- 1、索引的设计原则
- 2、Bean的什么周期
- 3、索引的结构和各自的优缺点
- 4、Mysql锁的类型
- 5、Mysql执行计划
- 6、事务的基本特效和隔离级别
- 7、隔离级别
- 8、ACID是如何保证的
- 9、Mysql主从同步原理
- 10、MylSAM和InnerDb的区别
- 11、常见的索引类型
12、RDB AOF- 13、缓存过期策略
- 14、缓存穿透,缓存击穿,缓存雪崩
- 15、redis 事务
- 16、redis集群方案
- 17.锁的分类实现
- 18、ConcurrentHashMap 原理
- 19、线程池状态
- 20、Redis 同步机制
- 21、 BgSave原理
22、redis淘汰策略">
22、redis淘汰策略- 23、Redis keys和Scan
24、 Redis集群搭建 Redis cluster">
24、 Redis集群搭建 Redis cluster
25、ElasticSearch 和集群">
25、ElasticSearch 和集群- 26 、 RabbitMq 集群
1、索引的设计原则
| 1、选择唯一索引 |
|---|
| 2、选择重复性低的数据 |
| 3、为需要排序,分组,联合操作的使用 |
| 4.限制索数目,并非越多越好,索引本身占空间 |
| 5、数据量小的表不需要索引 |
| 6、删除非必须索引 |
| 7、尽量使用前缀索引 |
1.1、Java死锁如何避免?
造成死锁的⼏个原因:1. ⼀个资源每次只能被⼀个线程使⽤2. ⼀个线程在阻塞等待某个资源时,不释放已占有资源3. ⼀个线程已经获得的资源,在未使⽤完之前,不能被强⾏剥夺4. 若⼲线程形成头尾相接的循环等待资源关系
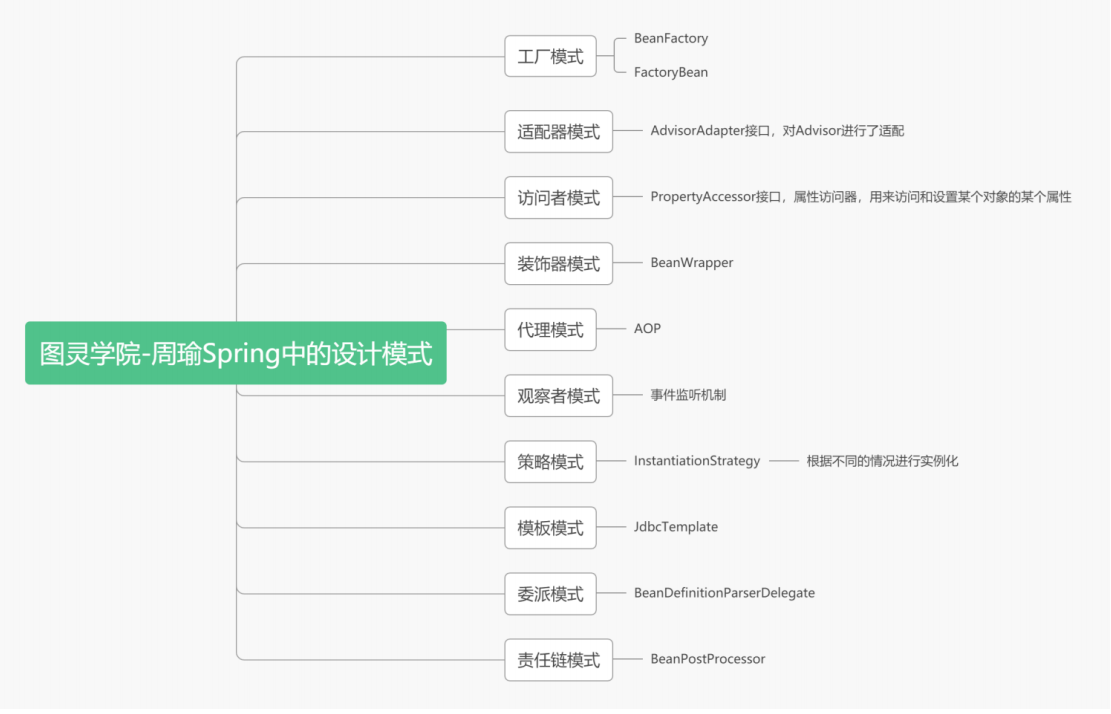
1.2、Spring设计模式
2、Bean的什么周期
| 1、BeanDefinition的加载 |
|---|
| 2、构造函数加载 |
| 3、Setter属性注入 |
| 4、Aware的方法回调 |
| 5、初始化之前BeanPostProcess |
| 6、初始化 |
| 7、初始化后BeanPostProcess |
| 8、shiyongBean |
2.1、 对象在三级缓存中的迁移
A/B 两对象在三级缓存中的迁移说明
A创建过程中需要B,于是A将自己放到三级缓存里面,去实例化B
B实例化的时候发现需要A,于是B先查一级缓存,没有,再查二级缓存,还是没有,再查三级缓存,找到了A,然后把三级缓存里面的这个A放到二级缓存里面,并删除三级缓存里面的A
B顺利初始化完毕,将自己放到一级缓存里面(此时B里面的A依然是创建中状态),然后回来接着创建A,此时B已经创建结束,直接从一级缓存里面拿到B,然后完成创建,并将A自己放到一级缓存里面。
2.2、三级缓存
第一级缓存:存放的是已经初始化好了的Bean,bean名称与bean实例相对应,即所谓的单例池。表示已经经历了完整生命周期的Bean对象第一级缓存:存放的是实例化了,但是未初始化的Bean,bean名称与bean实例相对应。表示Bean的生命周期还没走完(Bean的属性还未填充)就把这个Bean存入该缓存中。也就是实例化但未初始化的bean放入该缓存里第三级缓存:表示存放生成bean的工厂,存放的是FactoryBean,bean名称与bean工厂对应。假如A类实现了FactoryBean,那么依赖注入的时候不是A类,而是A类产生的Bean
2.3、四大方法
getSingleton():从容器里面获得单例的bean,没有的话则会创建 beandoCreateBean():执行创建 bean 的操作(在 Spring 中以 do 开头的方法都是干实事的方法)populateBean():创建完 bean 之后,对 bean 的属性进行填充addSingleton():bean 初始化完成之后,添加到单例容器池中,下次执行 getSingleton() 方法时就能获取到
3、索引的结构和各自的优缺点
1、hash索引,适合单条的查询读取2、B+tree 是平衡二叉树,索引复杂度不会剧烈波动,查询速度快
4、Mysql锁的类型
行锁,表锁,页锁(一组记录),记录锁(锁一行,精准索引,精准命中),间隙锁(锁住一个区间,锁住空隙-左开右闭),临建锁(间隙锁和记录所的集合 一行+左开右闭)意向共享锁:当一个事务对整个表加共享锁之前,先获取这个表的意向共享锁(加快效率,提前获知有锁)。意向排它锁:当一个事务对整个表加排它锁之前,先获取这个表的意向排它锁(加快效率,提前获知有锁)。
5、Mysql执行计划
5.1 Mysql 语句执行顺序
FROM->ON->WHERE->GROUP_BY->HAVING->SELECT->DISTINCT->ORDER_BY->LIMIT
5.2 Explain
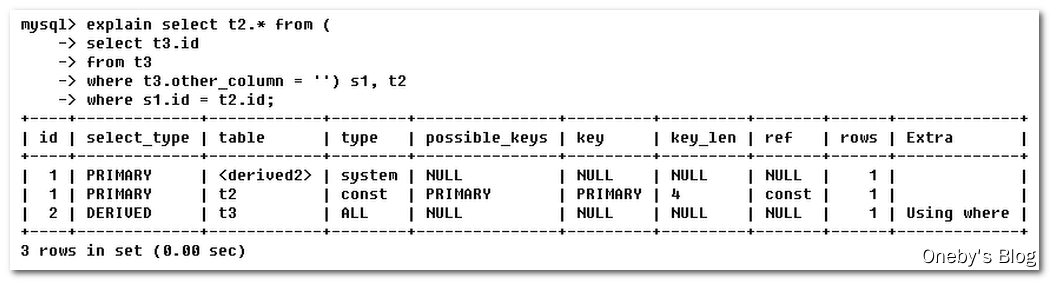
1、Select_type 类型
