- 大纲
- RPC 介绍
- RPC 的发展历程
- 1969年11月,ARPAnet 开始建立。
- 1974年:Jon Postel 和 Jim White发表了RFC674
- 1975年:RFC684 作为RFC 674 的注释发表,对RFC 674 的争议进行回复
- 1976年:RFC 707 发布
- 1983年1月1日,ARPA网将其网络核心协议由网络控制程序改变为 TCP/IP 协议
- 1984年:论文 《Implementing remote procedure calls》发表
- 1987年:《A Critique of the Remote Procedure Call Paradigm》发表
- 1988年,RFC 1057 发布,ONC RPC 被定义为标准的RPC 规范
- 1989年:Tim Berners-Lee 创建了万维网
- 1991年:OMG 发布CORBA 1.0
- 1994年:A Note on Distributed Computing 发布
- 1996年:HTTP/1.x 版本发布
- 1997年:OMG发布CORBA2.0
- 2002年:ZeroC Ice 发布
- 1999年: SOAP 发布
- 2000年:Roy Thomas Fielding 发表 RESTful 架构的博士论文
- 2008年:Google 开源 Protocol Buffer
- 2008年:FaceBook 开源 thrift
- 2010年5月: Avro脱离Hadoop项目,成为Apache顶级项目。
- 2015年:HTTP/2.0 发布
- 2015年:Google 开源gRPC
- 总结
“Does developer convenience really trump correctness, scalability, performance, separation of concerns, extensibility, and accidental complexity?” Vinoski (2008) 开发者的便利性真的比正确性、可扩展性、性能、关注点分离、可扩展性和偶然复杂度更重要吗?
大纲
远程过程调用(Remote Procedure Call,RPC)是一种允许两个实体通过通用请求/响应机制的通信通道进行通信的设计范例。RPC 的定义在过去三十年中发生了重大的变化和演变,因此 这里RPC 范式是一个广义的分类术语,指的是过去四十年中出现的所有 RPC 式系统。RPC 的定义经过几十年的发展。它已经从一个简单的客户端-服务器设计转移到一组相互连接的服务。虽然最初的 RPC 实现被设计为将计算外包给分布式系统中的服务器的工具,但 RPC 经过多年的发展,已经构建了一个与语言无关的应用程序生态系统。RPC 范式已经成为创建真正革命性的分布式系统的驱动力的一部分,并且在不同系统之间产生了各种通信方案和协议。
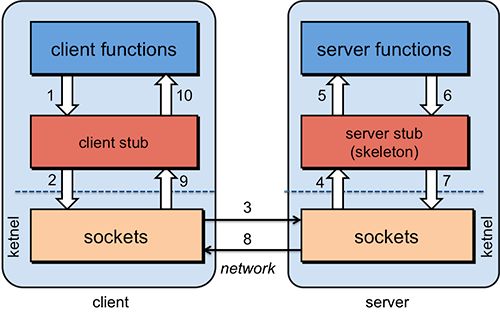
