参考请注意: 该文档创建于 2022/3/24,请注意随时间流逝文档信息是否过时,是否还有可参考的价值。 该文档仅作为个人笔记记录。 该文档记录时,使用的软件等版本会列在文档中,请注意识别。
相关资源
https://www.yuque.com/zhangshuaiyin/yygh-parent/gkdffa
开源软件漏洞数据库:https://security.snyk.io/
安装
windows
注:这个是直接在 windows 系统下的安装,由于作者在该次安装之后重装过系统,所以之后一直是在 docker 上使用 MySQL 了。 另外,推荐在 docker 上直接用 MySQL,前端使用 vscode 来操作。
https://juejin.cn/post/7024692194585870372
下载完成后,将压缩包解压,如图(版本8.0.28 winx64)
环境变量设置:系统变量/Path加入解压后bin所在的目录
然后通过powershell输入
PS C:\Users\Administrator> cd "D:\Program Files\MySQL"PS D:\Program Files\MySQL> mysqld --initialize-insecure --user=mysqlPS D:\Program Files\MySQL> mysqld -installService successfully installed.PS C:\Users\Administrator> net start MySQLMySQL 服务正在启动 ..MySQL 服务无法启动。服务没有报告任何错误。请键入 NET HELPMSG 3534 以获得更多的帮助。
在这里出错。然后使用了以下方案
输入mysqld --initialize,然后重启powershell,继续,然后。。。
PS C:\Users\Administrator> net start MySQLMySQL 服务正在启动 ........MySQL 服务无法启动。请键入 NET HELPMSG 3523 以获得更多的帮助。PS C:\Users\Administrator> net helpmsg 3523*** 服务无法启动。PS C:\Users\Administrator> net start MySQLMySQL 服务正在启动 ..MySQL 服务无法启动。服务没有报告任何错误。请键入 NET HELPMSG 3534 以获得更多的帮助。
我**。。。说实话改错改回原点,我平生第一次见。
然后试图按照mysqld --console启动,依然报错:
2022-03-24T11:48:24.204449Z 0 [System] [MY-010116] [Server] D:\Program Files\MySQL\bin\mysqld.exe (mysqld 8.0.28) starting as process 126162022-03-24T11:48:24.271151Z 1 [System] [MY-013576] [InnoDB] InnoDB initialization has started.2022-03-24T11:48:25.792476Z 1 [System] [MY-013577] [InnoDB] InnoDB initialization has ended.mysqld: Table 'mysql.plugin' doesn't exist2022-03-24T11:48:26.237088Z 0 [ERROR] [MY-010735] [Server] Could not open the mysql.plugin table. Please perform the MySQL upgrade procedure.2022-03-24T11:48:26.237730Z 0 [Warning] [MY-010441] [Server] Failed to open optimizer cost constant tables2022-03-24T11:48:26.238944Z 0 [Warning] [MY-010441] [Server] Failed to open optimizer cost constant tables2022-03-24T11:48:26.239436Z 0 [Warning] [MY-010441] [Server] Failed to open optimizer cost constant tables2022-03-24T11:48:26.239902Z 0 [Warning] [MY-010441] [Server] Failed to open optimizer cost constant tables2022-03-24T11:48:26.240245Z 0 [Warning] [MY-010441] [Server] Failed to open optimizer cost constant tables2022-03-24T11:48:26.240682Z 0 [Warning] [MY-010441] [Server] Failed to open optimizer cost constant tables2022-03-24T11:48:26.241168Z 0 [Warning] [MY-010441] [Server] Failed to open optimizer cost constant tables2022-03-24T11:48:26.321491Z 0 [Warning] [MY-010015] [Repl] Gtid table is not ready to be used. Table 'mysql.gtid_executed' cannot be opened.2022-03-24T11:48:26.551910Z 0 [Warning] [MY-010015] [Repl] Gtid table is not ready to be used. Table 'mysql.gtid_executed' cannot be opened.2022-03-24T11:48:26.607563Z 0 [Warning] [MY-010068] [Server] CA certificate ca.pem is self signed.2022-03-24T11:48:26.607753Z 0 [System] [MY-013602] [Server] Channel mysql_main configured to support TLS. Encrypted connections are now supported for this channel.2022-03-24T11:48:26.609821Z 0 [Warning] [MY-010441] [Server] Failed to open optimizer cost constant tables2022-03-24T11:48:26.610202Z 0 [ERROR] [MY-013129] [Server] A message intended for a client cannot be sent there as no client-session is attached. Therefore, we're sending the information to the error-log instead: MY-001146 - Table 'mysql.component' doesn't exist2022-03-24T11:48:26.610362Z 0 [Warning] [MY-013129] [Server] A message intended for a client cannot be sent there as no client-session is attached. Therefore, we're sending the information to the error-log instead: MY-003543 - The mysql.component table is missing or has an incorrect definition.2022-03-24T11:48:26.622180Z 0 [ERROR] [MY-010326] [Server] Fatal error: Can't open and lock privilege tables: Table 'mysql.user' doesn't exist2022-03-24T11:48:26.622434Z 0 [ERROR] [MY-010952] [Server] The privilege system failed to initialize correctly. For complete instructions on how to upgrade MySQL to a new version please see the 'Upgrading MySQL' section from the MySQL manual.2022-03-24T11:48:26.623340Z 0 [ERROR] [MY-010119] [Server] Aborting2022-03-24T11:48:27.852643Z 0 [System] [MY-010910] [Server] D:\Program Files\MySQL\bin\mysqld.exe: Shutdown complete (mysqld 8.0.28) MySQL Community Server - GPL.
