引子
之前一篇文章我们大致介绍了StarlingX的平台架构和部署架构。从底层操作系统和基础组件来看,starlingX很大程度上复用了当前主流的一些开源技术,并根据starlingX项目需求做了集成和性能优化,相关内容大家可以自行搜索相关技术介绍,所以这一篇文章我们将跳过这部分内容直接进入到starlingX本身的平台服务进行详细介绍。
StarlingX平台服务

StarlingX平台服务包含配置管理、故障管理、主机管理、服务管理、软件管理五个部分。
Configuration Management - 配置管理
StarlingX配置管理服务(CM)通过统一的管理入口(CLI、Web界面),实现远端边缘节点的自动发现和自动配置功能,从而降低边缘计算分布式节点的管理复杂度。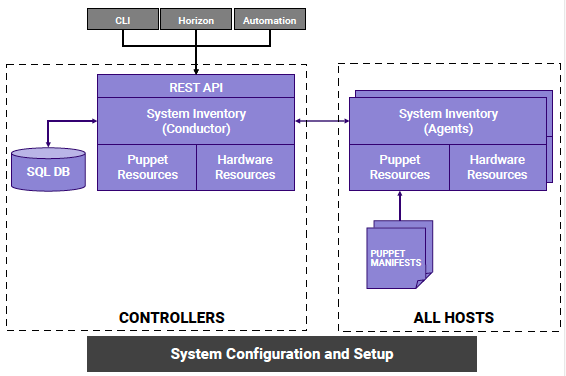
配置管理服务主要提供如下功能:
- 节点安装管理
- 自动发现新加入主机节点。
- 安装参数管理(console输出、根硬盘等参数)
- 批量配置文件分发和激活
- 节点配置管理
- 节点角色、角色配置
- 系统配置(CPU Pin、内存大页、网络端口、硬盘分配等)
StarlingX控制节点一般采用HA实现高可用,所以会有controler-0和controller-1两个阶段。controller-0节点需要管理员手动下载StarlingX安装镜像文件并制作启动U盘,通过U盘安装系统并完成相关配置。然后,在安装controller-1的时候,就可以通过配置管理服务实现节点的自动发现和自动配置。
- 启动controller-1节点后,通过在controller-0上输入system host-list命令即可发现新发现的节点(hostname为None的节点)

- 基于主机id配置角色属性为”controller”

其他节点角色属性包括”worker”: 工作节点、”storage”: 存储节点。
- 当节点被配置属性后,系统自动将预定义的配置文件复制至对应节点并完成配置。

Host Management - 主机管理
主机管理实现基于标准REST API接口对物理主机的生命周期管理,提供“供应商中立”的工具对主机进行监控和告警,并实现对故障的检测和自动恢复。
主机管理主要实现如下功能:
- 主机的全生命周期管理(加入集群、山区、上线等)
- 通过和基板管理控制器(Board Management Controller,BMC)交互,实现对主机的带外管理,如重启、开机、关机、硬件传感器监控等功能。
- 实现对集群内连通性、CPU处理器、物理资源利用率、网卡接口状态、硬件故障、物理传感器等信息进行监控和告警。
- 检测并识别主机故障,并触发自动恢复。
StarlingX主机有locked、unlocked两种管理状态(Administrative State):
- locked:主机在管理面上被设置不提供服务能力。
- 控制节点在locked状态不被作为HA节点,且不运行任何控制服务。
- 工作节点在locked状态下不运行任何用户应用实例,且不会被调度新的用户应用实例。
- unlocked:主机在管理面上被设置提供服务能力。
- 控制节点在unlocked状态(非failed),将处于HA模式,并运行分配的控制面服务。
- 工作节点在unlocked状态(非failed),可以提供用户业务实例运行和调度能力。
当用户执行lock操作会自动触发当前节点上的控制服务实例或用户应用实例迁移至其他可用节点,且进入locked状态方便管理云做运维操作;执行unlock操作会自动重启主机并重新读取主机配置。
StarlingX主机还有enabled、disabled两种操作状态(Operational State):
- enabled:表示主机能按预设想的能力对外提供服务。
- disabled:表示主机不能按预设想的能力对外提供服务。
同时,主机在生命周期中还有如下可用性状态(Availability State):
- Offline(离线状态):一个新主机刚加入集群,默认状态为离线(除controller-0外),此时平台还不能对主机做管理操作。
- Online(在线状态):表示主机的IP地址网络可达,且已经和控制节点建立管理链路会话。
- InTest(自检状态):临时状态,此状态下的主机正在对主机硬件和软件做自检。
- Available(可用状态):表示主机可以正常对外提供服务。
- Degrade(降级状态):表示主机存在一些操作限制,但是当前还能正常提供预期的服务。
- Failed(失败状态):主机运行存在问题,需要重新自检及修复,可能需要管理员人工介入帮助修复。

