创建索引shopping
PUT shopping
不能用POST shopping
因为POST不是幂等的
查询指定索引:
GET shopping
查询所有索引:
GET _cat/indices?v
v是展现详细信息
删除指定索引shopping:
DELETE shopping
索引中添加数据,用POST
POST shopping/_doc{"title":"小米手机","catagory":"小米","image":"http://xiaomi.jpg","price":3999.00}
带ID添加:
POST shopping/_doc/1001{"title":"小米手机","catagory":"小米","image":"http://xiaomi.jpg","price":3999.00}
或者:
PUT shopping/_doc/1001{"title":"小米手机","catagory":"小米","image":"http://xiaomi.jpg","price":3999.00}
或者:
PUT shopping/_create/1003{"title":"小米手机","catagory":"小米","image":"http://xiaomi.jpg","price":3999.00}
注意这里 id必须是没添加过的
这里的本质原因就是PUT是幂等的,POST是非幂等的
根据ID查数据
GET shopping/_doc/1001
查询所有:
GET shopping/_search
全量覆盖修改:
PUT shopping/_doc/1001{"title":"华为手机"}
没有写的属性会丢失
POST shopping/_doc/1003{"doc":{ //这个写不写都行,写了映射的结构会多一层doc"title":"华为手机"}}
这个也是全量修改
增量修改:加update
POST shopping/_update/1003{"doc":{"title":"华为手机"}}
根据ID删除数据:
DELETE shopping/_doc/1001
条件查询:
GET shopping/_search?q=catagory="小米"
这种方式不好,一般不用,可能会出现乱码情况
一般用这种
GET shopping/_search{"query" :{"match": {"catagory": "小米"}}}
全量查询:
GET shopping/_search{"query" :{"match_all": {}}}
分页查询:
from:起始页,计算公式:(页码-1)*每页数据条数
size:每页多少条
GET shopping/_search{"query" :{"match_all": {}},"from": 0,"size": 2}
分页查询且只看指定字段: _source
GET shopping/_search{"query" :{"match_all": {}},"from": 0,"size": 2,"_source": ["title"]}
分页查询,查看指定字段,并且排序:
GET shopping/_search{"query" :{"match_all": {}},"from": 0,"size": 2,"_source": ["title"],"sort": [{"price": {"order": "desc"}}]}
多条件查询
GET shopping/_search{"query" :{"bool": {"must": [{"match": {"catagory": "小米"}},{"match": {"price": "3999"}}],"should": [{"match": {"title": "华为"}}],"filter": {"range": {"price": {"gte": 1999,"lte": 4000}}}}}}
must是与
should是或
filter range是范围查询
完全匹配
GET shopping/_search{"query": {"match_phrase": {"title": "华为"}}}
match和match_phrase的区别:
https://www.yuque.com/frank-jzao9/ter554/binh4e
高亮显示
GET shopping/_search{"query": {"match_phrase": {"title": "华为"}},"highlight": {"fields": {"title": {}}}}
高亮上下对应
GET shopping/_search{"query": {"bool": {"should": [{"match": {"title": "华为"}},{"match": {"catagory": "华为"}}]}},"highlight": {"fields": {"title": {},"catagory": {}}}}
聚合操作
GET shopping/_search{"aggs": {"price_group": { //统计结果名称,随意取名"terms": { //分组,固定写法"field": "price", //分组字段"size": 10 //统计结果显示几条}}},"size": 0 //0表示不查看原始数据}
结果: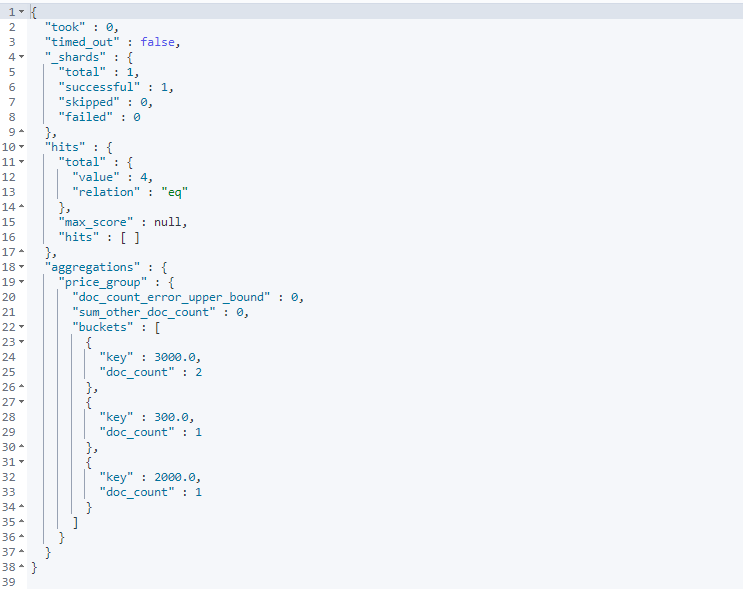
平均值
GET shopping/_search{"aggs": {"price_avg": { //统计结果名称,随意取名"avg": { //分组,固定写法"field": "price" //分组字段}}},"size": 0 //0表示不查看原始数据}
创建映射关系
PUT user/_mapping{"properties":{"name":{"type":"text","index":true},"sex":{"type":"keyword","index":true},"tel":{"type":"keyword","index":false}}}
keyword不会被分词,
index是false,代表不能被索引,不支持用tel查询
分词器
GET _analyze{"analyzer": "ik_max_word","text": "我好帅"}

若有收获,就点个赞吧
0 人点赞