最简单的 RPC 实现如图1所示。在这种情况下,客户端(或调用方)和服务器(或被调用方)被一个物理网络分开。系统的主要组件是客户端例程/程序、客户端存根、服务器例程/程序、服务器存根和网络例程。存根是一个小程序,通常用作较大程序的替代程序(或接口)。客户端存根向客户端例程公开服务器例程提供的功能,而服务器存根向服务器例程提供类似于客户端的程序。客户端存根从客户端程序获取输入参数并返回结果,而服务器存根向服务器程序提供输入参数并获取结果。客户端程序只能与客户端存根交互,后者为客户端提供远程服务器的接口。这个存根还序列化客户端例程发送到存根的输入参数。类似地,服务器存根为服务器例程提供客户端接口,并处理发送到客户端的数据序列化。
当客户端例程执行远程过程时,它调用客户端存根,该存根序列化输入参数。这个序列化数据使用 OS 网络例程(TCP/IP)发送到服务器。然后,服务器存根将数据反序列化,并使用给定的参数提供给服务器例程。来自服务器例程的返回值再次序列化,并通过网络发送回客户端,在那里客户端存根对其进行反序列化,并显示给客户端例程。这个远程过程通常对客户端例程隐藏,并作为本地过程显示给客户端。RPC 服务还需要一个发现服务/主机解析机制来引导客户端和服务器之间的通信。
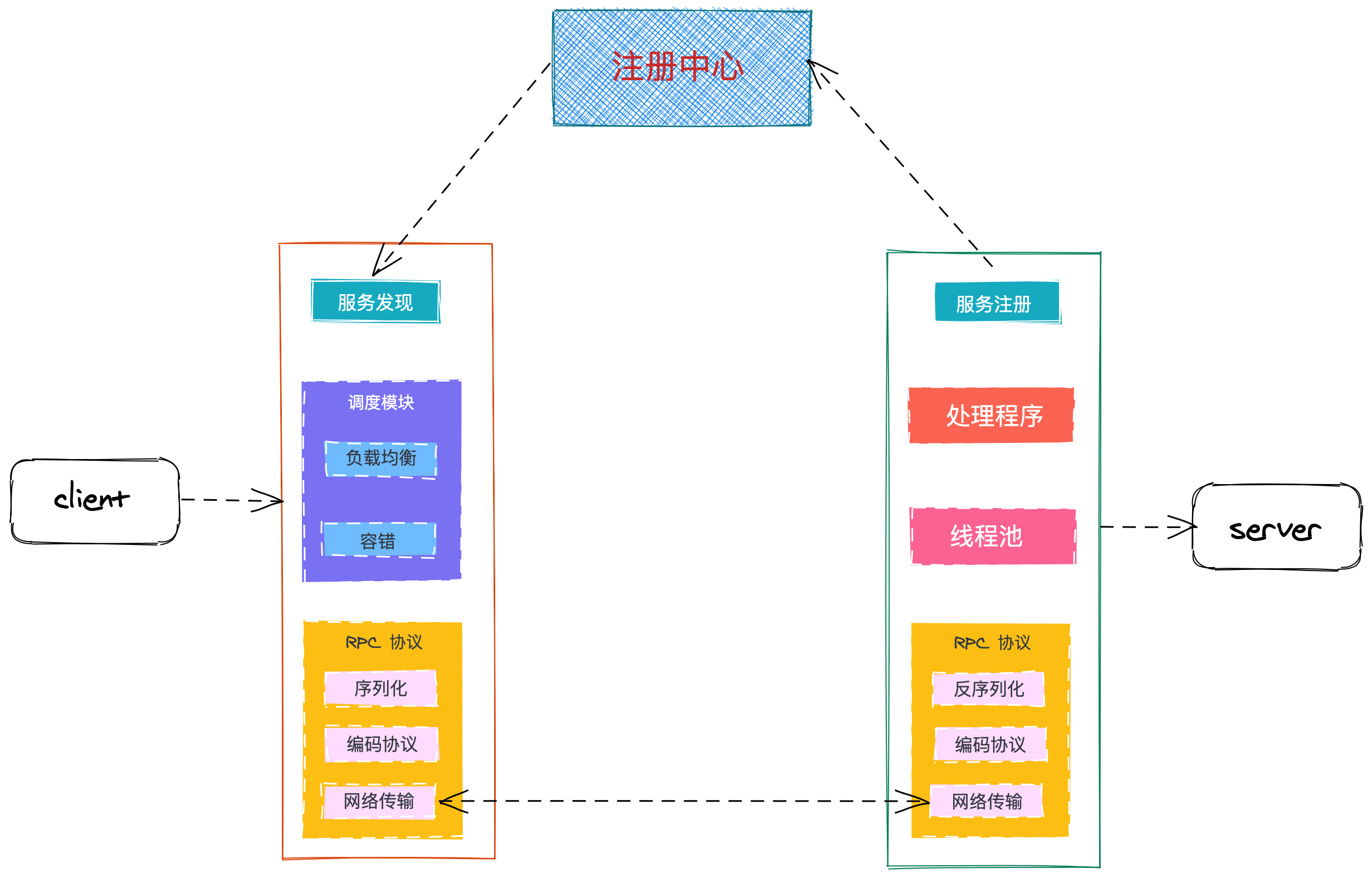
完整的 RPC 框架
**
在一个典型 RPC 的使用场景中,包含了服务发现、负载、容错、网络传输、序列化等组件,其中“RPC 协议”就指明了程序如何进行网络传输和序列化。
RPC 的发展历程
1969年11月,ARPAnet 开始建立。
1996年,美国国防部高级研究计划管理局(ARPA全称:Advanced Research Projects Agency)开始建立一个命名为ARPAnet的网络。最开始只有4个结点,分别是洛杉矶的加利福尼亚州大学洛杉矶分校、加州大学圣巴巴拉分校、斯坦福大学、犹他州大学四所大学的4台大型计算机。选择这四个节点的一个原因是要测试不同类型主机联网的兼容性。
1974年:Jon Postel 和 Jim White发表了RFC674
过程调用最早可以追溯到 Jon Postel 和 Jim White 在1974 年发表的 Procedure Call Protocol Documents Version 2(RFC674)。这个协议试图定义一种通用的方法,用于解决 NSW 项目中多个计算节点通信的问题。
协议发表后,引起了非常大的争议,1975年,RFC674的注释篇RFC684 发布。
1975年:RFC684 作为RFC 674 的注释发表,对RFC 674 的争议进行回复
RFC 684 不是一个独立的协议, 主要对 RFC674 的争议进行讨论。讨论内容可以总结为以下几点:
- RFC674 认为过程调用应该是一个原语操作,它应该在操作系统底层进行操作
- 原语是在操作系统中调用核心层子程序的指令。与一般广义指令的区别在于它是不可中断的,而且总是作为一个基本单位出现。
- 本地调用和远程调用是不同的,远程调用可能会发生故障,并且发生故障后可能无法恢复。
- 异步消息传递,或者显示的声明什么时候需要同步等待消息返回应该是一个更好的模型。
从这几点出发,关于这个编程范型的担忧成了RPC40多年历史中一个永恒的话题,即:
- 故障或错误后怎么恢复?重试、抛出异常?
- 顺序操作非常困难。比如一系列同步请求,如果其中某些请求失败,怎么保证错误的请求重新执行,以及请求还是顺序的?
