Python入门
为什么要学习Python
【人生苦短,我用Python】
(1)Python是一种动态的脚本语言,学习成本大大低于Java等编程语言,因此对于我们测试人员来说,如果需要掌握一门语言,Python就是最好的选择;
(2)由于Python有丰富的第三方库,几乎想要的功能,都能找到对应的库,而我们应用这些库的时候,只考虑怎么去使用这些库提供的API而不用考虑怎么去实现,十分的方便;
(3)Python开发效率很高,同样的任务大约是java的10倍,C/C++的10-20倍,当然这个统计来源于一些编程人员的感受,并不是精确的数值,但是也可以看出其开发效率之高。我们测试人员一般都会主要以手工测试为主,因此不可能全职来运用某种语言实现,肯定需要选择效率高的;
(4)Python支持多种系统,linux、mac上都默认安装了Python,windows更不用说,当我们测试需要在各种平台运行脚本的时候,几乎不用考虑跨平台。
基础语法
标识符
- 第一个字符必须是字母表中字母或下划线 _ 。
- 标识符的其他的部分由字母、数字和下划线组成。
-
注释
三种方式:
单行注释以
#开头- 多行注释用三个单引号
'''将注释括起来 - 多行注释用三个双引号
"""将注释括起来
示例代码如下:
#!/usr/bin/python3# 这是一个注释'''这是多行注释,用三个单引号这是多行注释,用三个单引号这是多行注释,用三个单引号'''"""这是多行注释,用三个单引号这是多行注释,用三个单引号这是多行注释,用三个单引号"""
行与缩进
与多数语言的{}不同,在Python中不使用{}作为代码块,而是使用缩进。
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。实例如下:
if True:print ("True")else:print ("False")
print输出
print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end=””:
#!/usr/bin/python3x="a"y="b"# 换行输出print( x )print( y )print('---------')# 不换行输出print( x, end=" " )print( y, end=" " )print()#结果ab---------a b
变量与函数
变量
变量(Variable)是存放数据值的容器。每个变量都拥有独一无二的名字,通过变量的名字就能找到变量中的数据。
从底层看,程序中的数据最终都要放到内存(内存条)中,变量其实就是这块内存的名字。
和变量相对应的是常量(Constant),它们都是用来“盛装”数据的小箱子,不同的是:变量保存的数据可以被多次修改,而常量一旦保存某个数据之后就不能修改了。
与一些语言(比如C和JAVA)不同,Python是弱类型语言。强类型语言和弱类型语言的区别就在于:强类型语言的变量类型是在变量定义之初就确定了的,不可更改了,而弱类型语言的变量类型可以随时修改。
C:int a = 1;a = "1"; // 报错JAVA:int a = 1;a = "1"; // 报错JAVASCRIPT:var a = 1;a = "1"; // 正常PYTHON:a = 1a = "1" // 正常
函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。
在 Python 中,定义函数使用 def 语句。一个函数主要由三部分构成:
- 函数名
- 函数参数
- 函数返回值
我们来分析一下这些代码:def function(arg):# Do somethingreturn
首先,我们使用def关键字定义了一个函数function,这个函数接受一个参数arg,定义完函数后用一个半角的冒号结束这行。
最后一行是一个return关键字,表示返回一个值,这里是返回一个空(None)如果用变量接收,将会是一个None。如果不写这行代码,编译将会报错,因为这个函数里什么也没有(注释不算),如果你不想写return,你可以用pass来代替,也表示结束,但是不返回一个值(接收的话还是None)。位置参数
```python def test(a, b): print a, b
a和b必须按顺序传入
test(1, 2)
<a name="ilEHs"></a>#### 关键字参数```pythondef test(a, b):print a, b# a和b可以打乱顺序传入test(b=2, a=1)# 有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序,以下用法就是错误的test(b=2, 1)
默认参数
def test(a, b=3):print a, b# b可以不传入,使用默认值3test(a=5)
可变位置参数
def test(a, *args):# 接收到的args是一个元组tupleprint a, argstest(1, 2, 3)
可变关键字参数
def test(a, **kwargs):# 接收到的kwargs是一个字典dictprint a, kwargstest(1, b=2, c=3)
组合使用
def test(a, b=2, *args, **kwargs):print a, b, args, kwargstest(1, 2, 3, 4, c=5, d=6)
数据类型
字符串
Python中的字符串用单引号 ‘ 或双引号 “ 括起来,可以用加号将两个字符串合并,同时使用反斜杠 \ 转义特殊字符。
name = '小明'age = '18岁'print('合并字符串:', name + age) # 合并字符串: 小明18岁
格式化字符串:%s
name= "I'm %s." % ('xiaoming')print(name) # I'm xiaoming.
Python 访问子字符串,可以使用方括号 [] 来截取字符串
var1 = 'Hello World!'var2 = "Runoob"print ("var1[0]: ", var1[0]) # Hprint ("var2[1:5]: ", var2[1:5]) # unno
数字
整型
整数英文为 integer 。代码中的整数跟我们平常认识的整数一样,包括正整数、负整数和零,是没有小数点的数字。Python 可以处理任意大小的整数,例如:1,100,-8080,0,等等。
浮点型
列表
