Sqoop概述
sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(hive)与传统的数据库(mysql,poetgresql…间进行数据的传递,可以将一个关系型数据库(例如:MYSQL,Oracle,Postgres等)中的数据导入到Hadoop的HDFS中,也将HDFS的数据导入到关系型数据库中。
传统的应用程序管理系统,即应用程序与使用RDBMS的关系数据库的交互,是产生大数据的来源之一。由RDBMS生成的这种大数据存储在关系数据库结构中的关系数据库服务器中。
当大数据存储和Hadoop生态系统的MapReduce,Hive,HBase,Cassandra,Pig等分析器出现时,他们需要一种工具来与关系数据库服务器进行交互,以导入和导出驻留在其中的大数据。在这里,Sqoop在Hadoop生态系统中占据一席之地,以便在关系数据库服务器和Hadoop的HDFS之间提供可行的交互。
Sqoop - “SQL到Hadoop和Hadoop到SQL”
Sqoop是一个用于在Hadoop和关系数据库服务器之间传输数据的工具。它用于从关系数据库(如MySQL,Oracle)导入数据到Hadoop HDFS,并从Hadoop文件系统导出到关系数据库。它由Apache软件基金会提供。
Sqoop如何工作?
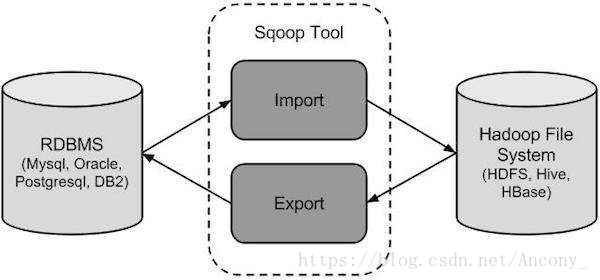
Sqoop导入
导入工具从RDBMS向HDFS导入单独的表。表中的每一行都被视为HDFS中的记录。所有记录都以文本文件的形式存储在文本文件中或作为Avro和Sequence文件中的二进制数据存储。
Sqoop导出
导出工具将一组文件从HDFS导出回RDBMS。给Sqoop输入的文件包含记录,这些记录在表中被称为行。这些被读取并解析成一组记录并用用户指定的分隔符分隔。
Sqoop的使用(命令在sqoop的bin目录下执行)
链接
其中的import(导入),export (导出)是相对于Sqoop的
MySQL数据库导入到HDFS
[root@master bin]# ./sqoop import —connect jdbc:mysql://192.168.53.8:3306/hahaha —username root —password 123456 —table biz_fee —m 1
—target-dir /mysql
—where “条件语句 city=’郑州 ‘ “
—fields-terminated-by ‘\t’
mysql数据库是本地的数据库,所以IP是windows的IP地址,hahaha是win中mysql数据库的数据库名
table是表名 m是map的数量
—fields-terminated-by ‘\t’ 指定分割符
—target-dir /mysql
数据库所有的表导入到HDFS中(某些版本不适用)
./sqoop import-all-tables —connect jdbc:mysql://192.168.53.8:3306/bigdata32 —username root
HDFS导出回RDBMS数据库
目标表必须存在于目标数据库中。输入给Sqoop的文件包含记录,这些记录在表中称为行。这些被读取并解析成一组记录并用用户指定的分隔符分隔。
./sqoop export —connect jdbc:mysql://localhost:3306/bigdata32 —username root —table emp —export-dir /emp/emp_data
安装配置
在/usr下创建目录(自定义目录)
在该文件夹下上传Sqoop并解压
将mysql的连接驱动包拷贝到其lib目录下

在使用之前把mysql允许远程连接(主要把wifi精灵关闭)
mysql> show databases;
mysql> use mysql;
mysql> update user set host = ‘%’ where user = ‘root’;
mysql> select hosh,user from user;
mysql> flush privileges #刷新权限
或者
GRANT ALL PRIVILEGES ON . TO ‘root’@’%’ IDENTIFIED BY ‘root’ WITH GRANT OPTION;
FLUSH PRIVILEGES

若有收获,就点个赞吧
0 人点赞
