Zookeeper入门
概述
Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目
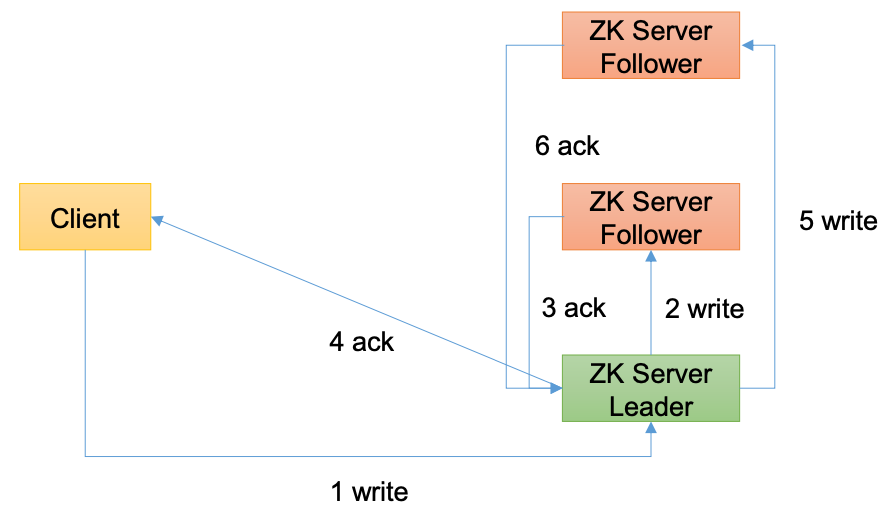
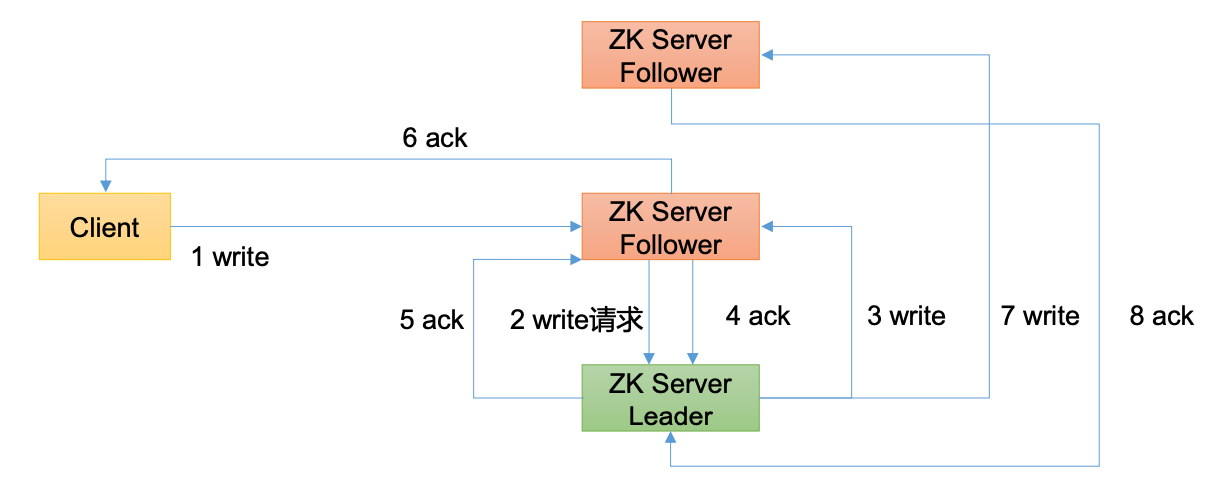
Zookeeper工作机制

特点

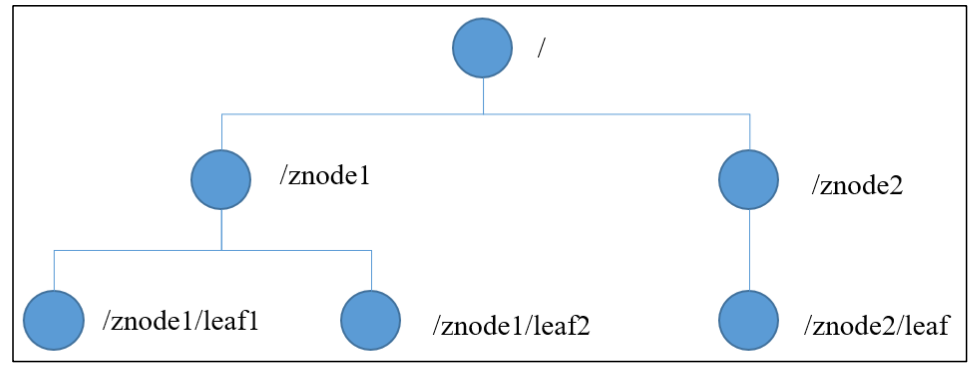
数据结构
- ZooKeeper 数据模型的结构与 Unix 文件系统很类似,整体上可以看作是一棵树,每个 节点称做一个 ZNode。每一个 ZNode 默认能够存储 1MB 的数据,每个 ZNode 都可以通过其路径唯一标识。
-
应用场景
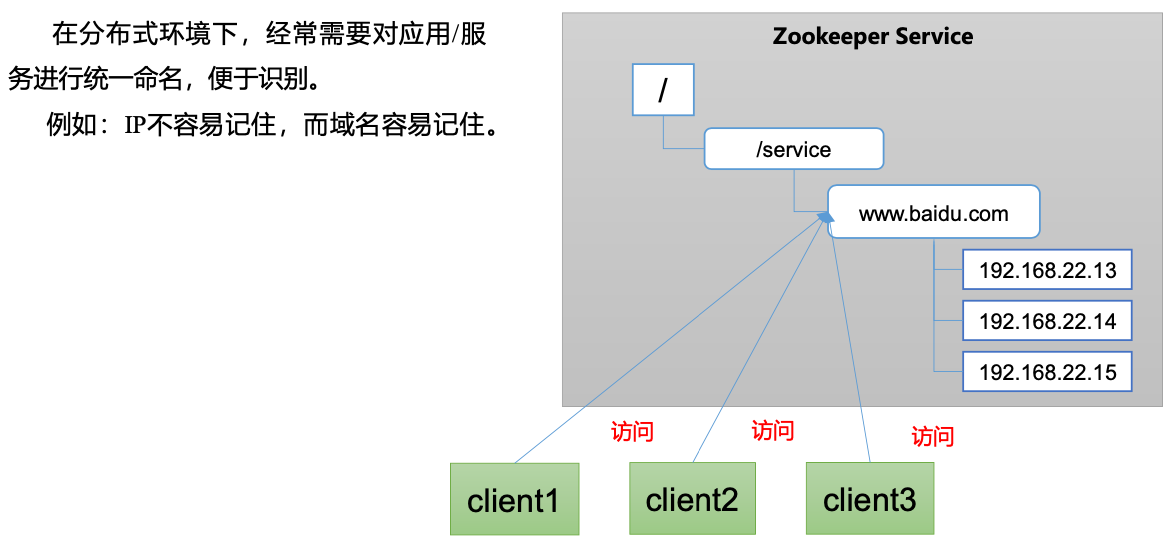
统一命名服务
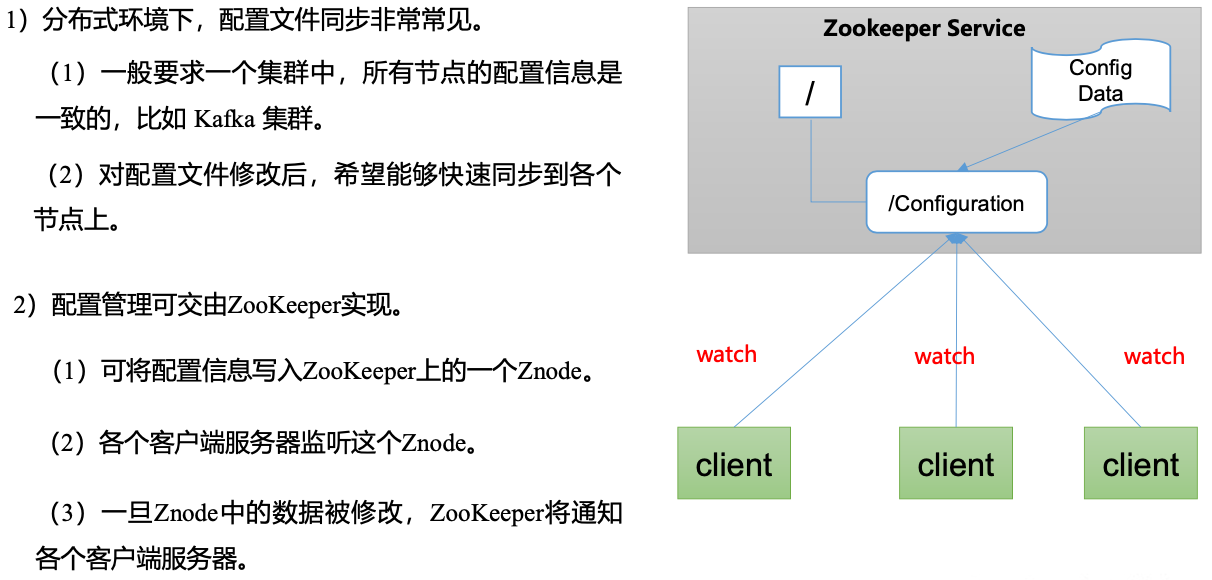
统一配置管理
统一集群管理
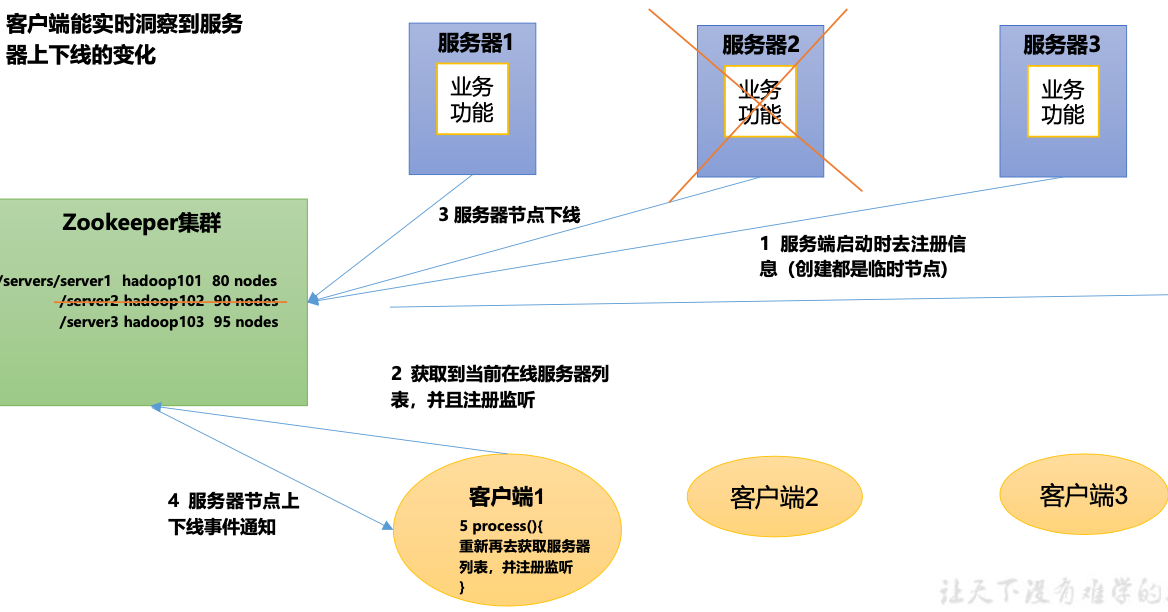
服务器动态上下线
软负载均衡
下载地址
官网首页
- https://zookeeerp.apache.org/
Zookeeper本地安装
本地安装模式
安装前准备
- https://zookeeerp.apache.org/
安装JDK
- 拷贝
apache-zookeeper-3.5.7.tar.gz文件到指定目录/opt/software - 解压到指定目录
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/ 修改名称
mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7配置修改
将
/opt/module/zookeeper-3.5.7/conf这个路径下的zoo_sample.cfg修改为zoo.cfgmv zoo_sample.cfg zoo.cfg
配置
zoo.cfg文件的dataDir路径启动Zookeeper
bin/zkServer.sh start
- 查看进程是否启动
jps1978 QuorumPeerMain代表启动成功
- 查看状态
bin/zkServer.sh status
- 启动客户端
bin/zkCli.sh
- 退出客户端
quit
停止Zookeeper
通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
-
initLimit=10
LF初始通信时限
-
syncLimit=5
LF同步通信时限
-
dataDir
保存Zookeeper中的数据
默认是tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录
clientPort=2181
-
Zookeeper集群操作
集群操作
集群安装
集群规划
在 hadoop102、hadoop103、hadoop104三个节点都部署Zookeeper
解压安装
-
配置服务器编号
在
/opt/module/zookeeper-3.5.7/zkData目录下创建一个myid文件vi myid
- 在文件中添加与server对应的编号
2
拷贝配置好的zookeeper到其它机器上
重命名为
zoo.cfg同上- 修改
zoo.cfg文件内的dataDir 在
zoo.cfg中增加如下配置#########################cluster###################server.2=hadoop102:2888:3888server.3=hadoop103:2888:3888server.4=hadoop104:2888:3888
配置参数解读
server.2=hadoop102:2888:3888- 2
- 是一个数字,表示这个是第几号服务器,集群模式下配置一个文件myid,这个文件在
zkData目录下,这个文件里面有一个数据就是2,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
