grep命令 1
grep<br /> 1.作用<br /> Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。<br /> grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。<br /> 2.格式及主要参数<br /> grep [options]<br /> 主要参数: grep --help可查看<br /> -c:只输出匹配行的计数。<br /> -i:不区分大小写。<br /> -h:查询多文件时不显示文件名。<br /> -l:查询多文件时只输出包含匹配字符的文件名。<br /> -n:显示匹配行及 行号。<br /> -s:不显示不存在或无匹配文本的错误信息。<br /> -v:显示不包含匹配文本的所有行。<br /> --color=auto :可以将找到的关键词部分加上颜色的显示。<br /> pattern正则表达式主要参数:<br /> \: 忽略正则表达式中特殊字符的原有含义。<br /> ^:匹配正则表达式的开始行。<br /> $: 匹配正则表达式的结束行。<br /> \<:从匹配正则表达 式的行开始。<br /> \>:到匹配正则表达式的行结束。<br /> [ ]:单个字符,如[A]即A符合要求 。<br /> [ - ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。<br /> .:所有的单个字符。<br /> *:所有字符,长度可以为0。<br /> 3.grep命令使用简单实例<br /> itcast$ grep ‘test’ d*<br /> 显示所有以d开头的文件中包含 test的行
itcast $ grep ‘test’ aa bb cc<br /> 显示在aa,bb,cc文件中匹配test的行。
itcast $ grep ‘[a-z]\{5\}’ aa<br /> 显示所有包含每个字符串至少有5个连续小写字符的字符串的行。
itcast $ grep ‘wesest.*\1′ aa<br /> 如果west被匹配,则es就被存储到内存中,并标记为1,然后搜索任意个字符(.*),这些字符后面紧跟着 另外一个es(\1),找到就显示该行。如果用egrep或grep -E,就不用”\”号进行转义,直接写成’w(es)t.*\1′就可以了。<br /> 4.grep命令使用复杂实例<br /> 明确要求搜索子目录:<br /> grep -r<br /> 或忽略子目录<br /> grep -d skip<br /> 如果有很多输出时,您可以通过管道将其转到’less’上阅读:<br /> itcast$ grep magic /usr/src/Linux/Documentation/* | less<br /> 这样,您就可以更方便地阅读。<br /> 有一点要注意,您必需提供一个文件过滤方式(搜索全部文件的话用 *)。如果您忘了,’grep’会一直等着,直到该程序被中断。如果您遇到了这样的情况,按 ,然后再试。<br /> 下面还有一些有意思的命令行参数:<br /> grep -i pattern files :不区分大小写地搜索。默认情况区分大小写,<br /> grep -l pattern files :只列出匹配的文件名,<br /> grep -L pattern files :列出不匹配的文件名,<br /> grep -w pattern files :只匹配整个单词,而不是字符串的一部分(如匹配’magic’,而不是’magical’),<br /> grep -C number pattern files :匹配的上下文分别显示[number]行,<br /> grep pattern1 | pattern2 files :显示匹配 pattern1 或 pattern2 的行,<br /> 例如:grep "abc\|xyz" testfile 表示过滤包含abc或xyz的行<br /> grep pattern1 files | grep pattern2 :显示既匹配 pattern1 又匹配 pattern2 的行。