@[toc]
这里熟悉Java内存模型的目的是为了后续对于多线程和并发问题的理解,以及相关源码的走读打下基础。
1. 硬件内存模型
硬件层面的内存模型指的就是操作系统中的内存模型,在上面的文章中已经讲到了部分关于操作系统中CPU缓存层面的内容,下面只简要总结一下。多级内存模型或是缓存模型的出现,根本目的是为了解决CPU运算速度和内存读写速度之间不匹配的矛盾。内存模型的出现使得CPU运算结束后可将结果写入到缓存中,由缓存负责将结果写入到内存中,当然最终数据可能还会保存到硬盘上。
例如,Linux系统可以使用lscpu查看计算的内存模型:
[root@iZbp15ffbqqbe97j9dcf5dZ ~]# lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 1On-line CPU(s) list: 0Thread(s) per core: 1Core(s) per socket: 1Socket(s): 1NUMA node(s): 1Vendor ID: GenuineIntelCPU family: 6Model: 79Model name: Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHzStepping: 1CPU MHz: 2494.224BogoMIPS: 4988.44Hypervisor vendor: KVMVirtualization type: fullL1d cache: 32KL1i cache: 32KL2 cache: 256KL3 cache: 40960KNUMA node0 CPU(s): 0
简要来说,CPU、缓存和内存之间的关系如下所示:
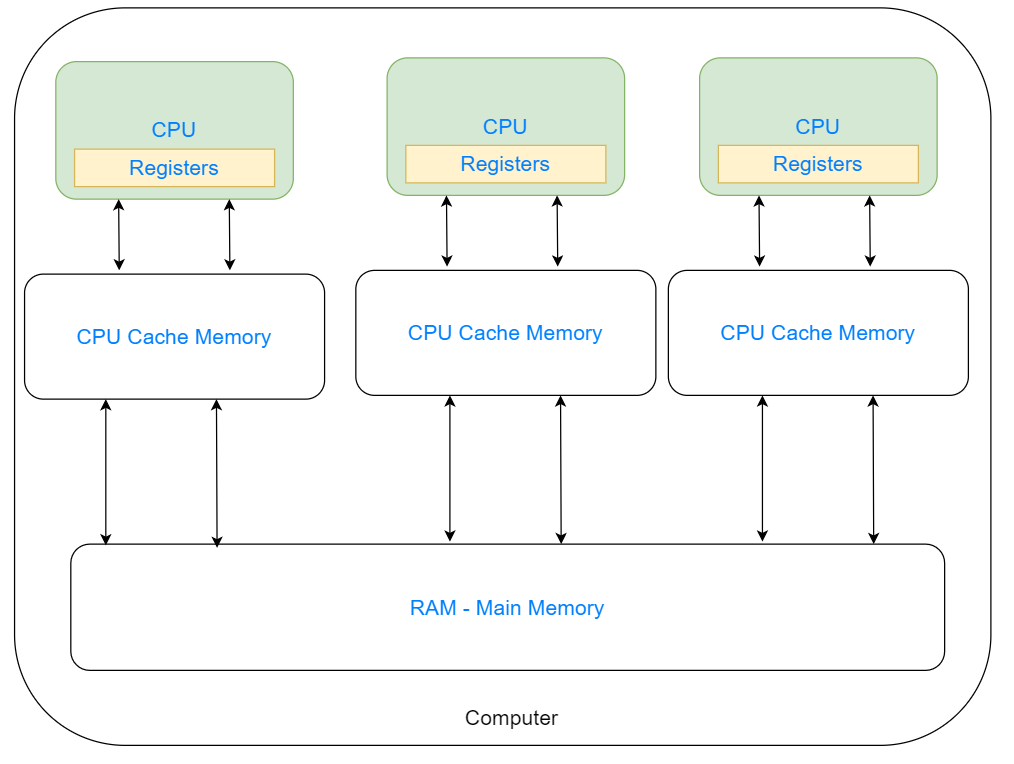