SIMPLE:简单的select查询,查询中不包含子查询或者UNIONPRIMARY:查询中若包含任何复杂的子部分,最外层查询则被标记为PRIMARYSUBQUERY:在SELECT或者WHERE列表中包含了子查询DERIVED:在FROM列表中包含的子查询被标记为DERIVED(衍生)MySQL会递归执行这些子查询,把结果放在临时表里UNION:若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVEDUNION RESULT:从UNION表获取结果的SELECT
2、Type
type显示的是访问类型,是较为重要的一个指标,结果值从最好到最坏依次是:system>const>eq_ref>ref>fultext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>ALL挑重要的来说:system>const>eq_ref>ref>range>index>ALL,一般来说,得保证查询至少达到range级别,最好能达到ref。eq_ref:唯一性索引,对于每个索引键,表中只有一条记录与之匹配,常见于主键或唯一索引扫描ref:非唯一索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引一般就是在你的where语句中出现了between、<、>、in等的查询这种范围扫描索引扫描比全表扫描要好,因为他只需要开始索引的某一点,而结束于另一点,不用扫描全部索引index:Full Index Scan,index与ALL区别为index类型只遍历索引树。这通常比ALL快,因为索引文件通常比数据文件小。(也就是说虽然all和index都是读全表,但index是从索引中读取的,而all是从硬盘数据库文件中读的)all:FullTable Scan,将遍历全表以找到匹配的行(全表扫描)
3、 Key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好key_len显示的值为索引最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的
4、Extra:包含不适合在其他列中显示但十分重要的额外信息
| Using filesort | - MySQL中无法利用索引完成排序操作成为“文件排序” - 出现 Using filesort 不好(九死一生),需要尽快优化 SQL |
|---|---|
| Using temporary | - 使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by - 出现 Using temporary 超级不好(十死无生),需要立即优化 SQL |
| Using index | - 表示相应的select操作中使用了覆盖索引(Coveing Index),避免访问了表的数据行,效率不错! - 如果同时出现using where,表明索引被用来执行索引键值的查找 - 如果没有同时出现using where,表明索引用来读取数据而非执行查找动作 |
| Using where | 表明使用了where过滤 |
| Using join buffer | 表明使用了连接缓存 |
| impossible where | where子句的值总是false,不能用来获取任何元组 |
| select tables optimized away | 在没有GROUPBY子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。 |
| distinct | 优化distinct,在找到第一匹配的元组后即停止找同样值的工作 |
5.3 数据库三范式
| 1、第一范式:数据库字段不可再分,每个字段单独属性 |
|---|
| 2、第二范式:数据表只存一种数据 |
| 3、第三范式:需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。 |
5.4 DDL DML DCL TCL
| DDL 数据定义语言,CREATE,COMMENT,ALTER |
|---|
| DML 是数据操纵语言,SELECT、INSERT、UPDATE、DELETE、GROUP BY、HAVING |
| DCL是数据控制语言(Data Control Language)的简称, 它包含诸如GRANT之类的命令,并且主要涉及数据库系统的权限,权限和其他控件。 |
| TCL是事务控制语言(Transaction Control Language)的简称, 用于处理数据库中的事务 COMMIT:提交事务 ROLLBACK:在发生任何错误的情况下回滚事务 |
6、事务的基本特效和隔离级别
