Lab 1 Util
Boot xv6
按照指导从仓库git clone代码,然后在运行
make qemu
启动xv6。
sleep
按照提示,理解如何获取传给程序的命令行参数,调用sleep系统调用。
显然,输入的第二个命令行参数为sleep系统调用的参数,所以使用atoi()将字符串转化为数字,为暂停的时钟节拍。
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int
main(int argc, char *argv[])
{
if(argc != 2){
fprintf(2, "Usage: sleep error...\n");
exit(1);
}
sleep(atoi(argv[1]));
exit(0);
}
pingpong
题意可知,使用管道来进行父进程与子进程之间的”ping-pong“。关于管道的知识点,除了xv6book的1.3外,还可以参考pipe()系统调用。
父进程要向子进程发送一个字节,所以当fork()!=0时,进入父进程,先写入一个字节,通过管道,子进程可以读取该字节,并在管道中写入字节发送给父进程,然后退出。在父进程中,wait(0)等待子进程的退出,然后读取管道中子进程写入的字节。其中,close()函数用于关闭管道的读取端或者写入端。
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int
main(int argc, char *argv[])
{
int pid;
int p[2];
char buf[2];
if(argc > 1)
{
fprintf(2, "Usage: pingpong error...\n");
exit(1);
}
pipe(p);
if(fork() == 0) //child
{
pid = getpid();
if(read(p[0], buf, 1) != 1)
{
fprintf(2, "Failed to read in child\n");
exit(1);
}
close(p[0]);
printf("%d: received ping\n", pid);
if(write(p[1], buf, 1) != 1)
{
fprintf(2, "Failed to write in child\n");
exit(1);
}
close(p[1]);
}
else // parent
{
pid = getpid();
if(write(p[1], buf, 1) != 1)
{
fprintf(2, "Failed to write in parent\n");
exit(1);
}
close(p[1]);
wait(0);
if(read(p[0], buf, 1) != 1)
{
fprintf(2, "Failed to read in parent\n");
exit(1);
}
printf("%d: received pong\n", pid);
close(p[0]);
}
exit(0);
}
primes
本题需要用管道来编写一个素数筛的并发版本。下面的代码和图片是对于这个方法的解释,源于这篇文章。此外,这里有一篇关于素数筛法介绍的文章。
p = get a number from left neighbor
print p
loop:
n = get a number from left neighbor
if (p does not divide n)
send n to right neighbor
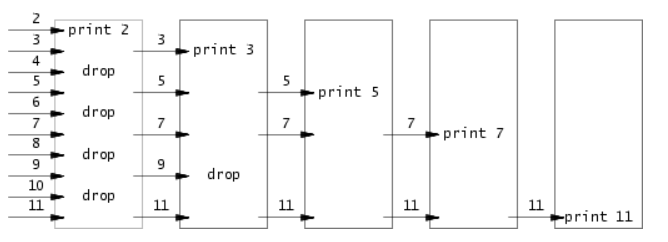
通过题意和提示,我们知道第一个进程会将数字2到35输入管道之中,然后在子进程中,会实现素数筛的过程,可以创建一个child_process函数作为子进程的操作。
根据上图和伪代码的解释,我们可以使用read在管道中读取左邻居的数,将这个数输出。由pipe()系统调用中我们可以知道,管道的行为类似于队列,为FIFO先进先出,所以第一个读取到的数为2,必为prime。由素数筛法可知,我们可以去掉所有被2整除的数,于是,读取的数如果被2整除就不写入孙子进程的管道。
周而复始,我们可以得到正确的答案,当写入管道关闭时,read返回零,循环结束。在这个过程中,及时close,防止系统资源不足。
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
void
child_process(int p[2])
{
int n;
int pp[2];
int prime;
close(p[1]);
if(read(p[0], &prime, 4) != 4)
{
fprintf(2, "Failed to read prime\n");
exit(1);
}
printf("prime %d\n", prime);
if(read(p[0], &n, 4))
{
pipe(pp);
if(fork() == 0)
{
child_process(pp);
}
else
{
do
{
if(n % prime) write(pp[1], &n, 4);
}
while(read(p[0], &n, 4));
close(p[0]);
close(pp[1]);
}
}
wait(0);
exit(0);
}
int
main(int argc, char *argv[])
{
int p[2];
if(argc > 1)
{
fprintf(2, "Usage: primes error...\n");
exit(1);
}
pipe(p);
if(fork() == 0) // child
{
child_process(p);
}
else // parent
{
close(p[0]);
for(int i=2; i<=35; i++)
{
write(p[1], &i, 4);
}
close(p[1]);
}
wait(0);
exit(0);
}
find
该题参照ls.c进行修改,得到相应的功能。
对于fmtname函数,我们看到ls中实现的功能有包括后面的一串空格,而在find中我们并不需要,于是删掉与生成一串空格相关的代码,直接返回p。
在find函数主体中,与ls函数主题框架相比变化不大,在switch中,如果st.type类型为文件,修改为如果输入参数得到的文件名与目标文件名对应,则输出。如果是文件夹,在文件夹中做与ls一样的处理,不一样的是,递归find,在子文件夹中寻找,注意,不要在”.”和”..”中递归,于是加入判定条件。
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
char*
fmtname(char *path)
{
char *p;
// Find first character after last slash.