<br /> grep -n pattern files 即可显示行号信息<br /> grep -c pattern files 即可查找总行数<br /> 还有些用于搜索的特殊符号:\< 和 \> 分别标注单词的开始与结尾。<br /> 例如:<br /> grep man * 会匹配 ‘Batman’、’manic’、’man’等,<br /> grep ‘\<man’ * 匹配’manic’和’man’,但不是’Batman’,<br /> grep ‘\<man\>’ 只匹配’man’,而不是’Batman’或’manic’等其他的字符串。<br /> ‘^’: 指匹配的字符串在行首,<br /> ‘$’: 指匹配的字符串在行 尾,<br /> <br /> 用grep查找结构体 grep -R "struct task_struct {" /usr/src 加-n可以显示行号<br />PS1=$ 进入到家目录在.bashrc 中
grep2
编号 参数 解释
1 —version or -V grep的版本
2 -A 数字N 找到所有的匹配行,并显示匹配行后N行
3 -B 数字N 找到所有的匹配行,并显示匹配行前面N行
4 -b 显示匹配到的字符在文件中的偏移地址
5 -c 显示有多少行被匹配到
6 —color 把匹配到的字符用颜色显示出来
7 -e 可以使用多个正则表达式
8 -f FILEA FILEB FILEA在FILEAB中的匹配
9 -i 不区分大小写针对单个字符
10 -m 数字N 最多匹配N个后停止
11 -n 打印行号
12 -o 只打印出匹配到的字符
13 -R 搜索子目录
14 -v 显示不包括查找字符的所有行
新建一个test.txt,里面内容如下:
root@Ubunut10:~/shell# cat test.txt
a
bc
def
ght12
abc999
tydvl658
123
456
789abc
1.—version
显示grep的版本号
[root@localhost shell]# grep —version
GNU grep 2.6.3
Copyright (C) 2009 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later [http://gnu.org/licenses/gpl.html](http://gnu.org/licenses/gpl.html>)
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
[root@localhost shell]#
-A 数字N
找到所有的匹配行,并显示匹配行后面N行
[root@localhost shell]# grep -A 2 “a” test.txt
a //匹配字符’a’ 后面两行
bc
def
—
abc999
tydvl658
123
—
789abc
[root@localhost shell]#
3.-B 数字N
找到所有的匹配行,并显示匹配行前面N行
[root@localhost shell]# grep -B 2 “a” test.txt
a
—
def
ght12
abc999 //匹配字符’a’ 前面两行
—
123
456
789abc
显示匹配到的字符在文件中的偏移地址
[root@localhost shell]# grep -b “a” test.txt
0:a //在文件中的偏移地址
15:abc999
39:789abc
[root@localhost shell]#
-c
显示有多少行被匹配到
[root@localhost shell]# grep -c “a” test.txt
3 //在整个txt中,共有三个字符’a’被匹配到
[root@localhost shell]#
6.—color把匹配到的字符用颜色显示出来

