- #问答与讨论
- 1.请问一下,在同一个context里面一个应用服务调另外一个领域服务,在进程里调用好还是实现client去调接口好一点呀,还是说跨context才用client
- 2.关于单元测试的这个问题,各位大佬,这个问题怎么看?
- 3.各位大佬,请求下。现在关于软件质量的度量,有哪些权威书籍? 现在在中台化的过程中,发现,如果只泛泛地说“高内聚、低耦合“的话,很容易空空地聊,沟通效率低,推进效率也低。
- 4.用于事件风暴分析的web在线工具有没有
- 5.OrderRepository 对应聚合根OrderAggregate,OrderAggregate下面有Order和OrderItem两个对应的表那么在OrderRepository Add方法中是否是dbContext.Add(order);for(…orderItem…)dbContext.Add(orderItem);
- 6.请教大家个问题,这登录算领域逻辑吗?
- 7.请教个问题:在拼团业务中,“团”与“团员”,有不变性规则:1.一个团一个用户只能参团一次2.团最多只能N人,并且到N人后,团的状态扭转为”满团“第一种设计方式:“团”是聚合根有List<团员>的实体集合,在这种设计方式下,存储层容易出现性能问题,如果N=100那么就是个大聚合;第二种设计方式:“团”是聚合根,“团员”也升级为聚合根,那么不变性规则,可能需要通过领域服务这里来做;这两种方式,怎么取舍?或者说设计上的错误什么场景下聚合内有实体集合?订单与订单项,如果订单频繁修改(虽然不可能),订单项没有数量限制,那么不也是个大聚合?这里有什么指引吗?
- 8.请问事务你们是在应用层还是领域层处理啊,如果在领域层一个应用服务需要多个领域服务时如何保障事务一致的呀。
第3&4周
2020年01月27日 - 2020年02月09日
编辑|子鱼
#问答与讨论
1.请问一下,在同一个context里面一个应用服务调另外一个领域服务,在进程里调用好还是实现client去调接口好一点呀,还是说跨context才用client
[Diven]
DDD倚天剑 [2019-01-31]
➤ 问题解答
[lyning] 是的,同一个上下文内,应用服务 调用 领域服务,很正常呀
[Diven] 也就是说拆开之后再把对应的领域服务换成client就可以了,之前在纠结耦合 和拆分的问题 绕晕了,
[lyning] 拆成两个服务之后,服务提供方 需要提供接口(RESTFul API or RPC),服务消费方 使用 client 去调用 服务提供方 提供的接口
2.关于单元测试的这个问题,各位大佬,这个问题怎么看?

[王喜春]
DDD倚天剑 [2019-02-09]
➤ 问题解答
[wuhthomas] 我觉得是整个团队要整体接受这个中开发方式困难,缺乏单元测试只是其中的一部分。
[秋叶1片] 我观察我的团队,缺乏单元测试的原因是根本不会拆分单元。换句话说,根本不懂面向对象,完全没有抽象能力。
[王喜春] 用着面向对象的语言,写着面向过程的代码
[东风如雨] 我觉得大部分原因是懒吧,面向过程感觉也可以单元测试
[Jeff - 王继] 不写单元测试的原因是很多的,经验、时间、开发模式、认知、自动化需求、开发文化、版本控制、成本……等等都影响测试案例,不是面向对象或抽象能力这么简单。
总的来讲,越倾向快速迭代,一次性消费方式的开发,越不注重测试案例;而越有经验,时间和开发成本投入较多的长期项目,也越重视测试案例。
[Qiao Liang] 什么是一次性消费?
[Jeff - 王继] 就是不打算或没有认真考虑迭代式重构的软件。,互联网速度决定论下很多软件都属于这一类。
[Qiao Liang] 那个软件只发布一个版本
只有一个版本,算一次性吧
“用了一次就丢”算一次性
这么理解对么?有专职测试人员的存在,写不写自动化都行
反正有人测,又不用自己测
当你认为应该有自动化测试的时候,已经没那个时间写了~最好的办法是推翻重来~推翻重来的时候,你判断还是不需要自动化测试
所以还是没有自动化测试
[张晓龙] 单元测试并不只是事后验证,更重要的是对设计的驱动,驱动出更好的代码结构和API设计,更强的表达力和更少的设计元素
[秋叶1片] 「东风如雨:
我觉得大部分原因是懒吧,面向过程感觉也可以单元测试」
- - - - - - - - - - - - - - -
低内聚,高耦合,一个方法几百行,一个class上万行。怎么写单元测试?
[腾云] 我从不测试驱动,但是我一定会写测试
[Qiao Liang] 我认为我们是在讨论写不写自动化测试用例
没有讨论写多少和是不是TDD方式写
[无] 大多数情况光有单元测试不够,还得有其他测试(如api测试)才能自动代替人工。但写这类测试所花费的成本也会相对较高,所以是否自动化,可能也得看是否值得。我觉得是这样。
[腾云] 我认为我是在回应张晓龙老师的观点
[王喜春] “Qiao Liang: 当你认为应该有自动化测试的时候,已经没那个时间写了~最好的办法是推翻重来~推翻重来的时候,你判断还是不需要自动化测试”
- - - - - - - - - - - - - - -
同感。
现在投资驱动的开发氛围下, 单元测试是团队和个人不容易出业绩的地方, 长期维护花费的精力和时间, 远不如“一次性消费”地做一个项目搞的动静大、升职加薪的幅度大。
[王答] 
追求单元测试覆盖率100%也是挺坑人的。
[一凡] 坑在哪里?
