BigDL 2.0: Seamless Scaling of AI Pipelines from Laptops to Distributed Cluster
阅读时间:2022-09-23
期刊: SN Computer Science 作者: Iqbal H. Sarker 发表日期:22 March 2021Abstract:
大多数人工智能项目都是从运行在一台笔记本电脑上的Python笔记本开始的; 然而,通常需要经历堆积如山的痛苦才能扩展它来处理更大的数据集 (用于实验和生产部署)。对于数据科学家来说,这些通常需要许多手动且容易出错的步骤来充分利用可用的硬件资源 (例如,SIMD指令、多处理、量化、存储器分配优化、数据分区、分布式计算等)。为了应对这一挑战,我们在Apache 2.0许可下在: https://github.com/intel-analytics/BigDL/ 开源BigDL 2.0 (结合了原始BigDL [19] 和analytics Zoo [18] 项目); 使用BigDL 2.0,用户可以简单地在他们的笔记本电脑上构建传统的Python笔记本电脑 (可能支持AutoML),然后可以在单个节点上透明地加速 (在我们的实验中,加速速度高达9.6倍),并无缝扩展到一个大型集群 (在实际使用情况下跨越数百台服务器)。BigDL 2.0已经被许多现实世界的用户 (如万事达卡、汉堡王、浪潮等) 在生产中采用。
Keywords:
Article skeleton:

Facing the challenges:
Conclusion:
Personal feelngs:
Related images:
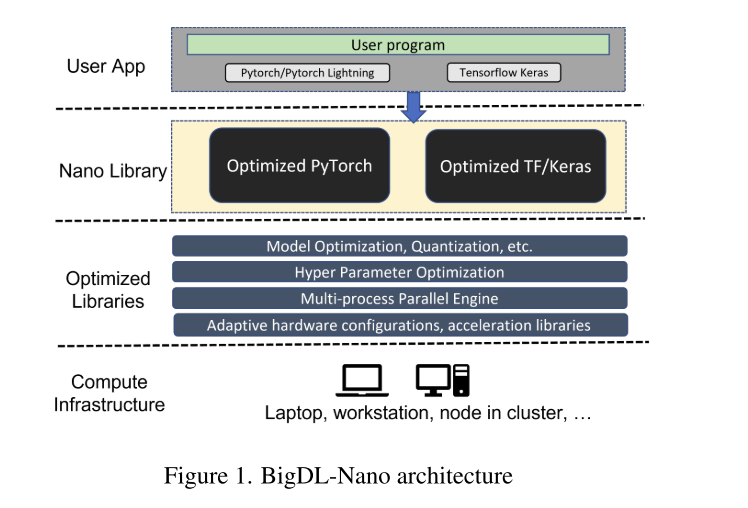
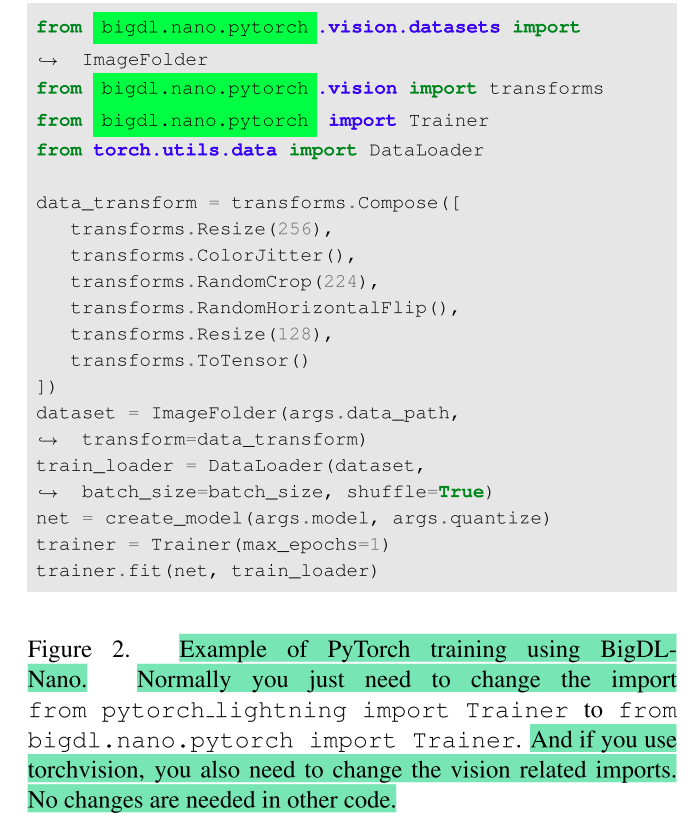
BigDL: A Distributed Deep Learning Framework for Big Data
阅读时间:2022-09-23
期刊: SN Computer Science 作者: Iqbal H. Sarker 发表日期:22 March 2021Abstract:
本文介绍了 BigDL(Apache Spark 的分布式深度学习框架),该框架已被业界多种用户用于在生产大数据平台上构建深度学习应用程序。它允许深度学习应用程序在 Apache Hadoop/Spark 集群上运行,从而直接处理生产数据,并作为端到端数据分析管道的一部分进行部署和管理。与现有的深度学习框架不同,BigDL 直接在 Spark 的功能计算模型(具有写入时复制和粗粒度操作)之上实现分布式数据并行训练。我们还分享了采用 BigDL 来解决他们的挑战的用户的真实经验和“战争故事”(即,如何轻松地为他们的生产数据构建端到端数据分析和深度学习管道)。
Keywords:
distributed deep learning, big data, Apache Spark, end-to-end data pipeline
Article skeleton:
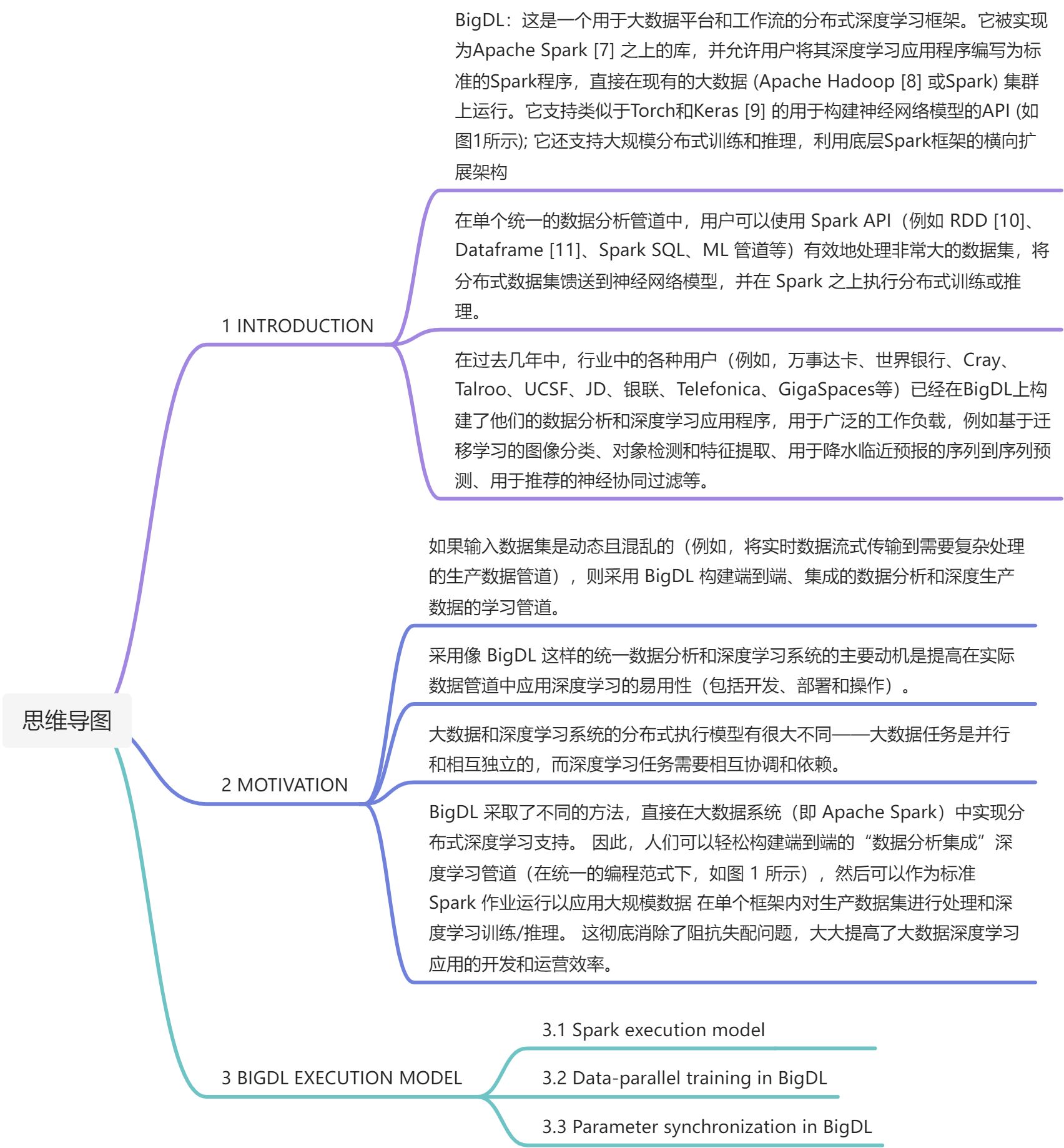
Facing the challenges:
Conclusion:
Personal feelngs:
Related images:

若有收获,就点个赞吧
0 人点赞
