环境准备
方案1
- 购买至少4 台阿里云服务器
方案2
- 电脑性能够强大, 开4 台虚拟机


我的电脑性能如下:
工作模式
Docker Engine 1.12 introduces swarm mode that enables you to create a cluster of one or more Docker Engines called a swarm. A swarm consists of one or more nodes: physical or virtual machines running Docker Engine 1.12 or later in swarm mode.
There are two types of nodes: managers and workers.
If you haven’t already, read through the swarm mode overview and key concepts.
节点
- 管理节点 (上图Manager)
- 管理节点可以与管理节点互相通信
- 管理节点可以操作工作节点, 反之不行
- 工作节点 (上图Worker)
搭建集群
docker swarm 命令用法
```shell docker swarm —help
Usage: docker swarm COMMAND
Manage Swarm
Options: —help Print usage
Commands:
初始化集群
init Initialize a swarm
加入集群
join Join a swarm as a node and/or manager
创建集群token
join-token Manage join tokens
离开集群
leave Leave the swarm unlock Unlock swarm unlock-key Manage the unlock key
更新集群
update Update the swarm
Run ‘docker swarm COMMAND —help’ for more information on a command.
<a name="IzzIU"></a>## docker swarm init 命令用法```shelldocker swarm init --helpUsage: docker swarm init [OPTIONS]Initialize a swarmOptions:# 广播地址--advertise-addr string Advertised address (format: <ip|interface>[:port])--autolock Enable manager autolocking (requiring an unlock key to start a stopped manager)--cert-expiry duration Validity period for node certificates (ns|us|ms|s|m|h) (default 2160h0m0s)--dispatcher-heartbeat duration Dispatcher heartbeat period (ns|us|ms|s|m|h) (default 5s)--external-ca external-ca Specifications of one or more certificate signing endpoints--force-new-cluster Force create a new cluster from current state--help Print usage--listen-addr node-addr Listen address (format: <ip|interface>[:port]) (default 0.0.0.0:2377)--max-snapshots uint Number of additional Raft snapshots to retain--snapshot-interval uint Number of log entries between Raft snapshots (default 10000)--task-history-limit int Task history retention limit (default 5)
实例
- 初始化集群, 并将指定的机器设置为主节点 (Manager 角色)

(上图在192.168.101.67 服务器上操作)
- 使用上图中的命令将另外机器加入到1. 步骤中初始化完毕的集群中 (Work 角色)

(上图在192.168.101.68 服务器上操作)
(上图在192.168.101.67 服务器上操作)
以worker 角色加入集群
docker swarm join-token worker
(上图在192.168.101.67 服务器上操作)4. 复制3. 步骤中的命令到另外未加入集群的服务中, 使其以work 角色加入集群<br />(上图在192.168.101.70 服务器上操作)<br /><br />(上图在192.168.101.67 服务器上操作)5. 使用docker swarm join-token manager 命令生成以manager 角色加入集群的命令, 与4. 步骤一样, 使另外一台服务器以manager 角色加入集群, 再返回到67 上查看集群成员信息<a name="LGtTM"></a>## 搭建swarm 集群的流程1. 生成主节点 (使用init 命令)1. 加入 (manager/worker)<a name="foBGR"></a># Raft 一致性算法<a name="aNPNR"></a>## 抛出问题- 集群中(现在是双主双从的模式), 假设一个节点挂了, 其他节点是否可以用?<a name="dwvhu"></a>## 定义- 保证大多数节点存活才可以用, 至少 > 1, 集群至少大于3 台<a name="ufzs7"></a>## 实验1. 将67 主节点停止 (模拟宕机), 可以发现在双主双从模式下的集群中, 另外一个节点也不能使用了<br />(上图在192.168.101.72 服务器上操作)2. 再次上线67 主节点, 可以发现leader 从67 变为了72<br />(上图在192.168.101.67 服务器上操作)3. 将70 (worker 节点) 离开集群, 可以发现在主节点的管理列表中, 该node 的status 变为down<br />(上图在192.168.101.70 服务器上操作)<br /><br />(上图在192.168.101.72 服务器上操作)4. 在任意manager 角色的节点上生成以manager 角色加入集群的命令, 然后在3. 