[王答] 坑在100%
你看TDD的提出者都不100%的单元测试
[LenFon] 覆盖率 80%以上就差不多了
[王答] 如果不100%的做单元测试,单元测试根本就不会影响开发速度,反而会提高开发速度
我感觉,首先把核心逻辑用单元测试覆盖到。然后剩下的就是哪里自己不放心,哪里就做单元测试就行了。
[一凡] 也就说定在80%就OK了,对吗?
[王答]  如果对代码质量没有自信,就80%呗。如果有自信,50%也行吧
如果对代码质量没有自信,就80%呗。如果有自信,50%也行吧
我截图中的肉容可是Kent Beck说的,他可是TDD和XP的老祖宗。
[一凡] 先走走看吧,100、80、50都可以,哪怕20都可以。就怕你到时候说10都有坑
[王答] 有一次我给团队培训单元测试,有个问题就是,对于private方法怎么做单元测试,我给的建议是,把private的方法改为 package级别或public级别。
有人问说这样是不是就破坏了封装,不面向对象了,我回复他的是:现在大部分人的代码,就算不改为public,也不怎么面向对象
[lyning] Kent Beck 写的 TDD 那本书(记得是2003年)也是这么说的,不过练习的时候,就应该追求100%
[翔子] 分布式项目中单项目领域上下文中可以追求TDD 集成测试的时候 还是利用一下自动化接口测试
我个人认为测试驱动很有必要的
[lyning] 聊tdd一般不是聊覆盖率,这是团队内部的目标,一般是聊用tdd解决什么问题,如果不是出于解决问题的,那覆盖率没用,因为覆盖率可以造假
[翔子] TDD我的理解是保证质量的一种有效的手段,在复杂度比较高的项目中,好处是显而易见的。空谈任何东西都是没有意义的,而且 讨论东西的时候都应该有相应的上下文才合理
[张晓龙] 产品生命周期越长,特性越多越复杂,数千人协作,对可靠性低时延要求很高,这样的情况越应该做好设计和自动化测试,因为成本收益比高
[Jeff - 王继] 谁说覆盖率没用?我的天……覆盖率的计算方法可以讨论,但是绝对覆盖率是一个硬指标
[翔子] 黑盒测试的用例其实也是一种覆盖率 只不过不是代码而已,覆盖率肯定是很重要的
[Jeff - 王继] 黑盒测试不是单元测试
[翔子] 是 但是 我理解他也是一种覆盖率
[LenFon] 黑盒测试 统计不到代码覆盖率
[Jeff - 王继] 和覆盖率不是一个话题
[LenFon] 黑盒测试 看的是功能覆盖
[翔子] 恩 不是一个级别的
[Jeff - 王继] Kent beck的“自信”和我们的“自信”不是一个级别的,我们还是不要乱吃药的好。
老老实实做好单元测试和覆盖率,这是学走路的基础。
一次性代码可以少些单元测试,主要是从成本角度,因为软件质量三角不追求面面具到,在一定范围内用人工测试来弥补单元测试,赢得开发时间的缩短,取得效益最大化。
[LenFon] 「Jeff - 王继:黑盒测试不是单元测试」
- - - - - - - - - - - - - - -
这个好像也不完全对,我们之前培训cmmi的时候,讲师有提到过 程序员编写测试,由测试员执行,他说可以是黑盒测试
[Jeff - 王继] 但是长期项目,有继承性的迭代项目,时间投入本来就很长,成本累加也随着时间的推移而指数型上升,前期成本的回报率在总成本计算中并不明显,因此单元测试才显得重要
@LenFon 单元测试的第一责任人是开发者自己
[LenFon] 我只是说明下 单元测试 不一定都是白盒测试
[王喜春] “Jeff - 王继: Kent beck的“自信”和我们的“自信”不是一个级别的,我们还是不要乱吃药的好。”
- - - - - - - - - - - - - - -
同感。
在当前的开发氛围中, 如果每个人都按自己的“自信”来单测的话, 就是现在的样子,几乎没有可发生实际作用的单测,也就是更谈不上对重构的保护了。
单元测试写的完善就不需要测试人员来执行此项任务。
单元测试够完善是自动化的前提,测试人员可以专注黑盒测试
[alex] tdd是设计方法,是要覆盖需求的
[Jeff - 王继] 「王答:有一次我给团队培训单元测试,有个问题就是,对于private方法怎么做单元测试,我给的建议是,把private的方法改为 package级别或public级别。
有人问说这样是不是就破坏了封装,不面向对象了,我回复他的是:现在大部分人的代码,就算不改为public,也不怎么面向对象」