列表(List)是一种有序的集合,可以随时添加和删除其中的元素。列表也可以使用切片,具体用法和上面讲得字符串类似。
常用的列表方法:
index
index 方法用于从列表中找出某个元素的位置,如果有多个相同的元素,则返回第一个元素的位置。
看看例子:
>>> numbers = [1, 2, 3, 4, 5, 5, 7, 8]>>> numbers.index(5) # 列表有两个 5,返回第一个元素的位置4>>> numbers.index(2)1>>> words = ['hello', 'world', 'you', 'me', 'he']>>> words.index('me')3>>> words.index('her') # 如果没找到元素,则会抛出异常Traceback (most recent call last):File "<stdin>", line 1, in <module>ValueError: 'her' is not in list
count
count 方法用于统计某个元素在列表中出现的次数。
看看例子:
>>> numbers = [1, 2, 3, 4, 5, 5, 6, 7]>>> numbers.count(2) # 出现一次1>>> numbers.count(5) # 出现了两次2>>> numbers.count(9) # 没有该元素,返回 00
append
append 方法用于在列表末尾增加新的元素。
看看例子:
>>> numbers = [1, 2, 3, 4, 5, 5, 6, 7]>>> numbers.append(8) # 增加 8 这个元素>>> numbers[1, 2, 3, 4, 5, 5, 6, 7, 8]>>> numbers.append([9, 10]) # 增加 [9, 10] 这个元素>>> numbers[1, 2, 3, 4, 5, 5, 6, 7, 8, [9, 10]]
extend
extend 方法将一个新列表的元素添加到原列表中。
看看例子:
>>> a = [1, 2, 3]>>> b = [4, 5, 6]>>> a.extend(b)>>> a[1, 2, 3, 4, 5, 6]>>>>>> a.extend(3)Traceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: 'int' object is not iterable>>> a.extend([3])>>> a[1, 2, 3, 4, 5, 6, 3]
注意到,虽然 append 和 extend 可接收一个列表作为参数,但是 append 方法是将其作为一个元素添加到列表中,而 extend 则是将新列表的元素逐个添加到原列表中。
insert
insert 方法用于将某个元素添加到某个位置。
看看例子:
>>> numbers = [1, 2, 3, 4, 5, 6]>>> numbers.insert(3, 9)>>> numbers[1, 2, 3, 9, 4, 5, 6]
pop
pop 方法用于移除列表中的一个元素(默认是最后一个),并且返回该元素的值。
看看例子:
>>> numbers = [1, 2, 3, 4, 5, 6]>>> numbers.pop()6>>> numbers[1, 2, 3, 4, 5]>>> numbers.pop(3)4>>> numbers[1, 2, 3, 5]
remove
remove 方法用于移除列表中的某个匹配元素,如果有多个匹配,则移除第一个。
看看例子:
>>> numbers = [1, 2, 3, 5, 6, 7, 5, 8]>>> numbers.remove(5) # 有两个 5,移除第 1 个>>> numbers[1, 2, 3, 6, 7, 5, 8]>>> numbers.remove(9) # 没有匹配的元素,抛出异常Traceback (most recent call last):File "<stdin>", line 1, in <module>ValueError: list.remove(x): x not in list
reverse
reverse 方法用于将列表中的元素进行反转。
看看例子:
>>> numbers = [1, 2, 3, 5, 6, 7, 5, 8]>>> numbers.reverse()>>> numbers[8, 5, 7, 6, 5, 3, 2, 1]
sort
sort 方法用于对列表进行排序,注意该方法会改变原来的列表,而不是返回新的排序列表,另外,sort 方法的返回值是空。
看看例子:
>>> a = [4, 3, 6, 8, 9, 1]>>> b = a.sort()>>> b == None # 返回值为空True>>> a[1, 3, 4, 6, 8, 9] # 原列表已经发生改变
如果我们不想改变原列表,而是希望返回一个排序后的列表,可以使用 sorted 函数,如下:
>>> a = [4, 3, 6, 8, 9, 1]>>> b = sorted(a) # 返回一个排序后的列表>>> a[4, 3, 6, 8, 9, 1] # 原列表没有改变>>> b[1, 3, 4, 6, 8, 9] # 这是对原列表排序后的列表
注意到,不管是 sort 方法还是 sorted 函数,默认排序都是升序排序。如果你想要降序排序,就需要指定排序参数了。比如,对 sort 方法,可以添加一个 reverse 关键字参数,如下:
>>> a = [4, 3, 6, 8, 9, 1]>>> a.sort(reverse=True) # 反向排序>>> a[9, 8, 6, 4, 3, 1]
该参数对 sorted 函数同样适用:
>>> a = [4, 3, 6, 8, 9, 1]>>> sorted(a, reverse=True)[9, 8, 6, 4, 3, 1]
除了 reverse 关键字参数,还可以指定 key 关键字参数,它为每个元素创建一个键,然后所有元素按照这个键来排序,比如我们想根据元素的长度来排序:
>>> s = ['ccc', 'a', 'bb', 'dddd']>>> s.sort(key=len) # 使用 len 作为键函数,根据元素长度排序>>> s['a', 'bb', 'ccc', 'dddd']
另外,我们还可以使用 sorted 进行多列(属性)排序。
