intro
在上一篇文章中,为了解决标签宽表在数据加载和使用过程中的种种问题,我们提出了bitMap。更进一步,为了解决数值bitmap膨胀的问题,我们引出了切片索引建模策略。与此同时,简要介绍了在切片索引下如何实现范围检索,聚合检索等非等值检索。
但是,我们一直都在讨论标签的建模方式,画像系统中的另外一个重要的元素,“事件”的数据该如何组织呢?事件和标签数据联合查询的场景该如何统一实现呢?考虑的更长远一点,离线和实时标签的存储、加工、使用能否抽象统一呢?事件驱动下的自动化营销能够也纳入到画像系统中来呢?
在调研了行业相关解决方案后,结合Clickhouse特性和近期工作经验,对上述问题打包回答,形成概要设计方案如下。
元数据设计
数据端和服务端应达成共识的是,标签和事件数据是项目的基础资产,对应的标签和事件元数据应只存一份,所有对标签和事件的后续应用应该在基础数据和基础元数据上进行扩展,而不是每次新增功能就拷贝一份元数据和基础数据。在设计元数据时,尽量遵循关系数据库的范式建模理论,减少后期数据冗余和失真的风险。
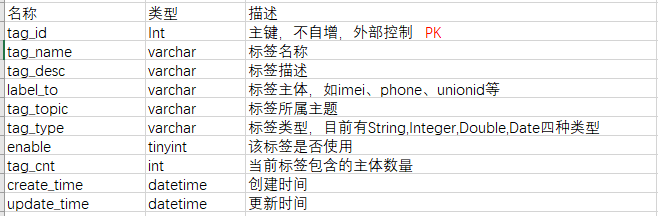
标签元数据
从现有的问题来看,设计标签元数据时,应考虑到。
- 标签主体多种多样,可能为imei、unionid、phone、openid等。
- 标签具有生命周期,应该利于标签的后期管理和下架。
- 用户应该是使用和管理标签的第一人,标签的创建和管理应上移到用户层。
- 元数据的设计应利于后期的数据质量监控。
事件元数据
事件的元数据较为简单,在存储基础数据时,不同的事件存在不同的表中。在检索时,用event_id对应的data_table和data_part来锁定目标表和可用分区。由于不同的事件可能有不同的字段,需要在table_col中指明事件表的schema信息。schema信息具体应包含字段id、字段类型、字段名称,为使用方便,可将schema信息封装为json数组中,数组中包含的字段即最后暴露给用户圈选的字段。
为了让前端同学更好的识别不同的数据类型,事件表的字段类型设置要按照相关约定。例如,日期时间类型的统一用datetime类型存储,或者在字段标示上统一用_time结尾,这样前端就可以针对不同的列类型选择不同的UI方案。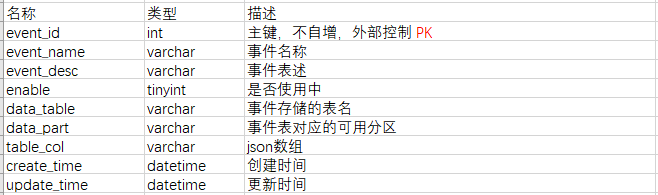
数仓建模和分层设计
基础数据从接入、清洗、加工到最终作为数据服务开放给用户,链路较长。为规范数据管理,可参考数据仓库分层设计的思想,具体表命名规范,任务命名规范参考中心数据中台方案,不再赘述。
需要注意的是,画像系统是在数据仓库之上的数据产品,建模方式在dw层之后不宜使用dm明细宽表设计。根据生产经验和实践总结,下图所示的分层设计能更好的满足业务需求和后期数据治理需求。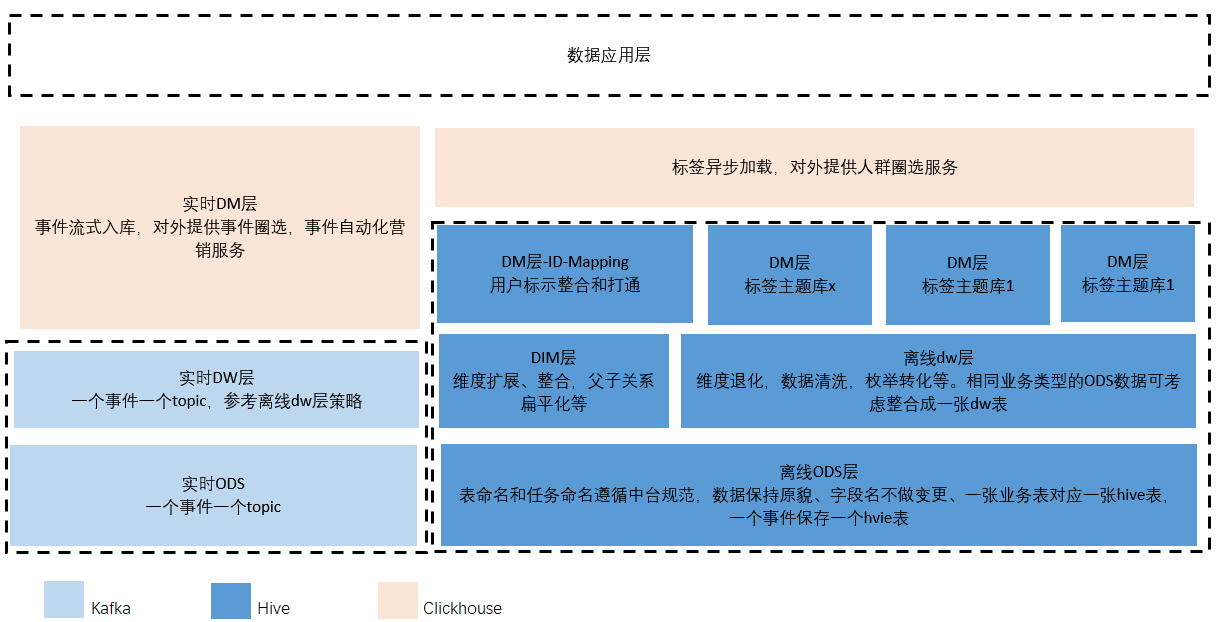
Dm层主题标签库
在经典的数据仓库建模方法中,dm对dw层进行轻度聚合,一般表示指标明细层。在表schema上采用宽表模型,将相关联的指标放在一起,减少后期相关信息的join。在本方案中,为减少标签表schema的频繁变动,解耦各标签的加工过程,dm层标签主题库采取”竖表”schema,即不同主键的标签放在不同的标签库下,标签的二级主题使用表分区来标示。一个参考主题标签库如下表所示。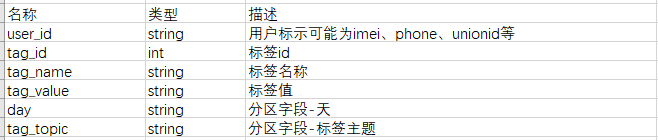
