0. 线程池
https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html?from=timeline
为什么要用线程池
- 相比new Thread,Java提供的四种线程池的好处在于:
a. 重用存在的线程,减少对象创建、消亡的开销,性能佳。
b. 可有效控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞。
c. 提供定时执行、定期执行、单线程、并发数控制等功能。
- Java通过Executors提供四种线程池,分别为:
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
- Executor框架有其局限性,不够灵活
Executor框架虽然提供了如newFixedThreadPool()、newSingleThreadExecutor()、newCachedThreadPool()等创建线程池的方法,
但都有其局限性,不够灵活;另外由于前面几种方法内部也是通过ThreadPoolExecutor方式实现,
使用ThreadPoolExecutor有助于大家明确线程池的运行规则,创建符合自己的业务场景需要的线程池,避免资源耗尽的风险。
线程池的原理
线程池的核心参数都是什么含义
//使用线程池来创建线程,简易版private static ExecutorService threadPool = new ThreadPoolExecutor(50, 300, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>());threadPool.submit(() -> {log.info("线程开始");});
ThreadPoolExecutor的构造函数
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {if (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.acc = System.getSecurityManager() == null ?null :AccessController.getContext();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;}
- corePoolSize:指定了线程池中的线程数量,它的数量决定了添加的任务是开辟新的线程去执行,还是放到workQueue任务队列中去;
- maximumPoolSize:指定了线程池中的最大线程数量,这个参数会根据你使用的workQueue任务队列的类型,决定线程池会开辟的最大线程数量;
- keepAliveTime:当线程池中空闲线程数量超过corePoolSize时,多余的线程会在多长时间内被销毁;
- unit:keepAliveTime的单位
- workQueue:任务队列,被添加到线程池中,但尚未被执行的任务;它一般分为直接提交队列、有界任务队列、无界任务队列、优先任务队列几种;
- 直接提交队列:参数为SynchronousQueue队列(new SynchronousQueue
())
SynchronousQueue是一个特殊的BlockingQueue,它没有容量,每执行一个插入操作就会阻塞,需要再执行一个删除操作才会被唤醒,反之每一个删除操作也都要等待对应的插入操作。** - 有界的任务队列:参数为ArrayBlockingQueue有界任务队列( new ArrayBlockingQueue
(10))
若有新的任务需要执行时,线程池会创建新的线程,直到创建的线程数量达到corePoolSize时,则会将新的任务加入到等待队列中。若等待队列已满,即超过ArrayBlockingQueue初始化的容量,则继续创建线程,直到线程数量达到maximumPoolSize设置的最大线程数量,若大于maximumPoolSize,则执行拒绝策略。在这种情况下,线程数量的上限与有界任务队列的状态有直接关系,如果有界队列初始容量较大或者没有达到超负荷的状态,线程数将一直维持在corePoolSize以下,反之当任务队列已满时,则会以maximumPoolSize为最大线程数上限。 - 无界的任务队列:参数为LinkedBlockingQueue无界的任务队列(new LinkedBlockingQueue
())
使用无界任务队列,线程池的任务队列可以无限制的添加新的任务,而线程池创建的最大线程数量就是你corePoolSize设置的数量,也就是说在这种情况下maximumPoolSize这个参数是无效的,哪怕你的任务队列中缓存了很多未执行的任务,当线程池的线程数达到corePoolSize后,就不会再增加了;若后续有新的任务加入,则直接进入队列等待,当使用这种任务队列模式时,一定要注意你任务提交与处理之间的协调与控制,不然会出现队列中的任务由于无法及时处理导致一直增长,直到最后资源耗尽的问题。 - 优先任务队列: 参数为PriorityBlockingQueue(new PriorityBlockingQueue
())
除了第一个任务直接创建线程执行外,其他的任务都被放入了优先任务队列,按优先级进行了重新排列执行,且线程池的线程数一直为corePoolSize,也就是只有一个。PriorityBlockingQueue它其实是一个特殊的无界队列,它其中无论添加了多少个任务,线程池创建的线程数也不会超过corePoolSize的数量,只不过其他队列一般是按照先进先出的规则处理任务,而PriorityBlockingQueue队列可以自定义规则根据任务的优先级顺序先后执行。
