对Hbase基础概念还不了解的同学请移步这篇文章
背景
公司团队初期将业务数据和日志数据都存储到了Mysql,后来随着业务增长,日志数量级已达千万,为避免触及性能瓶颈,决定将底层数据库选型由Mysql更改为Hbase。借此机会,查阅网上相关文章,结合自己的理解,从原理到应用解释Mysql和Hbase的区别。
二者简介
MySQL
MySQL是一种开放源代码的关系型数据库管理系统(RDBMS),主要面向OLTP,支持事务,支持多种索引,支持sql操作,支持主从。MySQL数据库系统使用最常用的数据库管理语言——结构化查询语言(SQL)进行数据库管理。
Hbase
HBase is a column-oriented database management system that runs on topof Hadoop Distributed File System (HDFS)。HBase 是运行在 HDFS 之上的面相列的数据库管理系统。注意 HBase 不是列式存储数据库,每一个列簇就是一个HFiel。有以下特点● 天然分布式,主从架构● NoSQL数据库,不支持事务,不支持sql● 不支持二级索引,仅能通过主键(row key)和主键的 range 来检索数据。● 海量数据存储:支持随机CRUD,亿级数据秒级响应。
存储结构不同
在说它们存储结构之前先给大家说一下行式存储和列式存储的区别:
行式存储相当于套餐,即使一个人来了也给你上八菜一汤,造成浪费;列式存储相等于自助餐,按需自取,人少了也不浪费。行式存储更像一个Java Bean,所有字段都提前定义好,且不能改变;列式存储更像一个Map,不提前定义,随意往里添加key/value。
下面举一个例子来更具体说明行式列式存储的区别,比如我们有如下表格:
行式存储模型: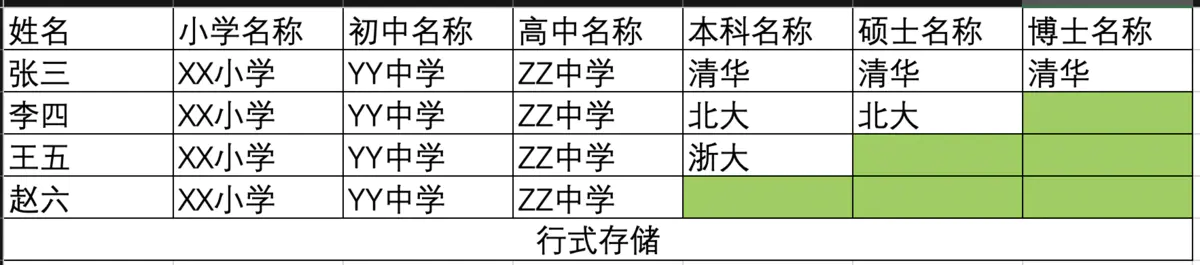
列式存储模型: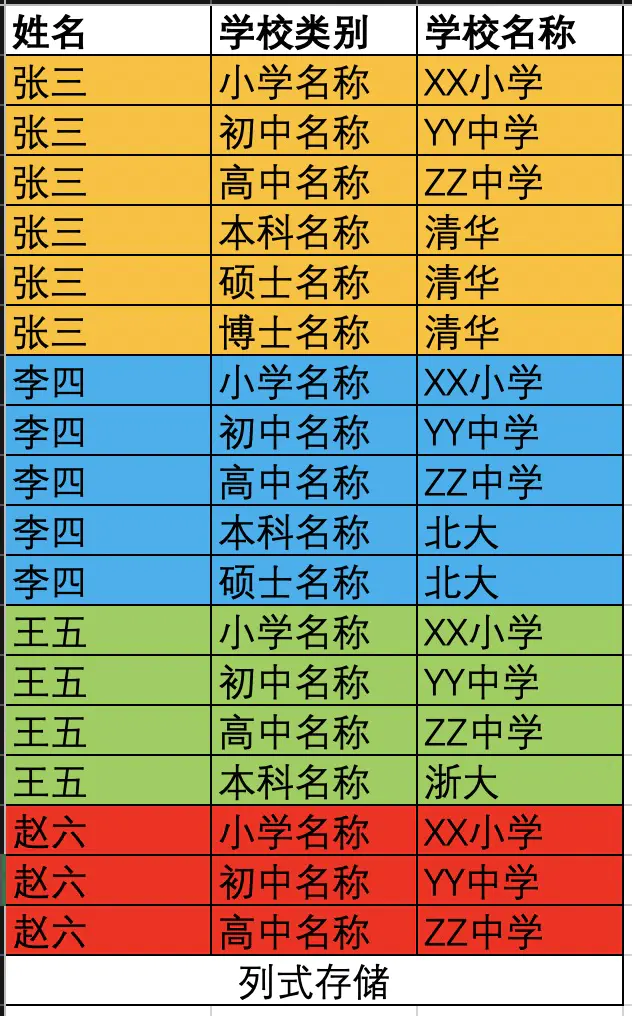
言归正传,Mysql和Hbase到底是按哪种模型存储的呢?