- RPC 请求是同步模型,方法被调用后会等待响应,但是由于请求是同步的,在系统负载高时如果希望优先响应优先级高的请求则变成了非常困难的事情。
- 同步更多地是针对一对一的调用和返回,而不是针对单个请求的异步特性和多个返回。此外,低优先级、可抢占的后台任务也不太可能在过程调用中实现。
此时的协议还是基于阿帕网(ARPANET),互联网还没有出现,已经在讨论分布式系统间调用的问题了。
1976年:RFC 707 发布
由于远程和本地调用的成本差异,应用程序程序员必须谨慎使用远程资源,即使远程资源的使用机制将被 RTE 大大简化。与虚拟内存一样,过程调用模型提供了极大的便利,也提供了强大的能力,于此同时也应该对可能产生的滥用有合理警觉
RFC 707 概括了 RFC 684 的思想,并讨论了诸如 TELNET 和 FTP 等服务的资源共享问题,这些服务中的每一个都提供了与之交互的不同接口,这就要求操作员知道与该服务交互的具体协议。针对这种问题,作者提出了一个新的想法:与其需要知道远程计算机上所有可用的命令和协议,我们能否定义一个通用的接受参数并遵循调用/响应模型的接口来执行一个远程过程。
1983年1月1日,ARPA网将其网络核心协议由网络控制程序改变为 TCP/IP 协议
1983年1月1日,ARPA网将其网络核心协议由网络控制程序改变为 TCP/IP 协议,互联网的种子开始发芽。
1984年:论文 《Implementing remote procedure calls》发表
RPC 是远程过程调用(Remote Procedure Call)的缩写形式,Birrell 和 Nelson 在 1984 发表于 ACM Transactions on Computer Systems 的论文《Implementing remote procedure calls》对 RPC 做了经典的诠释。RPC 是指计算机 A 上的进程,调用另外一台计算机 B 上的进程,其中 A 上的调用进程被挂起,而 B 上的被调用进程开始执行,当值返回给 A 时,A 进程继续执行。调用方可以通过使用参数将信息传送给被调用方,而后可以通过传回的结果得到信息。而这一过程,对于开发人员来说是透明的。之后的几年RPC一直被认为是建立分布式操作系统的最合适的范式。
RPC(Remote Procedure Call,远程过程调用)是建立在Socket之上的一种多进程间的通信机制。不同于复杂的Socket通信方式,RPC的初心是设计一套远程通信的通用框架,这个框架能够自动处理通信协议、对象序列化、网络传输等复杂细节,并且希望开发者使用这个框架以后,调用一个远程机器上的接口的代码与以本地方法调用的代码“看起来没什么区别”,从而大大减小分布式系统的开发难度,使得不懂网络编程的程序员也能比较容易地开发分布式系统。

这是论文中的rpc架构图,可以看到user,uset-sub和其中一个RPCRuntime的实例在调用者机器上执行;server,server-sub和另外一个RPCRuntime实例在被调用者机器上执行。当user发起远程调用时,其实是执行了一个完全正常的本地调用,而这个调用会去调用user-stub中相应的程序。user-stub负责将目标程序的规范和参数放置在一个或多个包中(打包),并请求RPCRuntime将这些包可靠地传输给被调用者机器。一旦接收到这些包,被调用者机器上的RPCRuntime就这些包传送给server-stub。server-stub将它们解包,像是执行一个完全正常的本地调用一样,该本地调用会调用server中对应的程序。与此同时,调用者机器上的调用进程将被挂起,并等待结果包的返回。当server中的调用完成时,它将结果返回给user-stub打包,然后结果包将由RPCRuntime再传送回给调用者机器上挂起的进程(RCPCRuntime负责重传,确认,数据包路由和加密)。这些包将被user-stub解包并返回给user。除去多机器间机器绑定或者通信失败的影响,调用就仿佛user直接在server上调用程序一样。确实是这样,如果user和server的代码放置在同一个机器上,并被直接绑定在一起(无需stub),程序将仍能工作。
1987年:《A Critique of the Remote Procedure Call Paradigm》发表
1987年,Tanenbaum 和 Renesse发表文章《A Critique of the Remote Procedure Call Paradigm》,讨论了RPC 模型的概念问题、实现技术问题、客户端和服务端崩溃后的处理问题、不同系统间的问题以及性能等多方面的问题,并对存在的问题进行了分析。
一个通用的范例不应该要求程序员将自己限制在所选择的编程语言的一个子集中,或者强迫他们采用某种编程风格(例如,不要一刀切的使用指针,因为 RPC 不能处理它们)
在这篇评论中,作者举了一个例子:
假设两个程序员在一个项目上工作。程序员1正在编写主程序。程序员2编写一个被主程序调用的过程集合。RPC 的主题从未被提及,两个程序员都认为他们的所有代码将被编译并链接成一个单一的可执行二进制程序,并在独立的计算机上运行,不连接任何网络。
在最后一分钟,在所有的代码都经过了彻底的测试、调试和记录之后,两个程序员都辞职离开了这个国家,代码部署在充满意外的分布式系统上运行。主程序和过程代码在不同的计算机上运行。
我们的论点是,由于 RPC 试图使远程过程调用看起来与本地过程调用完全一样,但无法完美地完成,调用过程中可能会出现大量的错误。虽然许多问题可以通过修改代码来解决,但是这样就失去了透明性。一旦我们承认真正的透明性是不可能的,并且程序员必须知道哪些调用是远程的,哪些是本地的,我们就会面临这样一个问题: 在根本没有尝试使远程计算看起来像本地的前提下,部分透明的机制是否真的比专门为远程访问设计的机制更好。
同时,还讨论了以下几个问题:
两军问题
网络是不可靠的,无法保证数据可以100%无误的通过网络传递。
参数问题
参数编组,参数顺序,参数传递等。特别是指针类型的参数传递。 现代RPC 通常使用———————————
全局变量
既然是RPC 可以像本地调用一样使用,那么全局变量是否可以通用?
