源的时候总会携带cookie,随着请求cookie会越来越大,这样请求后台时总会携带这些cookie,造成请求体与响应体增大,而开启多个CDN服务器就是为了避免这个问题。一个域名下的平均并发请求为5个,多开CDN会让我们的并发请求数=CDN数*5,这样请求的速度会大大缩小。但是不是所有的东西都是越多越好,每请求一个CDN服务器,都要对CDN进行解析,开启的CDN越多就会增加CDN解析的时间,依然会对页面的加载速度造成影响。
3. 离线缓存
这个是直接解决网页加载速度的方式。我们可以在浏览器中通过开发者工具下找到`Application`下找到`Local Storage`,它是通过`key:value`的方式存放,我们可以把js文件的源代码放到里边,直接解析激活该js使用。需要注意的是`Local Storage`的大小为5M,当使用内存达到2.5M时,国产的有些手机就会出问题。当我们将文件进行离线缓存后,一旦js文件进行了修改,我们如何让浏览器知道它需要请求新的js文件呢?MD5,给文件打上MD5戳,每次只需对比文件的MD5值,一旦MD5不一样,就说明文件进行了修改。又碰到一个问题,如果获取最新文件的MD5呢?那么就要用到Webpack的插件,它每次都会给我们返回一个JSON文件,激活的文件先去请求最新的MD5,不一致了就会触发请求,获取到最新的文件。在`Application`中还有`Session Storage`、`IndexedDB`、`Web SQL`等存储的方式。那么说了这么多,我们不能说每个都去手动进行离线缓存的管理,下面介绍两种离线缓存存储方案,前端OMR存储方案localForage和workbox。
4. 其他方式
- 雅虎军规。
- 服务端开启Gzip。
- 根据获取用户的网速来给用户输送不同的文件,可以通过多普勒测速法。
强缓的优先级

1. cache-control
设置过期的时间长度,单位秒。在这个时间范围内,浏览器请求都会直接读缓存。当`expires`和`cache-control`都存在时,`cache-control`的优先级更高。
2. expires
expires:Thu,16 May 2019 03:05:59 GMT
在HTTP头中设置一个过期时间,在这个过期时间之前,浏览器的请求都不会发出,而是自动从缓存中读取文件,除非缓存被清空,或者强制刷新。缺陷在于,浏览器时间和用户端时间可能不一致,所以HTTP/1.1加入了`cache-control`头来改进这个问题。