Mysql

Hbase
严格来讲不是列式存储。不管是存储在内存的 MemStore,还是存储在 HDFS 上的 HFile,其都是基于 LSM(Log-Structured Merge-Tree)结构存储的。下图有助于我们简单理解 MemStore 和 HFile 是怎么存储数据的,假设我们有以下一张 HBase 表。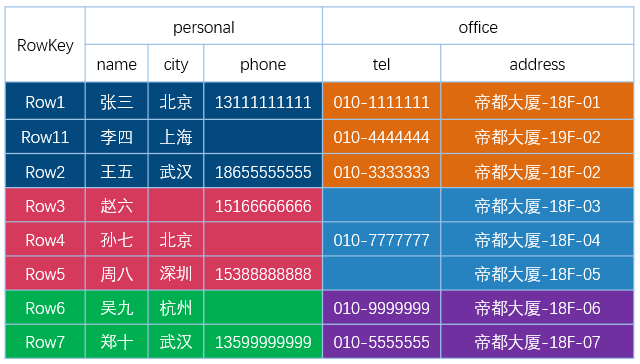
那在hbase底层的 KV 存储大概如下所示的: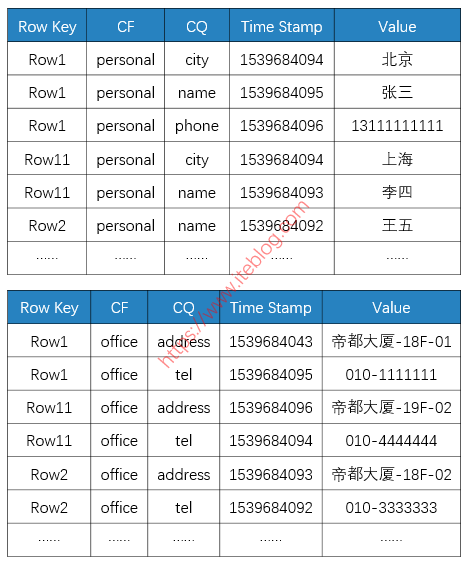
从上图可以看出:
- 不同的列族存在不同的文件中(上面两个表格代表不同的 HFile);
- HFiel里的数据是按照 Rowkey 进行字典排序的;
- 每一列数据在底层 HFile 中是以 KV 形式存储的;
- 相同的一行数据中,只有列族一样,这些数据才是顺序放在一起的。
到这里大家应该可以看到,HBase 其实不是列式数据库,因为同一行数据,如果列族不一样,那这些数据是没有存储在相邻位置的;
CRUD原理不同
Mysql
MySQL的Innodb中的数据是按主键的顺序依次存放,主键即为聚簇索引,索引采用B+树结构进行组织。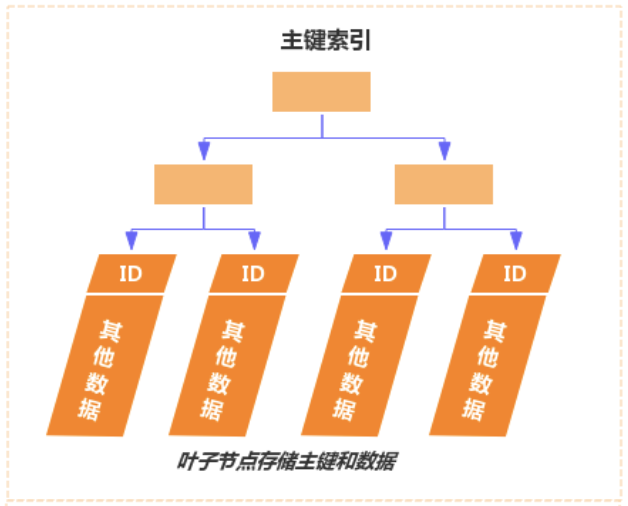
从图中可以看出,数据是按聚簇索引顺序依次存放,假设下面一些场景:
1.查询