for(p=path+strlen(path); p >= path && *p != '/'; p--)
;
p++;
return p;
}
void find(char *path, char *file)
{
char buf[512], *p;
int fd;
struct dirent de;
struct stat st;
if((fd = open(path, 0)) < 0){
fprintf(2, "find: cannot open %s\n", path);
return;
}
if(fstat(fd, &st) < 0){
fprintf(2, "find: cannot stat %s\n", path);
close(fd);
return;
}
switch(st.type){
case T_FILE:
if(strcmp(fmtname(path), file) == 0)
printf("%s\n", path);
break;
case T_DIR:
if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf){
printf("find: path too long\n");
break;
}
strcpy(buf, path);
p = buf+strlen(buf);
*p++ = '/';
while(read(fd, &de, sizeof(de)) == sizeof(de)){
if(de.inum == 0)
continue;
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0;
if(stat(buf, &st) < 0){
printf("find: cannot stat %s\n", buf);
continue;
}
if(!strcmp(de.name, ".") || !strcmp(de.name, "..")) continue;
find(buf, file);
}
break;
}
close(fd);
}
int
main(int argc, char *argv[])
{
if(argc != 3)
{
fprintf(2, "Usage: find error...\n");
exit(1);
}
find(argv[1], argv[2]);
exit(0);
}
xargs
这道题涉及到的知识点比较多,做起来并不是很清晰,参考了几种思路,最后选择了比较好理解的一种。
首先,关于xargs指令,有几点要注意的。我们可以看到例子中的
$ echo hello too | xargs echo bye
bye hello too
展示了xargs的功能,在这里,涉及到一个管道符“|”的知识。
对于管道符
Command A | Command B
将命令A的输出作为命令B的输入。于是这里又涉及到了标准化输入和标准化输出的内容,而在题目描述中也提及了标准化输入。查阅xv6 Book,可以知道标准化输入的文件描述符(file descriptor)为0。
下面是三个核心问题:
- 怎么获取前一个命令的标准化输出(此命令的标准化输入)?
- 如何获取自己的命令行参数?
- 如何使用exec执行命令?
建立一个xargv指针数组,用于储存相应的命令行参数。接着,对标准化输入进行读取,并循环至文件结束。指针b在数组buf中进行操作,如果对应的数组元素为’\n’则fork,且要将该元素置为0。在子进程中,调用exec,在第一个命令行参数中,知道要执行的文件。在父进程中,等待子进程的完成。
补充:在make grade跑分时发现,将元素置为0时要注意要在fork之前。
#include "kernel/types.h"
#include "user/user.h"
#include "kernel/param.h"
int
main(int argc, char *argv[])
{
char buf[MAXARG];
char *xargv[MAXARG];
char *b = buf;
int n;
int xargc = argc - 1;
if(argc <= 1)
{
fprintf(2, "Usage:xargs error...\n");
exit(1);
}
for(int i=1; i<argc; i++)
{
xargv[i-1] = argv[i];
}
while((n = read(0, b, 1)) > 0)
{
if(*b == '\n')
{
*b = 0;
if(fork() == 0)
{
xargv[xargc] = buf;
exec(xargv[0], xargv);
exit(0);
}
else
{
wait(0);
}
b = buf;
}
else
{
++b;
}
}
exit(0);
}

若有收获,就点个赞吧
0 人点赞