上图中的tag_topic和标签元数据中的tag_topic是相对应的,tag_topic在这里表示一种类型的标签,例如tag_topic=’gender’表示性别类标签,在元数据中该tag_topic下包含男性,女性子标签,在主题标签库中该tag_topic存放符合该标签的user_id信息。如果是采用标签宽表的设计,该tag_topic下的数据对应宽表中的一列,该列的列名等于该tag_topic。一般来说,一个标签加工的脚本对应一个topic,这样的设计有利于历史数据的回溯和异常数据的重加载。
在该表中,我们冗余了tag_id对应的tag_name信息(本可以通过tag_id关联标签表获取),这样设计是为了让数据分析师更好的理解标签表。在进行用户洞察时,他们可以按照需要构建灵活的标签宽表,在进行分析报表固化时,也可以复用该主题标签库。
Id-Mapping
用户标示打通是画像系统中非常基础和重要的处理环节之一。在目前的系统实现中,没有将其独立作为一个模块处理,不同标示体系的数据各自加工,各自使用,各个标示存在多对多,一对多,多对一关系。在涉及到标签打通,用户触达时,经常是从多对多关系中随机选择一个进行匹配,该种做法无法保证数据质量,且因多对多的关系复杂,每天变动,给数据分析师后期的工作带来了困难。
业界为了解决这个问题,有的采用了图计算,通过计算最大联通图来串联各个id,有的采用了业务规则匹配,此次系统概设采用了后者。具体操作为,捕获在同一设备、同一平台上不同账号登录的先后顺序、频率等信息,通过强规则绑定各id标示,最终生成id到id的一对一关系。当两个id存在多种绑定关系时,通过业务经验设定不同渠道,策略下的绑定优先级,最后的一对一表只取优先级最高的绑定关系。如下表所示,表中包含了两种不同的id,以及两种id在何时通过何种方式进行的逻辑绑定。
目前来看,这种id整合策略仅能满足使用,在关联链路较长,特别是涉及到三个id以上的打通时,数据失真较大,数据质量难以保证。除了将各id体系进行简单关联,另外一种思想是在idmapping的基础上,建立全局id,在后期使用数据时都以全局id为主键,业内如阿里有oneid实现,神策有神策id实现。构建统一id可作为后期探索方向,本次不做深究。
CH标签表设计
标签表
在ES和Hive作为核心的画像系统中,离线非算法类标签从加工到可用往往需要经过标签汇聚和加载的过程,该过程时间长达数小时之多。不同标签的时效性不同,部分标签需要小时级更新,部分标签需要天级更新,但每更新时都需要全删全写,效率低、代价大。CH的bitmap和聚合表引擎为解决该问题提供了新思路。
在本方案中,标签底层存储全部使用bitmap实现,参考苏宁的分享资料,建立四个类型的标签库如下所示。在建表时选择了AggregatingMergeTree引擎,具体到标签bitmap列,采用了保留最新数据的聚合方式。在这样的设计下,相同分区内如果相同主键的数据存在多条,只会保留最新的一条。这意味着相同标签id的数据前后多次插入到相同的表后,CH自动聚合只会保留最新的bitmap。该种方案用bitmap实现了各标签异步加载,用insert轻量级实现了标签update。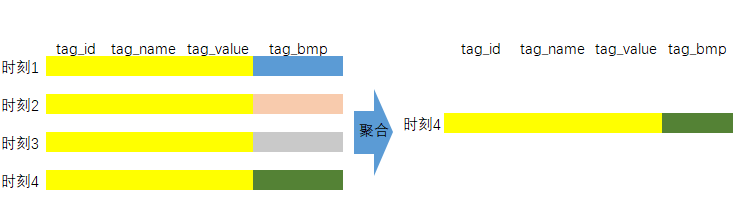