此时状态进一步描述:tasklist| findstr "mysql":没有输出,没有残余进程。mysql -u root -p无效
PS D:\Program Files\MySQL> mysql -u root -pEnter password: *********ERROR 2003 (HY000): Can't connect to MySQL server on 'localhost:3306' (10061)
然后卸掉重来试试:
PS D:\Program Files\MySQL> mysqld -removeService successfully removed.PS D:\Program Files\MySQL> mysqld --initializePS D:\Program Files\MySQL> mysqld -installService successfully installed.PS D:\Program Files\MySQL> net start mysqlMySQL 服务正在启动 ..MySQL 服务无法启动。服务没有报告任何错误。请键入 NET HELPMSG 3534 以获得更多的帮助。PS D:\Program Files\MySQL> mysqld -removeService successfully removed.PS D:\Program Files\MySQL> mysqld --initialize这次删掉data文件夹的时候资源管理器正好停留到了bin这儿,然后这个命令奇迹般花了好长时间结束。PS D:\Program Files\MySQL> mysqld -installService successfully installed.PS D:\Program Files\MySQL> net start mysqlMySQL 服务正在启动 ..MySQL 服务已经启动成功。
终于活了。下面停了一下然后再次重新启动,正常。
接下来尝试登录root账户。
PS C:\Users\Administrator> mysql -u root -pEnter password: ************Welcome to the MySQL monitor. Commands end with ; or \g.Your MySQL connection id is 8Server version: 8.0.28Copyright (c) 2000, 2022, Oracle and/or its affiliates.Oracle is a registered trademark of Oracle Corporation and/or itsaffiliates. Other names may be trademarks of their respectiveowners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql>
其中,密码在D:\Program Files\MySQL\data目录下一个后缀名为.err的文件中(只有一个,我的为DESKTOP-RKHB6NK.err)
在其中搜localhost:,后面就是密码,如图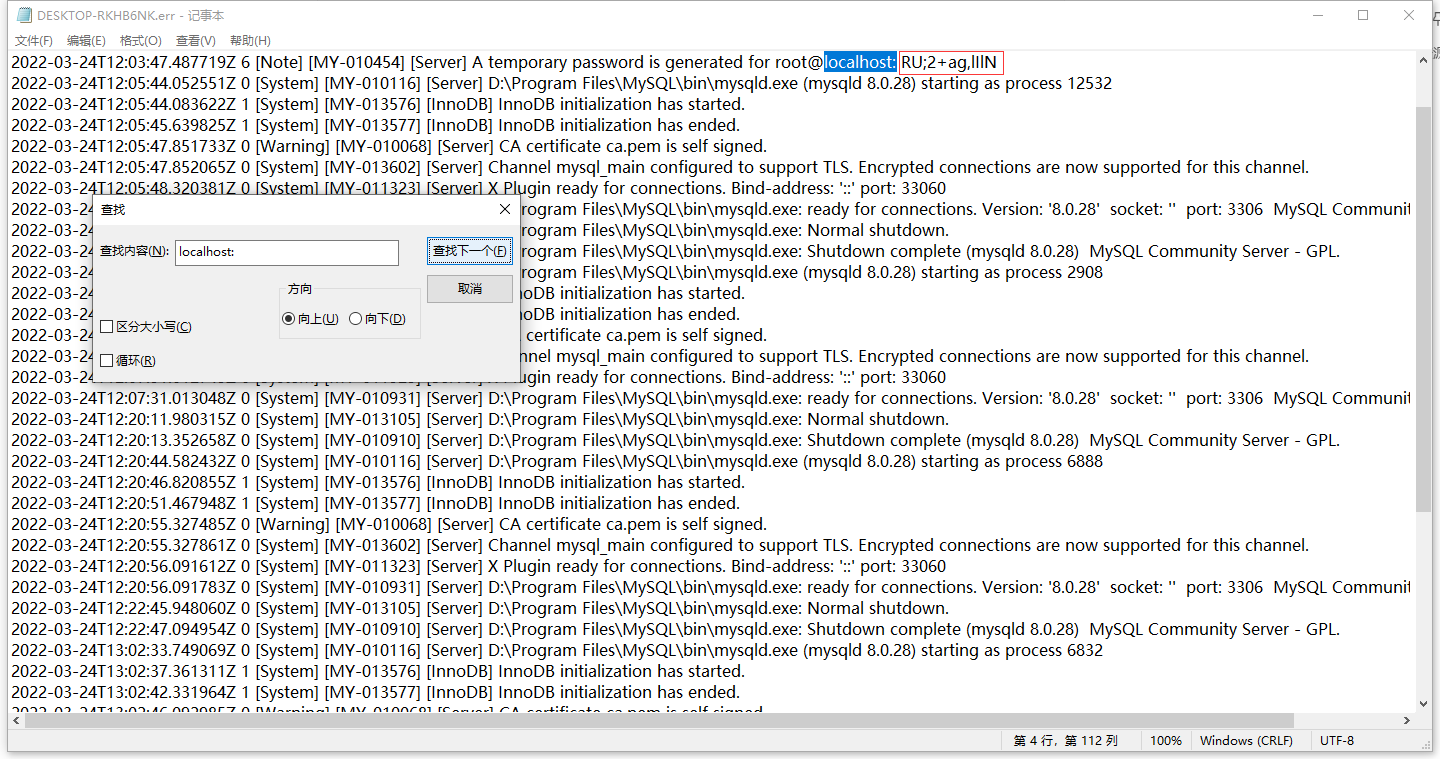
你这究竟是大写的i还是小写的L啊,淦
然后登录成功。一定注意这个命令是mysql不是mysqld!
然后通过ALTER USER 'root'@'localhost' IDENTIFIED BY 'new_password';修改为新密码(别问我为什么一定要加分号)
设置时区
mysql> show variables like '%time_zone';+------------------+--------+| Variable_name | Value |+------------------+--------+| system_time_zone | || time_zone | SYSTEM |+------------------+--------+2 rows in set, 1 warning (0.00 sec)mysql> set global time_zone = '+08:00';Query OK, 0 rows affected (0.00 sec)
docker
windows powershell 跑这个:
PS> docker run -d `--network todo-app --network-alias mysql `-p 3306:3306 `-v todo-mysql-data:/var/lib/mysql `-e MYSQL_ROOT_PASSWORD=your_secret `-e MYSQL_DATABASE=your_db `mysql:8.0.28
或者写成这样的 docker-compose.yml
version: "3.7"services:mysql:image: mysql:8.0.28volumes:- mysql-data:/var/lib/mysqlenvironment:MYSQL_ROOT_PASSWORD: your_secretMYSQL_DATABASE: your_dbports:- 3306:3306volumes:mysql-data:
sql
ppt中的多种查询方式
关系代数
符号写法类似python, 访问实例
访问实例 的一个属性。
的一个属性。
认为 是一系列属性的元组,
是一系列属性的元组, 就是返回实例对应属性值的元组。
就是返回实例对应属性值的元组。 表示两个实例拼接组合成一个实例。
表示两个实例拼接组合成一个实例。
广义笛卡尔积:两张表每个实例相互拼接组合成一个新的表
象集的概念: (
( ) 一个表中属性元组
) 一个表中属性元组 的值为
的值为 的实例的
的实例的 属性元组下的属性元组值。
属性元组下的属性元组值。
选择运算: 代表表
代表表 中满足
中满足 的实例集合
的实例集合
投影运算: 代表表
代表表 中属性元组
中属性元组 的所有可能情况集合,之前重复的元组会保留原有次序去重。
的所有可能情况集合,之前重复的元组会保留原有次序去重。
连接运算: :是从两个表的广义笛卡尔积中按照比较条件
:是从两个表的广义笛卡尔积中按照比较条件 筛选连接值。
筛选连接值。
- 特殊连接运算:
 为等于的等值连接,在此基础上
为等于的等值连接,在此基础上 为自然连接
为自然连接
以下是返回值为表(元组序列)的关系代数运算与sql的对比:
| 操作类型 | 关系代数符号 | sql符号 |
|---|---|---|
| 选择 |  |
select * from **R** where **F** |
| 投影 |  |
select distinct **tupleA** from **R** |
| 连接 |  |
select * from **R** join **S** where **AθB** |
元组演算(alpha)
RANGE 表名 别名GET 工作空间名 (结果元组): 条件 DOWN/UP 排序元组
与或非用离散逻辑符号,存在任意可以用。
如果需要涉及到其他表条件,直接使用别名属性即可
QBE
填表查询,像这样子:
| 表名 | 后面每一列各个属性 |
|---|---|
| 这里填非表示该表条件不满足 | 1. 加 P.表示该属性加入查询结果,所有属性都有就放到表名下面2. 主键给一个随意的例子,加下划线,表示一种条件。 or两行不同的例子。and两行相同的例子,一般一个属性俩条件才用非主键属性相同实例前面加  表示这一行条件满足的实例不是上一个,主键两行也要对应示例 表示这一行条件满足的实例不是上一个,主键两行也要对应示例3. 插入 AO(优先级数字)``DO升序或降序,优先级数字越小越是主要关键字 |
该属性的条件 |
定义关键字
CREATE TABLE s(sno char(9) primary key comment 'Primary Key',sname char(12) unique comment 'Create Time',sex char(12) comment 'Update Time',age int(8) comment 'Update Time',content varchar(255) comment 'content',dept char(20) comment '专业') default CHARSET UTF8 comment 'newTable';
如果需要修改表,那么这样做:alter table <table_name> add/drop <约束>, ...;
类型关键字(数据类型)
char(length)``varchar(maxlength)定长/不定长字符串。
其中varchar还会额外使用2字节存储字符串长度,总占用长度maxlength+2字节int``smallint
约束关键字
https://juejin.cn/post/7051485859563962405
约束前面可以不加但尽量加CONSTRAINT yueshu_name作命名约束。