- - - - - - - - - - - - - - -
这个就是单元测试的认定方法问题,从public方法间接测试到private方法可以认为是“覆盖”了。我给你一个更典型的例子,ServiceA的方法调用了另一个ServiceB的public方法,那么是否可以认为ServiceB的public方法被覆盖了呢?只要你能保证ServiceB在整个系统中不会存在其它调用条件,那么可以不必为ServiceB编写单独的测试。
[王答] 「Jeff - 王继:
这个就是单元测试的认定方法问题,从public方法间接测试到private方法可以认为是“覆盖”了。我给你一个更典型的例子,ServiceA的方法调用了另一个ServiceB的public方法,那么是否可以认为ServiceB的public方法被覆盖了呢?只要你能保证ServiceB在整个系统中不会存在其它调用条件,那么可以不必为ServiceB编写单独的测试。」
- - - - - - - - - - - - - - -
理解你表达的意思。
我理解对ServiceA的测试,应该尽量不依赖ServiceB,对ServiceB应该Mock出来,相信ServiceB是完全正确的。ServiceB的正确性由ServiceB的单元测试来保证。
在实际的开发中,单元测试难做的一个原因就是过多的依赖,导致单元测试的编写难,容易失效,从而难以自动化测试。
public的方法如果所有测试用例全部通过,不用管private方法是否正确。
现在我经常面临的问题是,大家的代码写的并不好,有各种问题,要是想提高大家的代码(面向对象)能力是很难的。所以我倾向于是:大家保证自己写的每个函数都是对的,这样正确的函数组装在一起,就能尽小可能的出错了。
就像组装汽车,我想保证每个零件都是对的。
其实大部分程序员都是不合格的程序员,没啥追求,就是能把功能堆出来而已。
我反思自己时也感觉自己离工匠差得老远。
[alex] 从下到上的方法,很难得到最有结果
[王答] TDD是不是有点儿从下到上的意思?@alex
[alex] 不是
tdd是先写测试,是需求的一种描述方法
[王答] 但是需求到代码中间还有一个分析和设计的过程。
需求直接映射代码总感觉怪怪的还是思维方式没适应。
[Jeff - 王继] 「王答:「Jeff - 王继:
这个就是单元测试的认定方法问题,从public方法间接测试到private方法可以认为是“覆盖”了。我给你一个更典型的例子,ServiceA的方法调用了另一个ServiceB的public方法,那么是否可以认为ServiceB的public方法被覆盖了呢?只要你能保证ServiceB在整个系统中不会存在其它调用条件,那么可以不必为ServiceB编写单独的测试。」
- - - - - - - - - - - - - - -
理解你表达的意思。
我理解对ServiceA的测试,应该尽量不依赖ServiceB,对ServiceB应该Mock出来,相信ServiceB是完全正确的。ServiceB的正确性由ServiceB的单元测试来保证。
在实际的开发中,单元测试难做的一个原因就是过多的依赖,导致单元测试的编写难,容易失效,从而难以自动化测试。」
- - - - - - - - - - - - - - -
不是这个意思,ServiceA和ServiceB各自的独立性是另一个问题。我的意思是在这个问题得到解决的前提下,我们有没有必要为ServiceB单独编写测试案例。假设ServiceB在整个系统中不存在开放访问的可能性,并且它的所有客户端都被覆盖,那么不管它和它的客户端之间存在多么必然的耦合性,我们可以认为ServiceB是安全的,也就没必要编写单独的测试案例。
是的TDD是先有测试案例,后有测试对象,但是这是理想情况,实际上也很难做到,一般来说是同步改进。除了这先后问题外,更大的问题是要习惯盲测,也就是说要依赖assert多过print
[张晓龙] 去年写的一个TDD相关的Chat,感兴趣的可以看看 https://gitbook.cn/m/mazi/article/5d667350cca96a09360e14e0?isLogArticle=no&readArticle=yes&sut=7a8a4f004afc11eab5d521713841d8b9
[鹏酱] 每个方法就做一件事,单元测试就好写了,且覆盖率会提升
