测试启动
标准输入显示到终端
test.yml
filebeat.inputs:- type: stdinenabled: trueoutput.console:pretty: trueenable: true
filebeat -e -c test.yml
读取文件显示到终端
nginx.yml
filebeat.inputs:- type: logenabled: truepaths:- /data/nginx/logs/default*output.console:pretty: trueenable: true
filebeat -e -c nginx.yml
启动进程日志
logging.level: XXX
debug, info(默认), warning, or error
path.logs: /xxx/xxx
默认 安装目录/logs/filebeat
启动或重启生成新的,旧的命名为 filebeat.1 类推
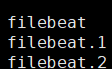
读取文件状态保持
保存每个文件的状态并经常将状态刷新到磁盘上的注册文件中
该状态用于记住harvester正在读取的最后偏移量,并确保发送所有日志行
如果输出(例如Elasticsearch或Logstash)无法访问,Filebeat会跟踪最后发送的行,并在输出再次可用时继续读取文件
数据目录/registry/filebeat/
在Filebeat运行时,每个prospector内存中也会保存文件状态信息,当重新启动Filebeat时,将使用注册文件的数据来重建文件状态,Filebeat将每个harvester在从保存的最后偏移量继续读取。
每个prospector为它找到的每个文件保留一个状态。由于文件可以被重命名或移动,因此文件名和路径不足以识别文件。对于每个文件,Filebeat存储唯一标识符以检测文件是否先前已被采集过。
专用日志搜集模块
以 nginx 为例
m.yml
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
filebeat -c m.yml modules list # 列出支持的
filebeat -c m.yml modules enable nginx # 启用、禁用
filebeat -c m.yml modules disable nginx # 启用、禁用
- module: nginx# Access logsaccess:enabled: truevar.paths: /var/log/nginx/access.log* # 默认访问日志路径# Error logserror:enabled: truevar.paths: /var/log/nginx/error.log* # 默认错误日志路径
var.paths 接收一个数组
var.paths: ["xx1.log","xx2.log"]或var.paths:- "xx1.log"- "xx2.log"
input
行过滤
filebeat.inputs:- type: logenabled: truepaths:- /var/log/messages- /var/log/securefields:type: oslogexclude_lines: ["user1","admin"]include_lines: ["Failed"]
单条日志有多行处理
multiline:
pattern: ‘^[‘
negate: true
match: after
filebeat.inputs:- type: logenabled: truepaths:- /usr/local/tomcat/logs/catalina.outfields:type: tomcatfields_under_root: truemultiline:pattern: '^\['negate: truematch: after
自定义字段
tags 添加值
tags:[“aaa”,”bbb”]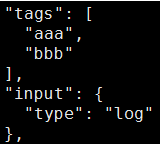
fields 添加键值
fields:
name1: “aaa”
name2: “啊啊啊”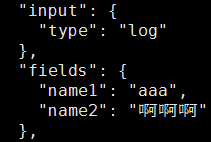
fields_under_root: true # 删除 fields父级字段,置于顶级字段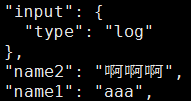
output
console
output.console:pretty: trueenable: truecodec.format: # 只输出指定字段拼成的字符串string: '%{[@timestamp]} %{[message]}'
es
指定索引名
output.elasticsearch:hosts: ["http://es:9200"]index: "%{[fields.type]}-%{+yyyy.MM.dd}"setup.template.name: "filebeat"setup.template.pattern: "filebeat-*"
kafka
filebeat.inputs:- type: logenabled: truepaths:- /var/log/message- /var/log/securefields:type: oslogname: "192.168.80.191"output.kafka:enabled: truehosts: ["192.168.80.81:9092","192.168.80.82:9092","192.168.80.83:9092"]topic: "%{[fields][type]}"partition.round_robin:reachable_only: truerequired_acks: 1compression: gzipmax_message_bytes: 1000000logging.level: warning
logstash
output.logstash:hosts: ["localhost:5044"]
processors 处理
丢弃符合正则的行
processors:- drop_event:when:regexp:message: "^ab" # 丢弃 message 中 ab 开头的行
过略字段
processors:- drop_fields:fields:- "log"- "input"- "ecs.version" # 子级字段- "agent"
添加字段
processors:- add_fields:target: a1fields:k1: v1k2: v2
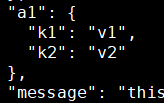
添加元数据信息
processors:- add_host_metadata:when.not.contains.tags: forwarded- add_cloud_metadata: ~- add_docker_metadata: ~- add_kubernetes_metadata: ~

若有收获,就点个赞吧
0 人点赞