性能问题
异常处理
通常当主程序调用过程时,如果代码是正确的,那么该过程最终将返回给调用者。如果机器崩溃,主程序和程序都会死亡,整个程序必须重新运行。因此,基本上有两种操作模式: 整个程序工作或整个程序失败。 RPC 引入了另一种故障模式: 客户端工作正常,但服务器崩溃。如果一个主程序调用一个过程,但是没有响应,那么应该怎么做呢?在某些系统中,客户端会永远挂起。 另一种可能是让客户端存根在向服务器发送消息时启动计时器。如果在某个时间间隔之后没有响应,它会一次又一次地尝试。在 n 次重试之后,依然失败那么则返回一个错误码标识服务不可用。
幂等问题
1988年,RFC 1057 发布,ONC RPC 被定义为标准的RPC 规范
Sun 公司是第一个提供商业化 RPC 库和 RPC 编译器。在1980年代中期, Sun 计算机提供 RPC,并在 Sun Network File System(NFS) 得到支持。该协议被主要以 Sun 和 AT&T 为首的 Open Network Computing (开放网络计算)作为一个标准来推动。这是一个非常轻量级 RPC 系统,可用在大多数 POSIX 和类 POSIX 操作系统中使用,包括 Linux、SunOS、OS X 和各种发布版本的 BSD。这样的系统被称为 Sun RPC 或 ONC RPC。最终sun成功了,sunrpc 成了第一个rpc的标准。
ONC RPC 提供了一个编译器,需要一个远程过程接口的定义来生成客户端和服务器的存根函数。这个编译器叫做 rpcgen。在运行此编译器之前,程序员必须提供接口定义。包含函数声明的接口定义,通过版本号进行分组,并被一个独特的程序编码来标识。该程序编码能够让客户来确定所需的接口。版本号是非常有用的,即使客户没有更新到最新的代码仍然可以连接到一个新的服务器,只要该服务器还支持旧接口。
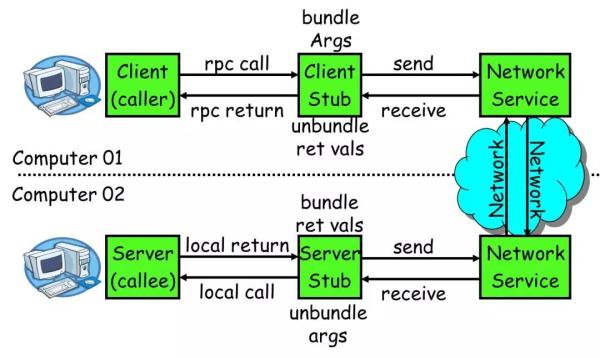
RPC的调用流程
- 服务消费方(client)以本地调用方式调用服务。
- client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体。
- client stub找到服务地址,并将消息发送到服务端。
- server stub收到消息后进行解码。
- server stub根据解码结果调用本地服务。
- 本地服务执行并将结果返回给server stub。
- server stub将返回结果打包成消息并发送至消费方。
- client stub接收到消息并进行解码。
- 服务消费方得到最终结果。

服务发现
ONC RPC 通过服务端的一个 portmapper 来实现服务发现。服务端在启动时向 portmapper 注册,portmapper 的端口是大家都知道的,所以客户端可以通过 portmapper 找到服务端。
ONC RPC 作为最早的 RPC 框架,还是有很多问题的
- 协议格式要求严格:需要客户端和服务端的压缩格式完全一致。
- 协议修改不灵活:客户端和服务端都要做修改,如果只有一方做了修改, 那 RPC 就会有错误。这导致版本更新的问题,每一次的版本更新,客户端和服务端基本是耦合的,必须同时作出更改,如果服务器没有运行,客户端是无法连接到远程过程进行调用的。管理员必须要确保在任何客户端试图连接到服务器之前将服务器启动。如果一个新服务或接口添加到了系统,客户端是不能发现的。这就要求开发客户端和服务端的需要是同一批人,或者至少要有密切的交流。
- 面向函数:面向对象的语言开始在1980年代末兴起,面向函数的ONC RPC 没有提供任何支持诸如从远程类实例化远程对象、跟踪对象的实例或提供支持多态性。现有的 RPC 机制虽然可以运作,但他们仍然不支持自动、透明的方式的面向对象编程技术。
1989年:Tim Berners-Lee 创建了万维网
1989年,蒂姆·伯纳斯-李发明了万维网。第二年9月,开发了第一个网页浏览器。到1990年圣诞节,蒂姆·伯纳斯-李创建运行万维网所需的所有工具:超文本传输协议(HTTP)、超文本标记语言(HTML)、第一个网页浏览器、第一个网页服务器和第一个网站,实现了超文本传输协议客户端与服务器的第一次通讯。他也因此而获得了2016年的图灵奖。
到1995年,互联网在美国已完全商业化。
1991年:OMG 发布CORBA 1.0
OMG成立于1989年,作为一个非营利性组织,集中致力于开发在技术上具有先进性、在商业上具有可行性并且独立于厂商的软件互联规范,推广面向对象模型技术,增强软件的可移植性(Portability)、可重用性(Reusability)和互操作性(Interoperability)。该组织成立之初,成员包括Unisys、Sun、Cannon、Hewlett-Packard和Philips等在业界享有声誉的软硬件厂商,目前该组织拥有800多家成员。
CORBA(Common Object Request Broker Architecture) 是面向对象语言的一个抽象,由 C++ 开发,它允许你在不同的语言和不同的机器上运行的不同的地址空间之间进行通信。CORBA 依赖于使用接口定义语言(IDL)来指定远程对象类的接口; 这种 IDL 用于生成远程系统对象接口在本地机器上的接口。这些 IDL 将用于生成 IDL 提供的抽象接口与 C++ 和 Java 等语言的实际实现之间的映射。
CORBA 试图为应用程序开发人员提供几个好处: 语言独立性、操作系统独立性、体系结构独立性、通过 IDL 中的抽象类型映射到这些类型的机器和语言特定实现的静态类型,以及对象传输,其中对象可以通过不同机器之间的连接进行迁移。CORBA 的承诺是,通过使用映射,远程调用可以作为本地调用出现,分布式系统相关的异常可以映射到本地异常,并由本地异常处理机制处理。
1994年:A Note on Distributed Computing 发布
Jim Waldo 等人发表了一篇 名为 《A Note on Distributed Computing》的论文。 这篇论文详细讨论了为什么 RPC 模型扩展到对象,是有问题的。
在这篇论文中,作者认为忽视本地和分布式计算之前的差异是很危险的,同时它还讨论了一个统一的对象视图,并列举了在 RPC 中将这些对象划分为分布式计算的4个主要问题: 通信延迟、解决空间分离、部分故障和并发问题(由于通过两个并发的客户端请求访问同一个远程对象而导致)。这些问题中的大多数(除了部分故障)都与分布式计算本身有着内在的联系,但是对于 RPC 系统来说,部分故障即意味着 RPC 系统并不总是可用的。
同时,作者也认为分布式计算的难题不在于如何在线上或者线下进行操作,并且每隔10年,我们就会试图统一本地计算和远程计算,并且每次都会遇到同样的问题:远程计算和本地计算是不同的。
作者认为,远程计算的问题主要有以下内容:
延迟
本地调用和远程调用最明显的区别应该是延迟问题: 如果忽略延迟,最终将直接影响软件性能。他指出,“依赖于底层硬件稳步增长的速度”是错误的,并且使用 “真正的子弹” 并不总是可能进行测试。性能分析和重定位是非常重要的,在某一点上是最优的设计不一定保持最优。
部分失败
在本地计算机中,故障是可以检测到的,并且主程序有足够的控制权。但对于分布式计算来说,情况并非如此: 远程组件可能失败,如果发生了部分失败、连接失败与远程处理器失败无法区分。
Waldo 认为,如果想要实现统一对象模型,只有两条道路。
- 将所有对象视为本地对象
- 将所有对象视为远程对象。
但最重要的问题不是“你能让远程方法调用看起来像本地方法调用吗?而是使远程方法调用与本地方法调用相同的代价是什么?
