04.集合
/—Collection接口:单列集合,存储对象
/—List接口:存储有序,可重复对象。—>动态数组,替换原来的数组
/—ArrayList List的主要实现类;线程不安全,效率高;底层使用Object[] elementData封装
/—LinkedList 底层使用双向链表存储,对于频繁的插入删除效率高
/—Vector List的古老实现类,线程安全,效率低;底层使用Object[] elementData封装
1.Collection


注意:add一般只返回true;
- Iterator接口 ``` boolean hasNext();是否有元素 next();返回迭代的下一个元素。
Collection 中iterator()方法返回在此collection上迭代的迭代器
使用:
Collection
3. 增强for循环,底层也是使用迭代器。
for(集合/数组的数据类型 变量名:集合或数组名) for(int i:arr){ syso(i); }
4. 存储自定义对象,需要需要重写equals方法
<a name="65f4fa44ad4257f4f09ea1ed132a0c4b_h2_1"></a>
## 2.泛型
创建对象时就会确定泛型的数据类型。
1. 使用泛型的好处
1. 避免了类型转换的麻烦
2. 把运行期异常提升到了编译期
2. 弊端:泛型是什么类型就只能存储什么类型的数据。
3. 不使用泛型的好处:可以存储任意类型的数据
4. 定义和使用含有泛型的类:
public class GenericClass
//不写默认泛型为object
GenericClass
5. 定义与使用含有泛型的方法:
格式: 修饰符 <泛型> 返回值类型 方法名(参数列表){ } 含有泛型的方法调用时确定泛型的数据类型,传递什么类型的参数,泛型就是什么类型。
public
6. 定义和使用含有泛型的接口
public interface GenericInterface{ public abstract void method(I i); }
//实现类 public class GenericInterfaceImpl {
}
7. <br />
<a name="9384e8d2ee96f3d2e6b82f044edabefa_h2_2"></a>
## 3.数据结构
<a name="b0d7fa097b93e21e9e0e122ce0974e46_h5_0"></a>
##### 1.栈
先进后出
<a name="f7828ee9d6a6667d280cb6894ec321b5_h5_1"></a>
##### 2.队列
先进先出
<a name="9bf5b3e8eb3c35b8041fe0a9678a33fb_h5_2"></a>
##### 3.数组
查询快,增删慢
<a name="847dc102d2bc4e3bc08904f3c978dd00_h5_3"></a>
##### 4.链表
查询慢,增删快
<a name="655e774585fec5042e5a3dc7ab9a5d5e_h5_4"></a>
##### 5.红黑树

<a name="8a2a941c40895aa1c53342c1646e4714_h2_3"></a>
## 4.List集合
1. 特点:有序集合有索引,包含了一些有索引的方法允许存储重复元素
1. 特有方法:
List
//遍历 1.普通循环遍历 2.迭代器遍历 3.增强for遍历
3. ArrayList源码分析:
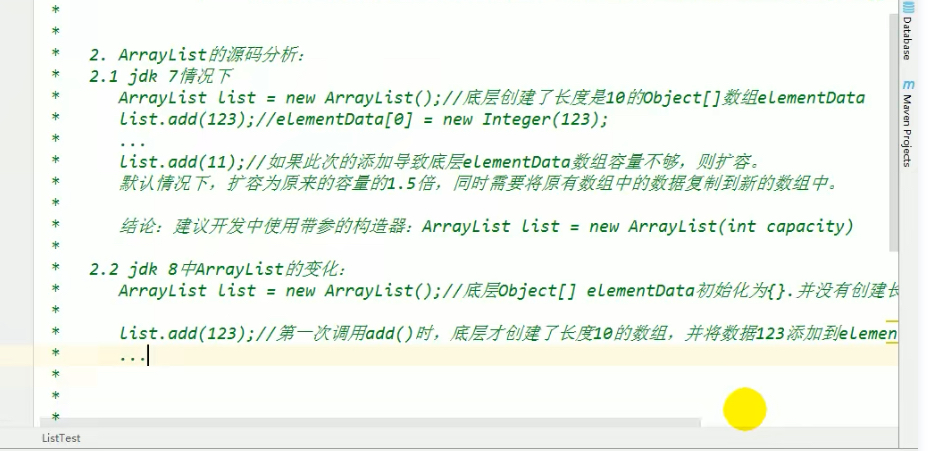
4. 面试题:ArrayList LinkedList Vector的异同
相同:都是List接口的实现类,存储数据特点相同<br />看文章头部
5. 常用方法
> 增 add
> 删 remove
> 查 get
> 改 set
> 插 add(index,Object)
> 长度 size()
> 遍历:迭代器
> 增强for循环
> 普通循环
<a name="060413701c65c9cba228ab9433784f84_h2_4"></a>
## 5.Set集合
1. 特点:无序,不可重复
1. /--set接口:无序,不可重复
/--HashSet:Set的主要实现类,线程不安全,可以存null<br />/--LinkedHashSet作为HashSet的子类,遍历内部数据时,可以按照添加的顺序访问<br />/--TreeSet:红黑树存储:可按照添加对象的指定属性进行排序。
3. HashCode方法
hashset:添加时先调用hashcode()方法,计算哈希值,而后通过哈希值计算索引位置,该位置无元素,添加成功,有元素则同一下标以链表方式存储,如果哈希值不同,则添加成功,哈希值相同则调用equals()方法比较:<br />返回true,添加失败<br />返回false,添加成功。<br />元素添加位置:七上八下
4. set中添加对象,一定要重写相关类的hashcode和equals方法。且尽量保持一致性。用数字31的好处...