因为删除你肯定得alter table <表名> drop 约束名字!comment 'string'注释unique禁止重复primary key主键[auto_increment](https://www.w3school.com.cn/sql/sql_autoincrement.asp)(=1)创建自动增长,一般用于idnot null不能没有check <condition>条件约束
查一个表的约束:show create table <表名>
尤其是你没手动命名约束时很好用(在这死过一次)
建立索引
查询
select [DISTINCT] <tuples> from <table> # table 可以是括起来一个筛选后的表[where <condition>][group by <tuple>][order by <tuple>][limit num1, num2];
DISTINCT:查询结果去重<tuples>:s, sc``s, sc as new_name这种写法order by:结果按元组排序,元组每项可指定如何按照关键字排序。
如按照公司递减排序,并以数字顺序显示顺序号:ORDER BY Company DESC, OrderNumber ASCgroup by <tuple>:按元组分组,分组之后聚集函数作用在各组上而不是所有结果上。limit num1, num2从第num+1条开始选,选num2条。找第几名用这个
另附一些基本说明:
查询可以嵌套,例如以下:
SELECT SnameFROM StudentWHERE Sno INSELECT SnoFROM SCWHERE Cno='2';
可以从一个处理过后的表中查询,例如以下:
select * from (select sno, count(cno) as course_count from scgroup by sno) sxc;
- 处理后的表需要一个名字
单层嵌套的运行逻辑顺序:from表连接 where筛选 group by 聚合
多表查询(连接查询)
查询会涉及到多个表。
注意:<tuples>处,前面需要加表名和点,如这样s.sno, s.agetable多个表逗号隔开,如s, sc。注意这样是从两表直接连接中选值,笛卡尔积形式,很容易有重复- 查询可以嵌套
exists根据后面结果是否存在返回true/false。后面选什么字段没用。连接
可以显式的在from处通过[inner/left/right/full] join <table> on <condition>,按照条件连接表。连接分为四类:inner连接后值,左右表内容都存在(join默认,可不写),left左边没匹配的也会写进去,right同理,full两边没匹配的都会写进去。
没有匹配的表项,对应的没匹配上的表的属性都是null<condition>两表皆可读插入
INSERT INTO table_name [(列1, 列2,...)] VALUES (值1, 值2,....), (...), ...;更新
UPDATE 表名称 SET 列名称1 = 新值1, 列名称2 = 新值2 WHERE <condition>新值处可以使用条件修改:update sc set grade =casewhen grade*1.05 > 100 then 100else grade*1.05endwhere cno=1;
删除
delete from table where <condition>触发器
CREATE TRIGGER <触发器名>
{BEFORE|AFTER} <触发事件> ON <表名>
FOR EACH{ROW|STATEMENT}
[WHEN <触发条件>]
<触发动作体>
{ROW|STATEMENT}行级/语句级 触发器:
行级触发器对操作语句对应的每个受影响的行执行一次。
语句级触发器只是在一条语句触发一次。
(mysql8.0.28)只允许使用行触发器
触发器中可以拿到表在命令处理过程中new``old两个版本,根据这个做下一步动作。
sequelize
[egg 使用教程](https://www.eggjs.org/zh-CN/tutorials/sequelize)``[列设置文档](https://sequelize.org/docs/v6/core-concepts/model-basics/#column-options)·
注意:这里的文档都是看的
sequelizev6 的内容,但是示例是用的 v4,差距很大。
定义
坑:因为 sql 中字段不区分大小写,所以虽然在sequelize里面有些字段命名是驼峰,但是转到sql表里面就是user_id这种形式!