1、原子性(atomicity)一个事务要么全部提交成功,要么全部失败回滚,不能只执行其中的一部分操作,这就是事务的原子性2、一致性(consistency)事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态。如果数据库系统在运行过程中发生故障,有些事务尚未完成就被迫中断,这些未完成的事务对数据库所作的修改有一部分已写入物理数据库,这是数据库就处于一种不正确的状态,也就是不一致的状态3、隔离性(isolation)4、持久性(Druid)
7、隔离级别
读未提交READ_UNCONMIT(脏读 读取到其他事务未提交的数据)读已提交READ_CONMIT可重复度REPEATED_READ(幻读 一个事务多次读取的值(前后读取不一致)不一致)串行化SERIAL
8、ACID是如何保证的
InnerDBA: UndoLog 保证原子性 记录胡衮的信息C: 由其他三个特效保证I: MVCC 多版本并发控制,存在于READ_COMMIT REPEATED_READ,聚镞索引trx_ID 每次事务执行的ID,rpll_pointer每次对聚镞索引修改都会把数据记录到UndoLog中,Roll_pointer就是上一个版本的指针,read_view 是活动事务的ID集合(排序数组)。访问数据的时候,聚镞索引先获取自己事务的ID,对比read_view,若果在左边正常执行不影响,在右边(创建Read_view之后才生产的事务Id)或者在read_view中间(事务未提交),代表不可访问,取出roll_pointer,访问上一次版本数据。已提交读:read_view策略 每次都会创建一个Read_view 多次读取的Read_view不一样。重复读取的话会导致读取的数据是另外一个事务的数据导致出错。可重复度:read_view策略 第一次访问创建Read_view ,所以可以找到上一次的roll_pointerD: redo-log+内存操作修改会
1、2PC 3PC TCC TM
XA规范:分布式事务规范,定义了分布式事务模型四个角色:事务管理器(协调者TM)、资源管理器(参与者RM),应用程序AP,通信资源管理器CRM全局事务:一个横跨多个数据库的事务,要么全部提交、要么全部回滚JTA事务时java对XA规范的实现,对应JDBC的单库事务#2PC第一阶段( prepare ) :每个参与者执行本地事务但不提交,进入 ready 状态,并通知协调者已经准备就绪。setnx 问题:1、早期版本没有超时参数,需要单独设置,存在死锁问题(中途宕机) 2、后期版本提供加锁与设置时间原子操作,但是存在任务超时,锁自动释放,导致并发问题,加锁与释 放锁不是同一线程问题第二阶段( commit ) 当协调者确认每个参与者都 ready 后,通知参与者进行 commit 操作;如果有参与者 fail ,则发送 rollback 命令,各参与者做回滚。问题:单点故障:一旦事务管理器出现故障,整个系统不可用(参与者都会阻塞住)数据不一致:在阶段二,如果事务管理器只发送了部分 commit 消息,此时网络发生异常,那么只有部分参与者接收到 commit 消息,也就是说只有部分参与者提交了事务,使得系统数据不一致。响应时间较长:参与者和协调者资源都被锁住,提交或者回滚之后才能释放不确定性:当协事务管理器发送 commit 之后,并且此时只有一个参与者收到了 commit,那么当该参与者与事务管理器同时宕机之后,重新选举的事务管理器无法确定该条消息是否提交成功。#3PC第一阶段:CanCommit阶段,协调者询问事务参与者,是否有能力完成此次事务。如果都返回yes,则进入第二阶段有一个返回no或等待响应超时,则中断事务,并向所有参与者发送abort请求第二阶段:PreCommit阶段,此时协调者会向所有的参与者发送PreCommit请求,参与者收到后开始执行事务操作。参与者执行完事务操作后(此时属于未提交事务的状态),就会向协调者反馈“Ack”表示我已经准备好提交了,并等待协调者的下一步指令。第三阶段:DoCommit阶段, 在阶段二中如果所有的参与者节点都返回了Ack,那么协调者就会从“预提交状态”转变为“提交状态”。然后向所有的参与者节点发送"doCommit"请求,参与者节点在收到提交请求后就会各自执行事务提交操作,并向协调者节点反馈“Ack”消息,协调者收到所有参与者的Ack消息后完成事务。 相反,如果有一个参与者节点未完成PreCommit的反馈或者反馈超时,那么协调者都会向所有的参与者节点发送abort请求,从而中断事务。#TCCTCC(补偿事务):Try、Confirm、Cancel
2、Innodb是如何实现事务的
Innodb通过Buffer Pool,LogBuffer,Redo Log,Undo Log来实现事务,以⼀个update语句为例:1. Innodb在收到⼀个update语句后,会先根据条件找到数据所在的⻚,并将该⻚缓存在Buffer Pool中2. 执⾏update语句,修改Buffer Pool中的数据,也就是内存中的数据3. 针对update语句⽣成⼀个RedoLog对象,并存⼊LogBuffer中4. 针对update语句⽣成undolog⽇志,⽤于事务回滚5. 如果事务提交,那么则把RedoLog对象进⾏持久化,后续还有其他机制将Buffer Pool中所修改的数据⻚持久化到磁盘中6. 如果事务回滚,则利⽤undolog⽇志进⾏回滚