由于CH拥有众多的bitmap操作函数,此次在数值bitmap表建模上没有采用BSI的方式,而是选择了和非数值标签类型相似的表结构,在统一策略的情况下,同样可以实现bitmap的范围检索和聚合查询。后期依数据量决定是否需要切换为BSI方案。
标签值为字串类型的标签结果表
标签值为int类型的标签结果表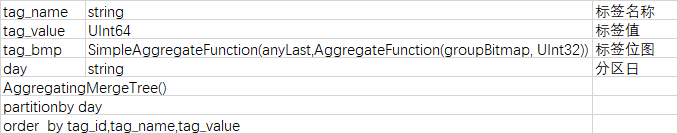
标签值为double类型的标签结果表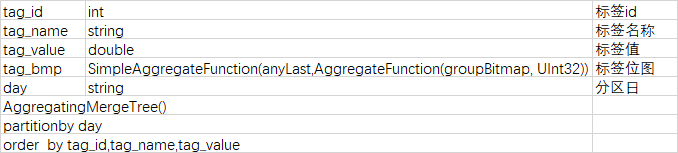
标签值为date类型的标签结果表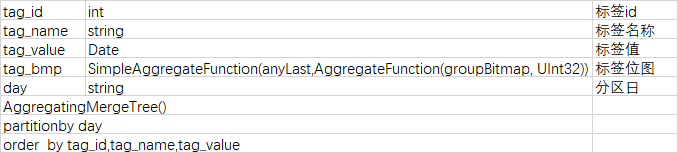
事件表
相对比标签表,事件表的限制较少。在表schema上,可以根据不同的事件灵活的选择事件表需要的字段,下面以官网banner点击事件为例说明。
不同的事件表,在元数据中会维护不同的table_col数据,该数据在事件上线时手动配置。前端获取到json数组后,根据数据渲染UI,用户可以灵活的查询出符合指定要求的人群。
标签事件联查
可以看到,标签存储的是bitmap,事件存储的是原始的明细数据,在进行标签和数据的联合查询时,需要将事件也转化为bitmap。具体的操作为,在用户圈选出符合要求的id数据后,再加一步转化为bitmap的过程(经过用户过滤后的id数据量已经较小了,使用CH自带的bitmap转化函数可以迅速的将id转化为bitmap),在这样的设计下,对人群的操作全部转化成了bitmap,实现了后续处理逻辑统一。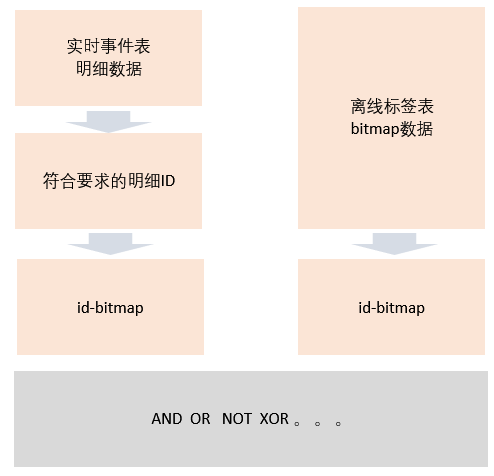
数据同步方案
实时数据同步
由于CH支持JDBC,数据同步统一使用JDBC即可解决。事件数据的上游为Kafka,针对不同事件,可以设置sparkStreaming消费数据批量周期型写入CH。
离线数据同步
CH离线标签数据的上游为hive标签主题库,在行业内,使用hive数据构建Clickhouse中bitmap数据列时,普遍采用的方案是将标签明细数据导入到Clickhouse中,再使用其内置的bitmap构造函数groupBitmapState结合group by语句构造bitmap,下文给出了该方案的示例Sql。
标签明细表
create table imei_infos(imei_id UInt32,model String,models String,sex String,age String,month Datetime) engine =MergeTreepartition by toYYYYMMDD(month)primary key (imei_id)order by (imei_id)
一张目标位图表如下
CREATE TABLE label_imei_bmp (label_name LowCardinality(String),imei_bmp AggregateFunction(groupBitmap, UInt64))ENGINE = AggregatingMergeTree()ORDER BY label_name;
基于标签明细表构建位图表(代码中的groupBitmapState函数将整型imei_id聚合成位图)
INSERT INTO label_imei_bmpSELECTmodels,groupBitmapState(toUInt64(imei_id))FROM imei_infosGROUP BY models;
