大数据技术组件简单介绍
该文档简单对一些大数据组件进行介绍,这些组件按照功能分为存储,流计算,消息队列还有管理几种类型。每种功能中至少选取一种技术框架做了简单介绍。
存储
hdfs
是什么
hdfs是一个分布式的文件系统,它是整个hadoop项目的一部分,主要分布式的文件存储。hbase的存储也是基于hdfs的。
特点
- 高度容错性
因为同一条数据,在整个hdfs文件系统中会存储多条,而且是分布在不同的机器上,所以当出现磁盘问题,服务器宕机等情况时,数据可以从其他的机器的备份中恢复 - 易扩展
整个的hdfs集群可以很容易的进行横向扩展,只需要增加存储服务器,这些存储服务器不需要太高的性能,使用低廉的硬件就能实现量存储。(现在交警的存储集群大于是100台左右,整个存储量级是5.5P) - 适合批处理
其主要作用是作为数据仓库,所以能够方便的进行数据批处理。mapReduce就是hadoop项目自带的一个批处理组件。两者可以方便的进行相互配合完成数据处理。 - 海量数据
hdfs的存储容量取决于datanode结点的数量与磁盘大小,因为其易扩展的特点,datanode结点数量也可以达到上百台,上千台甚至更多。所以可以很容易的达到TB,PB的存储量级。 - 高吞吐
一次写入多次读取,吞吐量高,同时处理大量数据。
应用场景
适合场景
- 储大文件
- 需要高的容错性,数据安全要求较高
- 需要强大的扩展能力
不适用场景
- 低延迟
- 大量小文件
- 修改较多场景
实际应用
hdfs在交警项目中的应用就是作为一个数据仓库,存储所有交警的图片数据。每天4000万的数据量,存储50天。交警整个集群,包括文本和图片的存储量是4P其中主要是图片数据。
Hbase
是什么
Hbase是hadoop项目的子项目。它是一个面向列的开源数据库,适合非结构化数据存储的分布式存储集群。其利用hdfs来作为其文件存储系统。
特点
- 海量存储
适合存储海量数据,交警项目中从13年到21年的过车文本数据都是存在hbase中。去年中旬统计的数据条数大约是350亿条。现在仍然以每天4000万的量增加。 - 列式存储
hbase中的物理结构存储是以【主键(rowkey)-列族-列-值-时间戳-类型标记】来存储的,根据每一列进行存储。 - 易扩展
hbase的处理能力依靠对hbase的rengionserver结点的扩展得到加强。
而且由于hbase其存储依赖于hdfs,所有 数据都会在hdfs上落盘,所以扩展hdfs的存储就相当于同时扩展了hbase的存储。 - 高并发
依托多个rengionserver可以实现十亿量级的秒级反馈。 - 结构稀疏
因为hbase的按列存储,所以每条数据除了主键外没有固定的列,某一列的存储根据该条数据决定可有可无,有就存没有就不存,不是完全结构化的数据格式。所以hbase存储的表结构可以是稀疏的结构。 - 多版本
hbase中每列数据都可以存在多个版本,依据时间戳作为版本信息。
应用场景
适用场景
- 存储非结构化数据
- 写操作密集型
每天写入数据量巨大,比如操作日志。 - 查询简单