Innodb中主键即为聚簇索引,假如根据主键查询,聚簇索引的叶子节点存放就是真正的数据,可以直接查到相应的记录。
假如是二级索引查询,那么需要先通过二级索引找到该记录的主键,然后根据主键通过聚簇索引找到对应的记录,这里多了一个索引查找的过程。
2.插入
顺序插入:因为Innodb的数据是按聚簇索引的顺序依次存放的,如果是根据主键索引的顺序插入,即插入的数据的主键是连续的,因为是顺序io,所以插入效率会较高。
随机插入:假如每次插入的数据主键是不连续的,MySQL需要取出每条记录对应的物理block,会引起大量的随机io,随机io操作和顺序io的性能差距很大,尤其是机械盘。
(Kafka官网提到一个机械盘的顺序写能达到600M/s,而随机写可能只有100k/s。As a result the performance of linear writes on aJBODconfiguration with six 7200rpm SATA RAID-5 array is about 600MB/sec but the performance of random writes is only about 100k/sec—a difference of over 6000X.这也是为什么HBase、ES将所有的insert、update、delete操作都统一看成顺序写操作,避免随机io)
note:这也是为什么MySQL的主键通常定义为自增id,不涉及业务逻辑,这样新数据插入时能保证是顺序io。另外MySQL为了提高随机io的性能,提供了insert buffer的功能。
3.更新 & 删除
update和delete如果不是顺序的话,也会包含大量的随机io,当然MySQL都针对随机io都进行了一些优化,尽量减少随机io带来的性能损失。
Hbase
HBase不支持二级索引,它只有一个主键索引,采用LSM树。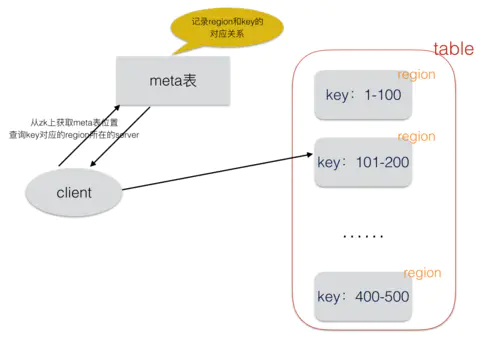
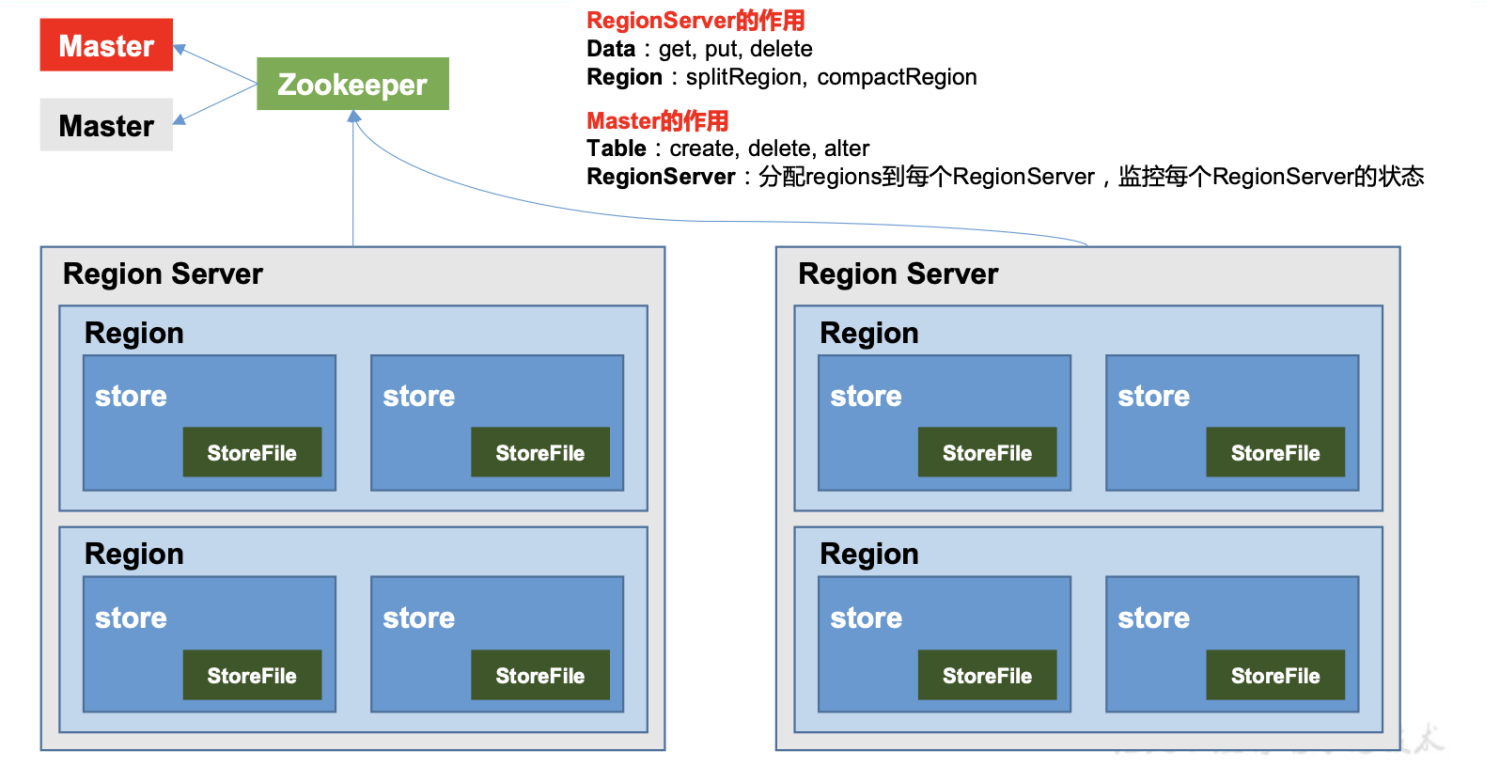
HBase是一个分布式系统,这点跟MySQL不同,它的数据是分散不同的server上,每个table由一个或多个region组成,region分散在集群中的server上,一个server可以负责多个region。
这里有一点需要特别注意:table中各个region的存放数据的rowkey(主键)范围是不会重叠的,可以认为region上数据基于rowkey全局有序,每个region负责它自己的那一部分的数据。
1.查询
查询操作是根据rowkey返回时间戳最大的数据。假如我们要查询rowkey=150的这条记录,首先从zk中获取hbase:meta表(存放region和key的对应关系的元数据表)的位置,通过查询meta表得知rowkey=150的数据在哪个server的哪个region上。
2.插入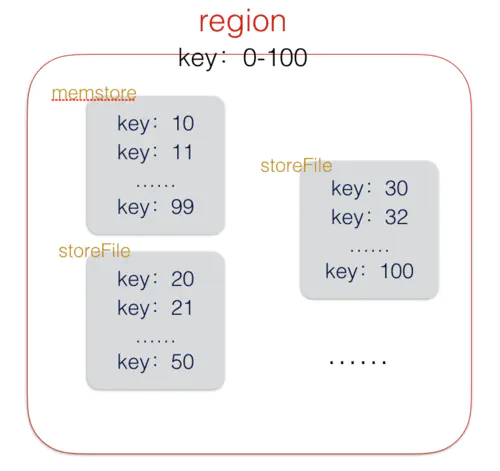