[白色熊猫] 很多业务逻辑都是依赖数据库的时候,怎么办?很多企业内部的业务系统
[鹏酱] 那是业务逻辑和数据库读取耦合了,得解偶,也就是说一个方法中做了不止一件事,还有单元测试是不应该跨进程的,连接数据库就属于跨进程了,已盖楼为例,单元测试看做是每块砖,只要每块砖稳固了,然后集成测试正常流程过一遍就差不多了,你说的测试人员一般就是集成测试
3.各位大佬,请求下。现在关于软件质量的度量,有哪些权威书籍? 现在在中台化的过程中,发现,如果只泛泛地说“高内聚、低耦合“的话,很容易空空地聊,沟通效率低,推进效率也低。
[王喜春]
DDD倚天剑 [2019-02-09]
➤ 问题解答
[c@ini@o] devops圈认可的四大指标:前置时间、发布频率、线上修复等待时间、上线成功率
[王喜春] @c@ini@o 嗯,这个貌似是项目或需求角度看的指标,主要想从怎么达成的角度看下,就内部实现的度量指标
还是多多感谢
[c@ini@o] 达成这块我没有太好的建议,因为屁股决定脑袋,如果是自己的业务开发,那交付的核心是可用的软件为组织创造价值;如果是研发服务提供商,那就是客户给的成本和利润的平衡问题。
[Qiao Liang] 应该先定义“啥是软件质量”,就像“啥是开发效率”一样,根本没啥科学度量,变量太多,还都不是标准件生产
4.用于事件风暴分析的web在线工具有没有
[薄军]
DDD屠龙刀 [2019-02-05]
➤ 问题解答
[Simon] 事件风暴鼓励面对面讨论,用零 IT 门槛的即时贴来方便所有相关人共同记录事件和各种领域对象。如果用在线工具,就违背了事件风暴的初衷
[薄军] @Simon 嗯,我是想目前都远程上班的情况下,大家可以在线共享,类似腾讯共享文档编辑那个功能
[王敏] 冠毒在线,怎么面对面讨论?做事哪有这么多条条框框。
[Bill] https://miro.com/
5.OrderRepository 对应聚合根OrderAggregate,OrderAggregate下面有Order和OrderItem两个对应的表那么在OrderRepository Add方法中是否是dbContext.Add(order);for(…orderItem…)dbContext.Add(orderItem);
[吴林峰]
DDD屠龙刀 [2019-02-05]
➤ 问题解答
[随锋灬逐远方] Ef 的话就直接dbContext.Add(order);就可以了
[吴林峰] 不是ef
[随锋灬逐远方] order 和orderiten 建立关系
[吴林峰] 用原生的ado的说
[随锋灬逐远方] 不是的话就2个insert 语句
[JAMES🦁] 还要事务
[吴林峰] 那就是add(Order聚合根),然后分别解析这个聚合根下面有哪些需要分别插入的表,然后在调用这个仓储的地方提交事务
[随锋灬逐远方] 这种的我感觉没有必要用工作单元了,repository 直接改名为dao 还好理解一点
[吴林峰] 也是orm,只是不像ef那样的
[JAMES🦁] 不一样啊
[吴林峰] repository肯定要
[JAMES🦁] repository是做聚合的持久化,dao是对持久对象
[随锋灬逐远方] repository是不做持久化的,只是维护聚合的状态
[吴林峰]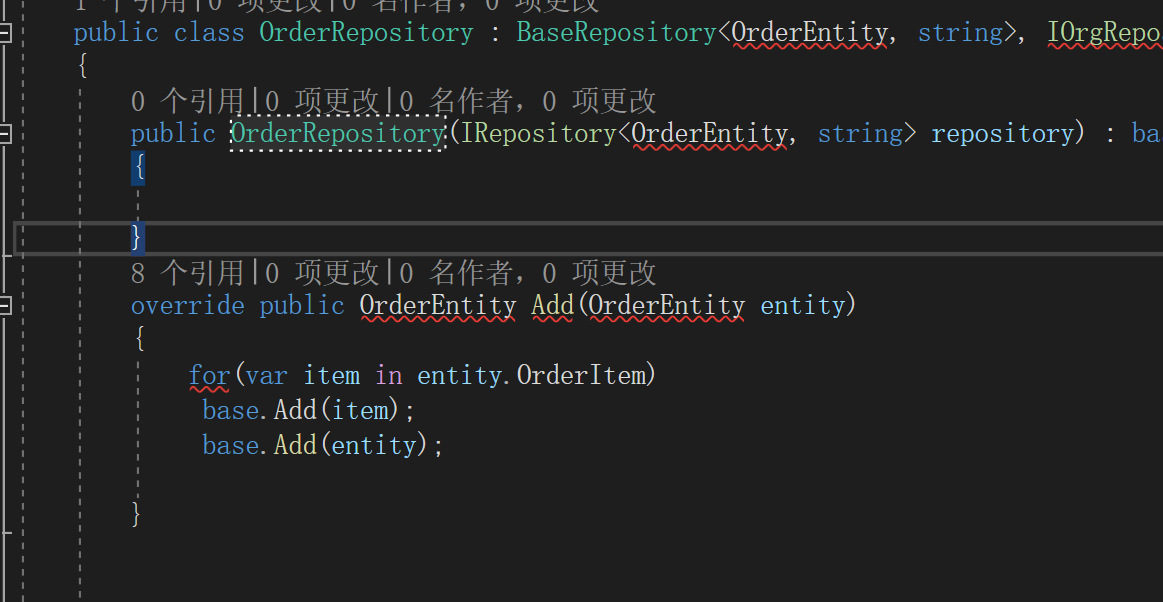
那我这个仓储中的add应该这样干,因为我这仓储是支持多个orm的
[Aries] 「峰:OrderRepository 对应聚合根OrderAggregate,
OrderAggregate下面有Order和OrderItem两个对应的表
那么在OrderRepository 的Add方法中是否是
dbContext.Add(order);
for(…orderItem…)
dbContext.Add(orderItem);」
- - - - - - - - - - - - - - -
这种情况不应该是在某层调用两add,一个add order 另一个add orderitem
[JAMES🦁] 「脑洞云-张维:这种情况不应该是在某层调用两add,一个add order 另一个add orderitem」
- - - - - - - - - - - - - - -
仓储内调用
[Aries] 事务放哪?