另外一种方是基于标签明细数据建立Btimap物化视图表(物化视图类似mysql中的触发器,能实现当xx发生时,自动触发下游的逻辑运行),当明细数据中增加数据时,CH会自动构建对应的物化视图,具体sql不再赘述。但,无论是手动构建,还是利用物化视图自动构建,这类处理方式是把hive中的数据原样拷贝到Clickhouse中后再进行后续加工。数据出现副本就会带来数据不一致的问题,除此之外,数据来回拷贝加大了数据存储量的同时也给末端CH增加了计算压力。
CH作为数据的最终应用层,应尽量减少复杂计算,那我们能不能在外部构建好bitmap文件,再直接bulkload到CH中呢?经过相关信息检索,实现了在spark中构建bitmap文件后写入到CH,该方式大大减少了Ch的存储占用和计算压力,具体实现参操如下步骤
- spark读取hive数据
- 分组聚合
- 构造RoaringBitMap
- 拼接CRoaring格式数据
- base64编码CRoaring最终的序列化文件
- 将编码后的数据通过JDBC写入到CH中目标bitMap标签表的string类型列
- 在CH的bitmap表中通过物化列的格式解码base64字串,构造BitMap
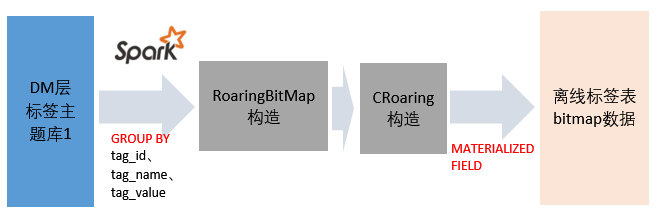
CH中的bitmap是用的CRoaring实现,java中常见的是RoaringBitMap实现,在向bitmap表数据写入时,需要对数据格式进行转化。物化列的引入是为了解决bitmap列不能直接写入的问题,更详细的内容可查阅“参考资料”章节中的文章”sparkSql&clickhouse&roaringbitmap实践”或者查看该概设文档的工程实现代码。
查询加速
过程预计算
在OLAP领域,CH属于ROLAP的范畴,与presto类似,每次查询都是从最底层的明细数据进行检索。和ROLAP对应的还有MOLAP,实现框架如Kylin、Druid,不同的是,Kylin实现了任意维度指标的提前预聚和,Druid只对最宽的维度指标进行聚合。ROLAP带来查询的灵活与多变,能满足业务方突发奇想需求,缺点是对计算力要求较高,响应较慢。MOLAP支持查询结果亚秒级输出,一般对接固定维度的报表分析,不足之处是缺乏灵活度,容易产生维度爆炸的问题。二者优点兼具的Hybird OLAP系统复杂度过高,难以推广,但在CH中,我们可以轻量级的实现部分MOLAP的特性,具体思路如下。
用户在查询和探索目标人群时,并不是如程序员一般直接输入一长串”与或非”表达式,一蹴而就。在确定目标触达、分析人群之前,他们有较长的探索过程,会去尝试各种组合条件。这个探索的过程相当于是把最终的计算压力分摊到过程中的各个阶段,我们不必到最后一刻才进行整体计算,可提前把探索的过程记录为一张bitmap表(预计算表)。该表主键由各个标签id和检索条件组合而成,用户在后续探索遇到相同的组合条件时,直接到到该预计算表获取对应结果。
相较于redis等结果缓存,此种设计方案相当于对计算的明细进行了缓存。在预计算成员标签数据更新之间,用户和用户之间可以复用缓存结果。带来的好处是计算的复杂度限制在了2~3个bitmap之间,可以实现秒级响应。
预计算标示
该方案主要考虑标签的时效型和可用性,即当发现预计算中的成员标签bitmap已经更新时,需要将query路由到标签表中原始的bitmap,重新计算该结果并替换预计算表中的对应bitmap。