步骤中离开集群的节点再次以manager 角色加入集群中, 可以发现该节点可以使用node ls 命令查看集群成员信息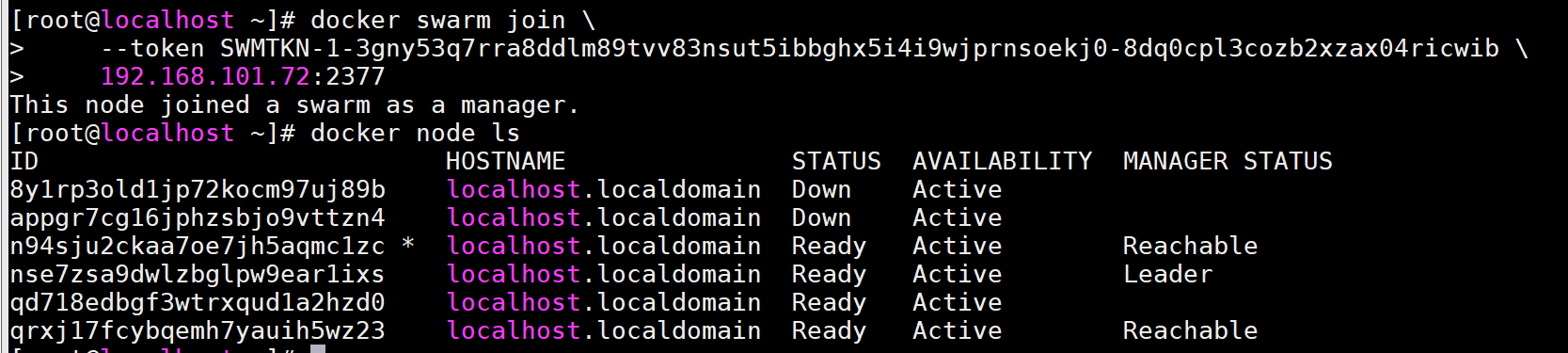5. 在67 和70 两个manager 服务器上在重复1. 步骤, 只剩下72 主节点存活, 发现72 主节点无法使用node ls 命令, 整个集群down<a name="wdKhR"></a>## 总结- 集群需要可用状态, 必须保证有3 个主节点, 其中:- 2 个主节点down, 整个集群down- 1 个主节点down, 整个集群可以继续使用- 总结成一句话: 保证大多数存活, 才可以使用<a name="ROi7G"></a># 动态扩缩容<a name="eKUej"></a>## 定义- 将容器变为了服务 (e.g. redis 服务可能有10 个副本组成, 也就是同时开启了10 个redis 容器)<a name="FGM4L"></a>## docker service 命令用法```shelldocker service --helpUsage: docker service COMMANDManage servicesOptions:--help Print usageCommands:create Create a new serviceinspect Display detailed information on one or more servicesls List servicesps List the tasks of a servicerm Remove one or more servicesscale Scale one or multiple replicated servicesupdate Update a serviceRun 'docker service COMMAND --help' for more information on a command.
体验
docker service create 命令用法
docker service create --helpUsage: docker service create [OPTIONS] IMAGE [COMMAND] [ARG...]Create a new serviceOptions:--constraint list Placement constraints (default [])--container-label list Container labels (default [])--dns list Set custom DNS servers (default [])--dns-option list Set DNS options (default [])--dns-search list Set custom DNS search domains (default [])--endpoint-mode string Endpoint mode (vip or dnsrr)#环境配置-e, --env list Set environment variables (default [])--env-file list Read in a file of environment variables (default [])--group list Set one or more supplementary user groups for the container (default [])--health-cmd string Command to run to check health--health-interval duration Time between running the check (ns|us|ms|s|m|h)--health-retries int Consecutive failures needed to report unhealthy--health-timeout duration Maximum time to allow one check to run (ns|us|ms|s|m|h)--help Print usage--host list Set one or more custom host-to-IP mappings (host:ip) (default [])--hostname string Container hostname#查看基本节点列表-l, --label list Service labels (default [])--limit-cpu decimal Limit CPUs (default 0.000)--limit-memory bytes Limit Memory (default 0 B)--log-driver string Logging driver for service--log-opt list Logging driver options (default [])--mode string Service mode (replicated or global) (default "replicated")--mount mount Attach a filesystem mount to the service--name string Service name--network list Network attachments (default [])--no-healthcheck Disable any container-specified HEALTHCHECK#查看暴露的节点端口-p, --publish port Publish a port as a node port--replicas uint Number of tasks--reserve-cpu decimal Reserve CPUs (default 0.000)--reserve-memory bytes Reserve Memory (default 0 B)--restart-condition string Restart when condition is met (none, on-failure, or any)--restart-delay duration Delay between restart attempts (ns|us|ms|s|m|h)--restart-max-attempts uint Maximum number of restarts before giving up--restart-window duration Window used to evaluate the restart policy (ns|us|ms|s|m|h)--secret secret Specify secrets to expose to the service--stop-grace-period duration Time to wait before