坑:默认情况下,sequelize会自动复数化表名,如:模型名是user,表名就是users,而且egg里面模型名是User
数据类型
请点击连接查看文档。
| 类型 | 字节数 | 有符号最大值 |
|---|---|---|
| tinyint | 1 | 127 |
| smallint | 2 | 32767 |
| mediumint | 3 | 8388607 |
| int | 4 | 2147483647 |
| bigint | 8 |  |
验证和约束
验证是在 Sequelize 层面通过编写纯 js 进行检查(自定义或 Sequelize 内置函数),如果检查不通过,就不会向数据库发送数据。缺点是无法在这个过程中向数据库获取信息,来做一些需要这些信息的验证,如唯一、总数等。
约束是在数据库层面进行检查,如果检查不通过会通过数据库返回错误。注意这个操作向数据库发送了数据。
增删改查
通过model来进行增和查。model的实例可以用来改,也可以删
常用插入
- 通过生成模型实例并保存的方式插入:
model.[create](https://sequelize.org/api/v6/class/src/model.js~model#static-method-create)
注意,如果不设置include,建立的模型实例是没有联系相关字段的。 - 通过插入语句:
在程序中插入一般是生成模型实例保存到数据库,直接insert硬数据的时候很少常用查找
```javascript const {gt, lte, ne, in: opIn} = Sequelize.Op; // 使用运算符查找
Model.findAll({ where: { attr1: {
[gt]: 50},attr2: {[lte]: 45},attr3: {[opIn]: [1,2,3]},attr4: {[ne]: 5},// or 和 and[or]: [{id: [1, 2, 3]},{[and]: [{id: {[gt]: 10}},{id: {[lt]: 100}}]}]
}, // 按照关键字排序,数组表示层叠优先级 order: [ // Will escape title and validate DESC against a list of valid direction parameters [‘title’, ‘DESC’],
// Will order by max(age)sequelize.fn('max', sequelize.col('age')),// Will order by max(age) DESC[sequelize.fn('max', sequelize.col('age')), 'DESC'],// Will order by otherfunction(`col1`, 12, 'lalala') DESC[sequelize.fn('otherfunction', sequelize.col('col1'), 12, 'lalala'), 'DESC'],// Will order an associated model's createdAt using the model name as the association's name.[Task, 'createdAt', 'DESC'],// Will order through an associated model's createdAt using the model names as the associations' names.[Task, Project, 'createdAt', 'DESC'],// Will order by an associated model's createdAt using the name of the association.['Task', 'createdAt', 'DESC'],// Will order by a nested associated model's createdAt using the names of the associations.['Task', 'Project', 'createdAt', 'DESC'],// Will order by an associated model's createdAt using an association object. (preferred method)[Subtask.associations.Task, 'createdAt', 'DESC'],// Will order by a nested associated model's createdAt using association objects. (preferred method)[Subtask.associations.Task, Task.associations.Project, 'createdAt', 'DESC'],// Will order by an associated model's createdAt using a simple association object.[{model: Task, as: 'Task'}, 'createdAt', 'DESC'],// Will order by a nested associated model's createdAt simple association objects.[{model: Task, as: 'Task'}, {model: Project, as: 'Project'}, 'createdAt', 'DESC'],// Will order by max age descendingsequelize.literal('max(age) DESC'),// Will order by max age ascending assuming ascending is the default order when direction is omittedsequelize.fn('max', sequelize.col('age')),// Will order by age ascending assuming ascending is the default order when direction is omittedsequelize.col('age'),// Will order randomly based on the dialect (instead of fn('RAND') or fn('RANDOM'))sequelize.random()