使用tag_reg字段来记录标签的两两组合结果,例如”1=’M’∩2>20”(假设tag_id=1标示性别,tag_id=2标示年龄),表示男性标签和年龄大于20岁的标签做交集运算后的结果。version_code字段用来表示该组合结果是从那个标签的那个版本计算而来的,版本号的生成需要结合标签id和标签id的更新时间,这两个数据在标签元数据中都是可以得到的。具体生成逻辑可参考如下逻辑(需要考虑到版本号和标签的顺序是无关的)。
标签id1-标签更新时间戳-标签id2-标签更新时间戳(升序排列)
如要预计算功能更好的运转,需要匹配开发一套“与或非”用户查询语句解析器,该解析器可以将复杂的查询简化为两两组合查询。进一步,还可以将该功能抽象,实现从用户语言到最终执行的具体代码的转化,最终结果可以是Ch的sql,也可以是prestoSql,elasticSearch的DSL。详细逻辑参考该概设文档的工程实现代码。
人群包任意画像
用户在检索到目标人群后,想要查看这些用户的其他标签信息分布以进行更详细的数据洞察,在设计上该如何实现呢?一种可行的方案是反解码出Btimap中的id,再与标签宽表进行join查询,但这样相当于重蹈覆辙,回到了问题的出发点,我们需要一种更优雅的实现方式。针对该问题,苏宁在一次分享中提出了新的解决方案,用下图来进行过程说明。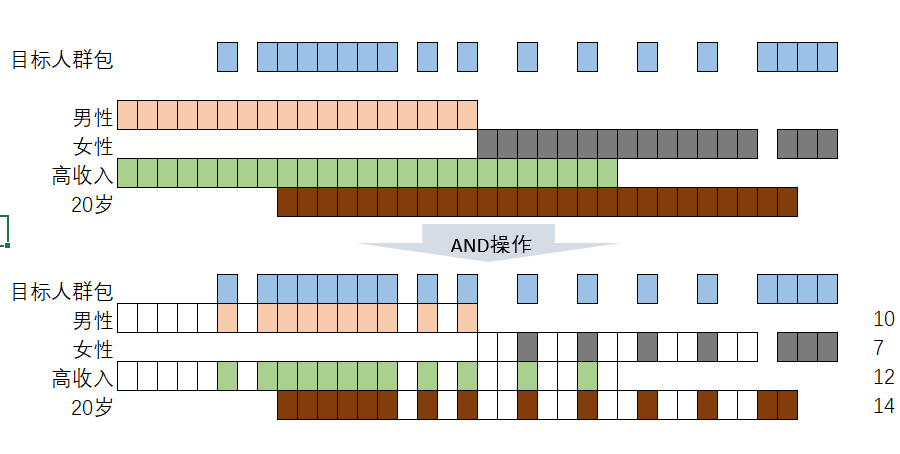
1、圈选出需要分析、触达的人群包
2、选择需要分析的各个维度bitmap
3、AND操作
4、对and操作后各维度bitmap进行基数统计
可以看到,在上述设计思想下,针对任意人群包,可以实现任意维度的数据探索。最终拼接的sql可能如下所示,其中target_crowd子查询中的tagetBitMap是经过标签、事件联合圈选出来的目标人群包,analy_bmp子查询中的tag_bmp是用户想要分析的各个标签bitmap。
selecttag_name,tag_value,bitmapAndCardinality(tag_bmp,targetBitMap) cntfrom(select1 as join_id,tag_name,tag_value,tag_bmpfrom位图标签库) analy_bmpjoin(select 1 as join_id,targetBitMap --目标人群包) target_crowdonanaly_bmp.join_id=target_crowd.join_id
从单机到分布式
截至目前,我们讨论的解决方案都是在单机上进行的。在生产环境中,仅有单台机器肯定满足不了海量的存储和计算要求,我们需要将数据进行分片(shard)。CH的分布式表和本地表都可以解决该问题,分布式表类似Mysql的分库中间件,只做逻辑上的数据整合,不真实的存储数据,本地表才是最后存储数据的表。分布式表使用简单,但在读写分布式表时有性能损耗,对应的,本地表更加高效,但需要自己对查询和存储进行路由,较为麻烦。
集群的HA
在集群环境中,除了数据的分片,另外一个重要的概念为数据副本。分片特性保证了数据的横向扩容,存储弹性可伸缩,副本的存在和CH的multi_master(非主从架构)特性保证了数据的高可用,在介绍本地表和分布式表之前先引入集群高可用。
- 集群配置