- 是一个数字,表示这个是第几号服务器,集群模式下配置一个文件myid,这个文件在
- hadoop102
- 是这个服务器地址
- 2888
- 是这个服务器Follower与集群中的Leader服务器交换信息的端口
- 3888
- 集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口
-
集群操作
分别启动Zookeeper
在hadoop102的
/home/bin目录下创建脚本vi zk.sh
在脚本之编写如下内容
#!/bin/bashcase $1 in"start"){for i in hadoop102 hadoop103 hadoop104doecho ---------- zookeeper $i 启动 ------------ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"done};;"stop"){for i in hadoop102 hadoop103 hadoop104doecho ---------- zookeeper $i 停止 ------------ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"done};;"status"){for i in hadoop102 hadoop103 hadoop104doecho ---------- zookeeper $i 状态 ------------ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"done};;esac
增加脚本执行权限
chmod u+x zk.sh
- zk集群启动脚本
./zk.sh start
- zk集群状态脚本
./zk.sh status
zk集群停止脚本
bin/zkCli.sh -server hadoop102:2181显示所有操作命令
-
znode节点数据信息
查看当前znode中所包含的内容
-
查看当前节点详细数据
ls -s /[zookeeper]cZxid = 0x0ctime = Thu Jan 01 08:00:00 CST 1970mZxid = 0x0mtime = Thu Jan 01 08:00:00 CST 1970pZxid = 0x0cversion = -1dataVersion = 0aclVersion = 0ephemeralOwner = 0x0dataLength = 0numChildren = 1
czxid:创建节点的事务zxid
- 每次修改Zookeeper状态都会产生一个ZooKeeper事务ID。事务ID是ZooKeeper中所有修改总的次序。每次修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。
- ctime:znode被创建的毫秒数(从1970年开始)
- mzxid:znode最后更新的事务zxid
- mtime:znode最后修改的毫秒数(从1970年开始)
- pZxid:znode最后更新的子节点zxid
- cversion:znode子节点变化号,znode子节点修改次数
- dataversion:znode数据变化号
- aclVersion:znode访问控制列表的变化号
- ephemeralOwner:如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0
- dataLength:znode的数据长度
-
节点类型(持久/短暂/有序号/无序号)
分别创建2个普通节点(永久节点+不带序号)
create /sanguo "diaochan"create /sanguo/shuguo "liubei"获得节点的值
-
创建带序号的节点(永久节点+带序号)
先创建一个普通的根节点
/sanguo/weiguocreate /sanguo/weiguo "caocao"
创建带序号的节点
创建短暂的不带序号的节点
create -e /sanguo/wuguo "zhouyu"