>>> students = [('john', 'B', 15),('jane', 'A', 12),('dave', 'B', 10),('ethan', 'C', 20),('peter', 'B', 20),('mike', 'C', 16)]>>># 对第 3 列排序 (从小到大)>>> sorted(students, key=lambda student: student[2])[('dave', 'B', 10),('jane', 'A', 12),('john', 'B', 15),('mike', 'C', 16),('ethan', 'C', 20),('peter', 'B', 20)]# 对第 2 列排序(从小到大),再对第 3 列从大到小排序>>> sorted(students, key=lambda student: (student[1], -student[2]))[('jane', 'A', 12),('peter', 'B', 20),('john', 'B', 15),('dave', 'B', 10),('ethan', 'C', 20),('mike', 'C', 16)]
字符串和元组是不可变的,而列表是可变(mutable)的,可以对它进行随意修改。我们还可以将字符串和元组转换成一个列表,只需使用 list 函数,比如:
>>> s = 'hello'>>> list(s)['h', 'e', 'l', 'l', 'o']>>> a = (1, 2, 3)>>> list(a)[1, 2, 3]
元组
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号 ( ),列表使用方括号 [ ]。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
>>> a = (1, 2, 3) # a 是一个元组>>> a(1, 2, 3)>>> a[0] = 6 # 元组是不可变的,不能对它进行赋值操作Traceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: 'tuple' object does not support item assignment
创建一个值的元组需要在值后面再加一个逗号,这个比较特殊,需要牢牢记住:
>>> a = (12,) # 在值后面再加一个逗号>>> a(12,)>>> type(a)<type 'tuple'>>>>>>> b = (12) # 只是使用括号括起来,而没有加逗号,不是元组,本质上是 b = 12>>> b12>>> type(b)<type 'int'>
元组也可以对它进行索引、分片等。由于它是不可变的,因此就没有类似列表的 append, extend, sort 等方法。
字典
字典是 Python 中唯一的映射类型,每个元素由键(key)和值(value)构成,键必须是不可变类型,比如数字、字符串和元组。
这里先介绍字典的几个基本操作:
创建字典
字典可以通过下面的方式创建:
>>> d0 = {} # 空字典>>> d0{}>>> d1 = {'name': 'ethan', 'age': 20}>>> d1{'age': 20, 'name': 'ethan'}>>> d1['age'] = 21 # 更新字典>>> d1{'age': 21, 'name': 'ethan'}>>> d2 = dict(name='ethan', age=20) # 使用 dict 函数>>> d2{'age': 20, 'name': 'ethan'}>>> item = [('name', 'ethan'), ('age', 20)]>>> d3 = dict(item)>>> d3{'age': 20, 'name': 'ethan'}
遍历字典
遍历字典有多种方式,这里先介绍一些基本的方式,后文会介绍一些高效的遍历方式。
>>> d = {'name': 'ethan', 'age': 20}>>> for key in d:... print '%s: %s' % (key, d[key])...age: 20name: ethan>>> d['name']'ethan'>>> d['age']20>>> for key in d:... if key == 'name':... del d[key] # 要删除字典的某一项...Traceback (most recent call last):File "<stdin>", line 1, in <module>RuntimeError: dictionary changed size during iteration>>>>>> for key in d.keys(): # python2 应该使用这种方式, python3 使用 list(d.keys())... if key == 'name':... del d[key]...>>> d{'age': 20}
在上面,我们介绍了两种遍历方式:for key in d 和 for key in d.keys(),如果在遍历的时候,要删除键为 key 的某项,使用第一种方式会抛出 RuntimeError,使用第二种方式则不会。
判断键是否在字典里面
有时,我们需要判断某个键是否在字典里面,这时可以用 in 进行判断,如下:
>>> d = {'name': 'ethan', 'age': 20}>>> 'name' in dTrue>>> d['score'] # 访问不存在的键,会抛出 KeyErrorTraceback (most recent call last):File "<stdin>", line 1, in <module>KeyError: 'score'>>> 'score' in d # 使用 in 判断 key 是否在字典里面False
字典常用方法
clear
clear 方法用于清空字典中的所有项,这是个原地操作,所以无返回值(或者说是 None)。
看看例子:
>>> d = {'name': 'ethan', 'age': 20}>>> rv = d.clear()>>> d{}>>> print rvNone
再看看一个例子:
>>> d1 = {}>>> d2 = d1>>> d2['name'] = 'ethan'>>> d1{'name': 'ethan'}>>> d2{'name': 'ethan'}>>> d1 = {} # d1 变为空字典>>> d2{'name': 'ethan'} # d2 不受影响