副本的写入机制有赖与zookeeper的协调,需要配置zookeeper的相关信息,具体流程和xml配置文件如下所示
在两台服务器的/etc/clickhouse-server/config.d目录下创建一个名为metrika.xml的配置文件
<?xml version="1.0"?><yandex><zookeeper-servers><node index="1"><host>hdp1</host><port>2181</port></node><node index="2"><host>hdp2</host><port>2181</port></node><node index="3"><host>hdp3</host><port>2181</port></node></zookeeper-servers></yandex>
在 /etc/clickhouse-server/config.xml 中增加
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
建立副本表
create table dm_xx_common_rept_ds (id UInt32,name String,sex String,create_time Datetime) engine =ReplicatedAggregatingMergeTree ('/clickhouse/tables/01/dm_xx_common_rept_ds','rept_1')partition by toYYYYMMDD(create_time)primary key (id)order by (id);----副本表create table dm_xx_common_rept_ds (id UInt32,name String,sex String,create_time Datetime) engine =ReplicatedAggregatingMergeTree ('/clickhouse/tables/01/dm_xx_common_rept_ds','rept_2')partition by toYYYYMMDD(create_time)primary key (id)order by (id);
为了让AggregateMergeTree引擎的本地表拥有副本的能力,在有上述建表语句中,使用了新的表引擎,ReplicatedAggregatingMergeTree,其中 的参数说明如下。
第一参数是分片的zk_path,按照 /clickhouse/tables/{shard}/{table_name} 的格式写。
第二个参数是副本名称,相同的分片副本名称不能相同。分布式表实现
分布式表的的配置信息记录在/etc/clickhouse-server/config.d/metrika.xml中,具体配置信息不详述,参考文末的相关资料。在进行合理的配置后,通过on cluster关键字实现集群中同时建立本地表,已本文中的bitmap表为例