创建短暂的带序号的节点
-
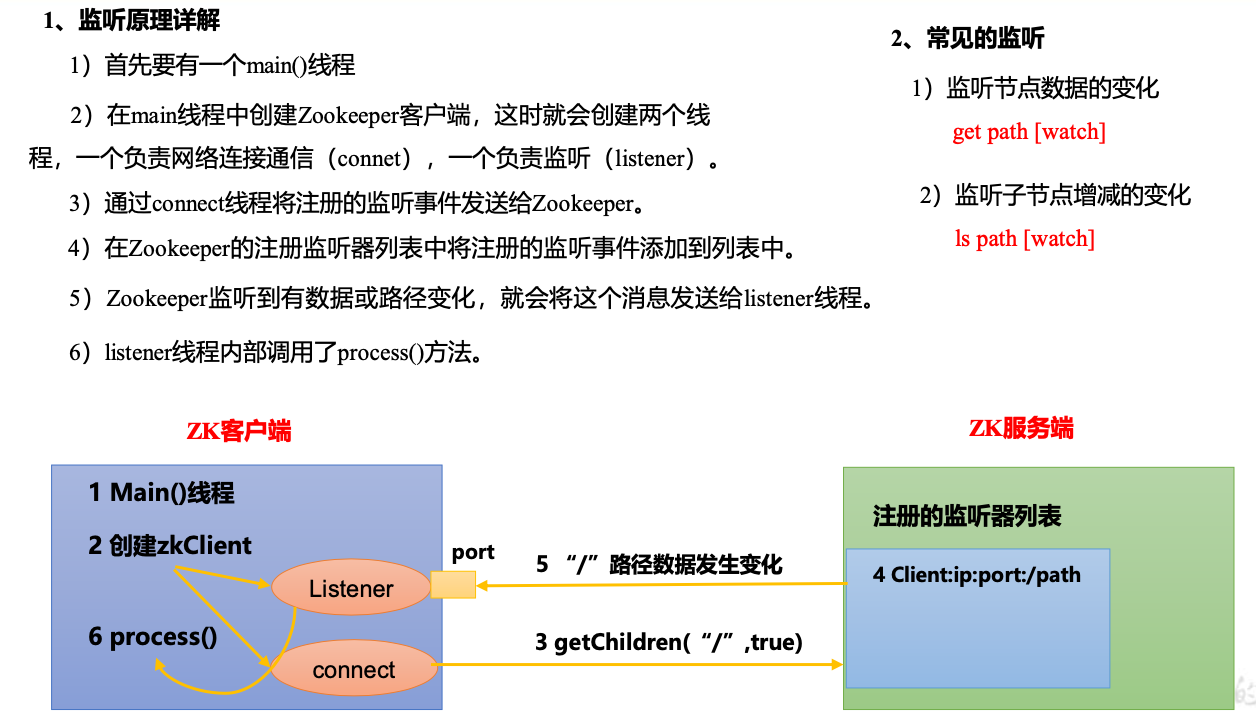
监听器原理
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、节点删除、子目录节点增加删除)时,ZooKeeper会通知客户端。监听机制保证ZooKeeper保存的任何的数据的任何改变都能快速的响应到监听了该节点的应用程序。
-
节点的值变化监听
在hadoop104主机上注册监听
/sanguo节点数据变化get -w /sanguo
- 在hadoop103主机上修改
/sanguo节点的数据set /sanguo "xisi"
观察hadoop104主机收到数据变化的监听
在hadoop104主机上注册监听
/sanguo节点的子节点变化ls -w /sanguo
- 在hadoop103主机
/sanguo节点上创建子节点create /sanguo/jin "simayi"
观察hadoop104主机收到子节点变化的监听
-
递归删除节点
-
查看节点状态
-
客户端API操作
IDEA环境搭建
创建一个工程zookeeper
添加pom文件
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.5.7</version></dependency></dependencies>
拷贝
log4j.properties文件到项目根目录log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n创建
ZooKeeper客户端和子节点public class zkClient { private static String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181"; private static int sessionTimeout = 2000; private ZooKeeper zkClient = null; @Before public void init() throws IOException { zkClient = new ZooKeeper(connectString, sessionTimeout, watchedEvent -> { //收到事件通知后回调函数 System.out.println(watchedEvent.getType() + "--" + watchedEvent.getPath()); //再次启动监听 try { List<String> children = zkClient.getChildren("/", true); for (String child : children) { System.out.println(child); } }catch (Exception e) { e.printStackTrace(); } }); } @Test public void createTest() throws InterruptedException, KeeperException { /** * 1、节点路径 * 2、节点数据 * 3、节点权限 * 4、节点类型 */ zkClient.create("/atguigu", "shuaige".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); } }测试
在hadoop102的zk客户端上查看创建节点情况
get -s /atguigu-
获取子节点并监听节点变化
/** * 获取子节点,并监听状态 */ @Test public void getChildren() throws InterruptedException, KeeperException { //设置监听器为true,走的是init方法的监听器 List<String> children = zkClient.getChildren("/", true); for (String child : children) { System.out.println(child); } //延迟阻塞 Thread.sleep(Long.MAX_VALUE); }
