首先是理解为什么会有回声:以手机端为例,当通话时,本地麦克风会拾取到本地扬声器所播放出的音频信号(对方所说的话),再传输给对方,这样对方能再次听到自己的声音,这个就是声学上的回声。如下图所示: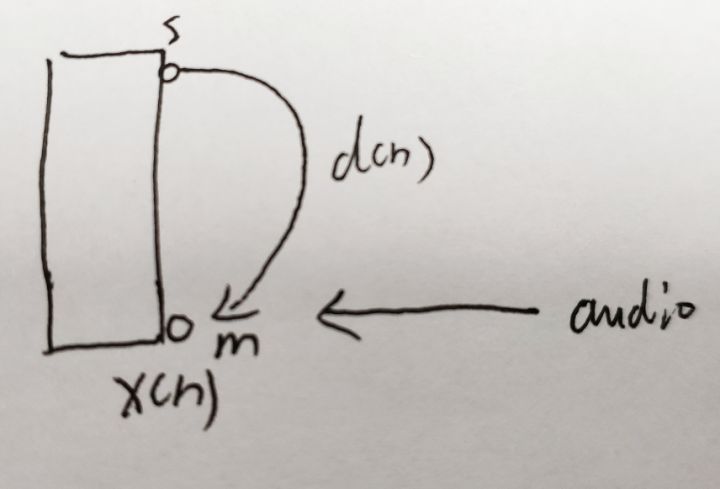 s表示speaker扬声器,m表示麦克风,d(n)表示回声,x(n)表示麦克风采集到的声音
s表示speaker扬声器,m表示麦克风,d(n)表示回声,x(n)表示麦克风采集到的声音
在设计算法处理回声时,我们有两个重要信息:一个是上图所示的d(n),即本地扬声器播放出的音频信号,还要一个x(n),即本地麦克风拾取到的音频信号。
有了上述两点非常重要的信号,我们可以采取自适应滤波器去学习d(n)是如何到达m点(麦克风)处,即传输函数,然后在本地麦克风减去d(n)卷积传输函数后的信号。核心点在于采用自适应滤波器学习d(n)如何到达本地麦克风的。
WebRtc就是采用上述思路做的:第一部分采用基于NLMS的自适应滤波器学习回声路径,并消除掉回声;第二部分采用相关性对残留回声进行进一步的消除。
在WebRTC应用开发中,我们可能需要知道某个通话过程中是否有回音产生,传统的做法是通过人工去听才能知道。从WebRTC56版本开始,WebRTC提供了一个接口可以让我们知道是否有回音。
有两个办法可以观察,一是如果是使用网页版本的WebRTC,你可以在浏览器中输入chrome://webrtc-internals,在打开的网页中关于音频的统计项目中有googResidualEchoLikelihood这一项,googResidualEchoLikelihood取值范围是0~1,0代表完全没有回音,1代表回音特别大。一般这个值超过0.5代表人耳可以很明显的听出有回音了。另外一种方法是调用GetStats接口拿到这个值,这样你就可以你在的应用中提示用户有没有回音了。另外一个相关联的值是googResidualEchoLikelihoodRecentMax,这个代表前10秒内回音的最大值
本文先讲第一部分:基于NLMS框架的自适应滤波器,即线性部分。
整体代码我有,有兴趣的小伙伴可以私聊,私发。这里讲解第一部分的代码。

第一步:
N表示频点数,即一帧多少点;M表示帧数,即每次保留多少帧的数据。我做的是128x12的矩阵,即保留12帧(128x12)的数据,近乎保留100ms的数据。所以我的处理矩阵是 128x12的矩阵。
xx和XX分别是远端(本地扬声器所播放的信号)的时域和频域数据,频域的话要保留 直流分量,所以大小是 1291的长度。
dd和DD分别是*近端(本地麦克风拾取到的信号)的时域和频域数据。
将两帧的语音信号拼接起来,这是一个利用FFT加速线性卷积操作,将两个长短不一的线性卷积拼接在一起,再FFT,overlap-save的方法加速。
框图大致如下: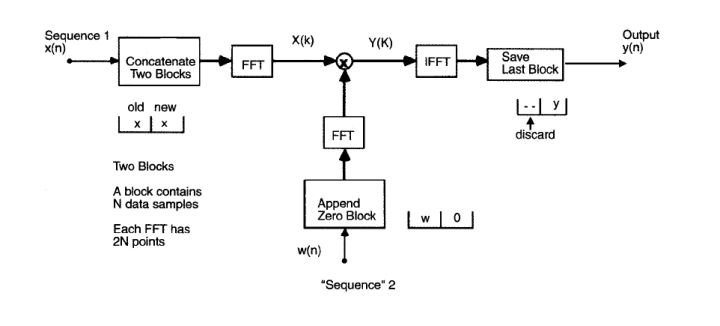
第二步:滤波
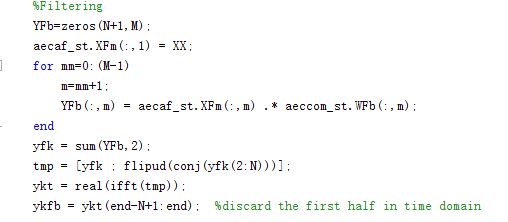
YFb是一个129*12的输出矩阵,129是因为要保留一点直流分量,所以频点数是 128+1。XFm是输入的远端频域信号。WFb是滤波器学习到的频域上的回声路径,对每一帧都进行频域相乘,即频域上远端信号乘以学习到的频域回声路径,实现时域上 远端信号与回声路径的卷积操作。因为是overlap-save加速线性卷积的方法,转到时域后需要丢弃前一半的信号。
此时 YFb是频域上,滤波器学习到的,从远端信号经过回声路径后到达近端时的频域信号,即近端处的回声。
而ykfb则是对帧求和后,近端处的回声时域信号。
第三步:误差估计
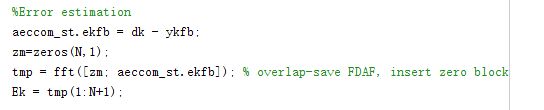
误差估计,在时域上对近端和学习到的回声信号进行求差,这里也是一个overlap-save加速线性卷积的方法,补上一半零后再做FFT。Ek则是频域上的误差信号。
第四步:自适应更新回声路径

pn0为远端信号的频域功率谱,alp为平滑系数。Ek2是频域上的归一化误差。
mEk是乘以一个学习步长的误差参数。
PP是远端信号乘以误差的参数,最后转换到频域 FPH,即滤波器的更新参数
最后将滤波器WFb加上这一帧更新的滤波器系数,为新滤波器系数。
滤波器更新可以参考NLMS,基本框架如下: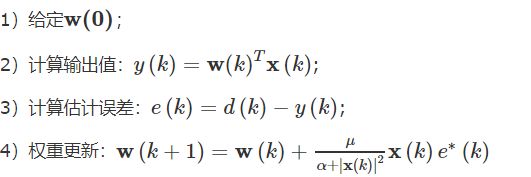
至此,基于WebRtc的声学回声消除的线性部分(滤波器部分)基本讲完了,核心就是设计一个自适应滤波器,学习回声路径,然后在近端减去远端卷积回声路径后的信号,即完成回声消除。

若有收获,就点个赞吧
0 人点赞