- threadFactory:线程工厂,用于创建线程,一般用默认即可;线程池中线程就是通过ThreadPoolExecutor中的ThreadFactory,线程工厂创建的。那么通过自定义ThreadFactory,可以按需要对线程池中创建的线程进行一些特殊的设置,如命名、优先级等
- handler:拒绝策略;当任务太多来不及处理时(maximumPoolSize),如何拒绝任务;1、AbortPolicy策略:该策略会直接抛出异常,阻止系统正常工作;2、CallerRunsPolicy策略:如果线程池的线程数量达到上限,该策略会把任务队列中的任务放在调用者线程当中运行;3、DiscardOledestPolicy策略:该策略会丢弃任务队列中最老的一个任务,也就是当前任务队列中最先被添加进去的,马上要被执行的那个任务,并尝试再次提交;4、DiscardPolicy策略:该策略会默默丢弃无法处理的任务,不予任何处理。当然使用此策略,业务场景中需允许任务的丢失;5、自己扩展RejectedExecutionHandler接口,定义自己的拒绝策略
ThreadPoolExecutor扩展ThreadPoolExecutor扩展主要是围绕beforeExecute()、afterExecute()和terminated()三个接口实现的,1、beforeExecute:线程池中任务运行前执行2、afterExecute:线程池中任务运行完毕后执行3、terminated:线程池退出后执行 ```java /**
- 手动创建线程池
- @param name 名称
- @param num 数量
@return */ public ExecutorService getExecutorService(Integer num,String name) { //线程工厂 ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat(name).build();
//启动线程池 return new ThreadPoolExecutor(num, num,
0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>(), namedThreadFactory,new ThreadPoolExecutor.AbortPolicy()
){
@Overrideprotected void afterExecute(Runnable r, Throwable t) {super.afterExecute(r, t);printException(r, t);}
}; } private static void printException(Runnable r, Throwable t) { if (t == null && r instanceof Future<?>) {
try {Future<?> future = (Future<?>) r;if (future.isDone()){future.get();}} catch (CancellationException ce) {t = ce;} catch (ExecutionException ee) {t = ee.getCause();} catch (InterruptedException ie) {Thread.currentThread().interrupt();}
} if (t != null){
log.error(t.getMessage(), t);
}
}
<a name="b1j7c"></a># 1.多线程实现(两种)线程的执行顺序不能人为干预,是由调度器(CPU)去处理的<br />多个线程在操作同一个资源的时候,会出现抢夺i问题,需要加入并发控制<a name="fedlV"></a>## 实现方法一:继承Thread类,重写run()方法,调用start()启动线程 ------- 单继承局限性- 线程调用run()和start()是不一样的<br />start()方法: 它会启动一个新线程,并将其添加到线程池中,待其获得CPU资源时会执行run()方法,start()不能被重复调用。run()方法:它和普通的方法调用一样,不会启动新线程。只有等到该方法执行完毕,其它线程才能获得CPU资源。start()实际上是通过本地方法start0()启动一个新线程,新线程会调用run()方法。- 线程创建不一定立即执行,受CPU调度影响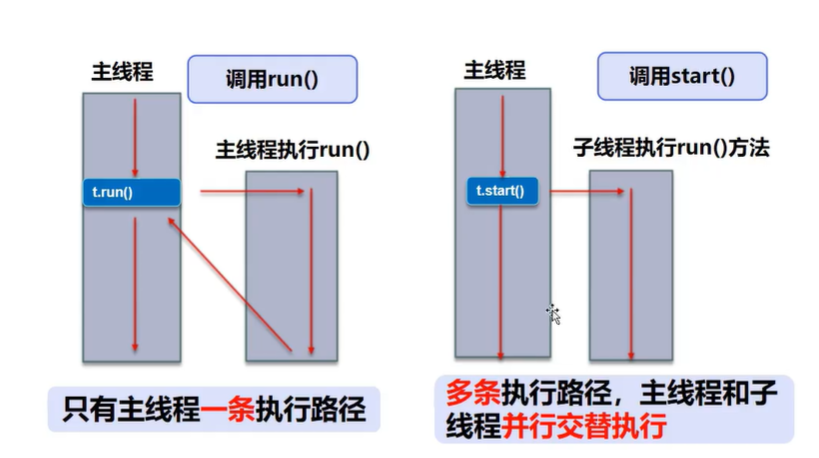```javapackage com.faq.demo01;//创建线程方式一:继承Thread类,重写run()方法,调用start开启线程//总结:注意,线程的开启不一定立即执行,由CPU调度执行public class TestThread1 extends Thread{@Overridepublic void run() {//run方法线程体for (int i = 0; i < 20; i++) {System.out.println("我在看代码--"+i);}}public static void main(String[] args) {//main线程,主线程//创建一个线程对象TestThread1 testThread = new TestThread1();//调用start()方法开启线程//testThread.run();//普通方法调用testThread.start();//与主线程交替运行for (int i = 0; i < 20; i++) {System.out.println("我在学习多线程--"+i);}}}