在客户端上创建一个节点,观察idea控制台
create /atguigu1 "atguigu1"
在客户端上删除一个节点,观察idea控制台
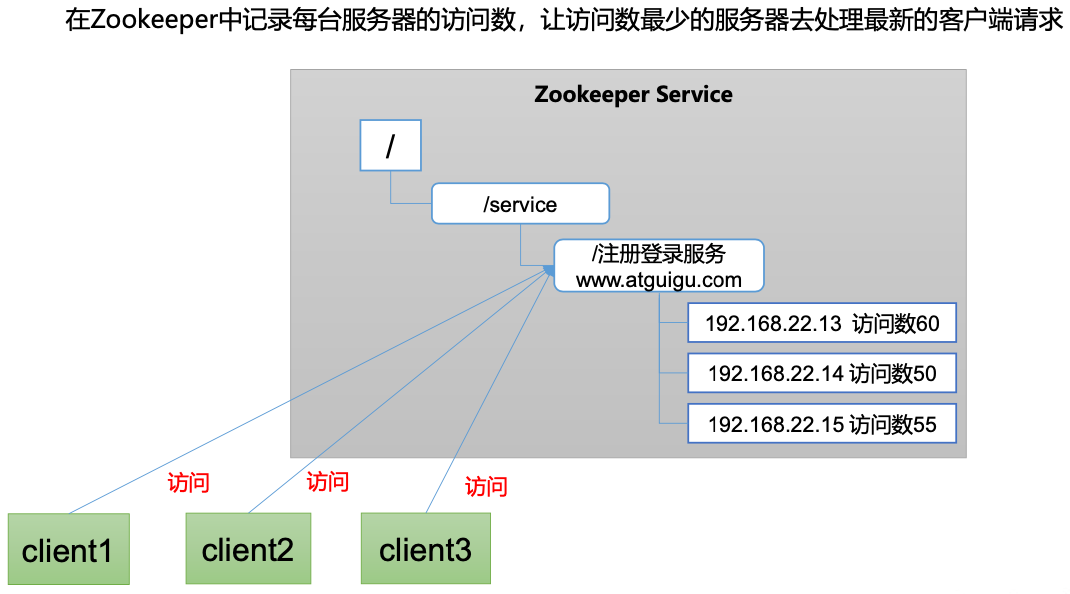
某分布式系统中,主节点可以有多台,可以动态上下线,任意一台客户端都能实时感知到主节点服务器的上下线。
需求分析
具体实现
先创建
/servers节点create /servers "servers"
- 服务端向Zookeeper注册 ```java package com.foreign.distribute;






import org.apache.zookeeper.CreateMode; import org.apache.zookeeper.KeeperException; import org.apache.zookeeper.ZooDefs; import org.apache.zookeeper.ZooKeeper;
import java.io.IOException;
/**
- @author fangke
- @Description:
- @Package
- @date: 2022/4/16 10:00 上午
*/ public class DistributeServer {
private ZooKeeper zk = null;
private String connectString = “hadoop102:2181,hadoop103:2181,hadoop104:2181”;
private int sessionTimeout = 2000;
private String parentPath = “/servers”;
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
//1、获取zk连接 DistributeServer server = new DistributeServer(); server.getConnect(); //2、利用zk连接注册服务器信息 server.registerServer(args[0]); //3、启动业务 server.business();}
private void business() throws InterruptedException {
Thread.sleep(Long.MAX_VALUE);}
private void registerServer(String hostname) throws InterruptedException, KeeperException {
String create = zk.create("parentPath", hostname.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL); System.out.println(hostname + "is online " + create);}
private void getConnect() throws IOException {
zk = new ZooKeeper(connectString,sessionTimeout,watchedEvent -> { });} } ```
- 客户端代码 ```java package com.foreign.distribute;
import org.apache.zookeeper.KeeperException; import org.apache.zookeeper.ZooKeeper;
import java.io.IOException; import java.util.ArrayList; import java.util.List;
/**
- @author fangke
- @Description:
- @Package
- @date: 2022/4/16 10:15 上午
*/ public class DistributeClient {