hbase只支持基于主键的查询,单条或者范围查询,所以主键的涉及要贴合常用的查询逻辑。 - 高扩展,高可靠性
不适用的场景
- 复杂查询较多
不支持复杂的sql处理。如关系型数据库中的join,hbase不支持。 - 对事务要求较高
hbase仅仅行级事务。
实际应用
济南交警平台的文本存储使用的就是hbase。过车记录的存储比较符合上述适用场景。海量过车数据,每天存在大量的写入操作。
但是过车记录的查询条件较多,通常是分为两类。
一类是直到车牌查过车记录。
另外一类是直到时间查过车。
所以针对这两类不同侧重的查询以及其他需求,交警的处理方案是,每条数据使用不同的主键保存到两个不同表中。只是用一个主键,很难做到对两种查询都支持。
流计算
storm
是什么
storm是一个免费和开源分布式实时计算系统。主要用来对源源不断的数据流做实时性分析处理
特点
- 支撑各种实时类项目场景
- 高度可伸缩
如果要扩容,直接加机器,调整storm计算作业的并行度就可以了,storm会自动部署更多的进程和线程到其他的机器上去,无缝快速扩容。 - 可靠性高
storm的消息可靠机制开启后,可以保证一条数据都不丢。数据不丢失,也不重复计算。
storm元数据全部放zookeeper,不在内存中,依靠zookeeper进行恢复。 - 实时性高
处理速度驱动是storm的重要指标,能够对流数据进行快速处理。
应用场景
适用场景
- 流数据处理
Storm 可连续进行流数据处理。Storm能保证计算可以永久运行,直到用户结束计算进程为止。 - 分布式RPC
由于Storm的处理组件是分布式的,而且处理延迟极低,所以可以作为一个通用的分布式RPC框架来使用。
实际应用
交警项目中使用storm来完成报警功能。将过车数据流和布控报警信息进行拟合,将处理结果进行报警短信推送。
Spark和Flink
是什么
spark和flink都是现在比较流行的两个流计算(实时计算)引擎。spark的使用者比较多,flink刚刚兴起,被阿里收购了,正在大力推广,处于快速发展阶段。
特点
相同点
- 适用于流处理和批处理
spark和flink都支持流,批处理。 - 适用于大规模数据量
- 分布式
二者都是分布式的架构,同一个处理任务可以被分到多个节点上进行执行。
不同点
- 对于流,批数据的处理方式不同
简单来说就是,spark对于流数据和批数据的处理都看成是批处理。流数据相当于把数据流切分为无数个微小的批量数据,然后进行批处理,最终得到一个个微批的处理结果,即这批数据足够的小,时间足够短就可以看作是流处理。
flink对于所有处理都当作流处理,对于批处理当作时间较长,数据量较多的流来处理。 - 实时性差异
因为处理方式的差异,所以造成了二者的实时性差异,Flink是真正的流处理,延迟在毫秒级,Spark Streaming是微批,延迟在秒级。 - 处理时间有差异
Flink可以处理事件时间,而Spark Streaming只能处理机器时间,无法保证时间语义的正确性。- flink三种时间语义,因此有水位线的概念:事件时间event time【事件的发发生时间】、机器时间processing time【机器接收到这条数据的时间】、数据进入flink的时间 ingestion time【flink的处理时间】。