这是一个不能忽略的问题。
到这里为止我们看到针对RPC 的讨论基本都是在讨论设计、实现、面向对象、性能、分布式问题如何解决。有一点好像被忽略了,那就是易用性。为什么呢?是因为当时的程序员喜欢复杂的技术么?
我以前老大有一次分享的时候说,他认为并不是所有的开发者都是合格的程序员,合格的程序员应该是像林纳斯、丹尼斯、蒂姆那样,尝试改变世界并且为之努力的人。互联网早期,开发者数量较少,程序员是一个相对小众精英的团体,这种程序员占得比例也大,协议制定的时候更多考虑的也是如何压榨计算机性能,易用性可能也不在第一优先级范围内。
而到了90年代后期,互联网已经开始普及,随着web 开发的兴起,开发者也以指数的速度增长,这时开发框架就不仅仅要考虑小部分人的使用体验而是要照顾大多数人的使用体验了。
1996年:HTTP/1.x 版本发布
1996 年,HTTP/1.0 版本发布,大大丰富了 HTTP 的传输内容,除了文字,还可以发送图片、视频等,这为互联网的发展奠定了基础。
相比 HTTP/0.9,HTTP/1.0 主要有如下特性:
- 请求与响应支持 HTTP 头,增加了状态码,响应对象的一开始是一个响应状态行
- 协议版本信息需要随着请求一起发送,支持 HEAD,POST 方法
- 支持传输 HTML 文件以外其他类型的内容
在 HTTP/1.0 发布几个月后,HTTP/1.1 就发布了。HTTP/1.1 更多的是作为对 HTTP/1.0 的完善
1997年:OMG发布CORBA2.0
1994年12月,CORBA 2.0 就已经发布规范,该规范希望能够解决不同厂商根据COBRA规范所开发的产品“互联互不通”的严重问题,但直到1997年,Corba2.0 才正式发布,但是最后还是失败了。至于COBRA失败的原因,COBRA阵营的技术大牛、COBRA技术的推动者,即后来加入反COBRA阵营的Michi Henning,在他的《The rise and fall of CORBA》书里做了如下深刻的总结。
- 规范巨大而复杂:许多特性都未曾被实现,甚至概念性的证明都没有做过;有些技术特性根本不可能实现,即使实现,也无法提供可移植性。
- CORBA学习曲线陡峭:平台的学习曲线陡峭,技术复杂,不容易正确使用,这些因素导致开发周期长、易出错。早期的实现常常充满Bug并且缺乏有质量的文档,有经验的CORBA程序员稀缺。
- 编程开发过于复杂:有经验的CORBA开发者发现编写实用的CORBA应用程序相当困难。许多API都很复杂、不一致,甚至让人感觉神秘,使得开发者必须关注许多细节问题。相比之下,组件模型的简单性,例如同时代的EJB,使得编程简单很多。
- 费用昂贵:使用商用CORBA产品时,开发者一般都需要花费几千美元购买开发者License,此外,部署CORBA产品与部署Oracle数据库一样,还需要客户支付企业License费用,而且这个费用很可能与部署在CORBA平台上的应用数量挂钩,因此对很多潜在的客户来说,CORBA这样的平台太昂贵了。
- Sun与Java成为COBRA最大的竞争对手:商业公司转向了Sun的Java与新兴的Web,并且开始构建基于Web浏览器、Java和EJB的电子商务基础设施。
- XML技术的兴起加速了COBRA的没落:20世纪90年代后期,XML成为计算机工业新的银弹,几乎所有定义为XML的东西都是好的。在放弃了DCOM之后,微软并没有把电子商务市场留给竞争对手,没有再参与一场不可能打赢的战争,而是使用XML开辟了新的战场。
2002年:ZeroC Ice 发布
最初参与CORBA 的一批技术专家不满CORBA 的设计,另起炉灶打造了新的RPC—-即 ZeroC Ice,ICE 最初的广告语为“反叛之冰”。它也一直延续至今,发展成了一个强大的微服务架构平台。
1999年: SOAP 发布
1998 年 XML 1.0 发布,被 W3C (World Wide Web Consortium) 推荐为标准的描述语言。同年,微软和DevelopMentor发布SOAP(Simple Object Access Protocol),随后提交给W3C作为标准。SOAP是一个严格定义的信息交换协议,使用XML作为RPC新的对象序列化机制,用于在Web Service中把远程调用和返回封装成机器可读的格式化数据。