private ZooKeeper zk = null;
private String connectString = “hadoop102:2181,hadoop103:2181,hadoop104:2181”;
private int sessionTimeout = 2000;
private String path = “/servers”;
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
DistributeClient client = new DistributeClient(); //1、获取连接 client.getConnect(); //2、监听 /servers 下面子节点的增加和删除 client.getServerList(); //处理业务 client.business();}
private void business() throws InterruptedException {
Thread.sleep(Long.MAX_VALUE);}
private void getServerList() throws InterruptedException, KeeperException {
//获取服务器子节点信息、并对父节点进行监听 List<String> children = zk.getChildren(path, true); //存储服务器信息列表 List<String> servers = new ArrayList<>(); for (String child : children) { byte[] data = zk.getData(path + "/" + child, false, null); servers.add(new String(data)); } //打印服务器列表信息 System.out.println(servers);}
private void getConnect() throws IOException {
zk = new ZooKeeper(connectString,sessionTimeout,watchedEvent -> { //再次启动监听 try { getServerList(); } catch (InterruptedException e) { e.printStackTrace(); } catch (KeeperException e) { e.printStackTrace(); } });测试
在Linux命令行上操作增加减少服务器
- 启动DistributeClient客户端
- 在hadoop102上zk的客户端
/servers目录上创建临时带序号节点create -e -s /servers/hadoop102 "hadoop102"create -e -s /servers/hadoop103 "hadoop103"
-
在Idea上操作增加减少服务器
启动DistributeClient客户端(如果已经启动过,不需要重启)
启动DistributeServer服务
比如进程A在使用该资源的时候,会先去获得锁,进程A获得锁以后会对该资源保持独占,这样其他进程就无法访问该资源,进程A用完该资源以后就将锁释放掉,让其他进程来获得锁,那么通过这个锁机制,我们就能保证了分布式系统中多个进程能够有序的访问该临界资源。我们就把这个锁叫作分布式锁。

原生Zookeeper实现分布式锁
分布式锁实现
```java package com.foreign.distributelock;

import org.apache.zookeeper.*; import org.apache.zookeeper.data.Stat;
import java.io.IOException; import java.util.Collections; import java.util.List; import java.util.concurrent.CountDownLatch;
/**
- @author fangke