在上面,d1 和 d2 最初对应同一个字典,而后我们使用 d1 = {} 使其变成一个空字典,但此时 d2 不受影响。如果希望 d1 变成空字典之后,d2 也变成空字典,则可以使用 clear 方法:
>>> d1 = {}>>> d2 = d1>>> d2['name'] = 'ethan'>>> d1{'name': 'ethan'}>>> d2{'name': 'ethan'}>>> d1.clear() # d1 清空之后,d2 也为空>>> d1{}>>> d2{}
copy
copy 方法实现的是浅复制(shallow copy)。它具有以下特点:
- 对可变对象的修改保持同步;
- 对不可变对象的修改保持独立;
看看例子:
# name 的值是不可变对象,books 的值是可变对象>>> d1 = {'name': 'ethan', 'books': ['book1', 'book2', 'book3']}>>> d2 = d1.copy()>>> d2['name'] = 'peter' # d2 对不可变对象的修改不会改变 d1>>> d2{'books': ['book1', 'book2', 'book3'], 'name': 'peter'}>>> d1{'books': ['book1', 'book2', 'book3'], 'name': 'ethan'}>>> d2['books'].remove('book2') # d2 对可变对象的修改会影响 d1>>> d2{'books': ['book1', 'book3'], 'name': 'peter'}>>> d1{'books': ['book1', 'book3'], 'name': 'ethan'}>>> d1['books'].remove('book3') # d1 对可变对象的修改会影响 d2>>> d1{'books': ['book1'], 'name': 'ethan'}>>> d2{'books': ['book1'], 'name': 'peter'}
和浅复制对应的是深复制(deep copy),它会创造出一个副本,跟原来的对象没有关系,可以通过 copy 模块的 deepcopy 函数来实现:
>>> from copy import deepcopy>>> d1 = {'name': 'ethan', 'books': ['book1', 'book2', 'book3']}>>> d2 = deepcopy(d1) # 创造出一个副本>>>>>> d2['books'].remove('book2') # 对 d2 的任何修改不会影响到 d1>>> d2{'books': ['book1', 'book3'], 'name': 'ethan'}>>> d1{'books': ['book1', 'book2', 'book3'], 'name': 'ethan'}>>>>>> d1['books'].remove('book3') # 对 d1 的任何修改也不会影响到 d2>>> d1{'books': ['book1', 'book2'], 'name': 'ethan'}>>> d2{'books': ['book1', 'book3'], 'name': 'ethan'}
get
当我们试图访问字典中不存在的项时会出现 KeyError,但使用 get 就可以避免这个问题。
看看例子:
>>> d = {}>>> d['name']Traceback (most recent call last):File "<stdin>", line 1, in <module>KeyError: 'name'>>> print d.get('name')None>>> d.get('name', 'ethan') # 'name' 不存在,使用默认值 'ethan''ethan'>>> d{}
setdefault
setdefault 方法用于对字典设定键值。使用形式如下:
dict.setdefault(key, default=None)
看看例子:
>>> d = {}>>> d.setdefault('name', 'ethan') # 返回设定的默认值 'ethan''ethan'>>> d # d 被更新{'name': 'ethan'}>>> d['age'] = 20>>> d{'age': 20, 'name': 'ethan'}>>> d.setdefault('age', 18) # age 已存在,返回已有的值,不会更新字典20>>> d{'age': 20, 'name': 'ethan'}
可以看到,当键不存在的时候,setdefault 返回设定的默认值并且更新字典。当键存在的时候,会返回已有的值,但不会更新字典。
update
update 方法用于将一个字典添加到原字典,如果存在相同的键则会进行覆盖。
看看例子:
>>> d = {}>>> d1 = {'name': 'ethan'}>>> d.update(d1) # 将字典 d1 添加到 d>>> d{'name': 'ethan'}>>> d2 = {'age': 20}>>> d.update(d2) # 将字典 d2 添加到 d>>> d{'age': 20, 'name': 'ethan'}>>> d3 = {'name': 'michael'} # 将字典 d3 添加到 d,存在相同的 key,则覆盖>>> d.update(d3)>>> d{'age': 20, 'name': 'michael'}
items/iteritems
items 方法将所有的字典项以列表形式返回,这些列表项的每一项都来自于(键,值)。我们也经常使用这个方法来对字典进行遍历。
看看例子:
>>> d = {'name': 'ethan', 'age': 20}>>> d.items()[('age', 20), ('name', 'ethan')]>>> for k, v in d.items():... print '%s: %s' % (k, v)...age: 20name: ethan
iteritems 的作用大致相同,但会返回一个迭代器对象而不是列表,同样,我们也可以使用这个方法来对字典进行遍历,而且这也是推荐的做法:
>>> d = {'name': 'ethan', 'age': 20}>>> d.iteritems()<dictionary-itemiterator object at 0x109cf2d60>>>> for k, v in d.iteritems():... print '%s: %s' % (k, v)...age: 20name: ethan
