什么是函数式编程?
Functional programming is a programming paradigm
treats computation as the evaluation of mathematical functions
avoids changing-state and mutable data
——- by wikipedia
总结下来有以下3点特点
- programming paradigm 编程范式
- Mathematical Functions:数学函数
- Changing-state And Mutable Data:不改变状态和数据
什么是编程范式?
编程范式从概念上来讲指的是编程的基本风格和典范模式。
换句话说其实就是程序员对于如何使用编程来解决问题的世界观和方法论。
包含 函数式编程、程序编程、面向对象编程、指令式编程 等不同的编程范式
通俗一点说是编程的思维模式
一门语言可以有多种编程范式,一种范式也可以在不同的语言中实现。如果把一门编程语言比作兵器,那他的语法,工具,技巧是招法,那么他采用的编程范式就是内心功法
javascript就是一种基于原型(prototype-based)多范式语言。面向对象+函数式什么是数学函数?
函数的定义
一般的,在一个变化过程中,假设有两个变量 x、y,如果对于任意一个 x 都有唯一确定的一个y和它对应,那么就称 x 是自变量,y 是 x 的函数。x 的取值范围叫做这个函数的定义域,相应 y 的取值范围叫做函数的值域。什么是纯函数?
没有副作用的纯函数都是引用透明的纯函数就是数学函数,对于相同的输入,永远得到的输出是唯一的,没有任何副作用
引用透明
```javascript引用透明性(Referential Transparency)指的是,如果一段代码在不改变整个程序行为的前提下,可以替换成它的执行结果。
const double = x => x * 2 const addFive = x => x + 5 const num = double(addFive(10))
num === double(10 + 5) === double(15) === 15 * 2 === 30
<a name="gp3jF"></a>### 什么是副作用(Side Effects)?```javascript副作用是在计算的过程中,系统状态的一种变化,或者与外部世界进行的可观察的交互。
副作用可能包含,但不限于以下行为:
- 更改文件系统
- 往数据库中插入记录
- 发送一个 http 请求
- 改变数据
- 打印 log
- 获取用户输入
- DOM 查询
- 访问系统状态
- …
当然这并不是说,要禁止使用一切副作用,而是说,要让它们在可控的范围内发生。函数式编程的哲学就是假定副作用是造成不正当行为的主要原因。
在后面讲到函子(functor)和单子(monad)的时候我们会学习如何控制它们。纯函数的好处
```javascript 面向对象语言的问题是,它们永远都要随身携带那些隐式的环境。你只需要一个香蕉,但却得到一个拿着香蕉的大猩猩…以及整个丛林
by Erlang 作者:Joe Armstrong
当你拿出一个香蕉,必须要附带其他的属性去描述这个香蕉,面向对象都是名词,函数式编程都是动词<br />使用纯函数的好处- **可缓存(cacheable)**- **可移植性/自文档化(Portable / Self-Documenting)**- **可测试性(Testable)**- **合理性(Resonable)**- **并行代码(Parallel Code)**<a name="lygD1"></a>## 为什么要避免状态改变?```javascriptShared mutable state is the root of all evil共享可变状态是万恶之源by Pete Hunt

const obj = {num:10}getsome(obj)console.log(obj) ??
作为函数式语言js还差什么?