],
// 并入联系的模型
include: [{
model: this.ctx.model.User,
as: ‘user’,
attributes: [ ‘id’, ‘name’, ‘age’ ],
}]
})
[常用选项](https://sequelize.org/docs/v6/core-concepts/model-querying-finders/):<br />`[findOne](https://sequelize.org/api/v6/class/src/model.js~model#static-method-findOne)(options: object): Promise<Model|null>`<br />按条件找一行,没有返回`null`<br />`[count](https://sequelize.org/api/v6/class/src/model.js~model#static-method-count)(options: object): Promise<number>`<br />对符合条件的行进行计数。返回总数。<br />`[findAndCountAll](https://sequelize.org/api/v6/class/src/model.js~model#static-method-findAndCountAll)(options: object): Promise<{count: number|number[], rows: Model[]}>`<br />找到合适的行(`rows`字段),并且输出匹配项目的行数(`count`字段)。<br />注意,如果用了`limit`和`offset`,只对输出的行限制,对统计的数量无影响。<a name="qiSCj"></a>### 常用更新/删除基于模型实例:1. 通过直接赋值字段/`model.[set](https://sequelize.org/api/v6/class/src/model.js~model#instance-method-set)({ field: newValue })`函数更新,但还需要`model.save()`保存修改。2. `model.update({ field: newValue })`更新并仅保存选定的字段。此外也可以基于查询[更新](https://sequelize.org/docs/v6/core-concepts/model-querying-basics/#simple-update-queries)和删除。```javascript// Change everyone without a last name to "Doe"await User.update({lastName: "Doe",// 基于已有值更新:使用 s.fn 或者 s.literal 直接传入 sqlfirstName: sequelize.fn('upper', sequelize.col('firstName')),age: sequelize.literal('`age` + 1'),}, {where: {lastName: null,}});// Delete everyone named "Jane"await User.destroy({where: {firstName: "Jane"}});
注意:
- 更新的返回值是
number[1],表示受影响的行数。
只有在postgresql且options.returning=true时,返回number[2],额外加实际受影响的行数 - 删除的返回值是一个常数,表示受影响的行数
原生 sql 查询
原生查询一般返回两个参数:查询结果二维表 和 元数据(如 影响的行数,api连接待补充)联系
sequelize通过联系的方式来处理不同表之间的关系(外码)。 遗憾的是,它并不能和mongodb那样自动的给一个多层的对象建表,只能是建好表匹配内容。
mysql任何东西都是表。想要是对象树形,必须另建表。
Sequelize 提供了4种联系:
- The HasOne association
- The
[BelongsTo](https://sequelize.org/api/v6/class/src/model.js~model#static-method-belongsTo)association - The HasMany association
- The BelongsToMany association
对于1对1或者一对多的联系,如A.HasOne(B)``B.BelongsTo(A),默认外码是创建在B表。
虽然直观思维是外码在A里面然后查B的id,但是实际上不能这么干。尤其是A可以没有B和A.HasMany(B)的时候。
联系的配置
两个模型之间有联系,将其分为:源模型和目标模型两个概念。
其中,源模型通过hasOne``hasMany链接到目标模型,源模型不定义外码。
- One-To-One,源模型
hasOne链接到目标模型,目标模型belongsTo源模型 - One-To-Many,源模型
hasMany链接到目标模型,目标模型belongsTo源模型 - Many-To-Many,两边都应使用
belongsToMany
下面说明配置部分基本一些字段的作用:
onDelete``onUpdate联系的外码字段删除或更新时应该怎么处理。foreignKey自定义外码。可直接传入一个名称,或者一个包括name``type``allowNull``targetKey等字段的对象。