- @Description:
- @Package
- @date: 2022/4/18 5:01 下午
*/ public class DistributeLock { // zookeeper server 列表 private String connectString = “hadoop102:2181,hadoop103:2181,hadoop104:2181”;
// 超时时间 private int sessionTimeout = 2000;
private ZooKeeper zk;
//ZooKeeper 连接 private CountDownLatch connectLatch = new CountDownLatch(1); //Zookeeper 等待 private CountDownLatch waitLatch = new CountDownLatch(1);
// 当前 client 等待的子节点 private String waitPath;
// 当前 client 创建的子节点 private String currentNode;
public DistributeLock() throws IOException, InterruptedException, KeeperException {
zk = new ZooKeeper(connectString, sessionTimeout, watchedEvent -> { //连接请求 if (watchedEvent.getState() == Watcher.Event.KeeperState.SyncConnected) { connectLatch.countDown(); } //waitPath删除事件 if (watchedEvent.getType() == Watcher.Event.EventType.NodeDeleted && watchedEvent.getPath().equals(waitPath)) { waitLatch.countDown(); } }); //等待连接建立 connectLatch.await(); //判断是否存在根节点 Stat stat = zk.exists("/locks", false); if (stat == null) { //创建 根节点,并且是永久类型 zk.create("/locks", "locks".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); }}
//加锁 public void zkLock() throws InterruptedException, KeeperException {
//创建带序号的临时节点 currentNode = zk.create("/locks" + "seq-", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL); //获取到子节点 List<String> children = zk.getChildren("/locks", true, null); if (children.size() == 1) { //如果只有一个节点,那么直接获取锁 return; } else { //排序节点 Collections.sort(children); //当前节点的名字 String currentNodeName = currentNode.substring("/locks/".length()); //判断当前节点排在哪个位置 int index = children.indexOf(currentNode); if (index == 0) { //说明在列表中最小位置,直接返回,获取锁 return; } else { //获取排名比currentNode靠前一名的节点进行监听 this.waitPath = "/locks/" + children.get(index - 1); // 在 waitPath 上注册监听器, 当 waitPath 被删除时, zookeeper 会回调监听器的 process 方法 zk.getData(waitPath, true, new Stat()); waitLatch.await(); return; } }}