函数式语言的特点
- 函数是“一等公民”(first class)
- 不可变的数据
- 使用递归而不是循环
- 柯里化
- 惰性求值
- 代数数据类型
- 模式匹配
- …
在函数式方面,由于 JavaScript 支持高阶函数、匿名函数、函数是一等公民、闭包、解构(模式匹配)等特性,所以它也能支持函数式编程范式。(尤其是 ES6 新增的箭头函数等特性~还有各种类库 )
不可变数据结构
JavaScript 一共有 6 种原始类型(包括 ES6 新添加的 Symbol 类型),它们分别是 Boolean,Null,Undefined,Number,String 和 Symbol。 除了这些原始类型,其他的类型都是 Object,而 Object等引用类型都是可变的。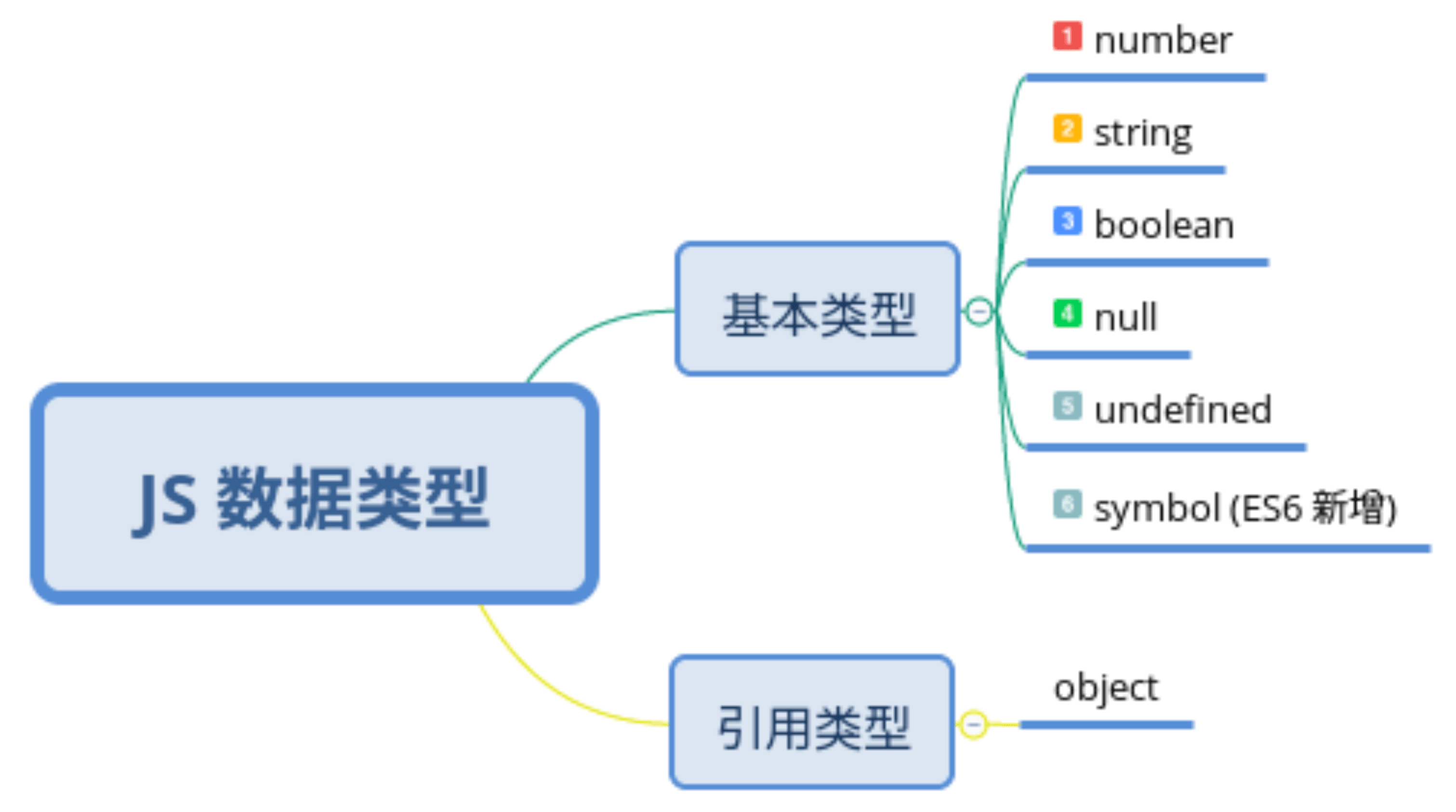
惰性求值
惰性(lazy)指求值的过程并不会立刻发生。
比如大部分语言中,参数中的表达式都会被先求值,这也称为应用序语言。
对于数组操作时,大部分语言也同样采用的是应用序。
[1, 2, 3, 4].map(x => x + 1)
所以,这个表达式立刻会返回结果 [2, 3, 4, 5] 。
当然这并不是说 JavaScript 语言使用应用序有问题,但是没有提供惰性序列的支持就是 JavaScript 的不对了。如果 map 一个大数组后我们发现其实只需要前 10 个元素时,去计算所有元素就显得多余了。
如何用 JavaScript 实现一个数组惰性求值库
es6中有generator 可以帮我们控制代码的执行流程,在其中判断迭代和流程是否完成,从而结束计算。
函数组合?