keys/iterkeys
keys 方法将字典的键以列表形式返回,iterkeys 则返回针对键的迭代器。
看看例子:
>>> d = {'name': 'ethan', 'age': 20}>>> d.keys()['age', 'name']>>> d.iterkeys()<dictionary-keyiterator object at 0x1077fad08>
values/itervalues
values 方法将字典的值以列表形式返回,itervalues 则返回针对值的迭代器。
看看例子:
>>> d = {'name': 'ethan', 'age': 20}>>> d.values()[20, 'ethan']>>> d.itervalues()<dictionary-valueiterator object at 0x10477dd08>
pop
pop 方法用于将某个键值对从字典移除,并返回给定键的值。
看看例子:
>>> d = {'name': 'ethan', 'age': 20}>>> d.pop('name')'ethan'>>> d{'age': 20}
popitem
popitem 用于随机移除字典中的某个键值对。
看看例子:
>>> d = {'id': 10, 'name': 'ethan', 'age': 20}>>> d.popitem()('age', 20)>>> d{'id': 10, 'name': 'ethan'}>>> d.popitem()('id', 10)>>> d{'name': 'ethan'}
对元素为字典的列表排序
事实上,我们很少直接对字典进行排序,而是对元素为字典的列表进行排序。
比如,存在下面的 students 列表,它的元素是字典:
students = [{'name': 'john', 'score': 'B', 'age': 15},{'name': 'jane', 'score': 'A', 'age': 12},{'name': 'dave', 'score': 'B', 'age': 10},{'name': 'ethan', 'score': 'C', 'age': 20},{'name': 'peter', 'score': 'B', 'age': 20},{'name': 'mike', 'score': 'C', 'age': 16}]
按 score 从小到大排序
>>> sorted(students, key=lambda stu: stu['score'])[{'age': 12, 'name': 'jane', 'score': 'A'},{'age': 15, 'name': 'john', 'score': 'B'},{'age': 10, 'name': 'dave', 'score': 'B'},{'age': 20, 'name': 'peter', 'score': 'B'},{'age': 20, 'name': 'ethan', 'score': 'C'},{'age': 16, 'name': 'mike', 'score': 'C'}]
需要注意的是,这里是按照字母的 ascii 大小排序的,所以 score 从小到大,即从 ‘A’ 到 ‘C’。
按 score 从大到小排序
>>> sorted(students, key=lambda stu: stu['score'], reverse=True) # reverse 参数[{'age': 20, 'name': 'ethan', 'score': 'C'},{'age': 16, 'name': 'mike', 'score': 'C'},{'age': 15, 'name': 'john', 'score': 'B'},{'age': 10, 'name': 'dave', 'score': 'B'},{'age': 20, 'name': 'peter', 'score': 'B'},{'age': 12, 'name': 'jane', 'score': 'A'}]
按 score 从小到大,再按 age 从小到大
>>> sorted(students, key=lambda stu: (stu['score'], stu['age']))[{'age': 12, 'name': 'jane', 'score': 'A'},{'age': 10, 'name': 'dave', 'score': 'B'},{'age': 15, 'name': 'john', 'score': 'B'},{'age': 20, 'name': 'peter', 'score': 'B'},{'age': 16, 'name': 'mike', 'score': 'C'},{'age': 20, 'name': 'ethan', 'score': 'C'}]
按 score 从小到大,再按 age 从大到小
>>> sorted(students, key=lambda stu: (stu['score'], -stu['age']))[{'age': 12, 'name': 'jane', 'score': 'A'},{'age': 20, 'name': 'peter', 'score': 'B'},{'age': 15, 'name': 'john', 'score': 'B'},{'age': 10, 'name': 'dave', 'score': 'B'},{'age': 20, 'name': 'ethan', 'score': 'C'},{'age': 16, 'name': 'mike', 'score': 'C'}]
集合
集合(set)和字典(dict)类似,它是一组 key 的集合,但不存储 value。集合的特性就是:key 不能重复。
先看下集合的常见操作:创建集合
set 的创建可以使用
{}也可以使用 set 函数:>>> s1 = {'a', 'b', 'c', 'a', 'd', 'b'} # 使用 {}>>> s1set(['a', 'c', 'b', 'd'])>>>>>> s2 = set('helloworld') # 使用 set(),接收一个字符串>>> s2set(['e', 'd', 'h', 'l', 'o', 'r', 'w'])>>>>>> s3 = set(['.mp3', '.mp4', '.rmvb', '.mkv', '.mp3']) # 使用 set(),接收一个列表>>> s3set(['.mp3', '.mkv', '.rmvb', '.mp4'])