协议约定
SOAP 的协议约定用的是 WSDL (Web Service Description Language) ,这是一种 Web 服务描述语言,在服务的客户端和服务端开发者不用面对面交流,只要用的是 WSDL 定义的格式,客户端知道了 WSDL 文件,就知道怎么去封装请求,调用服务。
传输协议
SOAP 是用 HTTP 进行传输的,信息有 Header 和 Body,SOAP 的请求和回复都放在消息中,进行传递。
服务发现
SOAP 的服务发现用的是 UDDI(Universal Description, Discovery, Integration) 统一描述发现集成,相当于一个注册中心,服务提供方将 WSDL 文件发布到注册中心,使用方可以到这个注册中心查找。
SOAP严格意义上是属于XML-RPC(XML Remote Procedure Call)技术的一个变种,一个XML-RPC请求消息就是一个HTTP-POST请求消息,其请求消息主体基于XML格式。客户端发送XML-RPC请求消息到服务端,调用服务端的远程方法并在服务端上运行远程方法。远程方法执行完毕后返回响应消息给客户端,其响应消息主体同样基于XML格式。远程方法的参数支持数字、字符串、日期等,也支持列表数组和其他复杂结构类型,SOAP是第一次真正成功地解决了多语言多平台支持的开放性RPC标准。
不过SOAP也有很多不足:
- 效率低。因为报文基于XML,报文内容除了数据以外,还有很多荣冗余在格式的定义上,并且对于XML的序列化和反序列化解析速度也慢。
- 它脱离了简单的初衷,开始添加一层又一层脱离了简单方法调用的一些附加概念:添加了异常处理、 事务支持、安全性和数字签名,人们感觉 SOA 已经变成了一个复杂协议。
这又和 Waldo 的经典结论保持了一致:
尝试让远程调用的行为像本地调用的代价是不可忽略的。
之后,大家开始慢慢抛弃SOAP标准中过程化、分层的概念,开始转向更简单的Rest传输方式。
2000年:Roy Thomas Fielding 发表 RESTful 架构的博士论文
2000年,Roy Thomas Fielding 博士在他的博士论文 《Architectural Styles and the Design of Network-based Software Architectures》首次提出了 REST 这个词。
REST提供了一系列架构约束,当作为整体使用时,它强调组件交互的可扩展性、接口的通用性、组件的独立部署,以及那些能减少交互延迟的中间件,它强化了安全性,也能封装遗留系统。 —— Roy Fielding
REST 不是协议而是一种使用HTTP 协议的进程间通信机制。REST非常简单,无需客户端stub 代码 和服务端 stub代码,且所有语言都可以集成实现。HTTP REST慢慢侵占了RPC大部分应用领地的“异类”,并且导致了一度盛行的XML-RPC的灭绝,但同时促进了正统RPC技术走向一个新的发展阶段,追求更高的性能及增加对多语言多平台的支持,成为越来越多的开源RPC框架的目标,典型的代表为Thrift、Apache Avro等新生的开源框架,这些框架在大数据系统、大型分布式系统及移动互联网应用方面被越来越多的公司使用。
2008年,Vinoski 在他的论文中提出了我们开头的提问:“开发者的便利性真的比正确性、可扩展性、性能、关注点分离、可扩展性和偶然复杂度更重要吗?”
我看先看下2020 年度语言排行榜,可能能得到一些答案:
这张图是2020年开发者最爱的语言: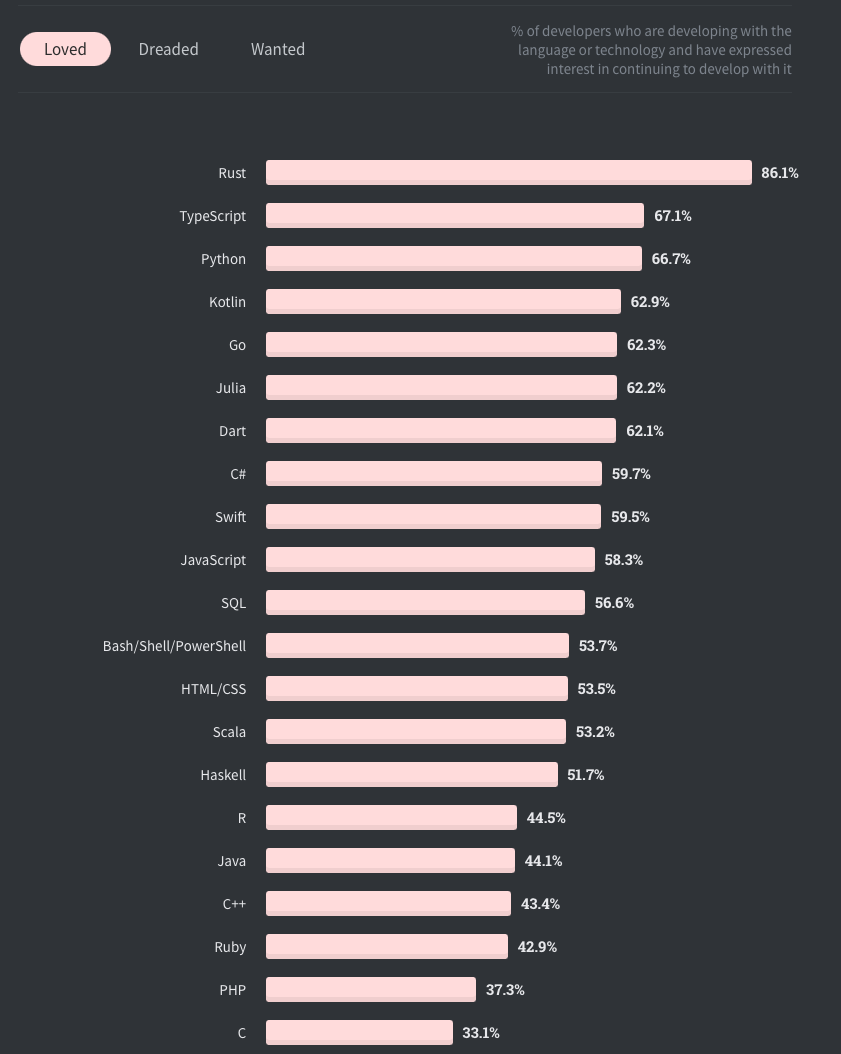
这张图是2020年最流行的语言
为什么学习曲线陡峭、设计复杂的Rust 是程序员的最爱? 为什么易学易用但有各种语言缺陷的JavaScript 能成为最流行的语言呢?