//解锁 public void unZkLock() throws InterruptedException, KeeperException {
//删除节点 zk.delete(currentNode, -1);} }
<a name="XI7bU"></a>
### 分布式锁测试
```java
package com.foreign.distributelock;
import org.apache.zookeeper.KeeperException;
import java.io.IOException;
/**
* @author fangke
* @Description:
* @Package
* @date: 2022/4/18 5:33 下午
* <p>
*/
public class DistributeLockTest {
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
DistributeLock lock1 = new DistributeLock();
DistributeLock lock2 = new DistributeLock();
new Thread(() ->{
try {
lock1.zkLock();
System.out.println("lock1 启动获取锁");
Thread.sleep(5000);
lock1.unZkLock();
System.out.println("lock1 释放锁");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}).start();
new Thread(() ->{
try {
lock2.zkLock();
System.out.println("lock2 启动获取锁");
Thread.sleep(5000);
lock2.unZkLock();
System.out.println("lock2 释放锁");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}).start();
}
}
Curator框架实现分布式锁案例
原生的Java API开发存在的问题
- 会话连接是异步的,需要自己去处理。比如使用CountDownLatch
- Watch需要重复注册,不然就不能生效
- 开发的复杂度高
-
Curator
是一个专门解决分布式锁的框架,解决了原生Java API开发分布式遇到的问题
Curator实操
pom依赖
<dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>4.3.0</version> </dependency> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>4.3.0</version> </dependency> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-client</artifactId> <version>4.3.0</version> </dependency>代码实现
```java package com.foreign.CuratorLock;
import org.apache.curator.RetryPolicy; import org.apache.curator.framework.CuratorFramework; import org.apache.curator.framework.CuratorFrameworkFactory; import org.apache.curator.framework.recipes.locks.InterProcessMutex; import org.apache.curator.retry.ExponentialBackoffRetry;
