前言
shuffle过程中有一个可选的流程Combiner,这个流程是做什么的?
概述
- Combiner是MR程序中Mapper和Reducer之外的一种组件
- Combiner组件的父类就是Reducer
- Combiner和Reducer功能上是一致的,两者的区别在于运行的位置
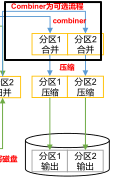
- Combiner是在每一个MapTask所在的节点运行
- Reducer是接收全局所有Mapper的输出结果
- Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小IO【磁盘IO+网络IO】。
Combiner默认是不开启的,能够应用Combiner的前提是不能影响最终的业务逻辑,有些需求是不能用Combiner的比如求平均数,而且Combiner的输出kv应该跟Reducer的输入kv类型要对应起来

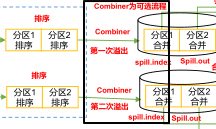
Combiner只会出现两次
- 环形缓冲区中数据溢写到磁盘之前可合并一次
- 对多个零时文件进行归并排序在落盘之前也可合并一次
对WordCount案例使用Combiner
方法一
1. 增加一个 WordCountCombiner类继承 Reducer
combiner操作的逻辑和Reducer逻辑是一致的public class WordcountCombiner extends Reducer<Text, IntWritable, Text,IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { // 1 汇总操作 int count = 0; for(IntWritable v :values){ count += v.get(); } // 2 写出 context.write(key, new IntWritable(count)); } }2. job中设置一下
// 指定需要使用 combiner,以及用哪个类作为 combiner 的逻辑 job.setCombinerClass(WordCountCombiner.class);方法二
因为wordcount的Reducer和combiner的逻辑是一致的,所以可以直接将wordcount的Reducer作为combiner即可job.setCombinerClass(WordcountReducer.class);

若有收获,就点个赞吧
0 人点赞