3. etag
这也是一组请求相应头:
/** 响应头 */etag:"D5FC8B85A045FF720547BC36FC872550"/** 请求头 */if-none-match:"D5FC8B85A045FF720547BC36FC872550"
服务器端返回资源时如果头部带上了`etag`,那么下次请求时都会把值加入到请求头`if-none-match`中,服务器会对比这个值,确认资源是否发生改变,如果没有改变,则返回304。etag的精度最大,能精确到毫秒级。
4. last-modified
这是 组请求相应头
/** 响应头 */last-modified: Wed, 16 May 2018 02:57:16 GMT 01/** 请求头 */if-modified-since: Wed, 16 May 2018 05:55:38 GMT
原理类似,服务端返回资源时如果头部带上 `last-modified`,那么下次请求时都会把值加入到请求头 `if-modified-since` 中,服务器会对比这个值,确认资源是否发生改变,如果没有改变,则返回304。
下面这个图讲解了etag和 last-modified的流程
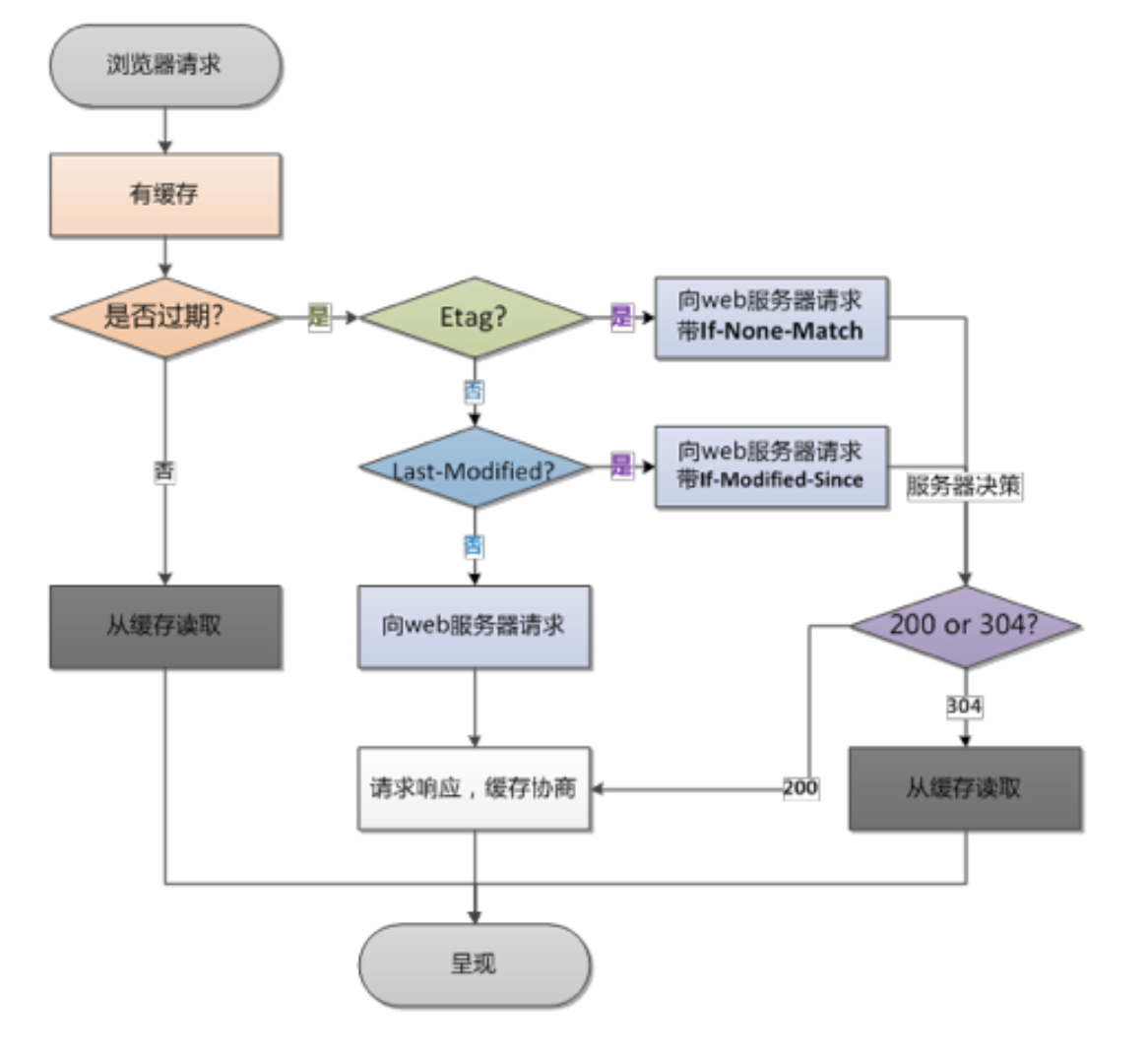
总结:上面有离线缓存,这里又讲了HTTP强缓,这两者在实际使用过程中如何抉择呢?业务用离线,库用HTTP强缓。项目中的业务处理js等文件使用离线缓存的方式,而我们用到的js库等使用HTTP强缓。因为我们会经常对业务js文件进行修改,而js库文件短时间内不会进行更新;HTTP强缓也有可能会丢失,而且在到期之前很难进行修改。
开启Keep-Alive和HTTP2
浏览器请求//xx.cn/a.js => 解析域名 =>HTTP 连接 => 服务器处理文件—>返回数据 => 浏览器解析、渲染文件。Keep-Alive解决的核心问题就在此,一定时间内,同一域名多次请求数据,只建立一次HTTP请求,其他请求可复用每一次建立的连接通道,以达到提高请求效率的问题。一定时间是可以配置的,HTTP1.1还是存在效率问题,第一个: 串行的文件传输。第二个:连接数过多。HTTP/2对同一域名下所有请求都是基于流,也就是说同一域名不管访问多少 件,也只建一路连接。同样Apache的最大连接数为300,因为有了这个新特性,最大的并发就可以提升到300, 原来提升了6倍!