面向对象通常被比喻为名词,而函数式编程是动词。面向对象抽象的是对象,对于对象的的描述自然是名词。
面向对象把所有操作和数据都封装在对象内,通过接受消息做相应的操作。比如,对象 Kitty,它们可以接受“打招呼”的消息,然后做相应的动作。
而函数式的抽象方式刚好相反,是把动作抽象出来,比如“打招呼”就是一个函数,而函数参数就是作为数据传入的 Kitty(即 Kitty 进入函数“打招呼”,出来的应该是 Hello Kitty)。
面向对象可以通过继承和组合在对象之间分享一些行为或者说属性,函数式的思路就是通过组合已有的函数形成一个新的函数。
然而 JavaScript 语言虽然支持高阶函数,但是并没有一个原生的利于组合函数产生新函数的方式。而这些强大的函数组合方式却往往被类似 Underscore,Lodash 等工具库的光芒掩盖掉。
尾递归优化?

函数式编程语言中因为不可变数据结构的原因,没办法实现循环。所以都是通过递归来实现循环。
然而递归使用不当很容易栈溢出(Stack Overflow),所以一般采用尾递归的方式来优化。
虽然 ES6 规范中规定了尾递归优化规范,然而提供实现的解释器还非常的少
使用函数式
函数是一等公民
其实经常写 JavaScript 的人可能潜移默化地已经接受了这个观念,例如你可以像对待任何其他数据类型一样对待函数——把它们存在数组里,当作参数传递,赋值给变量.等等。
乱用的匿名函数
然而,常常可以看到滥用匿名函数的现象…
// 太傻了const getServerStuff = function (callback) {return ajaxCall(function (json) {return callback(json)})}// 这才像样const getServerStuff = ajaxCall// 下面来推导一下...const getServerStuff=== callback => ajaxCall(json => callback(json))=== callback => ajaxCall(callback)=== ajaxCall// from JS函数式编程指南
再看另一个
const BlogController = (function () {const index = function (posts) {return Views.index(posts)}const show = function (post) {return Views.show(post)}const create = function (attrs) {return Db.create(attrs)}const update = function (post, attrs) {return Db.update(post, attrs)}const destroy = function (post) {return Db.destroy(post)}return { index, show, create, update, destroy }})()// 以上代码 99% 都是多余的...const BlogController = {index: Views.index,show: Views.show,create: Db.create,update: Db.update,destroy: Db.destroy,}// ...或者直接全部删掉// 因为它的作用仅仅就是把视图(Views)和数据库(Db)打包在一起而已。// from JS函数式编程指南
为何钟爱一等公民?