7.-e可以使用多个正则表达式
[root@localhost shell]# grep -e “a” -e “1” test.txt
a //查找txt中字符 ‘a’ 和 字符 ‘1’
ght12
abc999
123
789abc
[root@localhost shell]#
8.-f FILEA FILEB
FILEA在FILEAB中的匹配
[root@localhost shell]# cat test.txt
a
bc
def
ght12
abc999
tydvl658
123
456
789abc
[root@localhost shell]# cat test1.txt
abc
[root@localhost shell]# grep -f test.txt test1.txt
abc
[root@localhost shell]# grep -f test1.txt test.txt
abc999
789abc
[root@localhost shell]#
9.-i
不区分大小写
[root@localhost shell]# cat test1.txt
ab
Ac
6356
AKF57
[root@localhost shell]# grep -i “a” test1.txt
ab //找出所有字符’a’ 并且不区分大小写
Ac
AKF57
[root@localhost shell]#
10.-m 数字N
最多匹配N个后停止
[root@localhost shell]# grep -m 2 “a” test.txt
a
abc999 //匹配2个后停止
[root@localhost shell]#
11.-n
打印行号
[root@localhost shell]# grep -n -m 2 “a” test.txt
1:a //打印出匹配字符的行号
5:abc999
[root@localhost shell]#
12.-o
会打印匹配到的字符
[root@localhost shell]# grep -n -o “a” test.txt
1:a
5:a
9:a
[root@localhost shell]#
13.-R
搜索子目录
[root@localhost shell]# mkdir 666 //创建一个子目录
[root@localhost shell]# cp test.txt 666/ //将txt复制到子目录里面
[root@localhost shell]# ls
666 test1.txt test.txt //当前目录有两个txt和一个子目录
[root@localhost shell]# grep “a” *
test1.txt:ab //只在当前目录查找字符’a’
test.txt:a
test.txt:abc999
test.txt:789abc
[root@localhost shell]# grep -R “a” *
666/test.txt:a //在当前目录和子目录查找字符’a’
666/test.txt:abc999
666/test.txt:789abc
test1.txt:ab
test.txt:a
test.txt:abc999
test.txt:789abc
[root@localhost shell]#
14.-v
显示不包括查找字符的所有行
[root@localhost shell]# grep -v “a” test.txt
bc
def
ght12
tydvl658
123
456
[root@localhost shell]#
四、pattern主要参数
编号 参数 解释
1 ^ 匹配行首
2 $ 匹配行尾
3 [ ] or [ n - n ] 匹配[ ]内字符
4 . 匹配任意的单字符
5 * 紧跟一个单字符,表示匹配0个或者多个此字符
6 \ 用来屏蔽元字符的特殊含义
7 \? 匹配前面的字符0次或者1次
8 + 匹配前面的字符1次或者多次
9 X{m} 匹配字符X m次
10 X{m,} 匹配字符X 最少m次
11 X{m,n} 匹配字符X m—-n 次
12 666666 标记匹配字符,如666 被标记为1,随后想使用666,直接以 1 代替即可
13 | 表示或的关系
新建一个text.txt
[root@localhost shell]# cat test.txt
a
bcd
1
233
abc123
defrt456
123abc
12568teids
abcfrt568
[root@localhost shell]#
1.^
匹配行首
[root@localhost shell]# grep -n ‘^a’ test.txt
1:a //匹配以字符’a’开头的
5:abc123
9:abcfrt568
[root@localhost shell]#
[root@localhost shell]# grep -n ‘^abc’ test.txt
5:abc123 //匹配以字符串”abc”开头的
9:abcfrt568
[root@localhost shell]#
2.$
匹配行尾
[root@localhost shell]# grep -n ‘33$’ test.txt
4:233 //匹配以字符串”33”结束的
[root@localhost shell]# grep -n ‘3$’ test.txt
4:233 //匹配以字符’3’结束的
5:abc123
[root@localhost shell]#
3.[ ]
匹配 [ ]内的字符,
可以使用单字符
如 [ 1] 即匹配含有字符’1’的字符串(示例1),
如 [ a] 即匹配含有字符’a’的字符串(示例2),
如 [ 1 2 3 ] 即匹配含有字符’1’ 或者 ’2’ 或者’3’ 的字符串(示例3),
也可以使用字符序列,用字符 ‘-’ 代表字符序列
如 [ 1-3 ] 即匹配含有字符’1’ 或者 ’2’ 或者’3’ 的字符串(示例4)
如 [ 1-3 a-b] 即匹配含有字符’1’ 或者 ’2’ 或者’3’ 或者 ’a’ 或者 ’b’的字符串(示例5)
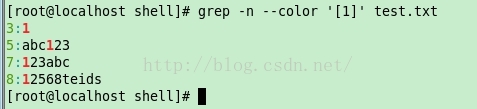
示例1:
[root@localhost shell]# grep -n —color ‘[1]’ test.txt
3:1
5:abc123
7:123abc
8:12568teids
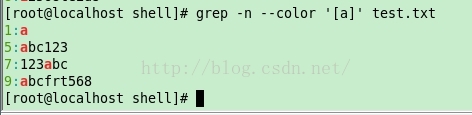
示例2:
[root@localhost shell]# grep -n —color ‘[a]’ test.txt
1:a
5:abc123
7:123abc
9:abcfrt568
示例3:
[root@localhost shell]# grep -n —color ‘[1 2 3]’ test.txt
3:1
4:233
5:abc123
7:123abc
8:12568teids