[吴林峰] @张维,因为order和orderitem都属同一个聚合根,一个仓储对应一个聚合根,所以order和orderitem的操作只能在同一个仓储中进行,我的理解
事务放在调用这个仓储的add前面有个工作单元,
仓储内调用是不用管事务的,事务是在调用仓储的时候管
[JAMES🦁] repository的add方法开启事务
[吴林峰] 这样要不得,因为调之前还要配合其它仓储,多个仓储之间肯定要工作单元统一开,统一提交
[Aries] 没错,按照你的那个场景order 和 order item是一个聚合根,在rep里面调用add order 和 add orderitem ,事实上也可以在别的层调用。
6.请教大家个问题,这登录算领域逻辑吗?
[熊瑞]
DDD少林派 [2019-02-02]
➤ 问题解答
[炙炙炙炙炙炙云深] 个人理解,微服务情况下,登录鉴权可以放在getway中做掉。然后对网关服务,可以把登录功能再抽象出界限上下文与聚合。
应用服务里的授权和认证,也不是领域服务,所以登录什么的,如果不涉及其他业务逻辑,只是单纯的登录、登出,可以这么认为,是基础设施的工作,对吧?
[ 炙炙炙炙炙炙云深] 具体要看你的子域划分吧。我的理解中基础设施层是没有业务逻辑的。如果是抽离登录鉴权到网关服务,那么它应该是作为一个子域存在的。在仓储接口写在领域层,实现写在基础设施的分层中,实际基础设施层做的是数据组装工作,而业务层实现具体业务。登录登出本身是用户域的一部分行为。放基础设施层有些割裂感
这些东西其实也看服务体量与业务变化,DDD如果是处理一些相对稳定的需求,其实并没有优势。。前期准备消耗人力[捂脸]
[熊瑞] 嗯嗯稳定可能代表的是简单的项目。
不是说简单就是体积小
7.请教个问题:在拼团业务中,“团”与“团员”,有不变性规则:1.一个团一个用户只能参团一次2.团最多只能N人,并且到N人后,团的状态扭转为”满团“第一种设计方式:“团”是聚合根有List<团员>的实体集合,在这种设计方式下,存储层容易出现性能问题,如果N=100那么就是个大聚合;第二种设计方式:“团”是聚合根,“团员”也升级为聚合根,那么不变性规则,可能需要通过领域服务这里来做;这两种方式,怎么取舍?或者说设计上的错误什么场景下聚合内有实体集合?订单与订单项,如果订单频繁修改(虽然不可能),订单项没有数量限制,那么不也是个大聚合?这里有什么指引吗?
[Zpl]
DDD少林派 [2019-02-02]
➤ 问题解答
[yanhua11:50这里的“团员”就是“参团”(名词)吧。感觉是两个聚合根合适
[yanhua11:50这个例子很好@Zpl[强]
[张逸11:53我觉得团是一个聚合,它的不变量就是:人数和状态。团聚合内的团员是自己聚合内的领域对象,团员另外有一个聚合。这就案例和微信群有些相似
[Zpl11:54“一个团一个用户只能参团一次”这个不变性规则,则要落到领域服务来实现?
[yanhua11:57你的语言里提到三个概念:用户,团,参团;我觉得是三个聚合。不变性在参团上维护
[小刀🤔🤔🤔12:00感觉可以落到团这个领域上上如果后期有变动可以抽离出来成为一个团的规则而这个规则就是策略集合
[张逸12:00这个问题确实还比较复杂。如果按照@yanhua的建议,由参团来维护“一个团一个用户只能参团一次”,同样也意味着由参团来维护满团状态。但状态自身其实是属于团的。
[张逸12:01先不考虑性能问题,合理的做法是由团来维护这两个不变性规则。
[yanhua12:02我最近在弄另一个案例,和这个很像。我觉得团是否满了(团的容量,和已参加人数决定)这个规则由团来维护。参团,维护一个用户一个团的规则。这两个聚合根之间需要通过Saga这样的事务管理机制来保障
[yanhua12:03这确实是一个很有争议的问题
[张逸12:04团里面会维护一个团员列表,故而可以在团的领域方法里维护“一个团一个用户只能参团一次”这个规则。至于性能,可以考虑在团聚合里维持的是自己的团员,只有一个团员Id信息需要管理生命周期。
[yanhua12:08我说一下我自己的案例,可能对大家有帮助。我们开始在做一个类似账户的应用。有个Account聚合根,账户是可以提现的,那一次提现(Withdral),也作为Account这个聚合的内部实体。这样的好处是,Account的余额、提现的规则限制等都可以在这个聚合根上维护。非常的RichDomain
[yanhua12:09但是,后来被性能问题挑战了
[yanhua12:09我现在的做法,是把Withdral变成了一个聚合根
[yanhua12:10但也会带来@Zpl这样的疑惑
[yanhua12:10我查了一些资料,可供大家讨论时参考[yanhua12:10https://blog.sapiensworks.com/post/2016/07/14/DDD-Aggregate-Decoded-1https://blog.sapiensworks.com/post/2016/07/14/DDD-Aggregate-Decoded-2
