报错信息
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [8, 1024, 8, 8]], which is output 0 of ReluBackward1, is at version 9; expected version 8 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
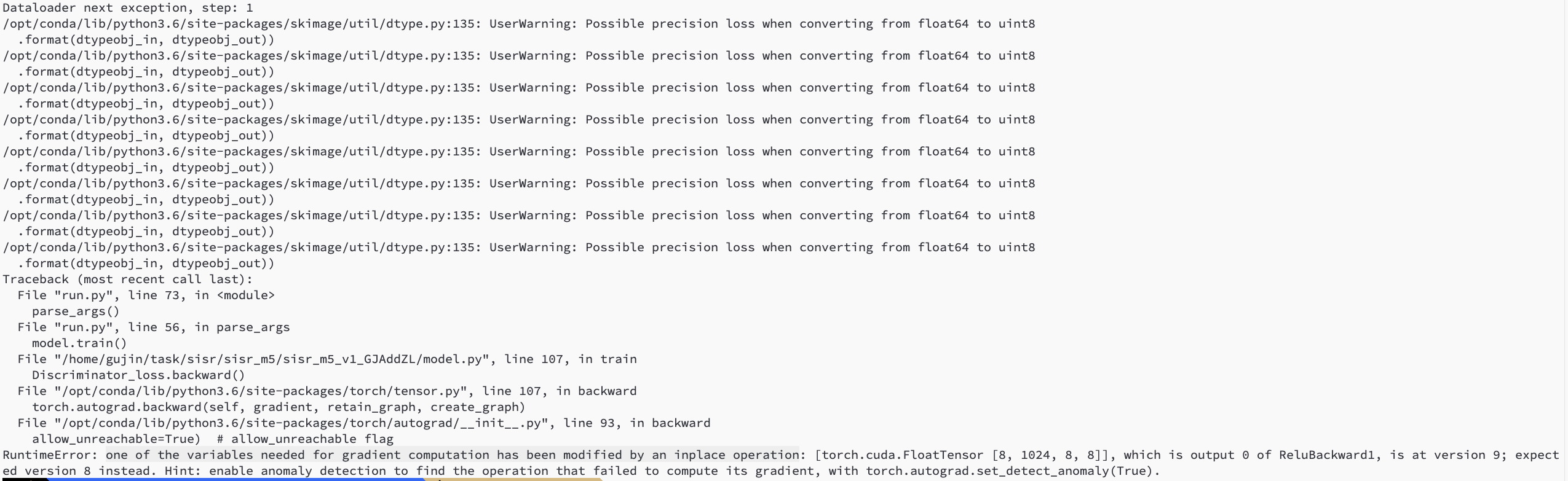
简单说,就是训练代码中出现了很多inplace操作,导致模型没法进行回传了。
解决方案
所以,解决的方法就是删除代码中的inplace操作。
常见的有:
一、激活函数
如relu, leaky_relu等都有inplace参数
将所有inplace参数的值都设为False(默认即False)
二、避免 a += b 这种写法
+=, -=, *=, /=都是inplace操作。 a += b 需要写成 a = a + b
进阶
我将代表中我认为能改的地方都改了,但还是有这个报错。后来查到一个新的知识点,如何去查报错的具体代码:https://github.com/pytorch/pytorch/issues/15803
操作非常简单,示例代码如下:
import torchwith torch.autograd.set_detect_anomaly(True):a = torch.rand(1, requires_grad=True)c = torch.rand(1, requires_grad=True)b = a ** 2 * c ** 2b += 1b *= c + ad = b.exp_()d *= 5b.backward()
只需要在跑模型前加一行 with torch.autograd.set_detect_anomaly(True) ,你再看报错提示就会变成下图:
轻轻松松定位到那个怎么也找不到的BUG了。

若有收获,就点个赞吧
0 人点赞