- Spark Streaming用的是微批次,只能用机器时间。
- 数据一致性的保障
Flink的检查点算法比Spark Streaming更加灵活,性能更高。能够较为容易的保证端到端一致性。
实际应用场景
现在交警中的报警系统的流处理可以使用上边两种技术进行替代。
在后边的交通学院项目中将会使用flink来做流处理和批处理。
几种实时计算框架的对比
| 产品 | 模型 | API | 保证次数 | 容错机制 | 状态管理 | 延时 | 吞吐量 |
|---|---|---|---|---|---|---|---|
| Storm | Native(数据进入立即处理) | 组合式(基础API) | At-least-once (至少一次) | Record ACK(ACK机制) | 无 | 低 | 低 |
| Spark Streaming | Micro-Batching | 声明式(提供封装后的高阶函数,如count函数) | Exactly-once | RDD CheckPoint(基于RDD做CheckPoint) | 基于DStream | 中等 | 高 |
| Flink | Native | 声明式 | Exactly-once | CheckPoint(Flink的一种快照) | 基于操作 | 低 | 高 |
技术选型
技术选型的参考,总体来说flink是趋势。
- 需要关注流数据是否需要进行状态管理,如果是,那么只能在 Spark Streaming 和 Flink 中选择一个。
- 需要考虑项目对 At-least-once(至少一次)或者 Exactly-once(仅一次)消息投递模式是否有特殊要求,如果必须要保证仅一次,也不能选择 Storm。
- 对于小型独立的项目,并且需要低延迟的场景,建议使用 Storm,这样比较简单。
- 已经使用了 Spark,并且秒级别的实时处理可以满足需求的话,建议使用 Spark Streaming。
- 要求消息投递语义为 Exactly-once;数据量较大,要求高吞吐低延迟;需要进行状态管理或窗口统计,这时建议使用 Flink。
消息队列
消息队列中间件(简称消息中间件)是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型,它可以在分布式环境下提供应用解耦、弹性伸缩、冗余存储、流量削峰、异步通信、数据同步等等功能,其作为分布式系统架构中的一个重要组件,有着举足轻重的地位。个人感觉比价场景应用核心的有三个:解耦、异步、削峰。
Kafka
是什么
kafka是一种高吞吐的分布式发布订阅消息系统。简单来说就是一个分布式消息队列。也有把kafka当作流数据处理引擎的。但是其常用的用途还是消息队列。
特点
- 高吞吐,高并发,低延迟
kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒。同时支持数千个客户端同时读写。 - 持久化存储
kafka支持将消息持久化到本地磁盘,并支持数据备份防止数据丢失。 - 易扩展