遍历集合
>>> s = {'a', 'b', 'c', 'a', 'd', 'b'}>>> for e in s:... print e...acbd
添加元素
add()方法可以将元素添加到 set 中,可以重复添加,但没有效果。>>> s = {'a', 'b', 'c', 'a', 'd', 'b'}>>> sset(['a', 'c', 'b', 'd'])>>> s.add('e')>>> sset(['a', 'c', 'b', 'e', 'd'])>>> s.add('a')>>> sset(['a', 'c', 'b', 'e', 'd'])>>> s.add(4)>>> sset(['a', 'c', 'b', 4, 'd', 'e'])
删除元素
remove()方法可以删除集合中的元素, 但是删除不存在的元素,会抛出 KeyError,可改用discard()。
看看例子:>>> s = {'a', 'b', 'c', 'a', 'd', 'b'}>>> sset(['a', 'c', 'b', 'd'])>>> s.remove('a') # 删除元素 'a'>>> sset(['c', 'b', 'd'])>>> s.remove('e') # 删除不存在的元素,会抛出 KeyErrorTraceback (most recent call last):File "<stdin>", line 1, in <module>KeyError: 'e'>>> s.discard('e') # 删除不存在的元素, 不会抛出 KeyError
交集/并集/差集
Python 中的集合也可以看成是数学意义上的无序和无重复元素的集合,因此,我们可以对两个集合作交集、并集等。
看看例子:>>> s1 = {1, 2, 3, 4, 5, 6}>>> s2 = {3, 6, 9, 10, 12}>>> s3 = {2, 3, 4}>>> s1 & s2 # 交集set([3, 6])>>> s1 | s2 # 并集set([1, 2, 3, 4, 5, 6, 9, 10, 12])>>> s1 - s2 # 差集set([1, 2, 4, 5])>>> s3.issubset(s1) # s3 是否是 s1 的子集True>>> s3.issubset(s2) # s3 是否是 s2 的子集False>>> s1.issuperset(s3) # s1 是否是 s3 的超集True>>> s1.issuperset(s2) # s1 是否是 s2 的超集False
运算符
Python 中的运算符主要分为算术运算符、比较(关系)运算符、赋值运算符、逻辑运算符、位运算符、成员运算符和身份运算符共 7 大类,运算符之间也是由优先级的,下面我们就来进行具体介绍。
算术运算符
Python 的算术运算符
| 运算符 | 描述 |
|---|---|
| + | 两个数相加,或是字符串连接 |
| - | 两个数相减 |
| * | 两个数相乘,或是返回一个重复若干次的字符串 |
| / | 两个数相除,结果为浮点数(小数) |
| // | 两个数相除,结果为向下取整的整数 |
| % | 取模,返回两个数相除的余数 |
| ** | 幂运算,返回乘方结果 |
算术运算符使用频率很高,附一张直观的图: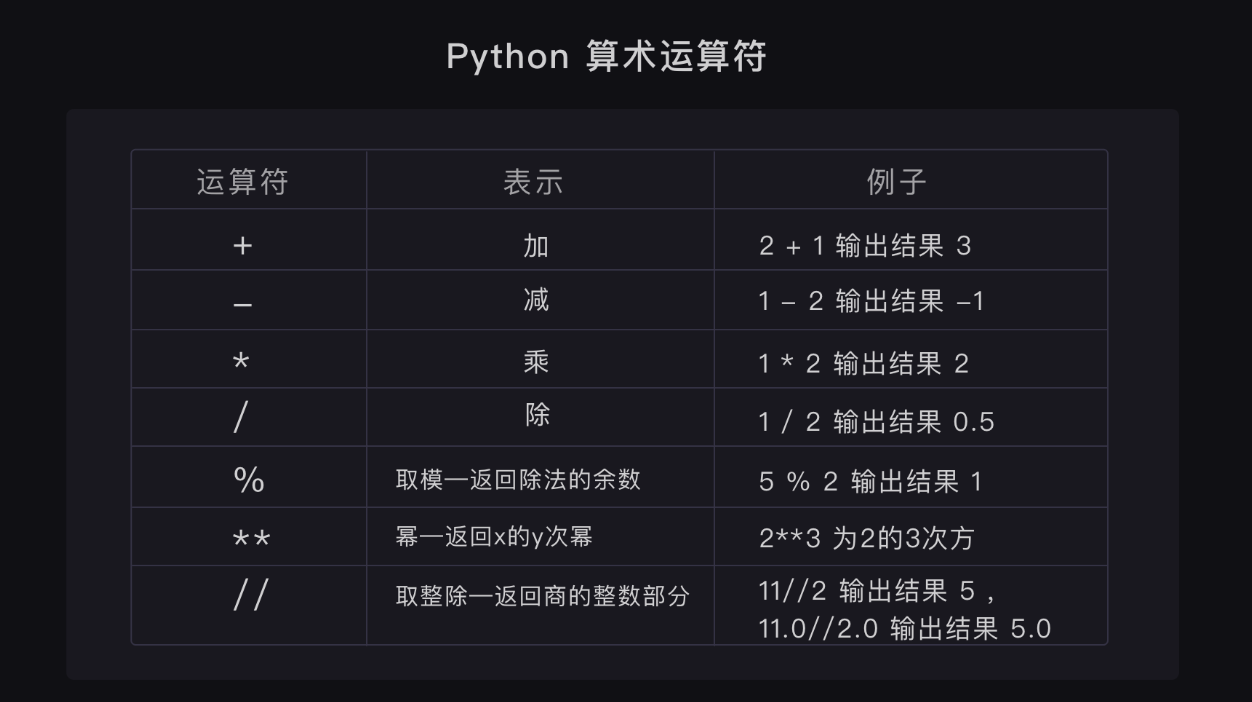
以上算术运算符的示例和运行结果如下所示:
>>> 5 + 4
9
>>> 4.3 - 2
2.3
>>> 3 7
21
>>> 2 / 4
0.5
>>> 2 // 4
0
>>> 17 % 3
2
>>> 2 * 5
32
比较(关系)运算符
Python 的比较(关系)算术运算符
| 运算符 | 描述 |
|---|---|
| == | 比较两个对象是否相等 |
| != | 比较两个对象是否不相等 |
| > | 大小比较,例如 x>y 将比较 x 和 y 的大小,如 x 比 y 大,返回 True,否则返回 False |
| < | 大小比较,例如 x<y 将比较 x 和 y 的大小,如 x 比 y 小,返回T rue,否则返回 False |
| >= | 大小比较,例如 x>=y 将比较 x 和 y 的大小,如 x 大于等于 y,返回 True,否则返回 False |
| <= | 大小比较,例如 x<=y 将比较 x 和 y 的大小,如 x 小于等于 y,返回 True,否则返回 False |
上述比较(关系)运算符的示例如下所示:
>>> a =1
>>> b =2
>>> print(a == b)
False
>>> print(a != b)
True
>>> print(a > b)
False
>>> print(a < b)
True
>>> print(a >= b)
False
>>> print(a <= b)
True
赋值运算符
Python 的赋值运算符
| 运算符 | 描述 |
|---|---|
| = | 常规赋值运算符,将运算结果赋值给变量 |
| += | 加法赋值运算符,例如 a+=b 等效于 a=a+b |
| -= | 减法赋值运算符,例如 a-=b 等效于 a=a-b |
| *= | 乘法赋值运算符,例如 a=b 等效于 a=ab |
| /= | 除法赋值运算符,例如 a/=b 等效于 a=a/b |
| %= | 取模赋值运算符,例如 a%=b 等效于 a=a%b |
| **= | 幂运算赋值运算符,例如 a=b等效于 a=ab |
| //= | 取整除赋值运算符,例如 a//=b 等效于 a=a//b |
上述赋值运算符的示例如下所示:
>>> a =2
>>> b =3
>>> a+=b
>>> print(a)
5
>>> a-=b
>>> print(a)
2
>>> a=b
>>> print(a)
6
>>> a/=b
>>> print(a)
2.0
>>> a%=b
>>> print(a)
2.0
>>> a*=b
>>> print(a)
8.0
>>> a//=b
>>> print(a)
2.0
逻辑运算符
Python 的逻辑运算符
| 运算符 | 描述 |
|---|---|
| and | 布尔“与”运算符,返回两个变量“与”运算的结果 |