[张逸12:12设计原则还是要维护一个小聚合,如果小聚合无法满足不变性或一致性,可以考虑交给领域服务来完成。但这里的前提是不能因为引入了领域服务,而让聚合内的实体与值对象变得贫血
[yanhua12:12这个文章里讲了他们通过和领域专家对话后,怎么把Transfer(有点类似我说的例子里的提现的场景)定义为一个聚合根的
[yanhua12:13第二个我考虑的就是DDD里聚合根设计有一个原则“聚合根要小”
[yanhua12:15第三个可以从四色原型或以前“基础资料+单据”的设计思路出发,也偏向于这个结果
[yanhua12:17但是,这样做,又容易带来另外三个质疑1.本末倒置,是不是为了解决性能问题而想出的这么多理由呢?2.贫血,转了一圈又贫血了哈3.Withdral/Transfer和Account不属于同一个聚合,那不能共享同一个本地事务了,反而比以前更复杂了
[yanhua12:19我目前还没有清晰的结论,把思考和验证过程说出来,供大家参考
[Super12:20[大哭]我也不知道中间表实体应该跟哪边走,今天才知道你们是把它做成聚合根的
[yanhua12:21还没有结论
[yanhua12:23这个类型的例子,能有一个被广泛接受的实现方案,ddd落地的障碍会小很多
[林杰12:25优先业务,后技术吧。如果性能上确实有问题,也只能妥协了,目前好像还没有专为DDD做持久化的框架。
[右军12:27通过BC拆分服务,聚合内聚这些是大方向,具体如何做一考虑分析阶段的业务复杂度,二结合落地的技术方案。不要拘泥,看各种方案本身的优劣。比如以提现为例,基于账户出发没有错,但可能涉及的业务规则要看一下,有没有银行卡渠道维度的限制。提现是从A(内部account)到B外部渠道比如银行卡,如果这样看,可以类比体系内部的转账从A到B,那么转账是不是领域服务更合适呢?
[yanhua12:27现在的一个问题是,参团/团员作为一个独立的聚合根这是一个对性能的妥协?还是本来就应该是一个聚合根?
[yanhua12:29“但可能涉及的业务规则要看一下”[强]
[yanhua12:29有更多的业务输入可能问题就清晰了
[yanhua12:29右军12:33「Zpl:请教个问题:在拼团业务中,“团”与“团员”,有不变性规则:1.一个团一个用户只能参团一次2.团最多只能N人,并且到N人后,团的状态扭转为”满团“第一种设计方式:“团”是聚合根有List<团员>的实体集合,在这种设计方式下,存储层容易出现性能问题,如果N=100那么就是个大聚合;第二种设计方式:“团”是聚合根,“团员”也升级为聚合根,那么不变性规则,可能需要通过领域服务这里来做;这两种方式,怎么取舍?或者说设计上的错误什么场景下聚合内有实体集合?订单与订单项,如果订单频繁修改(虽然不可能),订单项没有数量限制,那么不也是个大聚合?这里有什么指引吗?」———————-个人觉得团和团员,可以没有聚合关系,一个团有多个团员,一个团员可以参加N个团,二者也没有生命周期的一致性问题,无非一个团有限额问题,这个限额放在团对象上管理就好。
[张逸12:34还要考虑,是否真正存在性能问题。坦白说,因为性能问题来改变领域模型,本身已经偏离了DDD的初衷。顺序应该是,在建模时不要考虑性能的影响,在建模后,可以根据技术因素对领域模型做一些调整,算是设计上的妥协
[yanhua12:35参团这个按第一种方式设计,确实有性能问题
[Zpl12:37@右军团员与用户,还是不同的。
[yanhua12:39我觉得你这个团员应该是“参团单”这个单据的一个值对象
[阿斌哥12:41性能问题在哪里?
[yanhua12:43“团”是聚合根有List<团员>的实体集合—-这个集合可能非常大。我遇到的一个场景,有1k左右吧
[右军12:44「Zpl:@右军团员与用户,还是不同的。」———————-新增团队在团的对象內
[Super12:45「Zpl:@右军团员与用户,还是不同的。」———————-是哦,团员应该是用户的集合,属于中间表
[yanhua12:45大家现在对“团员”这个概念的理解是不一样的
[yanhua12:45语言没统一
[Super12:47团员感觉可以理解成是人员(用户)之于团队
[Zpl12:47团员类似“订单项”这样的位置,只是不是ProductId而是UserId
[Zpl12:50@yanhua所以,我也理解为“实体”,而非“值对象”
[yanhua12:50用四色原型套一下“团员”是一个TTT还是Time-interval的?我感觉大部分人理解的是TTT,而@Zpl实际说的是一个Time-interval的。所以我一直说“参团”而不是“团员”
[Zpl12:51时标型对象?