create table st_order_mt on cluster gmall_cluster (tag_id UInt32,tag_name String,tag_value String,tag_bmp SimpleAggregateFunction(anyLast,AggregateFunction(groupBitmap,UInt32))day String) engine =ReplicatedAggregatingMergeTree('/clickhouse/tables/{shard}/st_order_mt_0105','{replica}')partition by dayprimary key (id)order by (tag_id,tag_name,tag_value);
操作分布式表的方式和操作本地表一样,集群会自动处理内部逻辑。
本地表实现
操作本地表需要提前对数据进行路由,即同一个用户的数据导向同一台机器,下图是该方案的概要实现,具体实现参考工程代码。
入库路由

- 查询路由

运维风险及解决
数据迁移和扩容
经过10多年的发展,Hadoop生态下的基石HDFS提供了完整数据扩容缩容解决方案,能实现自动化容量平衡,集群节点无感知上下线。与之相比,CH在集群进行扩容时,需要手动设置各节点的存储比率,过程较为繁琐,目前可行的方案汇总如下。
TODO
遗留问题和思考
hive中也可以存储bitmap的序列化文件,能否自定义presto的UDF直接操作bitmap,减少了数据迁出,集群运维问题。
能否SparkSql自定义bitmap操作函数,进一步简化步骤
画像引擎的微服务化。
考虑到后期规则引擎的引用,可以将计算框架切换为flink,收敛技术栈。
参考资料
实体书 - clickhouse原理解析与应用实践 -朱凯-机械工业出版社
idmapping策略 :http://www.woshipm.com/pd/4238062.html
sparkSql&clickhouse&roaringbitmap实践 :https://blog.csdn.net/qq_27639777/article/details/111005838
sparkSql定义Bitmap处理函数 : https://blog.csdn.net/qq_27639777/article/details/110368117
HOLAP : https://thutmose.blog.csdn.net/article/details/108863376
Clickhouse集群扩容: https://www.it610.com/article/1279987102913675264.htm
clickhouse在阿里云的实践 https://www.bilibili.com/video/BV1pX4y15758
clickhouse在Bilibili的实践(OLAP建设) https://www.bilibili.com/video/BV1hU4y1W71L
clickhouse materialized view 踩坑记录 https://listenerri.com/2019/12/23/clickhouse-materialized-view-%E8%B8%A9%E5%9D%91%E8%AE%B0%E5%BD%95/
clickhose的副本和分片 https://www.cnblogs.com/shengyang17/p/14282944.html
各种本地表平滑副本 https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/replication/
BY — 西红柿

若有收获,就点个赞吧
0 人点赞