如上图所示,这里计算机中存在多个CPU,每个CPU都存在自己的高速缓存,但是都共享同一块内存区域。如果多个CPU所执行的线程都涉及内存中的同一个共享变量,但是不同的线程对于变量所执行的操作不同。如果对于多个线程之间的操作不加以限制,那么最终将结果重写写会内存就会引发缓存一致性的问题 。
2. Java内存模型(Java Memory Model)
在前面已经学习过Java虚拟机的相关内容,对于Jvm的运行时数据区,以及其他相关部分的结构和具体运行流程做了详细的介绍,详情可见如下的文章。
对于Java中的多线程问题来说,我们可以抽象出一个屏蔽底层硬件内存模型细节的内存模型,如下所示:
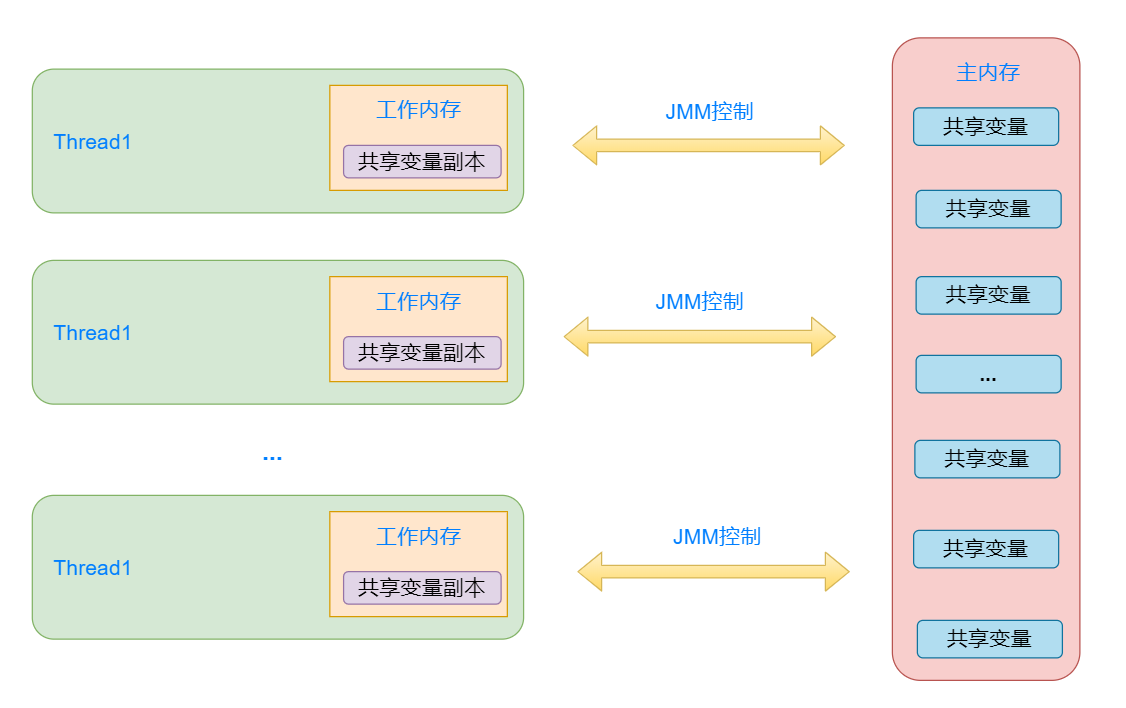
如上所示,Java内存模型中所有的共享变量(实例字段、惊天字段、构成数组对象的元素)都存储在主内存中,每个线程都有自己的工作内存,彼此之间是独立的。不同的线程对于主内存中共享变量的操作流程为:
- 首先,将主内存中的共享变量复制到自己的工作内存中,得到共享变量的副本
- 针对于自己独有的变量副本执行一系列相关的操作
- 最后将操作的结果重写入到主内存的共享变量中
例如,执行下面线程中的代码,对变量counter进行自增操作:
Thread t1 = new Thread(() -> {counter++;}, "t1");
对应的字节码指令为:
0 getstatic #10 <StackDemo/Test.counter>3 iconst_14 iadd5 putstatic #10 <StackDemo/Test.counter>8 retur
其中getstatic #10表示从主内存中获取counter的值,然后在线程t1的工作内存中使用iconst_1指令准备变量的副本;接着iadd对counter实现自增操作;最后使用putstatic #10将结果重写回到主内存中。因此,coutner++看似只有一行简单的代码,但是底层实现的步骤可不止一步。