示例4:
[root@localhost shell]# grep -n —color ‘[1-3]’ test.txt
3:1
4:233
5:abc123
7:123abc
8:12568teids
[root@localhost shell]#
示例5:
[root@localhost shell]# grep -n —color ‘[1-3 a-b]’ test.txt
1:a
2:bcd
3:1
4:233
5:abc123
7:123abc
8:12568teids
9:abcfrt568
[root@localhost shell]#

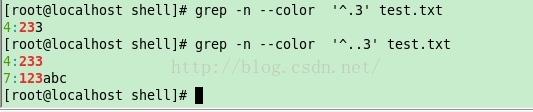
4. .
匹配任意的单字符
[root@localhost shell]# grep -n —color ‘^.3’ test.txt
4:233 //任意字符开头然后第二个字符为 ‘3’
[root@localhost shell]# grep -n —color ‘^..3’ test.txt
4:233 //任意两个字符开头,然后第三个字符为 ‘3’
7:123abc
[root@localhost shell]#
5. *
紧跟一个单字符,表示匹配0个或者多个此字符
下面例子的意思是,匹配字符’3’ 0次或者多次
[root@localhost shell]# grep -n —color ‘3*’ test.txt
1:a
2:bcd
3:1
4:233
5:abc123
6:defrt456
7:123abc
8:12568teids
9:abcfrt568
10:3

下面例子的意思是:匹配字符串”23”,但是 ‘3’ 被匹配的次数 >= 0
[root@localhost shell]# grep -n —color ‘23*’ test.txt
4:233
5:abc123
7:123abc
8:12568teids
[root@localhost shell]#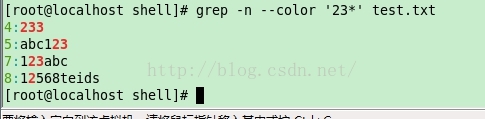
6. \
用来屏蔽元字符的特殊含义
下面的例子的意思是 在字符串 “365.398” 中,查找’.’这个字符,而不是任意单字符
[root@localhost shell]# echo “365.398” | grep —color ‘.’
365.398
[root@localhost shell]# echo “365.398” | grep —color ‘.‘
365.398
[root@localhost shell]#

7. \?
匹配前面的字符0 次或者 1次
[root@localhost shell]# grep -n —color ‘3\?’ test.txt
1:a
2:bcd
3:1
4:233
5:abc123
6:defrt456
7:123abc
8:12568teids
9:abcfrt568
下面例子的意思是:匹配字符串”33”但是 第二个字符‘3’只能匹配0次或者1次,因此实际匹配到的字符有“33 ”和 ‘3’这两种
[root@localhost shell]# grep -n —color ‘33\?’ test.txt
4:233
5:abc123
7:123abc
下面例子的意思是:匹配字符串”23”但是 第二个字符‘3’只能匹配0次或者1次,因此实际匹配到的字符有“23 ”和 ‘2’这两种
[root@localhost shell]# grep -n —color ‘23\?’ test.txt
4:233
5:abc123
7:123abc
8:12568teids

8. +
匹配前面的字符1次或者多次
[root@localhost shell]# grep -n —color ‘3+‘ test.txt
4:233
5:abc123
7:123abc
9.X{m}
匹配字符X m次
[root@localhost shell]# grep -n —color ‘3{1}‘ test.txt
4:233
5:abc123
7:123abc
10.X{m,}
匹配字符X 最少m次
[root@localhost shell]# grep -n —color ‘3{1,}‘ test.txt
4:233
5:abc123
7:123abc
[root@localhost shell]#
11.X{m,n}
匹配字符X m—-n 次
[root@localhost shell]# grep -n —color ‘3{0,1}‘ test.txt
1:a
2:bcd
3:1
4:233
5:abc123
6:defrt456
7:123abc
8:12568teids
9:abcfrt568
[root@localhost shell]#
13. |
表示或的关系
[root@localhost shell]# grep -n —color ‘ab∥23ab‖23’ test.txt
4:233
5:abc123
7:123abc
9:abcfrt568
五、示例
仅使用grep获取到ip,不使用其他 如 cut sed awk 命令
[root@localhost shell]# ifconfig eth0 | grep -o ‘inetaddr:inetaddr:[0−9]{1,}.\?[0−9]{1,}.\?{1,}‘ | grep —color -o ‘[0−9]{1,}.\?[0−9]{1,}.\?{1,}‘

若有收获,就点个赞吧
0 人点赞