force killing a container (ns|us|ms|s|m|h)-t, --tty Allocate a pseudo-TTY--update-delay duration Delay between updates (ns|us|ms|s|m|h) (default 0s)--update-failure-action string Action on update failure (pause|continue) (default "pause")--update-max-failure-ratio float Failure rate to tolerate during an update--update-monitor duration Duration after each task update to monitor for failure (ns|us|ms|s|m|h) (default 0s)--update-parallelism uint Maximum number of tasks updated simultaneously (0 to update all at once) (default 1)#配置用户信息-u, --user string Username or UID (format: <name|uid>[:<group|gid>])--with-registry-auth Send registry authentication details to swarm agents#配置工作目录-w, --workdir string Working directory inside the container
- 实例:
- 启动自定义的nginx 服务

- 根据服务名查看正在运行的nginx 服务

- 查看正在运行的nginx 服务的具体信息
docker service inspect mynginx[{"ID": "ljlbfk4122sy3cfczmzbjv6k7","Version": {"Index": 29},"CreatedAt": "2022-02-07T11:52:41.695689971Z","UpdatedAt": "2022-02-07T11:52:41.699705732Z","Spec": {"Name": "mynginx","TaskTemplate": {"ContainerSpec": {"Image": "nginx:latest@sha256:0d17b565c37bcbd895e9d92315a05c1c3c9a29f762b011a10c54a66cd53c9b31","DNSConfig": {}},"Resources": {"Limits": {},"Reservations": {}},"RestartPolicy": {"Condition": "any","MaxAttempts": 0},"Placement": {},"ForceUpdate": 0},"Mode": {"Replicated": {"Replicas": 1}},"UpdateConfig": {"Parallelism": 1,"FailureAction": "pause","MaxFailureRatio": 0},"EndpointSpec": {"Mode": "vip","Ports": [{"Protocol": "tcp","TargetPort": 80,"PublishedPort": 8888,"PublishMode": "ingress"}]}},"Endpoint": {"Spec": {"Mode": "vip","Ports": [{"Protocol": "tcp","TargetPort": 80,"PublishedPort": 8888,"PublishMode": "ingress"}]},"Ports": [{"Protocol": "tcp","TargetPort": 80,"PublishedPort": 8888,"PublishMode": "ingress"}],"VirtualIPs": [{"NetworkID": "r6t241jfgja5jndllate9em8s","Addr": "10.255.0.6/16"}]},"UpdateStatus": {"StartedAt": "0001-01-01T00:00:00Z","CompletedAt": "0001-01-01T00:00:00Z"}}]
查看正在运行的所有服务
docker service lsID NAME MODE REPLICAS IMAGEljlbfk4122sy mynginx replicated 1/1 nginx:latest
使用update 命令增加nginx 副本数

- 在任意的manager 节点上查看nginx 的分布情况

(主节点1)
(主节点2)
- 访问测试:

(上图访问了没有在该机器上运行自定义nginx service 的8888 端口)
(上图可以看出该机器没有运行nginx 容器, 但是由于在同一个swarm 集群中, 同样可以访问到)
再次动态扩缩容:
docker service update --replicas 10 mynginx
再次查看每个主节点中的容器使用情况

- 缩容

docker service scale 命令用法
docker service scale --helpUsage: docker service scale SERVICE=REPLICAS [SERVICE=REPLICAS...]Scale one or multiple replicated servicesOptions:--help Print usage
- 实例:
- 将mynginx 副本数扩容到5

docker service rm 命令用法
docker service rm --helpUsage: docker service rm SERVICE [SERVICE...]Remove one or more servicesAliases:rm, removeOptions:--help Print usage
- 实例:
- 将mynginx 服务移除

与docker run 的区别
- docker run 无扩缩容功能
- docker service 具有扩缩容功能, 滚动更新, 灰度发布功能
概念总结
- swarm
- 集群的管理和编号, docker 可以初始化一个swarm 集群, 其他节点可以加入 (manager, worker)
- node
- 就是一个docker 节点, 多个节点就组成了一个网络集群 (manager, worker)
- service
- 任务, 可以在管理节点或者工作节点来运行, 核心
- Task
- 容器内的命令, 细节任务



若有收获,就点个赞吧
0 人点赞