9、Mysql主从同步原理
1.主节点生成BinLog,数据更好修改binlog2.主节点binlog变动,会通过log dump线程会通知从节点3.从节点读取binlog到relayLog4.从节点sql线程读取日志保证数据最终一致性增量同步binlog+positonPoint全同步复制:等从节点完成之后才会完成同步。半同步复制:从库写入完成之后ACK主库告知主库已经同步完成
10、MylSAM和InnerDb的区别
MylSAM:不支持事务,表级锁,总行数。文件结构:索引文件,表结构文件,表数据,非聚镞索引。InnerDB:支持事务,标记锁,不支持总行数。支持ACID和事务隔离级别,聚镞索引(数据和索引在一起)。
11、常见的索引类型
| 1、普通索引 允许包含同样的值 |
|---|
| 2、唯一索引 3、主键 |
| 4、联合索引 |
| 5、全文索引 |
12、RDB AOF
RDB FORK子进程同步,安全数据不会丢。同步测量(每秒同步,修改同步,不同步)AOP Append Only File 日志文件形式增量修改,文件大性能消耗多(redis-check-AOP修复AOF文件),定期rewrite 压缩AOF文件,数据多时候,启动很慢
13、缓存过期策略
1.惰性过期 访问时检查2.定期过期 每隔一段时间扫描清除数据3.定时过期(redis未采用)
14、缓存穿透,缓存击穿,缓存雪崩
1.缓存穿透 :数据为null 打入数据库。解决:布隆过滤器所有不存在的数据就会访问不到。2.缓存击穿: 缓存过期,大量的请求打到一个点,锁和热点永不过期3.缓存雪崩: 大量的key失效,请求打到数据库大量请求,随机过期时间,锁,缓存预热
15、redis 事务
Watch(CAS)Mutilexec。。。UnMutilUnWatch1.事务开始->命令入队->事务执行
16、redis集群方案
1.主从

2.redisCluster

3.sharding

5、Redis集群策略
Redis提供了三种集群策略:1. 主从模式:这种模式⽐较简单,主库可以读写,并且会和从库进⾏数据同步,这种模式下,客户端直接连主库或某个从库,但是但主库或从库宕机后,客户端需要⼿动修改IP,另外,这种模式也⽐较难进⾏扩容,整个集群所能存储的数据受到某台机器的内存容量,所以不可能⽀持特⼤数据量2. 哨兵模式:这种模式在主从的基础上新增了哨兵节点,但主库节点宕机后,哨兵会发现主库节点宕机,然后在从库中选择⼀个库作为进的主库,另外哨兵也可以做集群,从⽽可以保证但某⼀个哨兵节点宕机后,还有其他哨兵节点可以继续⼯作,这种模式可以⽐较好的保证Redis集群的⾼可⽤,但是仍然不能很好的解决Redis的容量上限问题。3. Redis Cluster模式:Cluster模式是⽤得⽐较多的模式,它⽀持多主多从,这种模式会按照key进⾏槽位的分配,可以使得不同的key分散到不同的主节点上,利⽤这种模式可以使得整个集群⽀持更⼤的数据容量,同时每个主节点可以拥有⾃⼰的多个从节点,如果该主节点宕机,会从它的从节点中选举⼀个新的主节点。对于这三种模式,如果Redis要存的数据量不⼤,可以选择哨兵模式,如果Redis要存的数据量⼤,并且需要持续的扩容,那么选择Cluster模式。
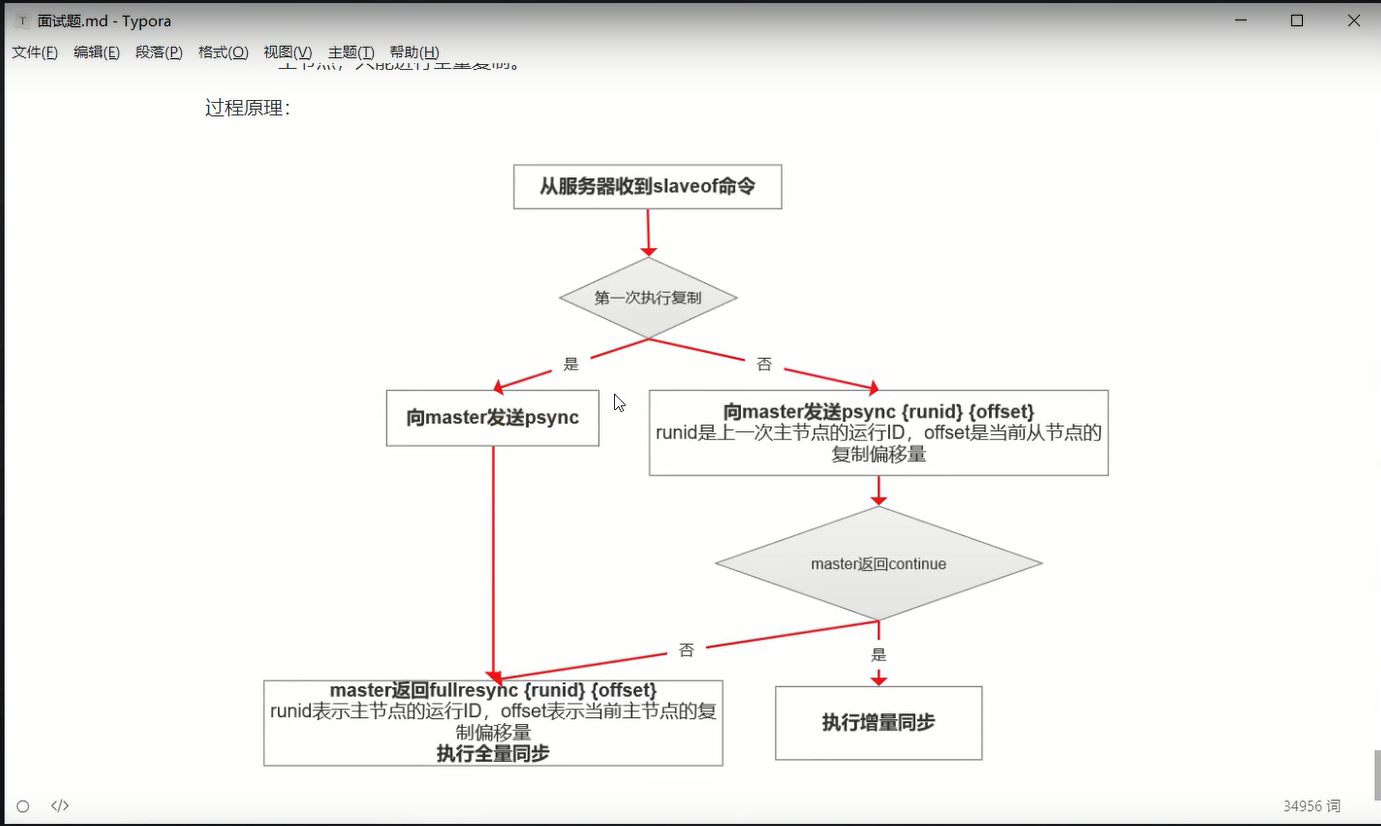
4、redis 主从复制的原理
17.锁的分类实现
1、分类(1)乐观锁/悲观锁(2)独享锁/共享锁(3)互斥锁/读写锁(4)可重入锁(5)公平锁/非公平锁(6)分段锁(7)偏向锁/轻量级锁/重量级锁(8)自旋锁
18、ConcurrentHashMap 原理
JDK1.7 中的 ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成,即 ConcurrentHashMap 把哈希桶数组切分成小数组(Segment ),每个小数组有 n 个 HashEntry 组成。Segment 继承了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。Segment 默认为 16,也就是并发度为 16。存放元素的 HashEntry,也是一个静态内部类。
在数据结构上, JDK1.8 中的ConcurrentHashMap 选择了与 HashMap 相同的Node数组+链表+红黑树结构;在锁的实现上,抛弃了原有的 Segment 分段锁,采用CAS + synchronized实现更加细粒度的锁。
将锁的级别控制在了更细粒度的哈希桶数组元素级别,也就是说只需要锁住这个链表头节点(红黑树的根节点),就不会影响其他的哈希桶数组元素的读写,大大提高了并发度。
19、线程池状态