[Super12:51「Zpl:团员类似“订单项”这样的位置,只是不是ProductId而是UserId」———————-对啊本质上他们是一样的但是为什么团员可以是聚合根是因为它的数量可能比较多吗
[yanhua12:51@Zpl你说的确实应该是实体,是一张“单据”,我是说这张单据里有个值对象“团员”,对应的是用户
[阿斌哥12:53团员就是一个用户ID而已吧,能占多少内存
[炙炙炙炙炙炙云深12:53我的理解,首先团员其实是属于用户,而用户信息(比如用户名)其实是可能不在团这个聚合内变动的。
[炙炙炙炙炙炙云深12:55并不是说团员是一个独立聚合,而是用户本身是一个聚合,当然如果你要存快照,可以存储为一份值对象,但这样后续团员相关数据一致性就得不到保障
[Zpl12:55团员会快照一些“用户”的状态,比如所属“部门”,“团队”,当时的状态。就好像订单项会快照商品的价格,作为凭据。
[Zpl12:56这只是举例,快照信息确实有。
[Super12:56「炙炙炙炙炙炙云深:我的理解,首先团员其实是属于用户,而用户信息(比如用户名)其实是可能不在团这个聚合内变动的。」———————-我觉得团员应属于团队[发抖]
[炙炙炙炙炙炙云深12:56就像我们现在做订单,其实买卖家也是作为一份快照数据。仅保存有限的实效性信息[捂脸]
[炙炙炙炙炙炙云深12:57「Super:我觉得团员应属于团队[发抖]」———————-[捂脸]团员首先是否需要成为注册登录,哪怕是输入下手机号。。总不能没有一分团员的数据啊
[Zpl12:57事实上,大家也可以不讨论我的业务,针对问题本质去思考;
[yanhua12:58本质上是太站在技术实现的角度考虑问题了[呲牙]
[Super12:58这个问题充值就能解决
[炙炙炙炙炙炙云深12:59感觉还是领域建模过程中,一些数据的适当冗余可以解决很多问题[捂脸]
[yanhua13:00有很多所谓的“中间表”,用业务词汇来表达的话,这个词往往是个名词,但也是个动词。而且更像是动词。
[Zpl13:00@yanhua有什么结论,记得分享一下。
[阿斌哥13:00我的观点:团是聚合根,团员是团聚合内部的值对象,其属性基本就是一个用户ID,用户是另外的聚合根。
[右军13:01「阿斌哥:我的观点:团是聚合根,团员是团聚合内部的值对象,其属性基本就是一个用户ID,用户是另外的聚合根。」———————-[强]
[Super13:01「阿斌哥:我的观点:团是聚合根,团员是团聚合内部的值对象,其属性基本就是一个用户ID,用户是另外的聚合根。」———————-确实是这样的,我平时实践最基本也是存到userid
[yanhua13:02「阿斌哥:我的观点:团是聚合根,团员是团聚合内部的值对象,其属性基本就是一个用户ID,用户是另外的聚合根。」———————-没错。不过,需要明确一点,团员这个值对象,在团下面是一个集合
[阿斌哥13:02嗯,我是这个意思
[Super13:04回到那个性能问题,现在是业务上必须把100个用户拉入内存吗?如果是的话,这和ddd的设计似乎没有直接关系呢
[yanhua13:04而且,可能还不只是一个用户id那么简单,比如这个用户什么时间参加的这个团?参加这个团,备注了什么信息?比如这个团有一些选项可选,记录在哪里?
[yanhua13:04实际的业务应该不是那么简单,这个讨论和https://blog.sapiensworks.com/post/2016/07/14/DDD-Aggregate-Decoded-2这里面讲的太像了
[Super13:05「yanhua:而且,可能还不只是一个用户id那么简单,比如这个用户什么时间参加的这个团?参加这个团,备注了什么信息?比如这个团有一些选项可选,记录在哪里?」———————-如果只是这些,其实也并不多吧,对于100团员而言,100团员与100用户,个人感觉还是有本质区别,后者要复杂的多
[yanhua13:07100个团员,或1000个团员,都属于团这个聚合根,那乐观锁怎么做。这1000个团员中间如果需要修改信息,乐观锁只做在聚合根上,那修改失败的情况太常见了
[yanhua13:07所以这也是ddd中强调聚合根要小的原因之一
[Zpl13:07你说这个就是大聚合,并发冲突严重的
[yanhua13:08是啊,如果把团员(用户id,参团时间,选项)放在团这个聚合下,就有这个问题
[阿斌哥13:08嗯,不是很复杂,加几个字段还是个值对象[呲牙],如果再继续复杂,以至于团员本身具有一些和团没啥关系的业务逻辑,那就要考虑提升为聚合了。
[yanhua13:09嗯,所以,ddd这个东西诡异的地方就在于,你业务信息输入的多少,对设计结果影响太大
[右军13:09「yanhua:100个团员,或1000个团员,都属于团这个聚合根,那乐观锁怎么做。这1000个团员中间如果需要修改信息,乐观锁只做在聚合根上,那修改失败的情况太常见了」———————-100个团员修改信息是哪些信息?