| or | 布尔“或”运算符,返回两个变量“或”运算的结果 |
| not | 布尔“非”运算符,返回对变量“非”运算的结果 |
上述逻辑运算符的示例如下所示:
>>> a =True
>>> b =False
>>> print(a and b)
False
>>> print(a or b)
True
>>> print(not(a and b))
True
位运算符
Python 的位运算符
| 运算符 | 描述 |
|---|---|
| & | 按位“与”运算符:参与运算的两个值,如果两个相应位都为 1,则结果为 1,否则为 0 |
| | | 按位“或”运算符:只要对应的两个二进制位有一个为 1 时,结果就为 1 |
| ^ | 按位“异或”运算符:当两对应的二进制位相异时,结果为 1 |
| ~ | 按位“取反”运算符:对数据的每个二进制位取反,即把 1 变为 0,把 0 变为 1 |
| << | “左移动”运算符:运算数的各二进制位全部左移若干位,由“<<”右边的数指定移动的位数,高位丢弃, 低位补 0 |
| >> | “右移动”运算符:运算数的各二进制位全部右移若干位,由“>>”右边的数指定移动的位数 |
上述位运算符的示例如下所示:
>>> a=55 #a=0011 0111
>>> b=11 #b=0000 1011
>>> print(a&b)
3
>>> print(a|b)
63
>>> print(a^b)
60
>>> print(~a)
-56
>>> print(a<<3)
440
>>> print(a>>3)
6
成员运算符
Python 的成员运算符
| 运算符 | 描述 |
|---|---|
| in | 当在指定的序列中找到值时返回 True,否则返回 False |
| not in | 当在指定的序列中没有找到值时返回 True,否则返回 False |
上述成员运算符的示例如下所示:
>>> a=1
>>> b=20
>>> l = [1, 2, 3, 4, 5]
>>> print(a in l)
True
>>> print(b not in l)
True
身份运算符
Python的身份运算符
| 运算符 | 描述 |
|---|---|
| is | 判断两个标识符是否引用自同一个对象,若引用的是同一个对象则返回 True,否则返回 False |
| is not | 判断两个标识符是不是引用自不同对象,若引用的不是同一个对象则返回 True,否则返回 False |
上述身份运算符的示例如下所示:
>>> a=123
>>> b=123
>>> c=456
>>> print(a is b)
True
>>> print(a is not c)
True
运算符优先级
Python 运算符优先级
| 运算符 | 描述 |
|---|---|
| ** | 幂 |
| ~ | 按位“取反” |
| *、/、%、// | 乘、除、取模、取整除 |
| +、- | 加、减 |
| >>、<< | 右移、左移 |
| & | 按位“与” |
| ^、| | 按位“异或”、按位“或” |
| <=、<、>、>= | 比较运算符 |
| ==、!= | 等于、不等于 |
| =、%=、/=、//=、-=、+=、=、*= | 赋值运算符 |
| is、is not | 身份运算符 |
| in、not in | 成员运算符 |
| and or not | 逻辑运算符 |
流程控制
Python 提供了现代编程语言都支持的两种基本流程控制结构,分支结构和循环结构:
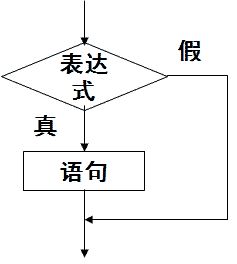
代码示例:
age = 18if age >= 18:print("可以进入网吧嗨皮了")
if else 语句
语法格式:
if 条件表达式:代码块else:代码块
执行流程:
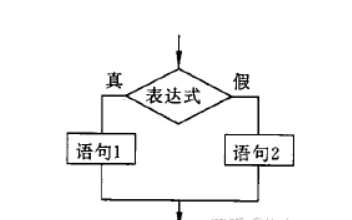
代码示例:
age = 18if age > 18:print("可以去网吧嗨皮了")else:print("未成年,请不要进入网吧")
if elif else 语句
语法格式:
if 条件表达式1:代码块1elif 条件表达式2:代码块2elif ...:.....else:代码块3
执行流程: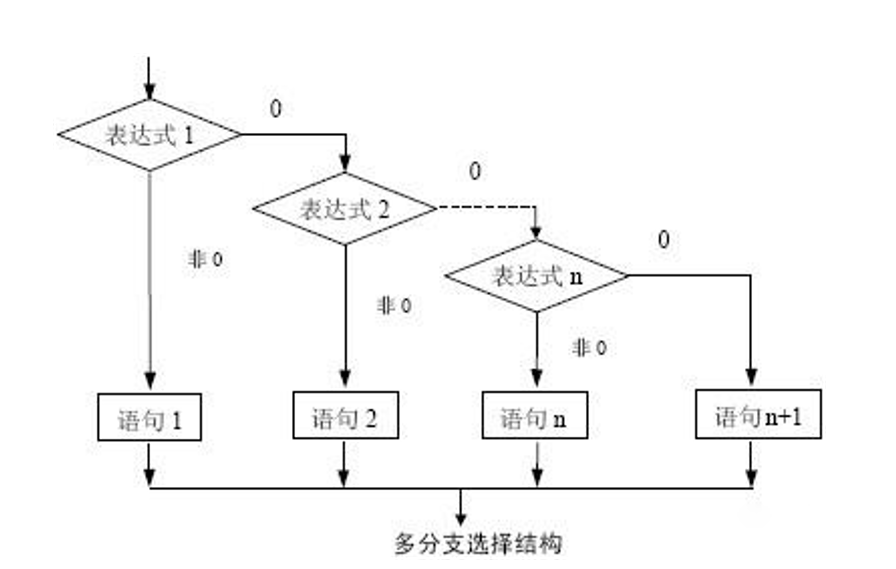
代码示例:
day_num = int(input("请输入一个整型数字:"))if num == 6:print("周六要加班")elif num == 7:print("周天可以休息了")else:print("挤公交,上班呀")
pass关键字的作用
pass 不做任何事情,一般用做占位语句。
代码示例:
age = 18if age > 18:pass
本代码中使用了pass进行占位操作,实际开发中,如果我们暂时没有想到逻辑,可以使用pass进行占位。
循环语句
while循环
语法格式:
计数器变量while 循环条件:循环体代码处理计数器
执行流程: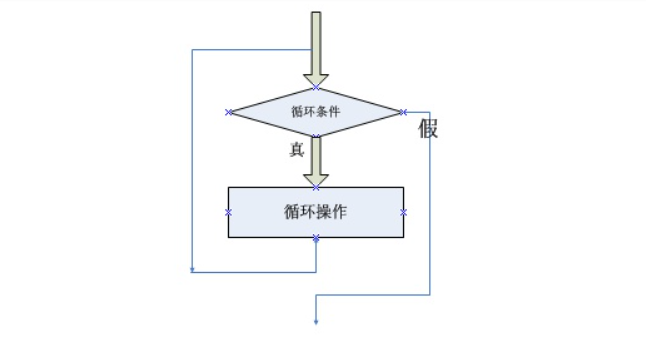
代码示例:
i = 0 # 程序中计数器从0开始while i < 10:print("我是循环体")i += 1
range函数
range() 函数可创建一个整数列表,一般用在 for 循环中。
语法格式:
range(start, stop, step)
参数说明:
- start: 计数从 start 开始。默认是从 0 开始。
- stop: 计数到 stop 结束,但不包括 stop。
- step:步长,默认为1。
- 记住一句话:顾头不顾尾。
for循环
语法格式:
流程图:for variable in sequence:语句块
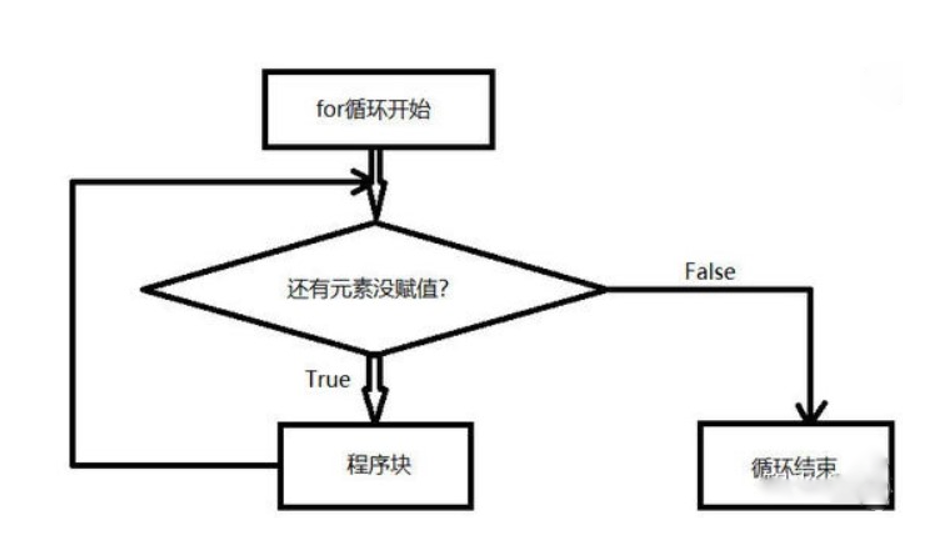
示例代码:
for i in range(10):print(i)
循环嵌套
循环嵌套是指:在一个循环体里面嵌入另一循环。
实例1:通过while循环打印99乘法表
j = 1while j <= 9:i = 1while i <= j:print('%d*%d=%d' % (i, j, i*j), end='\t')i += 1print()j += 1
实例2:通过for循环打印99乘法表
for j in range(1, 10):for i in range(1, j+1):print('%d*%d=%d' % (i, j, i*j), end='\t')i += 1print()j += 1
