:::info 💡宽度优先搜索(Breadth First Search,BFS ),也叫做广度优先搜索,或者层次遍历。一般在图论中叫宽度优先搜索或者广度优先搜索,在树结构中叫做层次遍历,目的都是遍历所有节点。 :::
图的广度优先搜索
BFS的做法是遍历当前节点的所有相邻节点,也就是下一层所有节点,然后在依次遍历下一层所有节点的相邻节点。如下图所示,当前节点为2号,那么相邻的3、5、4号节点为下一层节点,为了保证在遍历完4号节点之后,可以继续向下遍历,则需要暂存3、5、4号节点,并且可以取出继续分别访问它们的相邻节点。这里就需要使用数据结构中的队列,利用队列先进先出(Fisrt in Fisrt out, FIFO)的特点,可以对每一个节点访问其相邻节点,并且将相邻节点加入队列中,在遍历完当前层时,队列中充满的就是下一层节点。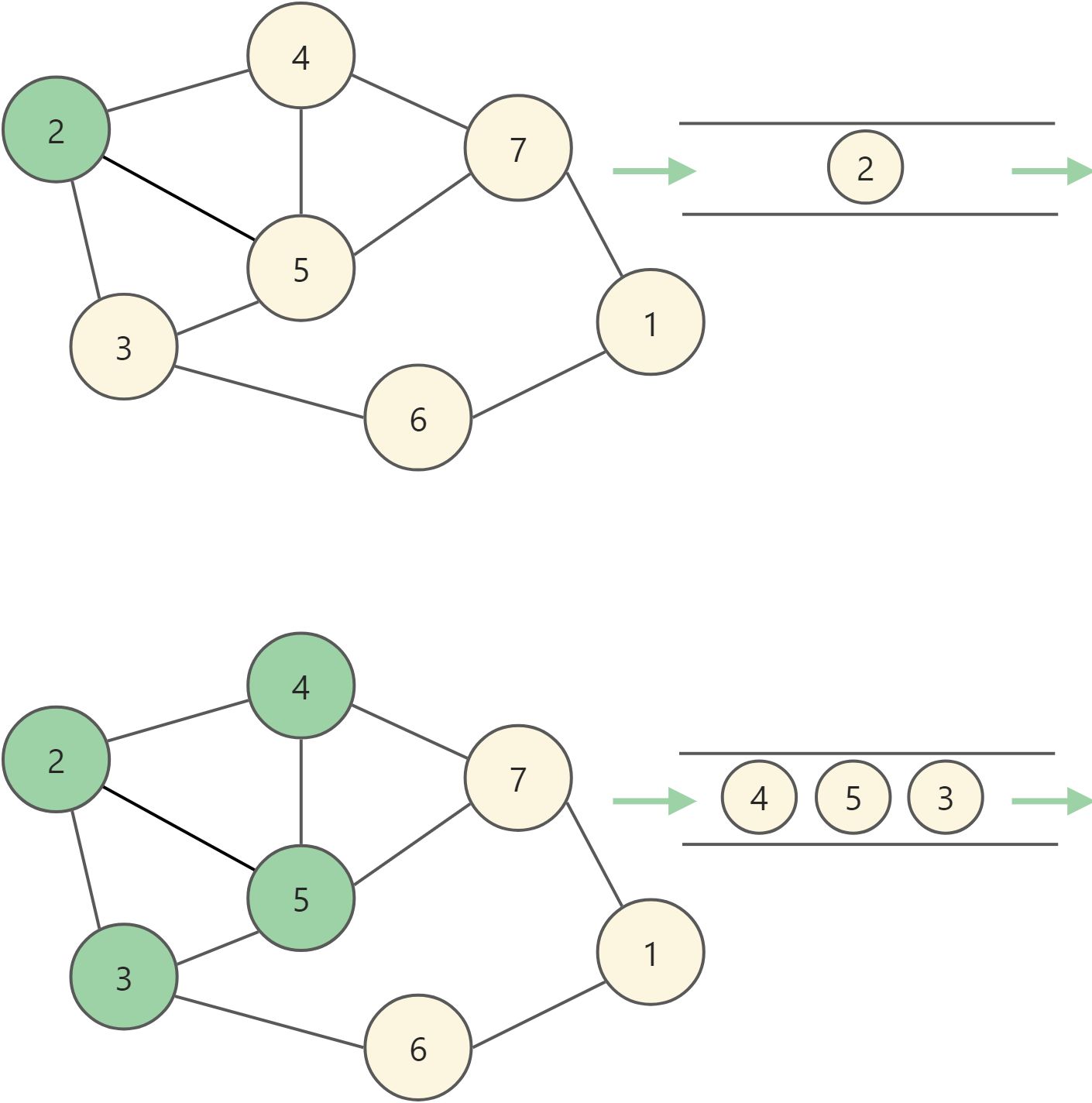
在遍历的过程中还需要对已经访问的节点设置一个已经访问的标志,避免重复遍历进入死循环。
伪代码实现
用邻接矩阵的形式来表示图中节点的关系,在实际的问题中通常时二维矩阵,或者节点边的状态表示,可以将其转化为邻接矩阵。
vector<int> visited; //记录节点是否访问queue<int> q; //队列q.insert(adj[0][0]); //先插入起始节点while (!q.empty()) { //当队列不为空时,继续搜索int n = q.size(); //当前层一共多少节点while (n--) { //搜索完当前层所有节点进入下一层int node = q.front();q.pop(); //出队auto &tmp = adj[node]; //当前节点的所有邻接节点for (auto &next:tmp) {if (visited[next]) continue; //若节点已经访问,则跳过visited[next]=true; //否则访问该节点,并且标记已经访问q.insert(next); //该节点加入队列}}
通过上述伪代码可以实现对图的宽度优先遍历,以离初状态的状态距离为序进行遍历。在实际问题中可以计算出图中节点之间的距离,比如力扣中的题目,计算网络的空闲时间,就可以通过计算各个节点离初状态的距离来计算网络中最远节点接受信息的时间。
树的层次遍历
对于树的层次遍历,思路跟图的广度优先遍历是相同的,在广度优先搜索的每一轮中,我们会遍历同一层的所有节点。
首先把根节点 root 放入队列中,随后在广度优先搜索的每一轮中,我们首先记录下当前队列中包含的节点个数(记为 cnt),即表示上一层的节点个数。在这之后,我们从队列中依次取出节点,直到取出了上一层的全部 cnt 个节点为止。当取出节点cur 时,我们将 cur 的值放入一个临时列表,再将cur 的所有子节点全部放入队列中。
当这一轮遍历完成后,临时列表中就存放了当前层所有节点的值。这样一来,当整个广度优先搜索完成后,我们就可以得到层序遍历的结果
以力扣的题目N叉树的层次遍历为例,如上图的二叉树为例,对N叉树进行层次遍历,并将结果存储在数组中,如[[1],[3,2,4],[5,6]]
/*// Definition for a Node.class Node {public:int val;vector<Node*> children;Node() {}Node(int _val) {val = _val;}Node(int _val, vector<Node*> _children) {val = _val;children = _children;}};*/class Solution {public:vector<vector<int>> levelOrder(Node* root) {if (root==nullptr) return {};vector<vector<int>> ans;queue<Node*> q;q.push(root);vector<int> tmp;while (!q.empty()) {int n = q.size();while (n--) {auto node = q.front();q.pop();tmp.emplace_back(node->val);auto childs = node->children;for (auto &child:childs) {q.push(child);}}ans.emplace_back(move(tmp));tmp.clear();}return ans;}};

若有收获,就点个赞吧
0 人点赞