渲染中的性能优化
网页整体的渲染流程
- 获取到的DOM是分层的;
- 对每个层的节点计算样式结果;
- 为每个节点生成图形和位置 ,所谓的回流,重排
Layout; - 将每个节点绘制填充到图层的位图中 叫做重绘
Paint; - 图层作为纹理上传至GPU (纹理是由CPU上传的);
- GPU把多个图层生成到显示器上,叫做合成层
Composite Layer。
总结:Layout => Paint => Composite Layers
小知识
- 重排一定引起重绘,重绘不一定引起重排;
- 有的元素是单独成层,不一定会让GPU参与;
- 会独立成层的属性:position 根元素 transform 半透明 滤镜 canvas video overflow bfc;
- 让GPU参与的是:css3D video WebGL transform css滤镜;
- 修改不同的CSS属性会触发不同阶段,参考网站CSS Triggers;
- DOM + CSS = Render Tree(渲染树)
造成重排的因素
- 添加或者删除可见的元素;
- 元素尺寸、内容改变;
- 元素的盒模型发生变化,比如边距、填充、边框;
- 渲染初始化;
- 读取元素宽高、位置等属性。
CPU和GPU的区别
相同之处:两种都有总线和外界联系,有自己的缓存体系以及数字和逻辑运算单元;两者都是为了运算而生。
不同之处:CPU主要负责操作系统和应用程序,GPU主要负责显示和数据处理。
总结:CPU的都可以干,但是效率没有GPU高。CPU是中央处理器,GPU是图形处理器;GPU能快速对texture进行偏移、缩放、旋转、修改透明度等操作。
原理:CPU的单元大而少,GPU的单元小而多。我们可以理解为单元越大处理数据的能力就越强,单元越多处理的事务就越多。
requestAnimationFrame(callback)
定义
定义绘制每一帧前的工作。每一帧的时间间隔为1/60=16.7ms。如果依靠浏览器内置时钟更新的频率,假如浏览器的更新频率正好是16.7ms的话,那么这样是非常完美的。然而理想是丰满的,现实是骨感的,像IE8以前的更新间隔为15.6ms,相同个数的时间间隔,总会导致**丢帧**现象的出现。如果使用`setTimeout`函数设置,我们都是`setTimeout`的时间是不准确的。那么就有了`requestAnimationFrame`的出现了。`requestAnimationFrame`会自动调节频率。`requestAnimationFrame`采用系统时间间隔,保持最佳绘制效率,不会因为间隔时间过短,造成过度绘制,增加开销;也不会因为间隔时间太长,使用动画卡顿不流畅,让各种网页动画效果能够有一个统一的刷新机制,从而节省系统资源,提高系统性能,改善视觉效果。**它能保证回调函数在屏幕每一次的刷新间隔中只被执行一次**,这样就不会引起丢帧现象,也不会导致动画出现卡顿的问题。
特点
【1】requestAnimationFrame会把每一帧中的所有DOM操作集中起来,在一次重绘或回流中就完成,并且重绘或回流的时间间隔紧紧跟随浏览器的刷新频率
【2】在隐藏或不可见的元素中,requestAnimationFrame将不会进行重绘或回流,这当然就意味着更少的CPU、GPU和内存使用量
【3】requestAnimationFrame是由浏览器专门为动画提供的API,在运行时浏览器会自动优化方法的调用,并且如果页面不是激活状态下的话,动画会自动暂停,有效节省了CPU开销
用法
通过下面的代码,来了解一下如果使用它:
/** 原始代码 */document.body.addEventListener('click',function(){var h1 = element1.clientHeight;element1.style.height = (h1 * 2) + 'px';})document.body.addEventListener('click',function(){var h2 = element2.clientHeight;element2.style.height = (h2 * 2) + 'px';})// 上面的代码 我们进行了两次的读写操作,这样就会触发两次Layout,那如何优化呢?请看如下代码:document.body.addEventListener('click',function(){// 读var h1 = element1.clientHeight;// 写requestAnimationFrame(fcnction(){element1.style.height = (h1 * 2) + 'px';})})document.body.addEventListener('click',function(){// 读var h2 = element2.clientHeight;// 写requestAnimationFrame(fcnction(){element2.style.height = (h2 * 2) + 'px';})})// 将写操作放到 requestAnimationFrame 下一帧统一执行,减少重排时间。
页面加载性能优化
页面加载流程
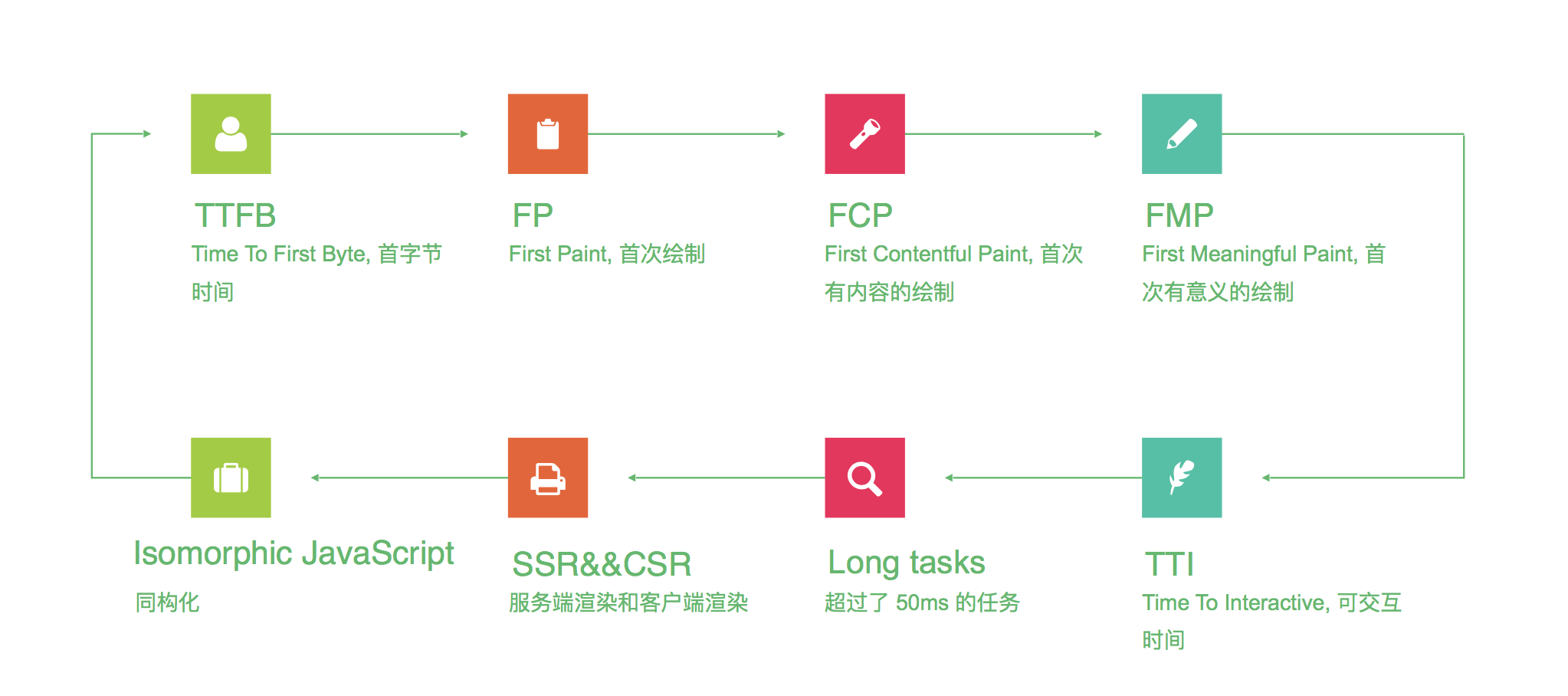
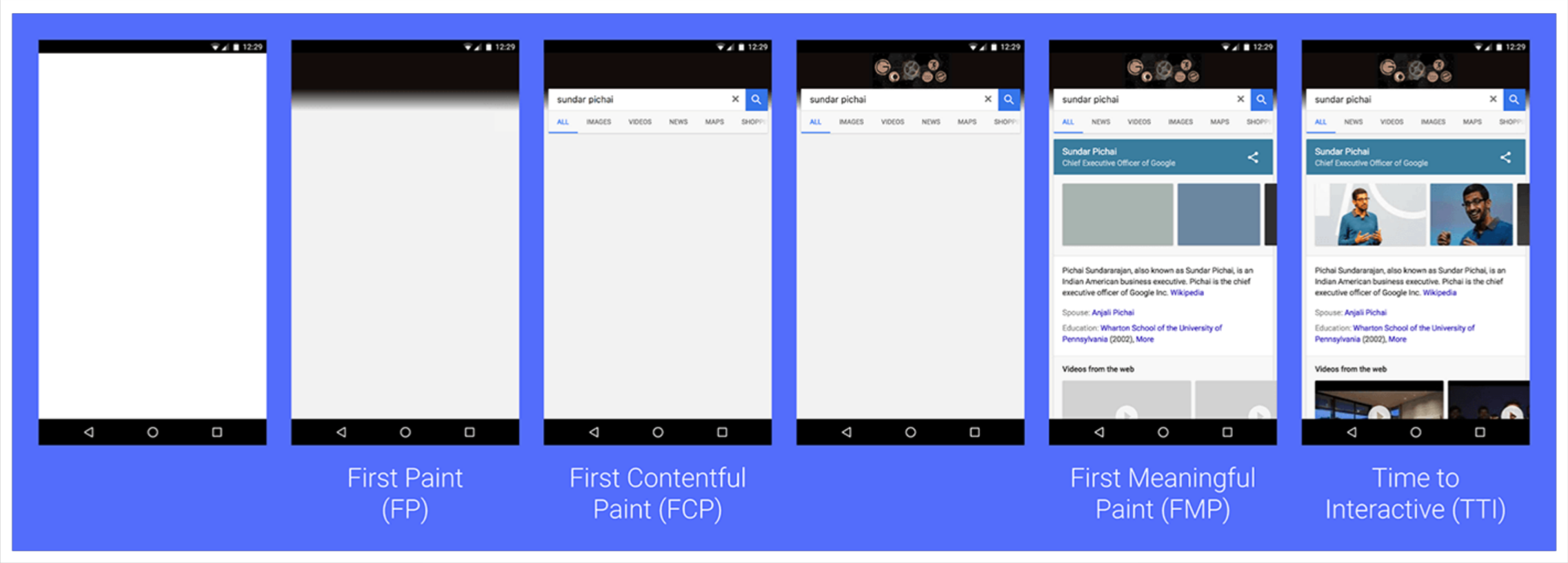

上面两个图说明了从用户输入网址到完全展现出来所进行的流程,即页面加载的流程。在进行页面加载流程优化的时候需要主要关注的节点为FP->FCP、FMP、Long tasks。
FP: 仅有一个 div 根节点。
FCP: 包含页面的基本框架,但没有数据内容。
FMP: 包含页面所有元素及数据。
下面通过代码的方式来获取这些节点所需的时间:
FP->FCP
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><meta http-equiv="X-UA-Compatible" content="ie=edge"><title>页面渲染性能优化</title><style>/** 触发FP */body {background: gray;}</style></head><body><div id="app"><!-- 空的div元素不会触发FCP只有有内容时才会触发 -->111</div><script>// 设置监听事件,监听paintconst observer = new PerformanceObserver((list) => {for (const entry of list.getEntries()) {console.log(entry);// 打印出执行的时间console.log(entry.name + "执行时间", entry.startTime + entry.duration);}});observer.observe({entryTypes: ["paint"]});</script></body></html>
总结:FP是第一个像素点生成,FCP是第一个内容生成。
FMP