假设此时又有一个线程t2对counter执行自减操作,如下所示:
Thread t2 = new Thread(() -> {counter--;}, "t2");
如果两个线程之间的执行顺序不同,那么最终counter的结果也会不同。如果两个线程按照如下的顺序执行,那么结果就可能是正数:
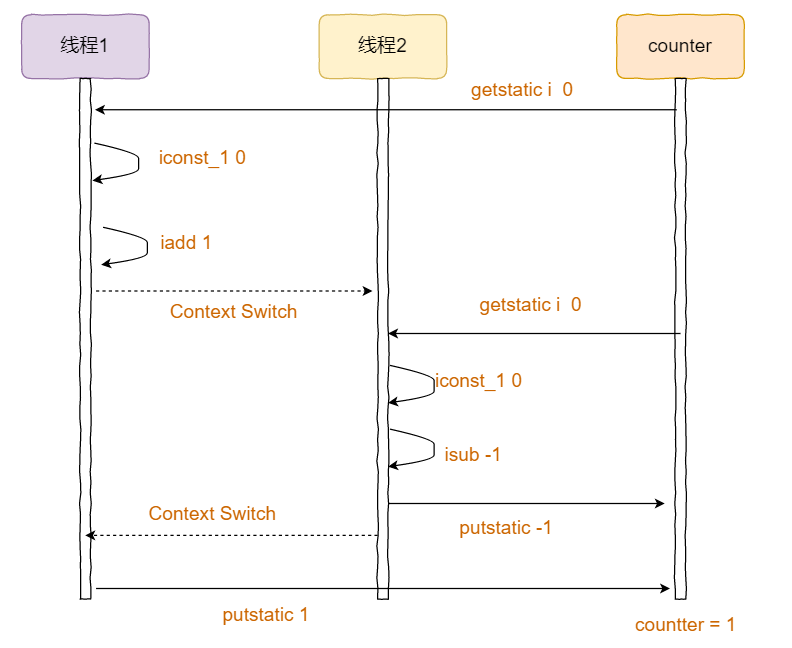
而如果按照下面的顺序执行,那么结果就可能为负数:
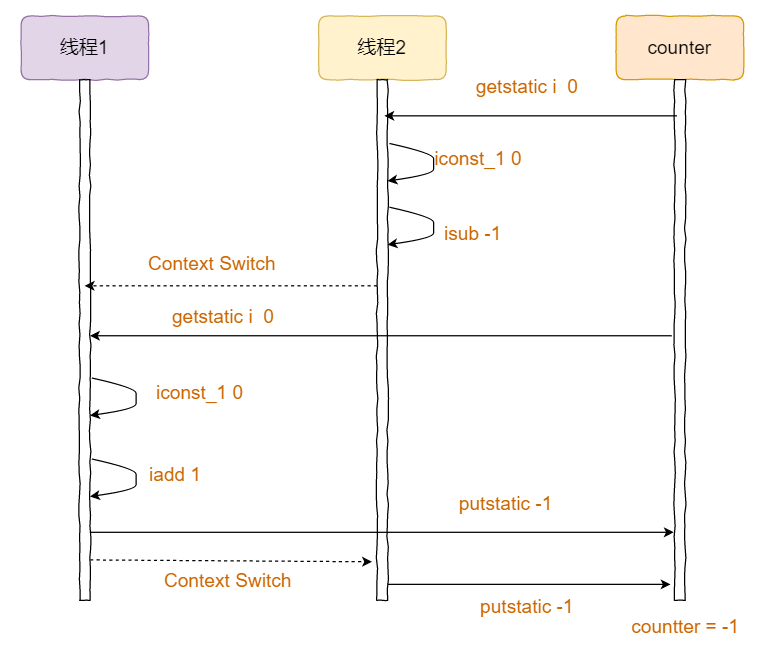
可以看出,正是由于不同指令之间的执行顺序对于共享变量值的改变,使得最终的结果不唯一。那么,如果想要使得最终的结果为0,那么就需要对使用counter这个共享变量做出某种限制,即做到线程同步。
3. 内存模型交互操作
如上面Java内存模型图所示,线程的工作内存和主内存之间的交互完全由JMM控制,它负责主内存和线程工作内存之间变量的辅助以及同步操作,并且保证每一个操作都具有原子性。主内存和工作内存之间交互的八种操作有:
lock:作用于主内存,将变量标识为线程独占状态unlock:作用于主内存,将被标识为线程独占的变量释放read:作用于主内存变量,将变量值从主内存传输到线程的工作内存中load:作用于主内存变量,将read操作得到的变量值放入到线程工作内存的变量副本中use:作用于工作内存变量,将工作内存中的一个变量值传递给执行引擎assign:作用于工作内存变量,将从执行引擎接受到的值赋值给工作内存中的相应变量store:作用于工作内存变量,将工作内存中的变量值传递到主内存中write:作用于主内存变量,将store操作传递得到的变量值放入主内存的变量中
可以看到,lock-unlock、read-load、use-assign、store-write之间是相互对应的,它们之间的交互图如下所示:
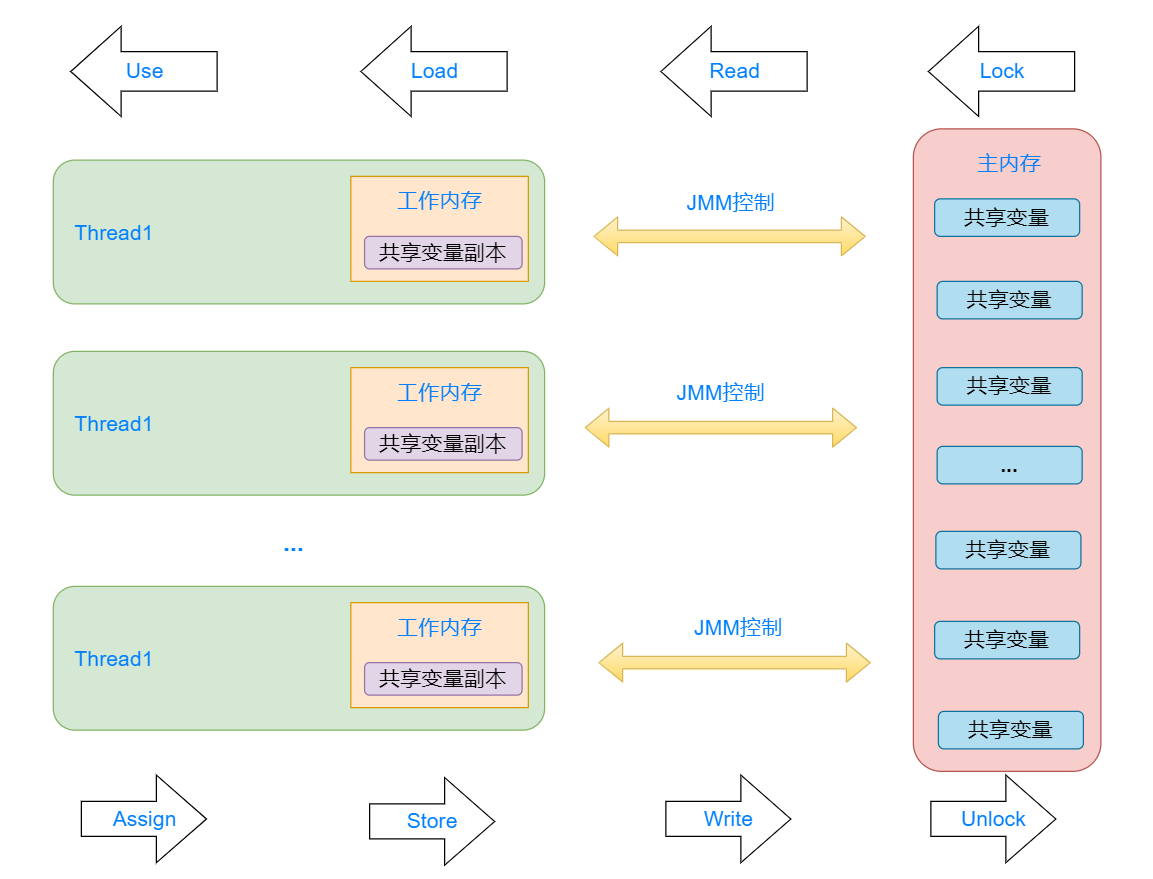