| RUNNING,指的是线程池的初始化状态,可添加待执行的任务。 |
|---|
| SHUTDOWN,指的是线程池处于待关闭状态,不接收新任务,仅处理已接收的任务。 |
| STOP,指的是线程池立即关闭,不接收新的任务,放弃缓存队列中的任务并且中断正在处理的任务。 |
| TIDYING,指的是线程池自主整理状态,我们可以调用 terminated() 方法进行线程池整理。 |
| TERMINATED,指的是线程池终止状态。 |
20、Redis 同步机制
Redis可以使用主从同步,从从同步。第一次同步时,主节点做一次bgsave,并同时将后续修改操作记录到内存buffer,待完成后将rdb文件全量同步到复制节点,复制节点接受完成后将rdb镜像加载到内存。
21、 BgSave原理
fork 和 cow 。fork 是指 Redis 通过创建子进程来进行 bgsave 操作。cow 指的是 copy on write ,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。这里 bgsave 操作后,会产生 RDB 快照文件。
22、redis淘汰策略
1.noeviction:返回错误当内存限制达到,并且客户端尝试执行会让更多内存被使用的命令。2.allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。3.volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。4.allkeys-random: 回收随机的键使得新添加的数据有空间存放。5.volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。6.volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。总结就是:直接报错,AllKey LRU,近期key LRU,Allkeys Radom,近期key Radom ,快过期键回收
23、Redis keys和Scan
假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某个固定的已知的前缀开头的,如果将它们全部找出来?使用 keys 指令可以扫出指定模式的 key 列表。如果这个 Redis 正在给线上的业务提供服务,那使用 keys 指令会有什么问题?Redis 的单线程的。keys 指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用 scan 指令,scan 指令可以无阻塞的提取出指定模式的 key 列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用 keys 指令长
24、 Redis集群搭建 Redis cluster
#创建多个redis实例for port in $(seq 7001 7006); \do \mkdir -p /mydata/redis/node-${port}/conftouch /mydata/redis/node-${port}/conf/redis.confcat << EOF > /mydata/redis/node-${port}/conf/redis.confport ${port}cluster-enabled yescluster-config-file nodes.confcluster-node-timeout 5000cluster-announce-ip 10.0.4.10cluster-announce-port ${port}cluster-announce-bus-port 1${port}appendonly yesEOFdocker run -p ${port}:${port} -p 1${port}:1${port} --name redis-${port} \-v /mydata/redis/node-${port}/data:/data \-v /mydata/redis/node-${port}/conf/redis.conf:/etc/redis/redis.conf \-d redis redis-server /etc/redis/redis.conf; \done#进入一个容器docker exec -it redis-7001 bash#创建主从redis-cli --cluster create 10.0.4.10:7001 10.0.4.10:7002 10.0.4.10:7003 10.0.4.10:7004 10.0.4.10:7005 10.0.4.10:7006 --cluster-replicas 1#已集群方式连接redisredis-cli -c -h 10.0.4.10 -p 7001#运行效果root@03a435032acd:/data# redis-cli -c -h 10.0.4.10 -p 700110.0.4.10:7001> set name xuwei-> Redirected to slot [5798] located at 10.0.4.10:7002OK10.0.4.10:7002> set a aaa-> Redirected to slot [15495] located at 10.0.4.10:7003OK10.0.4.10:7003> keys(error) ERR wrong number of arguments for 'keys' command10.0.4.10:7003> keys *1) "a"10.0.4.10:7003> get a"aaa"10.0.4.10:7003> get name-> Redirected to slot [5798] located at 10.0.4.10:7002"xuwei"#删除docker rm -f redis-7001 redis-7002 redis-7003 redis-7004 redis-7005 redis-7006#查询集群状态10.0.4.10:7002> cluster infocluster_state:okcluster_slots_assigned:16384cluster_slots_ok:16384cluster_slots_pfail:0cluster_slots_fail:0cluster_known_nodes:6cluster_size:3cluster_current_epoch:6cluster_my_epoch:2cluster_stats_messages_ping_sent:2315cluster_stats_messages_pong_sent:2306cluster_stats_messages_meet_sent:1cluster_stats_messages_sent:4622cluster_stats_messages_ping_received:2306cluster_stats_messages_pong_received:2316cluster_stats_messages_received:4622
25、ElasticSearch 和集群
#分词器 IK HanLPhttps://www.hanlp.com/
1、Elasticsearch 搜索的过程
搜索拆解为“query then fetch” 两个阶段。query 阶段的目的:定位到位置,但不取。步骤拆解如下:1、假设一个索引数据有 5 主+1 副本 共 10 分片,一次请求会命中(主或者副本分片中)的一个。2、每个分片在本地进行查询,结果返回到本地有序的优先队列中。3、第 (2)步骤的结果发送到协调节点,协调节点产生一个全局的排序列表。fetch 阶段的目的:取数据。路由节点获取所有文档,返回给客户端。
2、Elasticsearch 索引文档过程(存入)
1、客户写集群某节点写入数据,发送请求。2、节点接收到请求,根据id算出分片位置,把请求转发给此节点3、干活节点执行写操作,并行转发请求到写入节点(包含它的副本节点),等待执行成功,成功通知主节点。第二步中的文档获取分片的过程?回答:借助路由算法获取,路由算法就是根据路由和文档 id 计算目标的分片 id 的过程。1shard = hash(_routing) % (num_of_primary_shards)
3、elasticsearch-全文检索执行流程
elasticsearch-全文检索执行流程检查字段类型 。标题 title 字段是一个 string 类型( analyzed )已分析的全文字段,这意味着查询字符串本身也应该被分析。分析查询字符串 。将查询的字符串 QUICK! 传入标准分析器中,输出的结果是单个项 quick 。因为只有一个单词项,所以 match 查询执行的是单个底层 term 查询。查找匹配文档 。用 term 查询在倒排索引中查找 quick 然后获取一组包含该项的文档,本例的结果是文档:1、2 和 3 。为每个文档评分 。用 term 查询计算每个文档相关度评分 _score ,这是种将 词频(term frequency,即词 quick 在相关文档的 title 字段中出现的频率)和反向文档频率(inverse document frequency,即词 quick 在所有文档的 title 字段中出现的频率),以及字段的长度(即字段越短相关度越高)相结合的计算方式。参见 相关性的介绍 。