以上demo中,多包一层的问题就是,里面一层需要修改,外面很多层都要跟着修改
// 原始函数httpGet('/post/2', function (json) {return renderPost(json)})// 假如需要多传递一个 err 参数httpGet('/post/2', function (json, err) {return renderPost(json, err)})// renderPost 将会在 httpGet 中调用,// 想要多少参数,想怎么改都行httpGet('/post/2', renderPost)
提高函数复用率
除了上面说的避免使用不必要的中间函数包裹以外,对于函数参数的起名也很重要,尽量编写通用参数的函数。
// 只针对当前的博客const validArticles = function (articles) {return articles.filter(function (article) {return article !== null && article !== undefined})}// 通用性好太多const compact = function(xs) {return xs.filter(function (x) {return x !== null && x !== undefined})}
以上例子说明了在命名的时候,我们特别容易把自己限定在特定的数据上(本例中是 articles)。这种现象很常见,也是重复造轮子的一大原因。
this
柯里化(curry)
柯里化的概念
把接受多个参数的函数变换成一系列接受单一参数(从最初函数的第一个参数开始)的函数的技术。(注意是单一参数)
// 下面这段代码是解决了不纯的函数的问题,但是里面出现了硬编码function checkAge (age) {let mini = 18return age >= mini}// 普通的纯函数function checkAge (min, age) {return age >= min}console.log(checkAge(18, 20)) //trueconsole.log(checkAge(18, 24)) //trueconsole.log(checkAge(20, 24)) //true// 柯里化// checkAge函数返回值为一个函数,在新函数中比较年龄与最小年龄。function checkAge (min) {return function (age) {return age >= min}}//ES6写法let checkAge = min => (age => age >= min)//使用checkAge返回18和20的函数console.log(checkAge(18)(20)) //trueconsole.log(checkAge(18)(24)) //true
柯里化 VS 偏函数应用(partial application)
In computer science, partial application (or partial function application) refers to the process of fixing a number of arguments to a function, producing another function of smaller arity.by wikipedia
偏函数应用简单来说就是:一个函数,接受一个多参数的函数且传入部分参数后,返回一个需要更少参数的新函数。
柯里化一般和偏函数应用相伴出现,但这两者是不同的概念:
import { curry, partial } from 'lodash'const add = (x, y, z) => x + y + zconst curriedAdd = curry(add) // <- 只接受一个函数const addThree = partial(add, 1, 2) // <- 不仅接受函数,还接受至少一个参数=== curriedAdd(1)(2) // <- 柯里化每次都返回一个单参函数
柯里化的实现
虽然从理论上说柯里化应该返回的是一系列的单参函数,但在实际的使用过程中为了像偏函数应用那样方便的调用,所以这里柯里化后的函数也能接受多个参数。
// 实现一个函数 curry 满足以下调用、const f = (a, b, c, d) => { ... }const curried = curry(f)curried(a, b, c, d)curried(a, b, c)(d)curried(a)(b, c, d)curried(a, b)(c, d)curried(a)(b, c)(d)curried(a)(b)(c, d)curried(a, b)(c)(d)
// ES5var curry = function curry (fn, arr) {arr = arr || []return function () {var args = [].slice.call(arguments)var arg = arr.concat(args)return arg.length >= fn.length? fn.apply(null, arg): curry(fn, arg)}}// ES6const curry = (fn, arr = []) => (...args) => (arg => arg.length >= fn.length? fn(...arg): curry(fn, arg))([...arr, ...args])