/**
- @author fangke
- @Description:
- @Package
- @date: 2022/4/18 5:40 下午
*/ public class CuratorLockTest {
// zookeeper server 列表 private String connectString = “hadoop102:2181,hadoop103:2181,hadoop104:2181”;
private String rootNode = “/locks”;
// connection超时时间 private int connectionTimeout = 2000; // session 超时时间 private int sessionTimeout = 2000;
public static void main(String[] args) {
}
public void test() {
InterProcessMutex lock1 = new InterProcessMutex(getCuratorFramework(), rootNode);
InterProcessMutex lock2 = new InterProcessMutex(getCuratorFramework(), rootNode);
new Thread(() -> {
try {
lock1.acquire();
System.out.println("线程 1 获取锁");
// 测试锁重入
lock1.acquire();
System.out.println("线程 1 再次获取锁");
Thread.sleep(5 * 1000);
lock1.release();
System.out.println("线程 1 释放锁");
lock1.release();
System.out.println("线程 1 再次释放锁");
} catch (Exception e) {
e.printStackTrace();
}
}).start();
new Thread(() -> {
try {
lock2.acquire();
System.out.println("线程 2 获取锁");
// 测试锁重入
lock2.acquire();
System.out.println("线程 2 再次获取锁");
Thread.sleep(5 * 1000);
lock2.release();
System.out.println("线程 2 释放锁");
lock2.release();
System.out.println("线程 2 再次释放锁");
} catch (Exception e) {
e.printStackTrace();
}
}).start();
}
//分布式锁初始化
private CuratorFramework getCuratorFramework() {
//重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000,3);
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString(rootNode)
.connectionTimeoutMs(connectionTimeout)
.sessionTimeoutMs(sessionTimeout)
.retryPolicy(retryPolicy)
.build();
//开启连接
client.start();
System.out.println("zookeeper 初始化成功");
return client;
}
面试真题
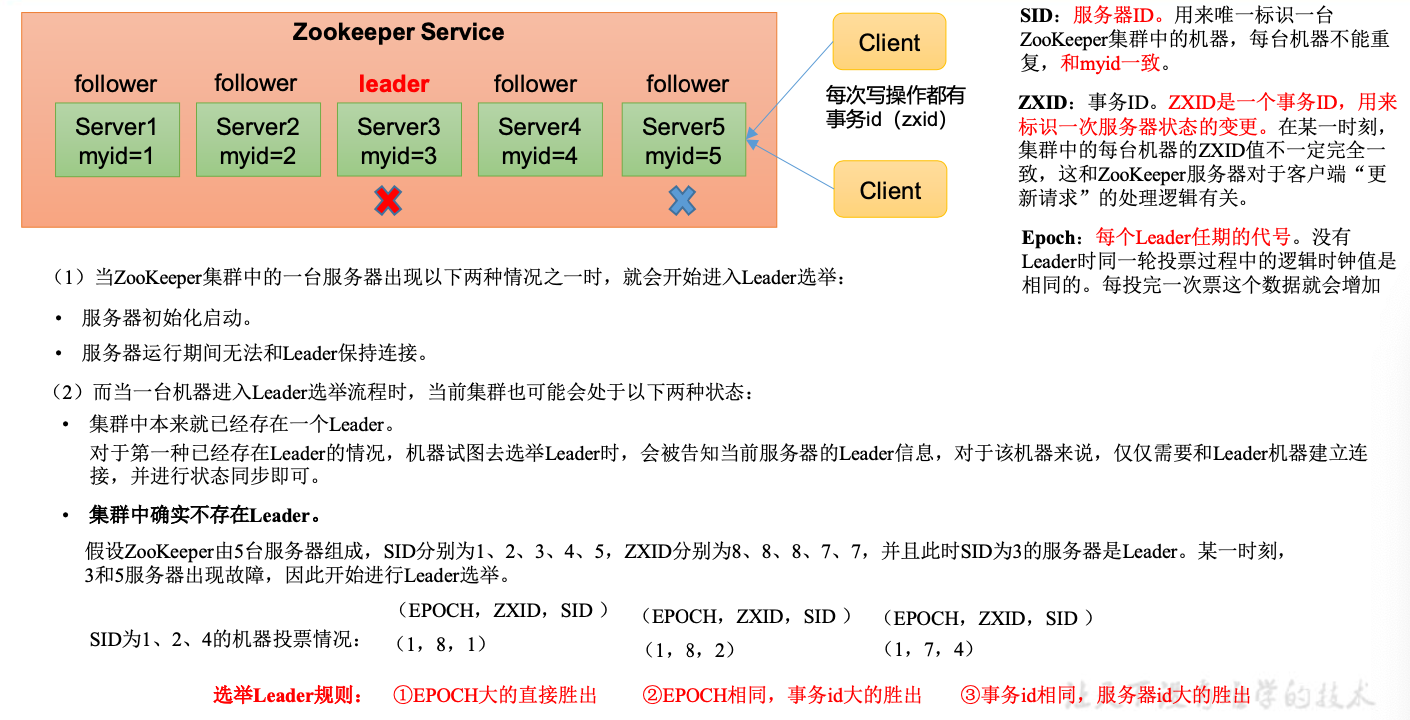
选举机制
半数机制,超过半数的投票通过,即通过
生产经验
- 10台服务器:3台zk
- 20台服务器:5台zk
- 100台服务器:11台zk
- 200台服务器:11台zk
- 服务器台数多:好处,提高可靠性;坏处:提高通信延时

若有收获,就点个赞吧
0 人点赞