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><meta http-equiv="X-UA-Compatible" content="ie=edge"><title>页面渲染性能优化</title><style>body {background: gray;}</style><link href="https://cdn.bootcss.com/animate.css/3.7.0/animate.min.css" rel="stylesheet"><script>performance.mark("css done");</script></head><body><div id="app">111<script>performance.mark("text done");</script></div><script>const perfEntries = performance.getEntriesByType("mark");for (const entry of perfEntries) {console.log(entry);console.log(entry.name + "执行时间", entry.startTime + entry.duration);}</script></body></html>
Long Tasks
/** Longtasks.js */// 当js文件执行超过50ms时,就会触发Long Tasksconst observer = new PerformanceObserver((list) => {for (const entry of list.getEntries()) {console.log(entry);console.log(entry.name + "执行时间", entry.startTime + entry.duration);}});observer.observe({entryTypes: ["longtask"]});
TTI
如果监控TTI,就需要知道js、css等文件全部加载完成,通过手动的检测很难实现,那么就需要通过插件来实现。通过NodeJS安装tti-polyfill.js
$ npm install tti-polyfill --save-dev
具体代码如下:
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><meta http-equiv="X-UA-Compatible" content="ie=edge"><title>页面渲染性能优化</title></head><body><script src="./node_modules/tti-polyfill/tti-polyfill.js"></script><script>// import ttiPolyfill from './path/to/tti-polyfill.js';ttiPolyfill.getFirstConsistentlyInteractive().then((tti) => {//统计的数据console.log(tti);//navigator.sendBeacon("a.gif?v="+11)});</script></body></html>
总结
虽然上面说了很多东西,但其实性能优化总的来说也就下面这几个模块:**雅虎军规**、**渲染加载**、**页面加载**、**Node加载**、**慎用加载**。用一句话来概括的话就是:**一个小字走天下,一个监控都不怕**。

若有收获,就点个赞吧
0 人点赞