柯里化的意义
柯里化和偏函数应用的主要意义就是固定一些我们已知的参数,然后返回一个函数继续等待接收那些未知的参数。
所以常见的使用场景之一就是高级抽象后的代码复用。例如首先编写一个多参数的通用函数,将其柯里化后,就可以基于偏函数应用将其绑定不同的业务代码。
// 定义通用函数const converter = (toUnit,factor,offset = 0,input) => ([((offset + input) * factor).toFixed(2),toUnit,].join(' '))// 分别绑定不同参数const milesToKm =curry(converter)('km', 1.60936, undefined)const poundsToKg =curry(converter)('kg', 0.45460, undefined)const farenheitToCelsius =curry(converter)('degrees C', 0.5556, -32)
你可能会反驳说其实也可以不使用柯里化啊,偏函数应用,我就直接怼也能实现以上的逻辑。
function converter (ratio, symbol, input) {return (input * ratio).toFixed(2) + ' ' + symbol}converter(2.2, 'lbs', 4)converter(1.62, 'km', 34)converter(1.98, 'US pints', 2.4)converter(1.75, 'imperial pints', 2.4)
然而两者的区别在于,假如函数 converter 所需的参数无法同时得到,对柯里化的方式来说没有影响,因为已经用闭包保存住了已知参数。而后者可能就需要使用变量暂存或其他方法来保证同时得到所有参数。
函数组合(compose)
组合的概念
函数组合就是将两个或多个函数结合起来形成一个新函数。
数学中复合函数的概念
如果 y 是 w 的函数,w 又是 x 的函数,即 y = f(w), w = g(x),那么 y 关于 x 的函数 y = f[g(x)] 叫做函数 y = f(w) 和 w = g(x) 的复合函数。其中 w 是中间变量,x 是自变量,y 是函数值。
此外在离散数学里,应该还学过复合函数 f(g(h(x))) 可记为 (f ○ g ○ h)(x)。(其实这就是函数组合)
组合的实现
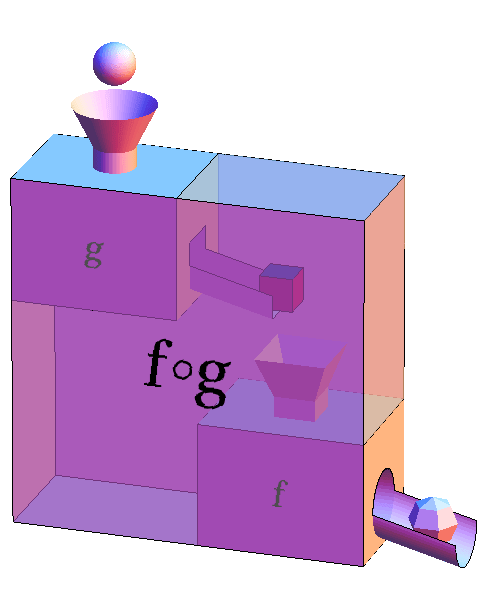
const add1 = x => x + 1const mul3 = x => x * 3const div2 = x => x / 2div2(mul3(add1(add1(0)))) // 结果是 3,但这样写可读性太差了const operate = compose(div2, mul3, add1, add1)operate(0) // => 相当于 div2(mul3(add1(add1(0))))operate(2) // => 相当于 div2(mul3(add1(add1(2))))// redux 版const compose = (...fns) => {if (fns.length === 0) return arg => argif (fns.length === 1) return fns[0]return fns.reduce((a, b) => (...args) => a(b(...args)))}// 一行版,支持多参数,但必须至少传一个函数const compose = (...fns) => fns.reduceRight((acc, fn) => (...args) => fn(acc(...args)))// 一行版,只支持单参数,但支持不传函数const compose = (...fns) => arg => fns.reduceRight((acc, fn) => fn(acc), arg)
Pointfree?
起名字是一个很麻烦的事儿,而 Pointfree 风格能够有效减少大量中间变量的命名。
Pointfree 即不使用所要处理的值,只合成运算过程。中文可以译作"无值"风格。
const addOne = x => x + 1const square = x => x * x
上面是两个简单函数 addOne 和 square,现在把它们合成一个运算。
const addOneThenSquare = compose(square, addOne)addOneThenSquare(2) // 9
上面代码中,addOneThenSquare 是一个合成函数。定义它的时候,根本不需要提到要处理的值,这就是 Pointfree。
此外有的库(如 Underscore、Lodash…)把需要处理的数据放到了第一个参数。
const square = n => n * n;_.map([4, 8], square) // 第一个参数是待处理数据R.map(square, [4, 8]) // 一般函数式库都将数据放在最后
这样会有一些很不函数式的问题,即:
1.无法柯里化后偏函数应用
2.无法进行函数组合
3.无法扩展 map(reduce 等方法) 到各种其他类型
(详情参阅参考文献之《Hey Underscore, You’re Doing It Wrong!》)
函数组合的意义
首先让我们从抽象的层次来思考一下:一个 app 由什么组成?