实现方法二:实现Runable类,实现run()方法,创建线程对象调用start()启动线程 ———— 方便同一个对象被多个线程使用
package com.faq.demo01;//创建线程方式2:实现runnable接口,重写run方法,执行线程需要丢入runnable接口实现类,调用start方法public class TestThread3 implements Runnable{@Overridepublic void run() {//run方法线程体for (int i = 0; i < 20; i++) {System.out.println("我在看代码--"+i);}}public static void main(String[] args) {//main线程,主线程//创建runnable接口的实现类对象TestThread3 testThread3 = new TestThread3();//创建线程对象,通过线程对象来开启我们的线程,代理Thread thread = new Thread(testThread3);thread.start();//可以合起来写成new Thread(testThread3).start();for (int i = 0; i < 20; i++) {System.out.println("我在学习多线程--"+i);}}}
实现方式三:实现Callable接口
- 需要返回值类型
- 重写call方法,需要抛出异常
- 创建目标对象
- 创建执行服务ExecutorService ser = Executors.newFixedThreadPool(1);
- 提交执行
Futureresult1=ser.submit(t1); - 获取结果
boolean r1 = result1.get() - 关闭服务
ser.shutdownNow(); ```java package com.faq.demo02;
import org.apache.commons.io.FileUtils;//别人的类
import java.io.File; import java.io.IOException; import java.net.URL; import java.util.concurrent.*;
//线程创建方式三:实现Callable接口 /* Callable的好处: 1、可以定义返回值 2、可以抛出异常
*/
public class TestCallable implements Callable
public TestCallable(String url,String name){this.url=url;this.name=name;}//线程的执行体@Overridepublic Boolean call(){WebDownloader webDownloader = new WebDownloader();webDownloader.downloader(url,name);System.out.println("下载了文件名为:"+name);return true;}public static void main(String[] args) throws ExecutionException, InterruptedException {TestCallable t1 = new TestCallable("https://img-home.csdnimg.cn/images/20210114101935.png","1.jpg");TestCallable t2 = new TestCallable("https://img-home.csdnimg.cn/images/20201125054322.jpg","2.jpg");TestCallable t3 = new TestCallable("https://img-bss.csdn.net/1609984629114.jpg","3.jpg");//创建执行服务:ExecutorService ser = Executors.newFixedThreadPool(3);//提交执行:Future<Boolean> result1=ser.submit(t1);Future<Boolean> result2=ser.submit(t2);Future<Boolean> result3=ser.submit(t3);//获取结果:boolean r1 = result1.get();boolean r2 = result2.get();boolean r3 = result3.get();//打印返回值System.out.println(r1);System.out.println(r2);System.out.println(r3);//关闭服务:ser.shutdownNow();}
}
//下载器 class WebDownloader{ //下载方法 public void downloader(String url,String name){ try { FileUtils.copyURLToFile(new URL(url),new File(name));//调用类中方法 } catch (IOException e) { e.printStackTrace(); System.out.println(“IO异常,downloader方法出现问题”); } }
} 输出: 下载了文件名为:1.jpg 下载了文件名为:3.jpg 下载了文件名为:2.jpg true true true ```
2.多线程同步
同步解决的问题:每个线程在自己的工作内存交互,内存控制不当会造成数据不一致
3.多线程通信

若有收获,就点个赞吧
0 人点赞