支持热扩展,无序停机就可以进行接入结点的扩展。济南交警从之前的18台,增加到现在的25台。 - 完全分布式
kafka可以自动实现负载均衡,对发送来的消息均衡分配到各个partition。
支持故障转移,当主节点宕机时,会自动启用备份节点代替主节点工作。
应用场景
适用场景
- 日志收集
- 消息队列
- 流式处理
实际应用
在交警系统中,kafka作为消息队列来存在,每天接收4000万左右的数据量。每天近40T的数据。AMQ用来处理交警前后之间的消息传递,如查询请求与查询结构在前后台的传递;还有,数据流处理末端的数据转发操作,其数据来源于二次识别后加入到AMQ队列中。
消息队列的对比
因为消息队列的主要作用都是相同的,各个消息队列不同的是侧重点和具体实现。所以不做过多介绍。放两张消息队列的对别图。
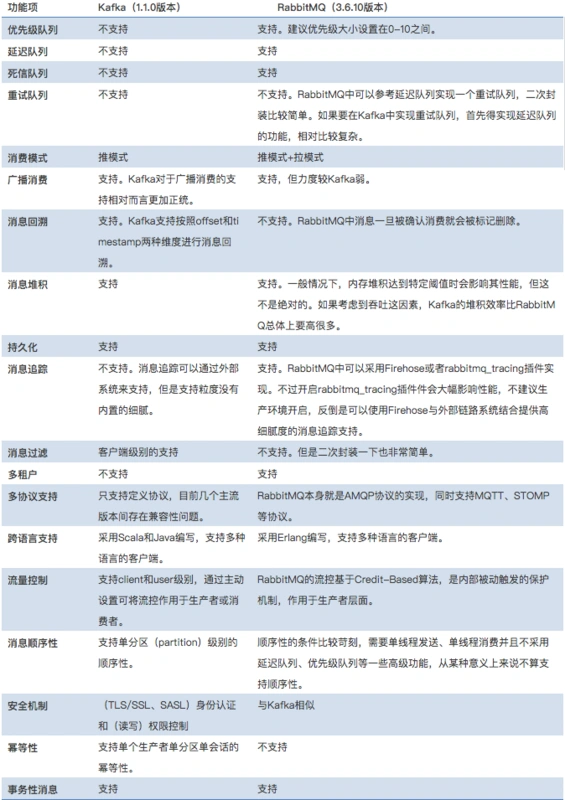
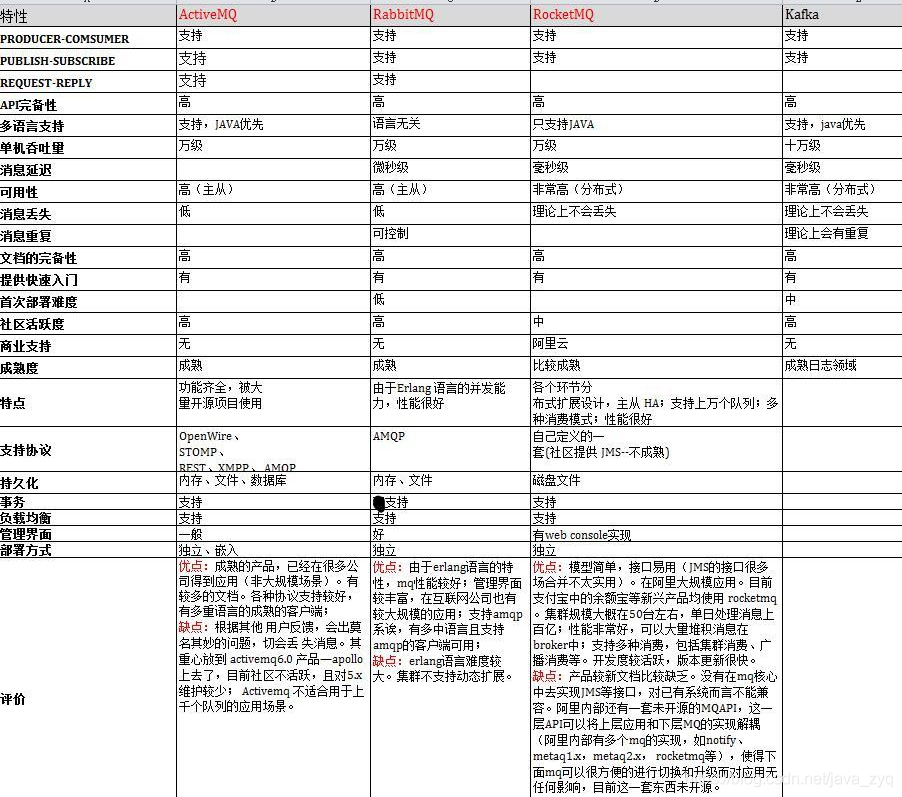
管理
zookeeper
是什么
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,也是hadoop项目的一部分,是hdfs和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
为什么叫做zookeeper?
是因为hadoop图标是 , hbase是
, hbase是 ,hive是
,hive是 ,各个以动物命名的分布式组件放在一起,整个分布式系统看上去就像一个大型的动物园,而Zookeeper正好要用来进行分布式环境的协调,作为其管理者,所以就是zoo + keeper的结合。
,各个以动物命名的分布式组件放在一起,整个分布式系统看上去就像一个大型的动物园,而Zookeeper正好要用来进行分布式环境的协调,作为其管理者,所以就是zoo + keeper的结合。
特点
- 分布式
多个zookeeper组成一个集群,当leader结点出现问题会从follower中进行选举产生新的leader作为主节点。 - 可靠性
更改请求被提交到zookeeper被应用后,结果会被持久化直到下次更改覆盖。 - 原子性
所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
应用场景
- 服务动态上下线
可以通过zookeeper管理注册服务的启停 - 发布/订阅
zookeeper可以作为消息的中转站,即结点在zookeeper进行注册之后,在zookeeper上发布一个消息(如配置文件),那么在zookeeper上注册的结点可以从zookeeper上获取到该配置文件,实现动态更新数据的目的。 - 负载均衡
支持同一zookeeper集群上相同服务不同结点之间的负载均衡。
实际应用
zookeeper在交警项目中担任比较重要的责任。主要有两种应用,一是作为集群的管理者,上边的这些组件绝大多数都需要用到zookeeper。二是用来动态管理服务的上线下线(图片服务中使用到)。

若有收获,就点个赞吧
0 人点赞