输出结果:
1*1=11*2=2 2*2=41*3=3 2*3=6 3*3=91*4=4 2*4=8 3*4=12 4*4=161*5=5 2*5=10 3*5=15 4*5=20 5*5=251*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=361*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=491*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=641*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
break关键字
Python中break关键字用来终止循环语句,即循环条件没有False的情况下,停止循环。
示例代码:
for i in range(10):if i == 5:breakprint("Bye")
注意:一旦使用了break,同等缩进的情况下,不能再有其他语句块。
continue关键字
Python中continue关键字跳出本次循环,进入下一次循环。
示例代码:
for i in range(10):if i == 5:continueprint(i)
运行之后我们发现,没有数字5。即循环到5之后,终止本次循环进入下一次循环。
Python在自动化中的应用
概述
Python在自动化测试中的应用是比较多的,比如用Requests&Pytest可以做一个简单的接口测试框架,用Selenium可以做WEB的UI自动化测试,用Appium可以做APP的UI自动化测试等等。
在测试部门的应用
目前Python在非功能测试中使用的并不多,因为专项测试脚本基本都是用JS写的,只有Venus项目中的SMT(冒烟测试)是用Python&RobotFramework搭建的。
当前部门Leader也十分重视自动化,有专项小组来推进自动化在整个部门的使用。
STC_AutoTesting
该项目可能是未来部门主推的一个自动化测试工具,主要由Pytest&Allure&Zal库为基础来构建。
- Pytest是一个非常成熟的全功能的Python测试框架
- Allure测试报告直观、简洁、数据清晰越好,使用装饰器与pytest搭配使用
- Zal库是与车机底层交互的工具库
目录结构
主代码
| conftest.py | pytest通用插件 | | —- | —- | | pytest.ini | pytest运行时配置文件 | | pytest_helper.py | pytest运行时主控代码 | | pytest_cloudsparrow.py | 通过云雀执行pytest测试的主代码,会调用pytest_helper.py | | pytest_cloudsparrow.xml | 通过云雀执行pytest测试时,云雀生成的配置文件
与pytest_cloudsparrow.py配合使用 | | pytest_suites_generator.py | 生成pytest测试用例集 | | results/ | 测试结果文件夹 | | pytestlib/ | 测试库 | | suites/ | 测试用例集 | | | |
测试库
| pytestlib/ | 测试库 |
|---|---|
| ├── asserts.py | |
| ├── fixtures | pytest用到的各个纹理文件,可以在测试代码中直接使用 |
| │ ├── init.py | |
| │ ├── avn.py | |
| │ ├── can.py | |
| │ ├── common.py | |
| │ └── ui.py | |
| ├── locators | 车机控件定位文件 |
| └── naming.py | 测试项目、本地文件、carsim等命名映射 |
测试集
| suites/ | 测试用例集 |
|---|---|
| ├── conftest.py | 用例集通用插件 |
| ├── suites.csv | 用例集 |
| └── AS22L | 适用于AS22L的用例集 |
| ├──系统设置 | 一级模块 |
| │ ├── 智能设置 | 二级模块 |
| │ │ └── …… | 三级模块 |
| │ │ └── test系统设置智能设置.py | 测试用例 |
| │ │ └── conftest.py |
具体使用
由于本人目前还没参与到该项目中,具体使用就附上一个框架开发同学的文档,后期应该也有详细的用例文档给大家的。
https://yuque.antfin.com/office/lark/0/2021/docx/14256366/1626420158912-b5b77f80-b535-4a37-93c8-26b9fc048285.docx?from=https://yuque.antfin.com/uwk7mr/lxax5x/hkantq
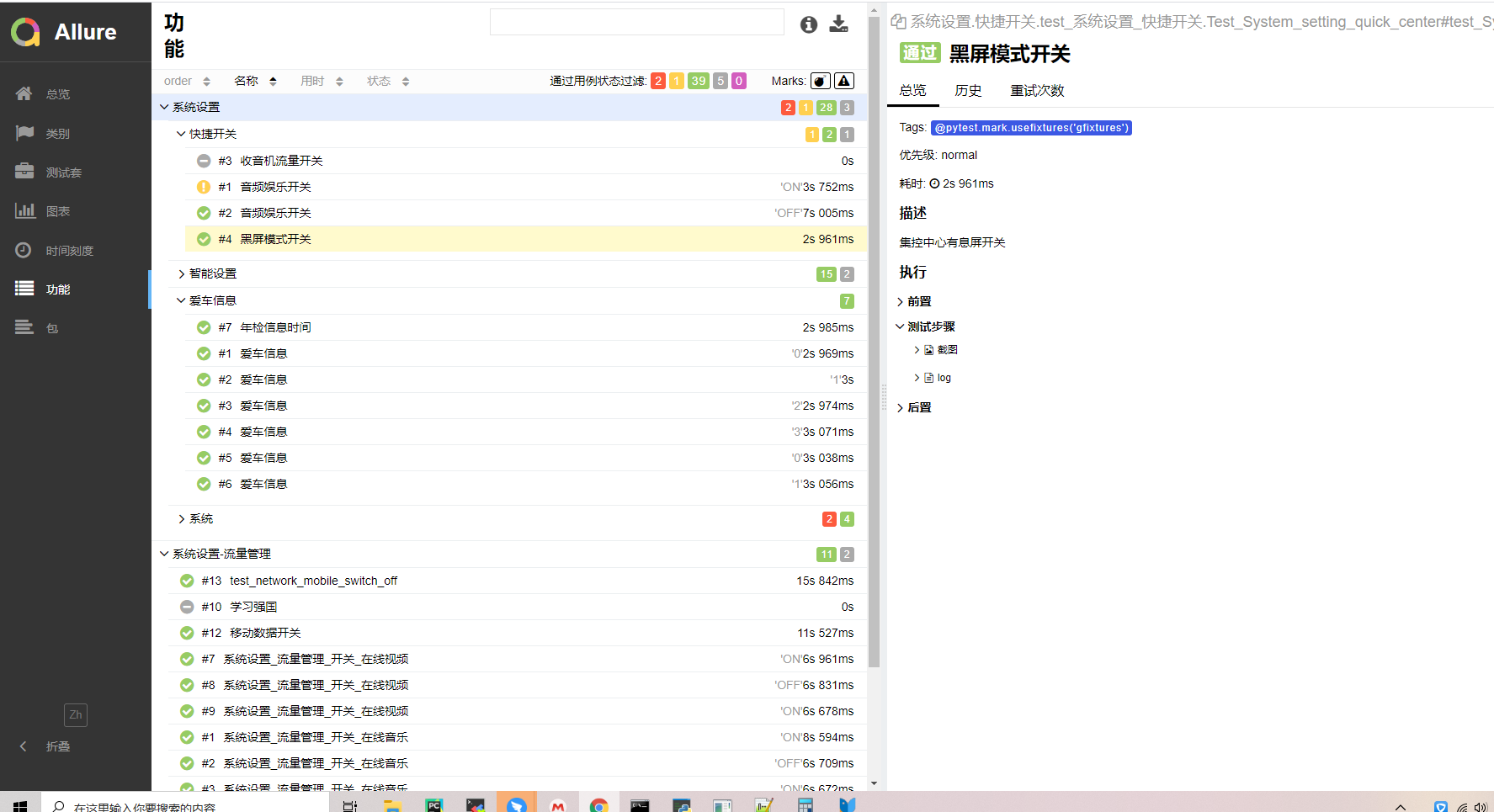
测试报告展示
云雀测试报告: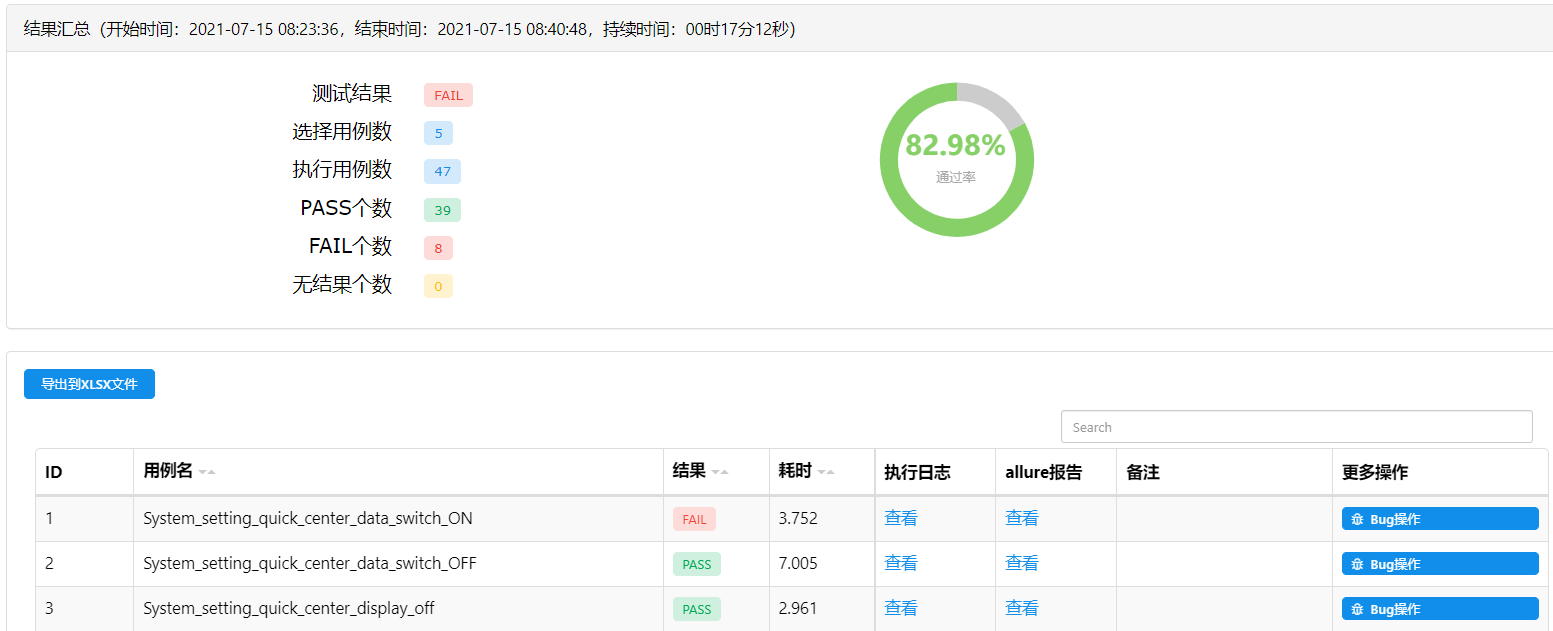
http://test.yunos-inc.com/openservice?executionId=956047&product=Car&type=pytest&tab=1&device=AS22L&hostname=guoxiangqiang.gxq&version=2.3.1-R-20210705.0122&producttag=YunOS&taskexecutionid=1876064
详细报告:http://oss-cn-hangzhou-zmf.aliyuncs.com/styunos/public/pytest/results/1876064/allure_report_dest/index.html#
Log: https://oss-cn-hangzhou-zmf.aliyuncs.com/styunos/public/pytest/results/1876381/Test_System_Settings_Data_flow.test_systemsetting_dataflow_video_ON1/pytest_logcat_20210715_155526.log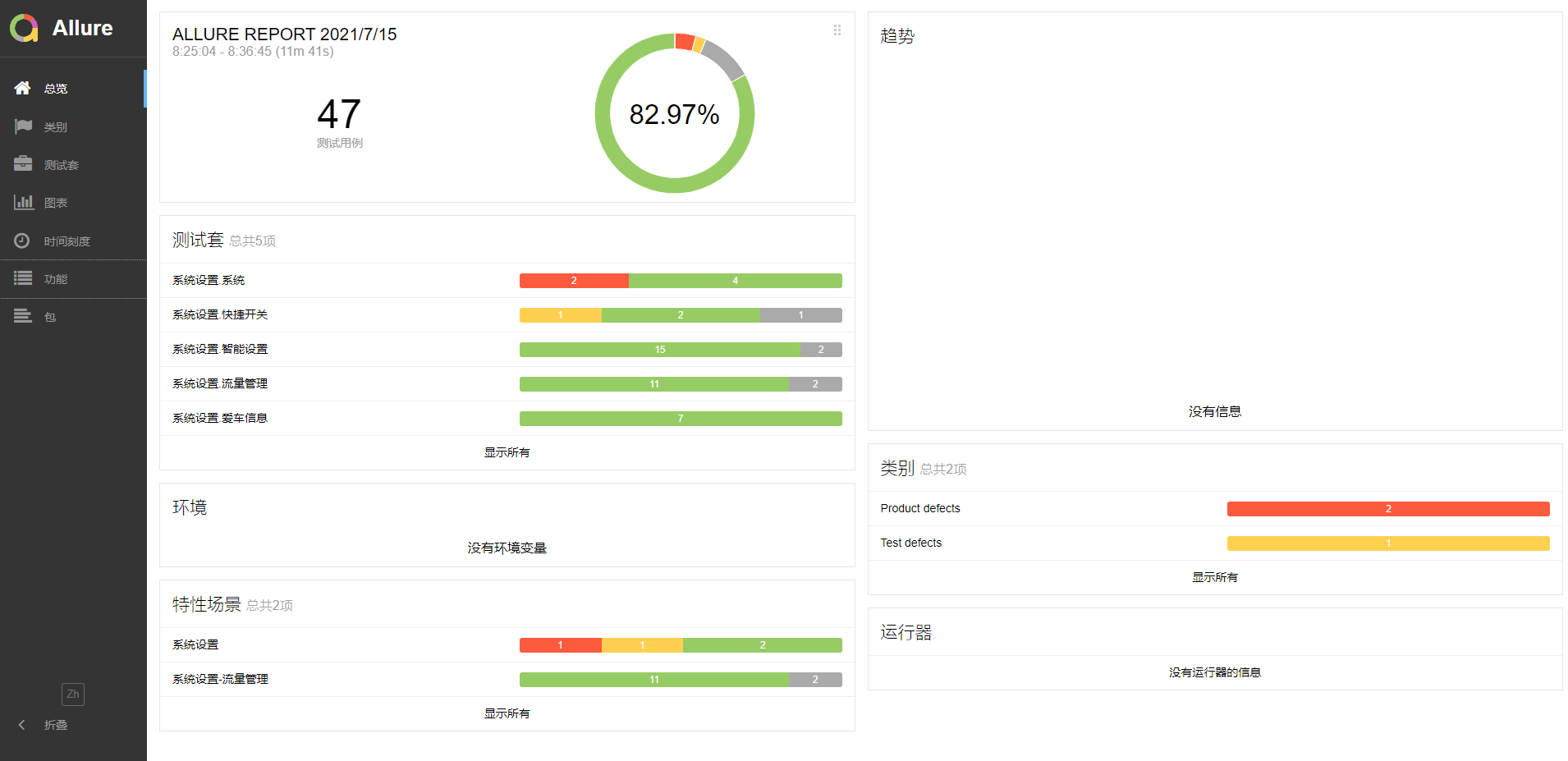

若有收获,就点个赞吧
0 人点赞
