- 先决条件">先决条件
- 第 1 步 - 安装 Java">第 1 步 - 安装 Java
- 第 2 步 – 下载最新的 Apache Kafka">第 2 步 – 下载最新的 Apache Kafka
- 第 3 步 – 创建 Systemd 文件">第 3 步 – 创建 Systemd 文件
- 第 4 步 – 启动 Kafka 和 Zookeeper 服务">第 4 步 – 启动 Kafka 和 Zookeeper 服务
- 第 5 步 – 在 Kafka 中创建主题">第 5 步 – 在 Kafka 中创建主题
- 第 6 步 – 使用 Kafka Producer 发送消息">第 6 步 – 使用 Kafka Producer 发送消息
- 第 7 步 – 使用 Kafka Consumer 接收消息">第 7 步 – 使用 Kafka Consumer 接收消息
先决条件
需要 sudo 特权帐户访问 Ubuntu 20.04 系统。第 1 步 - 安装 Java
Apache Kafka 可以在平台支持的任何 Java 上运行。 要在 Ubuntu 系统上设置 Kafka,首先需要安装 Java。我们在这里使用 OpenJDK 的开源版本。 安装 OpenJDK。检查当前活动的Java版本。
sudo apt updatesudo apt install default-jdk
java --versionopenjdk version "11.0.9.1" 2020-11-04OpenJDK Runtime Environment (build 11.0.9.1+1-Ubuntu-0ubuntu1.20.04)OpenJDK 64-Bit Server VM (build 11.0.9.1+1-Ubuntu-0ubuntu1.20.04, mixed mode, sharing)
第 2 步 – 下载最新的 Apache Kafka
从官方网站下载 Apache Kafka 的二进制文件。然后解压缩存档文件
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.8.1/kafka_2.13-2.8.1.tgz
tar xzf kafka_2.13-2.8.1.tgzmv kafka_2.13-2.8.1 /usr/local/kafka
第 3 步 – 创建 Systemd 文件
接下来,需要为 Zookeeper 和 Kafka 服务创建一个 systemd 单元文件,这里我们通过 Systemd 启动/停止 Zookeeper 和 Kafka 服务。 首先,创建一个 Zookeeper systemd 单位文件。然后添加以下内容,保存并关闭文件。
vim /etc/systemd/system/zookeeper.service
接下来,为 Kafka 服务创建一个 systemd 单位文件:
[Unit]Description=Apache Zookeeper serverDocumentation=https://zookeeper.apache.orgRequires=network.target remote-fs.targetAfter=network.target remote-fs.target[Service]Type=simpleExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.propertiesExecStop=/usr/local/kafka/bin/zookeeper-server-stop.shRestart=on-abnormal[Install]WantedBy=multi-user.target
请添加以下内容,保存并关闭文件。确保设置的 JAVA_HOME 为系统上安装的 Java 路径。
vim /etc/systemd/system/kafka.service
重新加载 systemd 守护程序以加载新创建的 systemd 单位文件。
[Unit]Description=Apache Kafka ServerDocumentation=https://kafka.apache.org/documentation.htmlRequires=zookeeper.service[Service]Type=simpleEnvironment="JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64"ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.propertiesExecStop=/usr/local/kafka/bin/kafka-server-stop.sh[Install]WantedBy=multi-user.target
systemctl daemon-reload
第 4 步 – 启动 Kafka 和 Zookeeper 服务
首先,需要启动 ZooKeeper 服务,然后再启动Kafka。 使用 systemctl 命令启动单节点 ZooKeeper 实例。然后启动 Kafka 服务器并查看执行状态。
sudo systemctl start zookeeper
此时 Kafka 已经安装成功。下面将介绍如何使用 Kafka 服务器。
sudo systemctl start kafkasudo systemctl status kafka
第 5 步 – 在 Kafka 中创建主题
Kafka 提供了多个预构建的 Shell 脚本来处理它。首先,在具有单个副本的单个分区上创建一个名为“ testTopic”的主题。复制因子指示创建的数据的副本数。将此值保留为1,因为 Kafka 正在单个实例上运行。 将分区选项设置为要对数据进行分区的代理数。将此值保持为 1,因为正在单个代理上运行。 你可以运行与上述相同的命令来创建多个主题。之后,你可以通过执行以下命令来检查 Kafka 创建的主题。
cd /usr/local/kafkabin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopicCreated topic testTopic.
或者,你可以配置代理以在发布不存在的主题时自动创建主题,而不是手动创建主题。
bin/kafka-topics.sh --zookeeper localhost:2181 --list[output]testTopic
第 6 步 – 使用 Kafka Producer 发送消息
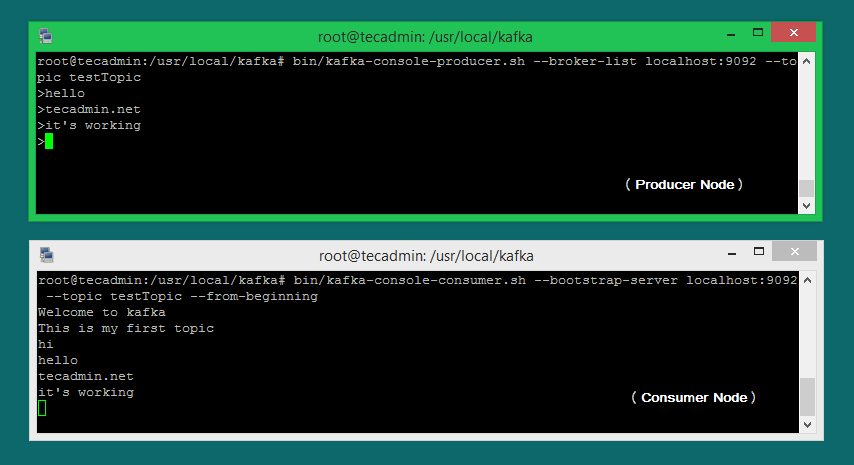
“生产者”是将数据输入 Kafka 的过程。 Kafka 带有命令行客户端,该客户端从文件或标准输入中获取输入,并将其作为消息发送到 Kafka 集群。默认的 Kafka 将每一行作为单独的消息发送。 让我们运行生产者,然后在控制台中键入一些消息以将它们发送到服务器。你可以退出此命令或让此终端运行以进行进一步测试。下一步是为 Kafka 消费者流程,打开一个新终端。
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic>Welcome to kafka>This is my first topic>
第 7 步 – 使用 Kafka Consumer 接收消息
Kafka 还有一个命令行使用者,它从 Kafka 集群中读取数据并将消息打印到标准输出。现在,如果你仍在另一台设备上运行 Kafka Producer(第 6 步)。你所要做的就是在该生产者的设备上输入文本。它会立即显示在消费者终端上。请在下面查看 Kafka 生产者和消费者的屏幕截图。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic testTopicWelcome to kafkaThis is my first topic
参考怎样在Ubuntu 20.04上安装Apache Kafka
Kafka 的使用可以参考下面的文章:

若有收获,就点个赞吧
0 人点赞