一个应用其实就是一个长时间运行的进程,并将一系列异步的事件转换为对应结果。
- 一个 start 可以是:
- 开启应用
- DOM 事件(DOMContentLoaded, onClick, onSubmit…)
- 接收到的 HTTP 请求
- 返回的 HTTP 响应
- 查询数据库的结果
- WebSocket 消息
- ..
- 一个 end 或者说是 effect 可以是:
- 渲染或更新 UI
- 触发一个 DOM 事件
- 创建一个 HTTP 请求
- 返回一个 HTTP 响应
- 保存数据到 DB
- 发送 WebSocket 消息
- …
那么在 start 和 end 之间的东东,我们可以看做数据流的变换(transformations)。这些变换具体的说就是一系列的变换动词的结合。
这些动词描述了这些变换做了些什么(而不是怎么做)如:
- filter
- slice
- map
- reduce
- concat
- zip
- fork
- flatten
- …
当然日常编写的程序中一般不会像之前的例子那样的简单,它的数据流可能是像下面这样的…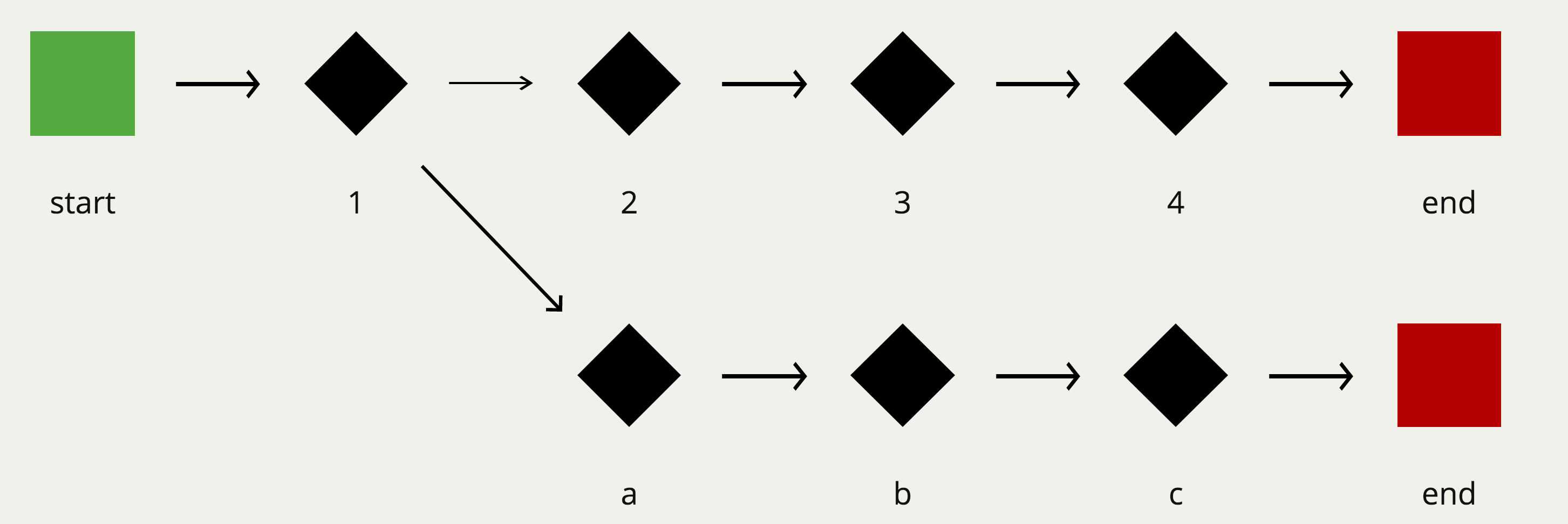

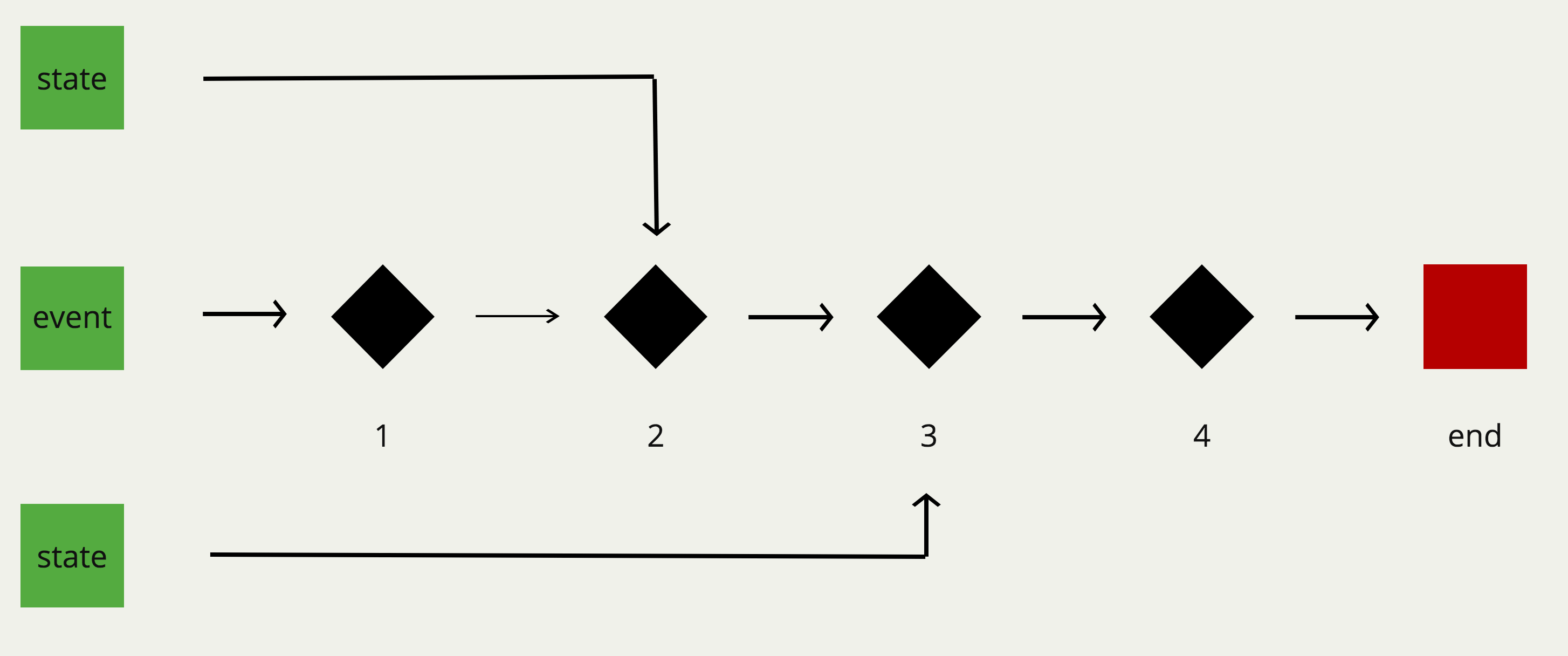
并且,如果这些变换在编写时,遵守了基本的函数式规则和最佳实践(纯函数,无副作用,引用透明…)。
那么这些变换可以被轻易地重用、改写、维护、测试,这也就意味着编写的应用可以很方便地进行扩展,而这些变换结合的基础正是函数组合。
参考文档:https://buptsteve.github.io/blog/
https://mp.weixin.qq.com/s/R_yW8ZQk05GG5LtvhnEk6g
JS函数式编程指南
Pointfree 编程风格指南
Hey Underscore, You’re Doing It Wrong!
Functional Concepts with JavaScript: Part I
Professor Frisby Introduces Composable Functional JavaScript
函数式编程入门教程

若有收获,就点个赞吧
0 人点赞