- 在源模型设置后影响的是目标模型或者连接表的外码,作为多联系的匹配依据
has和belongs如果都配置,这两个的foreignKey都需要填相同的值。
as可以给模型取别名,作为相同表多联系的区分依据。强烈建议使用驼峰命名。 | |[hasOne](https://sequelize.org/api/v6/class/src/model.js~model#static-method-hasOne)|[hasMany](https://sequelize.org/api/v6/class/src/model.js~model#static-method-hasMany)|[belongsTo](https://sequelize.org/api/v6/class/src/model.js~model#static-method-belongsTo)|[belongsToMany](https://sequelize.org/api/v6/class/src/model.js~model#static-method-belongsToMany)| | —- | —- | —- | —- | —- | | 函数执行者 | 源模型 | 源模型 | 目标模型 | 源模型目标模型 | | as | 目标的单数 | 目标的复数 | 目标的单数 | 对面的复数 | | foreignKey | 指代源模型外码名 | 指代源模型外码名
另附sourceKey | 指代源模型外码名
创建在该表 | 指代自己的外码名otherKey指代对面的外码名 | | | | | | | | | | | |
|
通过实例操作联系
sequelize 会给实例自动添加对对应联系进行操作的函数。函数命名后缀是联系名(该模型定义的as属性)对应的单复数。
这些函数包括(对多的联系会有其对应的复数形式):add``create``has``get``count``remove``set
初次之外,模型实例在 js 中include加入对应模型构造之后,可以直接通过联系名得到联系的对象。include可以只设置为{all: true},这样可以加载所有直接关联的模型。(继续关联最好还是自己配置)
表的配置/迁移
migration
sequelize给出了一种可撤销可记录式的配置建表、表迁移的解决方案,替代手动敲sql,然后敲完忘没影了。
流程:创建表迁移文件 写迁移文件的升级降级过程 执行表迁移
每一个文件可以看作一个表迁移的断点,再往后迁移只执行新写的迁移js文件了,相当于“迁移js文件是一次性使用的”
命令集合:
# 创建一个表迁移文件npx sequelize migration:generate --name=init-message# 执行表迁移
sync model
这种方法同步model更方便,但是这个方法只能在开发环境使用。[egg/app.js](https://github.com/eggjs/egg-sequelize#sync-model-to-db)
egg-sequelize 配置
app.model是sequelize实例。
以下是egg-sequelize给sequelize设置的默认配置:
{delegate: 'model',baseDir: 'model',logging(...args) {// if benchmark enabled, log usedconst used = typeof args[1] === 'number' ? `[${args[1]}ms]` : '';app.logger.info('[egg-sequelize]%s %s', used, args[0]);},host: 'localhost',port: 3306,username: 'root',benchmark: true,define: {// https://sequelize.org/docs/v6/core-concepts/model-basics/#table-name-inferencefreezeTableName: false,underscored: true,},};
需要注意的问题:
sequelize默认的model会加入createdAt和updatedAt两个字段。
可以通过配置关闭,详情见Timestamps
实体间关系论
我们知道,关系数据库需要建立多个表来表示现实中各种各样的关系。接下来我们就按照这个话题进行推导,来得到更多的结论。
在这之前,我们先讨论一些提前的假设和事实:
- 关系数据库中,多个表关系相连,这种逻辑上的相连都是通过外码来实现的
- 外码必然指向一个表的主键,每行主键唯一且永不变化
这里写:为什么要有这两个假设。
我们都知道,数据库各表有各种各样的联系,分为以下:
one-one:一对一,实例a只能对应唯一的实例b,反之也一样one-many:一对多,实例a可对应多个实例b,但b只能对应唯一的amany-many:多对多,实例a可对应多个实例b,b也可对应多个实例a。
对应关系是通过另一个C表来实现的
在这里,你会想一个问题,a和b在逻辑上是等价的吗?
就比如两个模型的one-one关系,外码在哪个表定义?是不是你把外码放到另一个表也可以?
sequelize中的hasOne和belongsTo,换着用也行?
处理关系关注的问题:
- 两个模型中,如果一方实例
a没有对应关系对象b,其是否可以作为一种情况存在?
如果是1对1的从属关系,下属没有对应完整实例的关系,是不能存在的,反之则是有可能的。
而对于多对多的关系,一般没有对应关系对象是可以存在的,但是也会有特例。 - 关注实例的历史性质,以及相关实例和关系的产生、更改和移除,对对应关系对象的影响。
主键相对应的前后的实例是变化一脉相承的,但是非主键属性会有变化,而且涉及到可能变化空间的问题。
插入
更新与删除
更新与删除是基于原来实例情况的,从一种状态到另一种状态的变化。
更新与删除意味着该实例相连的那一个实例被更换/删除,不再是原来的那一个实例。
(绿色为 sequelize 设置的默认值)