其中,需要注意以下几点:
- read load ; store write只能成对操作,不能出现只读不用,只返回不存储
- 不允许线程丢弃assign操作,用完的变量一定会传回主内存,也不允许将未assign的变量从工作内存写回主内存
- 变量只能从主内存中创建,未初始化的变量线程不能load 或 assign
- 变量只能被一个线程执行lock操作,但可以执行多次lock,对应的释放时也必须执行相应次数的unlock
- 线程只能对自己lock的变量执行unlock,而且未被lock的变量不能只能unlock操作
- 对一个变量执行lock操作,将会清空工作内存中该变量的值,所以在执行引擎使用这个变量前,需要重新执行load或assign操作对其进行初始化
- 对一个变量执行unlock操作之前,必须先把该变量同步回主内存(如store、write操作)
4. 三大特性
4.1 原子性
原子性指一个操作在执行期间不可中断、不可分割,对应到多线程中指:一旦某个具体的线程开始执行某个操作,那么这个操作将不能被其他的线程干扰。
Java内存模型直接用来保证原子性变量的操作包括use、read、load、assign、store、write,我们大致可以认为Java基本数据类型的访问都是原子性的。如果用户要操作一个更大的范围保证原子性,Java内存模型还提供了lock和unlock来满足这种需求,但是这两种操作没有直接开放给用户,而是提供了两个更高层次的字节码指令:monitorenter和 moniterexit,这两个指令对应到Java代码中就是synchronized关键字,所以synchronized代码块之间的操作具有原子性。
4.2 可见性
可见性指当一个线程修改了主内存中的共享变量后,使用相同变量的线程可以立即得知这个修改。
Java内存模型通过将变量修改后将新值同步写回主内存,在读取前从主内存刷新变量值,所以JMM是通过主内存作为传递介质来实现可见性的。无论是普通变量还是volatile修饰的变量都是这样的,唯一的区别在于:
- volatile变量在被修改之后会立刻写回主内存,而在读取时都会重新去主内存读取最新的值
- 普通变量则在被修改后会先存储在工作内存,之后再从工作内存写回主内存,而读的时候则是从工作内存中读取该变量的副本
除了volatile可以实现可见性之外,synchronized和final关键字也能实现可见性
- synchronized:对一个变量执行unlock操作之前,必须将变量的改动写回主内存来(store、write两个操作)
- final字段:一旦final字段初始化完成,其他线程就可以访问final字段的值,而且final字段初始化完成之后就不再可变
4.3 有序性
为了提高性能,编译器和处理器可能会对指令做重排序。重排序可以分为三种:
编译器优化的重排序:编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序
指令级并行的重排序:现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序
内存系统的重排序:由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行
同样JMM中也存在指令重排序优化,这种优化在单线程中是不会存在问题的,但如果这种优化出现在多线程环境中,就可能会出现多线程安全的问题,因为线程1的指令优化可能影响线程2中某个状态。
Java提供了volatile和synchronized关键字来保证线程间操作的有序性:
- volatile是因为其本身的禁止指令重排序语义来实现
- synchronized则是由“同一个变量在同一时刻只能有一个线程对其进行lock操作”这条规则来实现的,这也就是synchronized代码块对同一个锁只能串行进入的原因
5. 参考

若有收获,就点个赞吧
0 人点赞
