在理想状态下,网络爬虫并不是必需品,每个网站都应该提供API,以结构化的格式共享它们的数据。然而在现实情况中,虽然一些网站已经提供了这种API,但是它们通常会限制可以抓取的数据,以及访问这些数据的频率。另外,网站开发人员可能会变更、移除或限制其后端API。总之,我们不能仅仅依赖于API 去访问我们所需的在线数据,而是应该学习一些网络爬虫技术的相关知识。
《用Python写网络爬虫第2版》中文PDF,212页,带书签目录,文字可以复制;英文PDF,215页,带书签目录,文字可以复制;配套源代码。
下载: https://pan.baidu.com/s/1b5xYKuxRyjLF9y43mJJg6g
提取码: z9zu
《用Python写网络爬虫第2版》包括网络爬虫的定义以及如何爬取网站,如何使用几种库从网页中抽取数据,如何通过缓存结果避免重复下载的问题,如何通过并行下载来加速数据抓取,如何利用不同的方式从动态网站中抽取数据,如何使用叔叔及导航等表达进行搜索和登录,如何访问被验证码图像保护的数据,如何使用 Scrapy 爬虫框架进行快速的并行抓取,以及使用 Portia 的 Web 界面构建网路爬虫。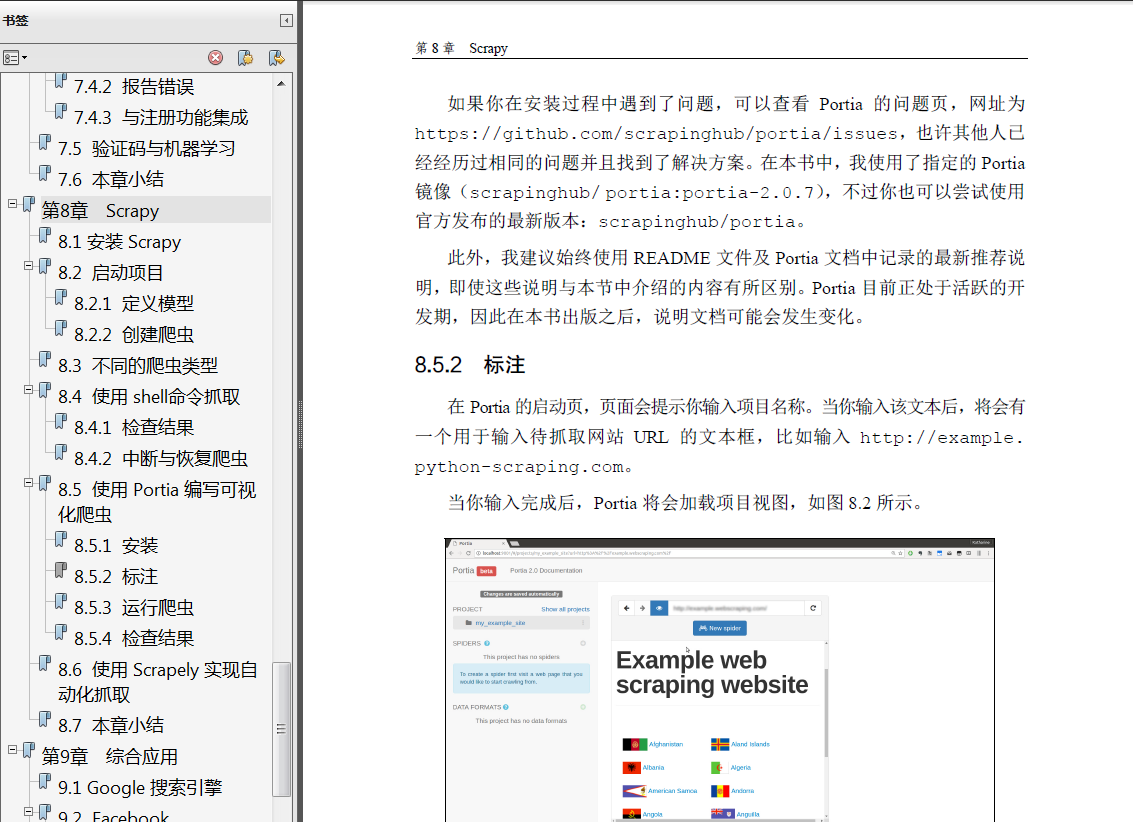
经过大半年的辗转,认为对于像爬虫这种实操工程类的编程学习的是术,用到就去学,用多了自然熟,不追求强记,但要知道有这么一种东西可以用。而对于一些算法类的编程学习是道,就要去理解,去熟悉,去反复磨炼。 作为python编程入门者“见识”整体项目逻辑构造,代码健壮性逐步优化的过程都是新手值得学习的地方,而且阅读基本上除了一些巧妙的编写逻辑需要停顿思考外,其他地方读起来很畅快,推荐阅读。
据爬取《实战Python网络爬虫》PDF+代码运行
《实战Python网络爬虫》PDF,483页;配套源代码。
下载: https://pan.baidu.com/s/1BbFejbRvbnbdu8YQum4Mqg
提取码: 3ww5
从原理到实践,循序渐进地讲述了使用Python 开发网络爬虫的核心技术。从逻辑上可分为基础篇、实战篇和爬虫框架篇三部分。基础篇主要介绍了编写网络爬虫所需的基础知识,包括网站分析、数据抓取、数据清洗和数据入库。网站分析讲述如何使用Chrome 和Fiddler 抓包工具对网站做全面分析;数据抓取介绍了Python爬虫模块Urllib 和Requests 的基础知识;数据清洗主要介绍字符串操作、正则和BeautifulSoup的使用;数据库讲述了MySQL 和MongoDB 的操作,通过ORM 框架SQLAlchemy 实现数据持久化,进行企业级开发。实战篇深入讲解, 了分布式爬虫、爬虫软件的开发、12306 抢票程序和微博爬取等。框架篇主要讲述流行的爬虫框架Scrapy ,并以Scrapy 与Selenium、Splash、Redi s 结合的项目案例,深层次了解Scrapy 的使用,还介绍了爬虫的上线部署、如何自己动手开发一款爬虫框架、反爬虫技术的解决方案等内容。