4. Treeset
添加同种类对象。<br />两种排序方式:自然排序:实现compareTo()<br />定制排序:Comparator
<a name="ede46606279453049fe343b97d395ab7_h2_5"></a>
## 6.Collections
> Collections coll = new ArrayList();
> 1.coll.add()只能返回true
> 3.coll.contains()会调用元素所在类的equals方法,所以最好重写添加元素所在类的equals方法。
> containsAll(Collection coll);
>
> 4.coll.remove(),也会调用元素的equals
> removeAll()
> 5.retainAll();求交集
> 6.coll.equals(),逐个比较。
> 7.hashCode(),返回hash值,定义在object中。
> 8.toArray(),集合到数组的转换
> 9.Arrays.asList(123,456);返回list
> 10.iterator()返回迭代器
> iterator.remove();
> 
<a name="cd74a2ebb498dd4e91b05da25fe3061e_h2_6"></a>
## 7.Map集合
1. 结构:
|----Map:双列数据key-value<br />|----HashMap:作为Map主要实现类;线程不安全,效率高;可存储null的key与value<br />|----LinkedHsahMap:保证遍历时按照添加的顺序遍历<br />在原有的HashMap底层结构基础上添加了一对指针。对于频繁的遍历效率高于HashMap();<br />|----TreeMap:排序,按照key自然或定制排序。<br />底层使用红黑树<br />|----HashTable:作为Map的古老实现类,线程安全,效率低<br />|----Properties:常用来处理配置文件,key和value大都是String类型<br />面试题:<br />HashMap的底层实现原理<br />HashMap和HashTable的异同
2. key无序,不可重复,使用Set存储。
key所在的类要重写equals和hashcode方法。<br />value无序可重复,使用Collection存储所在类要重写equals方法<br />一对键值对组成Entry,无序不可重复,使用Set存储所有的entry
3. HashMap底层实现原理:
jdk7:
```java
HashMap map = new HashMap();
//实例化后底层创建长度为16的一维数组Entry[] table。
map.put(key1,value1);
//调用key1所在类的hashcode()方法,计算在entry[]数组的位置
如果此位置为空,则entry1(key1,value1)添加成功。 ---情况1
如果此位置不为空,比较key1与已经存在的一个或多个数据的哈希值:
不同,则entry1添加成功 ---情况2
key1的哈希值与某一数据相同,继续比较,调用key1所在类的equals(key2):
如果equals返回false,entry1添加成功 ---情况3
返回true,则使用value1替换value2。
默认的扩容方式为:当超出临界值并且要添加的位置不为空时,扩容为原来的2倍,并将数据复制过来。
jdk8:
- new hashMap():底层没有创建长度为16的数组
- jdk8底层数组是Node[],不是Entry[]
- 首次调用put()方法时,底层创建长度为16的数组
- jdk7底层结构:数组+链表 jdk8底层结构:数组+链表+红黑树
当数组某个索引位置以链表存在的数据个数>8且当前数组长度>64 ,则数据以红黑树存储

- Map常用方法:



- TreeMap
向TreeMap中添加键值对,要求Key必须属于同一个类。
自然排序,定制排序。
- HashTable子类:Properties
key,value都是String类型,主要用于处理配置文件。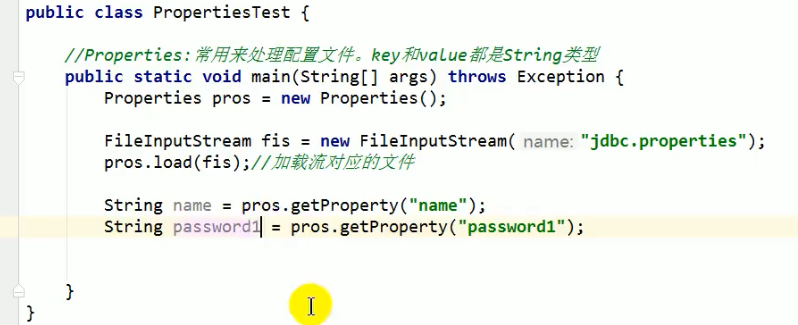
- Collections工具类:
操作Collection和Map的工具类
List dest = Arrays.asList(new Object[list.size()]);
Collections.copy(dest,list);
//copy需要dest.size>=list.size

若有收获,就点个赞吧
0 人点赞