上图粗略的展示了HBase的region的结构,region不单单是一个文件,它是由一个memstore和多个storeFile组成(storeFile上的上限可以配置)。插入数据时首先将数据写入memstore,当memstore大小达到一定阈值,将memstore flush到硬盘,变成一个新的storeFile。flush的时候会对memstore中的数据进行排序,压缩等操作。可以看到单个storeFile中的数据是有序的,但是region中的storeFile间的数据不是全局有序的。
这样有的好处就是:不管主键是否连续,所有的插入一律变成顺序写,大大提高了写入性能。
看到这里大家可能会有一个疑问:这种写入方式导致了一条记录如果不是一次性插入,很可能分散在不同的storeFile中,那在该region上面查询一条记录时,怎么知道去找哪个storeFile呢?答案就是:全部查询。HBase会采用多路归并的方式,对该region上的所有storeFile进行查询,直到找到符合条件的记录。所以HBase的拥有很好的写入性能,但是读性能较差。
当然HBase也做了很多优化,比如每个storeFile都有自己的index、用于过滤的bloom filter、compaction:按可配置的方式将多个storeFile合并成一个,减少检索时打开的文件数。
3.更新 & 删除
修改操作其实是根据时间戳重新put一条数据。删除操作其实是PUT一条操作类型为DEL的数据。(当查询时发现该row key的最大时间戳记录操作类型为DEL,则不返回数据,给用户造成的感觉就是已删除该row key)。因此也造成数据冗余。
HBase将更新和删除也全部看做插入操作,用timestamp和delete marker来区分该记录是否是最新记录、是否需要删除。也正是因为这样,除了查询,其他的操作统一转换成了顺序写,保证了HBase高效的写性能。
架构不同
Mysql
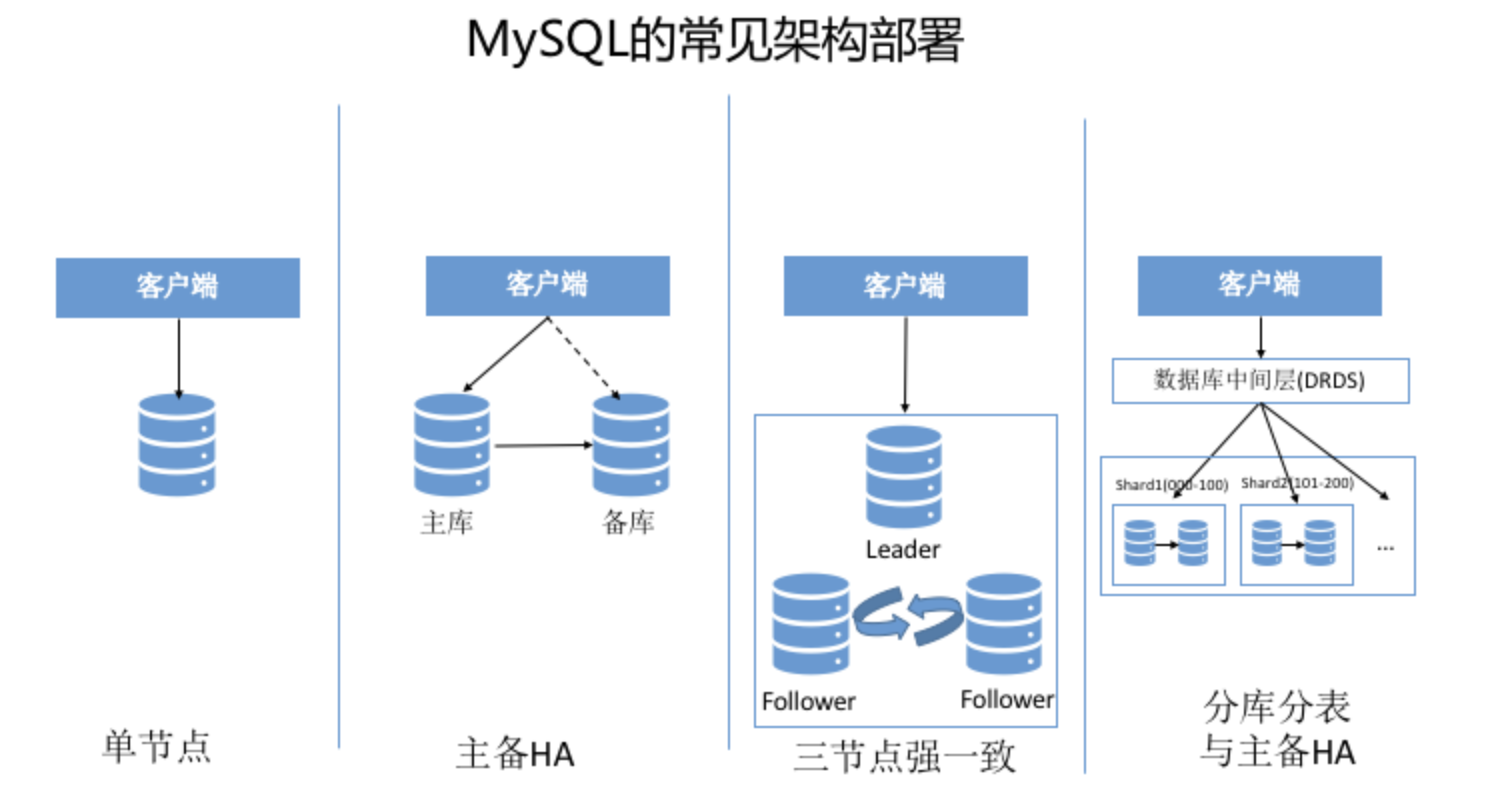
Hbase
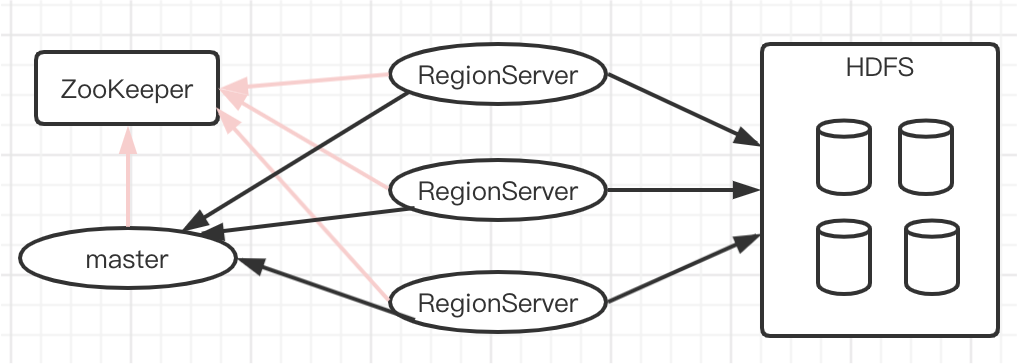
- 完全分布式(数据分片、故障自恢复)
- 底层使用 HDFS(存储计算分离)。
解决问题定位不同

MySQL解决应用的在线事务问题。
Hbase解决大数据场景的海量存储问题。
HBase 不是 MySQL 的替换,HBase 是业务规模及场景扩张后,对 MySQL 的自然延伸。
我是 小豪哥学编程,21年校招某科技公司SP,关注我,帮助你互联网少走弯路~!
欢迎老司机们补充和温故。
注:
本文部分内容参考自
https://www.jianshu.com/p/4e412f48e820
https://blog.csdn.net/JacksonKing/article/details/107617608

若有收获,就点个赞吧
0 人点赞