主节点:node.master:true 标志节点可以被作为主节点。集群问题:(1)脑裂问题:加入十个节点网络故障 七个一组,三个一组 会形成两个集群(2)一个集群有一个主节点,负责集群的调度任务。(正常不把主节点作为数据节点,Node.master:false)(3)客户端节点,负责集群的负载均衡策略,负责请求的分发汇总。(node.master:false,node.data:false)脑裂问题解决方案(老版本):(1)角色分离: 主节点不承担数据节点功能,降低它的工作负载。(2)减少误判: 主节点默认是三秒无响应认为宕机,可以设置长一点(discovery.zen.ping_timeout:5)(3) 选举触发: discovery.zen.minimum_master_nodes:6 假如有十个节点,设置为6 表示必须有六个节点没宕机才能选举新的节点。(建议候选节点数/2)+1) 禁止小集群诞生集群搭建:(1) 创建docker 网络docker network create --driver bridge --subnet=172.18.12.0/16 --gateway=172.18.1.1 mynet(2) 查看网络详情docker network inspect mynet
for port in $(seq 1 3); \do \mkdir -p /mydata/elasticsearch/master-${port}/configmkdir -p /mydata/elasticsearch/master-${port}/datachmod -R 777 /mydata/elasticsearch/master-${port}cat << EOF > /mydata/elasticsearch/master-${port}/config/elasticsearch.ymlcluster.name: my-es #集群的名称,同一个集群该值必须设置成相同的node.name: es-master-${port} #该节点的名字node.master: true #该节点有机会成为master节点node.data: false #该节点可以存储数据network.host: 0.0.0.0http.host: 0.0.0.0 #所有http均可访问http.port: 920${port}transport.tcp.port: 930${port}discovery.zen.ping_timeout: 10s #设置集群中自动发现其他节点时ping连接的超时时间discovery.seed_hosts: ["172.18.1.21:9301","172.18.1.22:9302","172.18.1.23:9303"]cluster.initial_master_nodes: ["172.18.1.21"] #新集群初始时的候选主节点,es7的新增配置EOFdocker run --name elasticsearch-node-${port} \-p 920${port}:920${port} -p 930${port}:930${port} \--network=mynet --ip 172.18.1.2${port} \-e ES_JAVA_OPTS="-Xms300m -Xmx300m" \-v /mydata/elasticsearch/master-${port}/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \-v /mydata/elasticsearch/master-${port}/data:/usr/share/elasticsearch/data \-v /mydata/elasticsearch/master-${port}/plugins:/usr/share/elasticsearch/plugins \-d elasticsearch:7.6.2donefor port in $(seq 4 6); \do \mkdir -p /mydata/elasticsearch/master-${port}/configmkdir -p /mydata/elasticsearch/master-${port}/datachmod -R 777 /mydata/elasticsearch/master-${port}cat << EOF > /mydata/elasticsearch/master-${port}/config/elasticsearch.ymlcluster.name: my-es #集群的名称,同一个集群该值必须设置成相同的node.name: es-node-${port} #该节点的名字node.master: false #该节点有机会成为master节点node.data: true #该节点可以存储数据network.host: 0.0.0.0http.host: 0.0.0.0 #所有http均可访问http.port: 920${port}transport.tcp.port: 930${port}discovery.zen.ping_timeout: 10s #设置集群中自动发现其他节点时ping连接的超时时间discovery.seed_hosts: ["172.18.1.21:9301","172.18.1.22:9302","172.18.1.23:9303"]cluster.initial_master_nodes: ["172.18.1.21"] #新集群初始时的候选主节点,es7的新增配置EOFdocker run --name elasticsearch-node-${port} \-p 920${port}:920${port} -p 930${port}:930${port} \--network=mynet --ip 172.18.1.2${port} \-e ES_JAVA_OPTS="-Xms300m -Xmx300m" \-v /mydata/elasticsearch/master-${port}/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \-v /mydata/elasticsearch/master-${port}/data:/usr/share/elasticsearch/data \-v /mydata/elasticsearch/master-${port}/plugins:/usr/share/elasticsearch/plugins \-d elasticsearch:7.6.2done#查看集群状态http://h.freefish.info:9204/_cluster/healthhttp://h.freefish.info:9204/_cat/nodes
26 、 RabbitMq 集群
1.普通模式消息只会存在于集群的一个节点(即数据节点),当其他节点(其他节点只会存储Mq的消息类型)访问消息时,数据节点先把数据发送到该节点,在消费。弊端:当数据节点宕机,整个集群不可用无法高可用2.镜像模式A,B,C 每个队列数据都一致,master宕机会主动选取主节点,主节点负责数据访问#启动主节点docker run -d --hostname rabbitmq01 --name rabbitmq01 \-v /mydata/rabbitmq/rabbitmq01:/var/lib/rabbitmq -p \15673:15672 -p 5673:5672 -e RABBITMQ_ERLANG_COOKIE='freefish' \rabbitmq:management#启动第二个docker run -d --hostname rabbitmq02 --name rabbitmq02 -v /mydata/rabbitmq/rabbitmq02:/var/lib/rabbitmq -p 15674:15672 -p 5674:5672 -e RABBITMQ_ERLANG_COOKIE='freefish' --link rabbitmq01:rabbitmq01 rabbitmq:management#启动第三个docker run -d --hostname rabbitmq03 --name rabbitmq03 -v /mydata/rabbitmq/rabbitmq03:/var/lib/rabbitmq -p 15675:15672 -p 5675:5672 -e RABBITMQ_ERLANG_COOKIE='freefish' --link rabbitmq01:rabbitmq01 --link rabbitmq02:rabbitmq02 rabbitmq:management#配置主节点docker exec -it rabbitmq01 bashrabbitmqctl stop_apprabbitmqctl resetrabbitmqctl start_appexit#配置第二和三个节点 需要加入集群docker exec -it rabbitmq02 bashrabbitmqctl stop_apprabbitmqctl resetrabbitmqctl join_cluster --ram rabbit@rabbitmq01rabbitmqctl start_appexitdocker exec -it rabbitmq03 bashrabbitmqctl stop_apprabbitmqctl resetrabbitmqctl join_cluster --ram rabbit@rabbitmq01rabbitmqctl start_appexit# 访问可查看集群状态http://h.freefish.info:15673/#/##############以上是普通集群搭建方式,镜像集群是在其基础上搭建的##############docker exec -it rabbitmq01 bash# / 为默认虚拟主机 可以替换为自己的 ^代表所有对烈 ,可以随意设置如:'hello' 代表所有hello开头的队列rabbitmqctl set_policy -p / ha "^" '{"ha-mode":"all","ha-sync-mode":"automatic"}'#查出 / 虚拟主机下所有策略rabbitmqctl list_policies -p /

若有收获,就点个赞吧
0 人点赞