崔庆才《Python 3网络爬虫开发实战》中文PDF+源代码
《Python 3网络爬虫开发实战》中文PDF,606页,带目录和书签,文字可以复制。配套源代码;
下载: https://pan.baidu.com/s/1pLo9lpMLODHEJH8zOTNzPw
提取码: nvxe
总体上满足了预期期望值,对爬虫各方法的内容都有涉及,而且内附理论解释详尽,代码即可实现。推荐所有对爬虫有兴趣或从业人员细细研读。学习了三章:第2章介绍了学习爬虫之前需要了解的基础知识,如HTTP、爬虫、代理的基本原理、网页基本结构等内容,对爬虫没有任何了解的建议好好了解这一章的知识。第3章介绍了最基本的爬虫操作,一般学习爬虫都是从这一步学起的。这一章介绍了最基本的两个请求库(urllib和requests)和正则表达式的基本用法。学会了这一章,就可以掌握最基本的爬虫技术了。第4章介绍了页解析库的基本用法,包括Beautiful Soup、XPath、pyquery的基本使用方法,它们可以使得信息的提取更加方便、快捷,是爬虫必备利器。
瑞安《Python网络爬虫权威指南第2版》中文PDF+英文PDF+源代码
《Python网络爬虫权威指南第2版》中文PDF,266页,带目录,文字可复制;英文PDF,306页,带书签,文字可复制;配套源代码。
下载: https://pan.baidu.com/s/1LPFT-Uho-1LbwjbjcyBe9g
提取码: 7bmx
对那些没有学过编程的人来说,计算机编程看着就像变魔术。如果编程是魔术(magic),那么网页抓取(Web scraping)就是巫术(wizardry),也就是运用“魔术”来实现精彩实用却又不费吹灰之力的“壮举”。
《Python 3.7编程快速入门》PDF+源代码
《Python 3.7编程快速入门》PDF,297页,带书签,文字可复制;配套源代码。
下载: https://pan.baidu.com/s/1S67IzUvew9YevBI3L_EJow
提取码: jer4
Python因其具有丰富和强大的库,以及简单容易上手的特性,目前活跃在众多技术领域,包括人工智能、大数据分析处理、机器学习与深度学习、金融量化交易、网络开发、服务器编程、Web编程、运维自动化、物联网等领域。《Python 3.7编程快速入门》针对零基础,所有的知识点都通过大小示例让反复练习,激发学习的兴趣,快速掌握Python编程技巧、获得生产力。 
《Python学习手册第5版》中文PDF+英文PDF+源代码
《Python学习手册第5版》中文PDF,上册,796页,带书签,文字可复制;《Python学习手册第5版》中文PDF,下册,722页,带书签,文字可复制;《Python学习手册第5版》英文PDF,1594页,带书签,文字可复制;配套源代码。