[Super13:10确实,想到这,乐观锁会是一个问题
[yanhua13:10参团的时间,参团的一些选择等
[Zpl13:10然后大家还是只是考虑1个团的情况
[Zpl13:10事实上是,n场活动,每个活动n个团
[yanhua13:11@Zpl我会和我最近的那个案例一起总结的。感谢你提出这么好的案例[呲牙]
[右军13:11这个是出游团还是拼多多采购团?如果是拼多多,基本上是id
[yanhua13:11嗯,要是pdd,就简单了
[yanhua13:11如果是社区拼团就复杂了
[yanhua13:11还是业务背景的问题
[右军13:12可以把需求整理出来,然后大家分头建模讨论
[Zpl13:12嗯嗯,设计上,不倾向于简化为userid列表,作为团员。因为这样可追溯性差;
[Super13:14「右军:「yanhua:100个团员,或1000个团员,都属于团这个聚合根,那乐观锁怎么做。这1000个团员中间如果需要修改信息,乐观锁只做在聚合根上,那修改失败的情况太常见了」———————-100个团员修改信息是哪些信息?」———————-我们先假设一些操作会修改到团员信息。在这个场景下,针对团员信息的修改,不只是一个用户或者一个团,而是众多的“用户”都有可能是这些修改行为的触发者。我现在的理解,这也是OrderItem和GrouponUser的差别,前者只有一个订单和一个用户,而后者是一个团和一堆用户。
[Super13:14后者乐观锁问题严重得多,前者可以理想的认为没有乐观锁的问题
[右军13:15如果是用户基本信息在用户上下文
[阿斌哥13:37还是不能脱离具体的业务场景去分析。如果团员自身还经常要修改各种信息什么的,可以把团员建模成聚合根,团员聚合根中通过团ID关联到团聚合根,要修改团员的信息通过用户ID和团ID获取到团员进行修改。团聚合中继续存用户ID的集合
[阿斌哥13:39要修改团员的信息为什么要通过团聚合把一千个团员找出来?显然不合理。实际业务也不会是这样的吧,肯定是用户自己去改自己的团员信息,这种业务场景下,把团员提升为聚合个人觉得没毛病。
[阿斌哥13:40个人观点,有不合理的还请指正[呲牙]
[Super13:45@阿斌哥[抱拳]大佬真实在
[Super13:48确实是这样,结合上面的说法,就可以不拿OrderItem跟团员做类比了:因为现在的设计里,“团员”是一个聚合根,只不过“团”与“团员”是一对多的关系,它们之间没有其他的中间表,团员本身有团Id,因此就形成了这个结构。
[子鱼] 优先业务,后技术吧。
如果性能上确实有问题,也只能妥协了,目前好像还没有专为DDD做持久化的框架。
———-
@刘杰 我们团队一直在开发的DDD持久化框架Obase快要发布了
[yanhua] spring data jdbc是原生支持ddd的
[队长,我还可以救一下] axonframework了解一下@刘杰
[陈瑞] 这个问题的本质是说,团与团员之间存在一个关联,这个关联是单向的还是双向的,如果是单向的方向如何
即便存在团到团员的关联,我认为一般也不应该基于这个关联来验证是否满员这条规则。现实世界当中,也不是每次验证时都去数数,首先就不符合“领域模型要忠实反映现实世界”这一原则。
是否需要这个方向的关联,关键还是看问题域反映的现实世界中是否存在从团到团员的导航
实际上,应该在“团”类增加一个属性,用于团员计数,每次有用户入团时把这个计数加一
再看第二条规则。将一个用户加入一个团时,实际上是在团与团员之间创建一个关联实例,这个关联的两端分别是团和用户,在对象系统中不可能存在两个相同的关联实例,因此这个规则在领域模型中是当然存在的,不需要领域层面的验证。实际系统中可以在接口层和应用层做处理:(1)接口层,用户进入团购页面时,应当查询这个关联实例是否存在,如果存在,就要对界面做相应处理;(2)应用层,参团应用服务应该首先查询是否存在这个关联实例,如果存在引发异常。
当然,这两个规则可能还需要考虑并发问题,这就更复杂一些。可以用Obase的对象版本控制来解决。
我的意思是不基于这个关联关系来验证满员,而是基于一个计数属性,验证逻辑是在团上
在团上定义一个IncreaseMemberCount方法,在这个先做验证,然后递增_memberCount;
团员类定义一个方法SetTeam(Team t),在这个方法里面调用t.IncreaseMemberCount(),(如果是显式关联,就在关联内的构造函数里面调用)。
首先考虑现实的业务过程,现实的业务过程本来就会考量性能的。没有人会在每次加入新成员时把成员列表数一遍。
[子鱼] 类似的,订单和订单项的问题,订单项是不是应该放到订单里面作为一个大聚合了?如果订单项作为一个大聚合,也会出现性能问题吧
[陈瑞] 是的。每次统计个数都要查数据库
从数据库层面讲,这种场景都在加一个冗余字段;从领域模型层面讲,这个冗余字段就是个属性。
首先是弄清楚关联是否真的为聚合关联,像订单和订单项是聚合关联,但团跟团员就不是。因为团和用户是两个独立的实例,用户参团是一种参与关系,并不是团的构成元素。
如果确定是聚合关联,那原则上还是要定义成聚合,即便聚合的对象非常多。但就我的经验来看,现实中真正的聚合涉及的对象都不多,因为现实世界没那么复杂,否则人们就无法理解了。
8.请问事务你们是在应用层还是领域层处理啊,如果在领域层一个应用服务需要多个领域服务时如何保障事务一致的呀。
[刘杰]
DDD少林派 [2019-02-03]
➤ 问题解答
[Super18:46我是在应用层
[刘杰18:46我也想放在应用层,但感觉是一种妥协~~~,所以想问下大佬
[花雾19:00应用层
[花雾19:00文章里有讲

若有收获,就点个赞吧
0 人点赞