| cascade | set default/null | restrict | no action | |
|---|---|---|---|---|
| 更新 外码 | 无效果 不能更新为不存在的指向值,但是对更新为null无限制且无副作用 |
无效果 | 无效果 | 无效果 |
| 更新 指向 (指向主键,假设说不可更新) |
自动更新该外码字段 | 设置该外码字段 | 阻止 | 无效 |
| 删除 外码 | 无效果 | 无效果 | 无效果 | 无效果 |
| 删除 指向 | 删除自己 | 将自己修改 | 阻止 | 无效果 |
范式
我们知道,现实事物各个性质之间是有依赖的。 范式主要指导如何通过依赖进行分表,从而降低数据冗余。 但实际上,这样做也会加大很多查询事务的时间。 所以实际上对一个表的设计,分表去重但也不会去太多重。而且也不只是程度上有些事不干,也可以在字段层面上选择是否拆分。
依赖
包括函数依赖和多值依赖。
函数依赖:对于一行,通过确定的字段元组X查找元组Y,只能查到一条结果。(即存在一个Y为因变量,X是自变量的函数,但是具体这个函数是什么可以不必深究,函数就是表)
函数依赖关心是部分依赖还是完全依赖。(sno, cno) => grade是完全依赖。每个学生每门课有自己的成绩。(sno, cno) -> dept为非完全依赖。课程号与专业没什么必然联系。相当于函数有多余的自变量。
就像z(x, y)=2x这种,y是多余的。
只讨论非平凡依赖
如(sno, cno) => cno是平凡依赖,当然凭cno就能推导出cno自己,不用你提这一嘴废话。
非平凡依赖指的是,依赖于X的Y,不是X的一部分,得包括别的东西。(sno, cno) => grade是一个非平凡依赖。grade不是(sno, cno)的一部分。
码(候选码)
候选码K:K => U,由K可以索引唯一的所有属性。
定义中是完全依赖,K中的属性不能多也不能少。K的任意真子集都不是候选码。
但是也不一定只有一种情况,这时选其中之一作为主码。
不包含在任何可能的候选码的属性为非主属性。比如m:n联系的链接表的其它属性。
多值依赖
这个两个定义感觉说的都不是很明白。
而且,也不清楚”不满足多值依赖”的情况是如何的
非平凡多值依赖要求,依赖关联的两项之外不可为空。
- 对于表内的两组字段
X和Y,其中Z是这两组之外的其它字段。如果对于一组特定的X``Z的值,查找得到的Y的可能值组合(这个组合肯定会有),可以构造一个函数使得Y=f(X),和Z无关? - 对于表内两个
X相同但Y不同的字段,交换一下它们的Y值,其它不变,这样值的元组一定存在。
函数依赖是特殊的多值依赖。
多值依赖和其它部分Z也有关系。如果X=>>Y,则对Y的一部分Y'不一定满足X =>> Y'
公理系统
范式等级
范式等级是表的性质。我们判断的是表满足第几范式。 如果要进阶范式,一定关联到拆分成多个表。因为拆分之后的依赖图,各个表之间没有连线,就相当于没有依赖(逻辑上有但表上没有),所以整个关系模式满足了高阶的范式。
第一范式:无要求
将部分依赖于主码的字段,按照所依赖主码分表
第二范式:每个非主属性完全依赖于码。
将传递依赖于主码的字段,按照直接依赖项分表
第三范式:在以上基础上,每个表的非主属性也不传递依赖于码。
BC范式:每个分表任何的”决定属性因素”(也就是每个分表的主键)都包含整合大表中同一候选码中的字段(可不全)。
- 有多个候选码的可能时,才会出现这个问题
至此,所有只具有函数依赖的已经处理完毕。还有多值依赖。
第四范式:每个表都没有非平凡多值依赖
第五范式课件没有说明。
数据库事务
事务的ACID特性:
数据库故障实际上是不可预期的
恢复是基于冗余的恢复,利用之前备份的冗余数据恢复数据。
备份,在ppt中起了一个高大上的名字,叫做转储
根据备份时能不能改数据库,叫做静态备份和动态备份
按照一次备份是全备份还是只备份变化的部分,称为海量备份和增量备份
此外还需要日志文件
并发控制
实际上数据库很多事务都是并行执行的。根据是否并行分三种方式:
- 串行
- 交叉并行:类似于体系结构的多线程执行,每隔一会切换到另一个事务的一个执行部分
- 同时并行:多处理机同时并行
并发操作会破坏事务的隔离性从而带来数据不一致性,分为以下方面:
- 修改丢失:如订票系统,两个机器同时检测出剩16张票。然后同时订票,写入剩余票数都是它们自己取得的16-1,改成了两个15,而不是15和14
- 不可重复读:
- 读脏数据:T1先改数据,T2读,接下来T1撤销了,然后T2读的数据是一个不对的数据
主要通过三种方法做并发控制:
- 封锁:
某一个有影响的动作,在执行时先锁定。在该事务完毕解除锁之前,其它事务不能执行 - 时间戳
- 乐观控制法
主要讲锁控制法。
锁有两种锁:
- 写锁
X:事务T对数据对象加写锁之后,其它数据对象不能读写这个数据对象,也不能对这个数据对象加锁,直到T释放 - 读锁
S:事务T对数据对象加S锁之后,其它事务只能读该数据对象并加S锁,直到所有S锁解除之前,不能写该数据对象
可以根据规则得出一个矩阵。
锁机制会带来活锁和死锁两个新的问题:
- 活锁:如果有多个事务请求出现,当前一个事务锁解除之后,如果不按照时间顺序给等待的事务分配锁,就有可能有事务一直被锁无法执行
- 死锁:
事务T1封锁了数据R1
T2封锁了数据R2
T1又请求封锁R2,因T2已封锁了R2,于是T1等待T2释放R2上的锁
接着T2又申请封锁R1,因T1已封锁了R1,T2也只能等待T1释放R1上的锁
这样T1在等待T2,而T2又在等待T1,T1和T2两个事务永远不能结束,形成死锁
接下来将死锁如何预防和诊断:
预防有两种方法,一次把涉及到的数据全封锁和对数据规定顺序封锁,实际上是很困难的
诊断有两种方法:
- 规定时间超时认为死锁:由于时间问题,可能会误判执行时间长的事务,也可能会因为时间太长而一定要等这么些时间才能发现死锁
- 事务等待图:
每隔几秒生成一个事务等待图,如果出现环,就认为发生了死锁
解决方案是挑一个代价最小的事务,把它的锁给放了,欸嘿
接下来讲可串行性、封锁粒度、两段锁协议

若有收获,就点个赞吧
0 人点赞