开发者的便利性真的比正确性、可扩展性、性能、关注点分离、可扩展性和偶然复杂度更重要吗?
从开发者的选择来看,答案应该是YES!**
可以看到自90年代后期进入了web 开发的时代,web1.0、web2.0、web3.0 相继出现。以 http 为基础的请求/响应方案(XML、REST) 开始流行并占领了大部分的市场。RPC也开逐渐被开发者抛弃,进入了沉默期。
当然,RPC 并没有消失,而是在特定的领域继续生长。比如:Sun 微系统的网络文件系统 (NFS) 就是建立在 RPC 之上,是最早获得普及的分布式文件系统之一。
而随着互联网的指数扩张,微服务架构开始成了业界的“银弹”,分布式系统开始变的无处不在,基于HTTP的RESTful的缺点开始放大:
- 只支持请求/响应方式的通信
- 单个请求中获取多个资源具有挑战性
- 有时很难将更多操作映射到HTTP动词
- 基于JSON或者XML 的消息冗余严重,性能底下。
而天生就是为分布式计算出现的RPC也开始重新走入开发者的视野。
2008年:Google 开源 Protocol Buffer
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据序列化,很适合做数据存储或 RPC 数据交换格式。它可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
2008年:FaceBook 开源 thrift
Thrift 是一个跨语言的服务部署框架,最初由Facebook于2007年开发,2008年进入Apache开源项目。Thrift通过一个中间语言(IDL, 接口定义语言)来定义RPC的接口和数据类型,然后通过一个编译器生成不同语言的代码(目前支持C++,Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, Smalltalk和OCaml),并由生成的代码负责RPC协议层和传输层的实现。
Thrift 和 Protocol Buffer 不同,它不仅仅是一个数据序列化工具,而是一个完整的RPC 框架。另一个不同点在于,Protobuf 标准化了单一的二进制编码方式,但Thrift 则包含了多种不同的序列化方式(Thirft 称之为协议)。
2010年5月: Avro脱离Hadoop项目,成为Apache顶级项目。
Avro 是一个基于二进制数据传输高性能的中间件,在2009年成为 Hadoop 中的一个子项目,并与2015年脱离Hadoop,加入Apache成为一个独立的项目。
Avro 同样支持跨编程语言实现(C, C++, C#,Java, Python, Ruby, PHP),Avro 提供着与诸如 Thrift 和 Protocol Buffers 等系统相似的功能,但是在一些基础方面还是有区别的,主要是:
- 动态类型:Avro 并不需要生成代码,模式和数据存放在一起,而模式使得整个数据的处理过程并不生成代码、静态数据类型等等。这方便了数据处理系统和语言的构造。
- 未标记的数据:由于读取数据的时候模式是已知的,那么需要和数据一起编码的类型信息就很少了,这样序列化的规模也就小了。
- 不需要用户指定字段号:即使模式改变,处理数据时新旧模式都是已知的,所以通过使用字段名称可以解决差异问题。
Avro 和动态语言结合后,读/写数据文件和使用 RPC 协议都不需要生成代码,而代码生成作为一种可选的优化只需要在静态类型语言中实现。
当在 RPC 中使用 Avro 时,服务器和客户端可以在握手连接时交换模式。服务器和客户端有着彼此全部的模式,因此相同命名字段、缺失字段和多余字段等信息之间通信中需要解决的一致性问题就可以容易解决。
还有,Avro 模式是用 JSON(一种轻量级的数据交换模式)定义的,这样对于已经拥有 JSON 库的语言可以容易实现。
可以看到的是,avro 相对pb 和 thrift 来说更简单一点。
2015年:HTTP/2.0 发布
虽然 HTTP/1.1 已经优化了很多点,作为一个目前使用最广泛的协议版本,已经能够满足很多网络需求,但是随着网页变得越来越复杂,甚至演变成为独立的应用,HTTP/1.1 逐渐暴露出了一些问题:
- 在传输数据时,每次都要重新建立连接,对移动端特别不友好
- 传输内容是明文,不够安全
- header 内容过大,每次请求 header 变化不大,造成浪费
- keep-alive 给服务端带来性能压力
在 2010 年到 2015 年,谷歌通过实践一个实验性的 SPDY 协议,证明了一个在客户端和服务器端交换数据的另类方式。其收集了浏览器和服务器端的开发者的焦点问题,明确了响应数量的增加和解决复杂的数据传输。SPDY 最终进化成了HTTP2.0 并与2015年发布。
- 使用二进制分帧层:在应用层与传输层之间增加一个二进制分帧层,以此达到在不改动 HTTP 的语义,HTTP 方法、状态码、URI 及首部字段的情况下,突破HTTP1.1 的性能限制,改进传输性能,实现低延迟和高吞吐量。在二进制分帧层上,HTTP2.0 会将所有传输的信息分割为更小的消息和帧,并对它们采用二进制格式的编码,其中 HTTP1.x 的首部信息会被封装到 Headers 帧,而我们的 request body 则封装到 Data 帧里面。
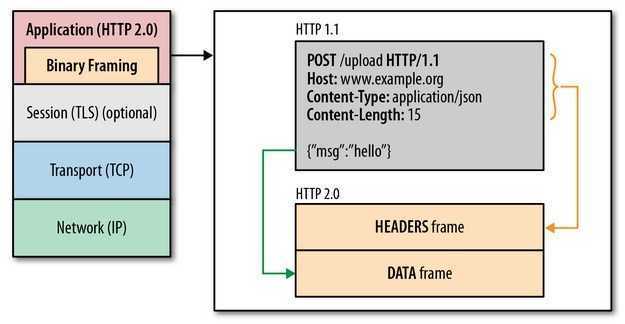
- 多路复用:对于 HTTP/1.x,即使开启了长连接,请求的发送也是串行发送的,在带宽足够的情况下,对带宽的利用率不够,HTTP/2.0 采用了多路复用的方式,可以并行发送多个请求,提高对带宽的利用率。

- 数据流优先级:由于请求可以并发发送了,那么如果出现了浏览器在等待关键的 CSS 或者 JS 文件完成对页面的渲染时,服务器却在专注的发送图片资源的情况怎么办呢?HTTP/2.0 对数据流可以设置优先值,这个优先值决定了客户端和服务端处理不同的流采用不同的优先级策略。
- 服务端推送:在 HTTP/2.0 中,服务器可以向客户发送请求之外的内容,比如正在请求一个页面时,服务器会把页面相关的 logo,CSS 等文件直接推送到客户端,而不会等到请求来的时候再发送,因为服务器认为客户端会用到这些东西。这相当于在一个 HTML 文档内集合了所有的资源。
- 头部压缩:使用首部表来跟踪和存储之前发送的键值对,对于相同的内容,不会再每次请求和响应时发送。

可以看到 HTTP/2.0 的新特点和 SPDY 很相似,其实 HTTP/2.0 本来就是基于 SPDY 设计的,可以说是 SPDY 的升级版。
2015年:Google 开源gRPC
2015 年,Google 将gRPC框架开源,gRPC 使用 PB 作为序列化的解决方案,而在传输的介质上使用了 HTTP/2而不是常见的TCP。gRPC 是一个多路复用、双向流式 RPC 协议。在一般的 RPC 机制中,客户端发起到服务器的连接,只有客户端可以请求,而服务器只能响应传入的请求。然而,在双向 gRPC 流中,虽然初始连接是由客户端发起的(称为端点1) ,但是一旦建立连接,服务器(称为端点2)和端点1都可以发送请求和接收响应。这极大地简化了两个端点相互通信的开发(如网格计算)。由于两个数据流都是独立的,这也省去了在端点之间创建两个独立连接的麻烦(一个从端点1到端点2,另一个从端点2到端点1)。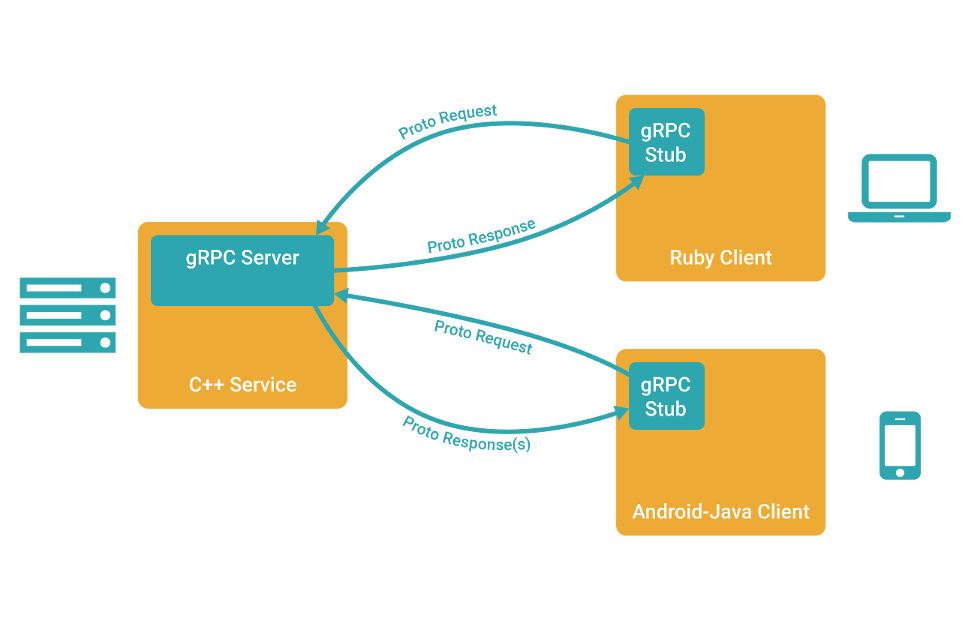
总结
- RPC 的发展方向是易用性,异步
- 易用性可能真的比扩展性、性能、关注点分离、可扩展性和偶然复杂度更重要
- 让远程调用向本地调用一样的代价是不可忽略的
参考链接:
CORBA
Implementing Remote Procedure Calls 中文版
花了一个星期,我终于把RPC框架整明白了
RPC原理详解
理解Rest和Rpc
谁能用通俗的语言解释一下什么是 RPC 框架?
什么是Rpc
什么是Rpc
微服务通信
寻根溯源:微服务模式发展简史
https://thrift.apache.org
http://avro.apache.org
https://insights.stackoverflow.com/survey/2020#overview

若有收获,就点个赞吧
0 人点赞