下载: https://pan.baidu.com/s/1XwchI5zTUK9F-QOalSZzyw
提取码: 1dwf
下载: https://pan.baidu.com/s/1RGu99P3IGtoITiiziYPtBA
提取码: 982d
Python 绝对是一门易学难精的语言,打着简单语法的旗号把我忽悠过来,最后发现它背后隐藏了许多复杂的实现。 如果不是作为 “玩具” 语言来学习,一定要看看全方位细致讲解的书《Python学习手册第5版》。它涵盖了 Python 的每一个角落,让我明白了版本差异、作用域、函数式编程工具、相对导入、mro 解析顺序、装饰器、元类等等内容。 缺点是章节之间存在繁复交错的线索,让初读者头大,还有 1400 多页上下两册沉甸甸的分量让心情和手腕一样沉重,但是只要读完,你就会有如释重负之感,不禁为之拍案叫绝。 另外遗憾的是翻译诘屈聱牙,举个例子,译者把目录中的 revisited 翻译成 “重访”,个人认为还是翻译成 “重温” 或者 “回顾” 比较好。希望译者还是要多花点功夫,力求 “信达雅”,而不只是图快啊! 
《Python 快速入门第3版》PDF习题及代码
《Python 快速入门第3版》高清中文PDF,500页,带书签,文字可复制;英文PDF,473页,带目录,文字可复制;配套源代码和习题答案。
下载: https://pan.baidu.com/s/1NiQR26Ju9ikyvxPsDVMFPw
提取码: 97es
我们在学习python时,希望能够快速入门,然后把它作为工具,应用到数据分析和机器学习等领域,它已强大到足以应对从底层系统资源到应用程序(如深度学习)的方方面面。它既简洁、优雅又功能完备,还拥有庞大的由库和框架构成的生态系统。Python程序员的需求量很大,不熟练掌握Python显然不行!
Python专业人士Naomi Ceder编写的Python语言的综合指南。配有大量贴切的示例和边做边学的习题,有助于掌握每一个重要概念。
Python快速入门基于Python 3.6编写。分为4部分,第一部分讲解Python的基础知识,对Python进行概要的介绍;第二部分介绍Python编程的重点,涉及列表、元组、集合、字符串、字典、流程控制、函数、模块和作用域、文件系统、异常等内容;第三部分阐释Python的特性,涉及类和面向对象、正则表达式、数据类型即对象、包、Python库等内容;第四部分关注数据处理,涉及数据文件的处理、网络数据、数据的保存和数据探索,最后给出了相关的案例。
框架结构清晰,内容编排合理,讲解循序渐进,并结合大量示例和习题,可以快速学习和掌握Python,既适合Python初学者学习,也适合作为专业程序员的简明Python参考。

若有收获,就点个赞吧
0 人点赞