主机在可用性状态间的转换:
- Offiline -> Online:
- 当主机和控制节点管理链路会话时,状态更新为在线状态。
- 当管理链路会话建立超时,状态更新为失败状态。
- Online -> Offline:
- 当管理链路会话断开时(关机或重启),状态更新为离线状态。
- 用户Unlock操作会触发主机重启重新加载配置,状态更新为离线状态。
- Online -> InTest
- 临时状态,管理云执行Unlocked操作后主机自检(主机功能、主机服务完整性和可用性检测等)。
- Intest -> Available, Degraded, Failed
- 主机基于自检结果分别进入不同状态。
- Failed -> InTest
- 增强的高可用设计,基于故障触发自动恢复
- Available <-> Degraded, Available -> Falied, Degraded -> Failed
- 可用由Operational State变更或主机故障导致状态更新
- 状态更新会触发当前运行实例迁移
- Available, Degraded, Failed -> Offline
- 当主机管理链路断开或意外宕机
- 会自动在其他可用节点恢复用户应用实例
Service Management - 服务管理
服务管理(SM)实现对StarlingX平台的集群服务和基础服务管理能力,并基于冗余部署模型(N+M主备或N活)实现HA高可用。
服务管理主要实现如下功能:
- 服务生命周期管理及监控(主动监控或被动监控)
- 链路高可用,防止网络故障导致脑裂
- 支持最多3条网络通信链路
- 支持LAG链路聚合
- 支持HMAC SHA-512通信加密
- 支持服务高可用
- 支持N+M主备(如控制服务支持1+1主备)
- 支持N活
服务管理提供HA高可用和StarlingX的部署方式有很大相关,我们会在后续介绍starlingX的几种部署方式的时候再来看看其HA能力。
Fault Management - 故障管理
故障管理(FM)实现对物理资源(主机)、虚拟资源(虚机、网络)等实现告警和日志管理能力,并提供用户WebUI、CLI命令行等实现告警查询和操作。
故障管理主要实现如下功能:
- 支持操作告警和操作日志
- 平台节点和资源告警和操作日志
- 虚拟化资源告警和操作日志
- 告警配置和清除操作日志
- 提供基础设施服务告警管理的API
- 支持自定义告警(设置、查询和清除)。
- 支持自定义事件(Events)生成日志。
- 支持REST API用于告警和事件查询。
- 支持SNMP协议生成告警。
- 提供告警清单查询
- 支持告警抑制(单位时间重复告警、无关联操作告警)
告警管理(FM)定义了C(Critical)、M(Major)、m(Minor)、W(Warning)四个告警级别,可以对应不同的告警紧急度。如下图所示,当平台CPU使用率超过90%会触发MAJOR的100.101告警,超过95%则会进一步触发CRITICAL告警。
故障告警对告警的类型也进行了分类,具体如下:
- 100 系列:CPU/内存/网口/文件系统/NTP等告警
- 200 系列:网络连接/系统服务等告警
- 300 系列:数据端口告警
- 400 系列:license告警
- 500 系列:认证相关告警
- 750 系列:应用管理告警
- 800 系列:存储告警
- 900 系列:升级告警
Software Management - 软件管理
软件管理功能提供StarlingX系统所有组件统一的升级管理机制,支持多节点并发滚动升级,且会自动在线迁移被升级节点上的工作实例保证业务连续性。
软件管理实现如下功能:
- 自动部署系统各组件的升级软件包、安全补丁包以及新功能软件包。
- 主机操作系统升级软件包。
- StarlingX服务升级软件包、新功能软件包。
- OpenStack升级软件包、新功能软件包。
- 支持滚动升级
- 自动化升级简化管理员操作。
- 如需离线升级,自动在线迁移工作实例。
软件管理自动升级一般遵循如下步骤:
- 升级版本的依赖管理和检查。
- 升级前的健康检查。
- 系统数据(配置文件、系统数据库等)、软件包、用户数据等自动备份。
- 切换主机状态至locked状态。
- 升级软件包,有些情况需要重启主机。
- 迁移配置和相关数据至新版本。
- 文件系统数据同步。
一般节点升级顺序如下:
- 先升级Controller-1,完成后通过swact命令切换controller-1为主服务。
- 后再升级Controller-0节点。
- 然后依次升级storage和worker节点。
Controller控制节点因为是1+1主备,所以分布升级不会影响业务;Storage存储节点依赖底层Ceph集群高可用架构,数据是多副本存储,升级也不会影响业务;Worker节点升级前需要将当前节点上的工作负荷热迁移至其他节点,各节点依次操作,也不会影响业务。这就实现StarlingX系统升级,尽可能不影响上层运行的用户业务。
StarlingX原本就是基于风河给运营商NFV部署的云基础平台演进的,所以我们看到其平台服务能力很多都是关注在业务的高可用,以及运维管理简易型上,这样也符合紧要应用边缘部署依赖高可用、高可靠、安全的基础环境需求。我们在下一篇将继续介绍StarlingX的几种部署方式,从而满足不同边缘位置和规模的业务需求。

若有收获,就点个赞吧
0 人点赞
