动态连通性
这里所说的「连通」是一种等价关系,也就是说具有如下三个性质:
1、自反性:节点 p 和 p 是连通的。
2、对称性:如果节点 p 和 q 连通,那么 q 和 p 也连通。
3、传递性:如果节点 p 和 q 连通,q 和 r 连通,那么 p 和 r 也连通。
并查集的思路
用森林表示图的动态连通性,用数组来具体实现这个森林。
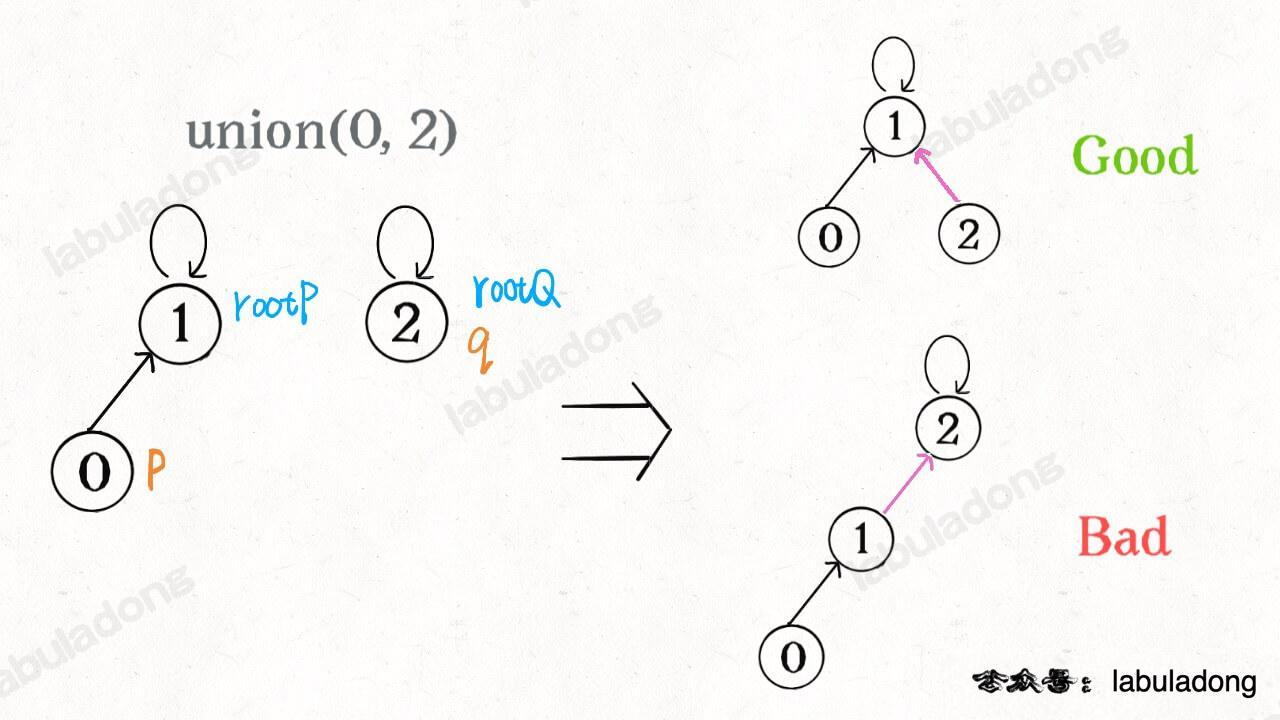
如果某两个节点被连通,则让其中的(任意)一个节点的根节点接到另一个节点的根节点上。这样,如果节点 p 和 q 连通的话,它们一定拥有相同的根节点。通过union和find,我们实现了用数组模拟一个森林。
find 主要功能就是从某个节点向上遍历到树的根节点,其时间复杂度就是树的高度。
平衡性优化
我们其实是希望,小一些的树接到大一些的树下面,这样就能避免头重脚轻,更平衡一些。解决方法是额外使用一个 size 数组,记录每棵树包含的节点数,我们不妨称为「重量」
路径压缩
其实我们并不在乎每棵树的结构长什么样,只在乎根节点。我们希望find 就能以 O(1) 的时间找到某一节点的根节点,相应的,connected 和 union 复杂度都下降为 O(1)。
有两种路径压缩方法:(在find中)
第一种:
for parent[x] != x{parent[x] = parent[parent[x]]x = parent[x]}return x
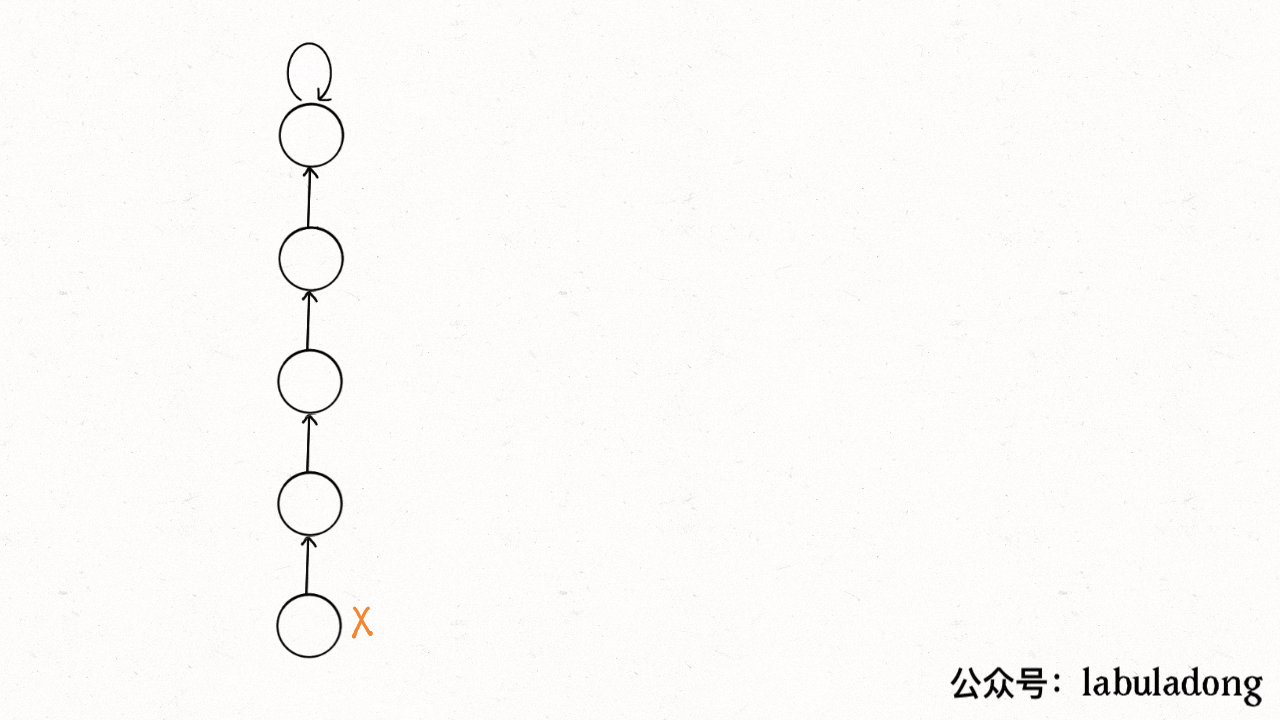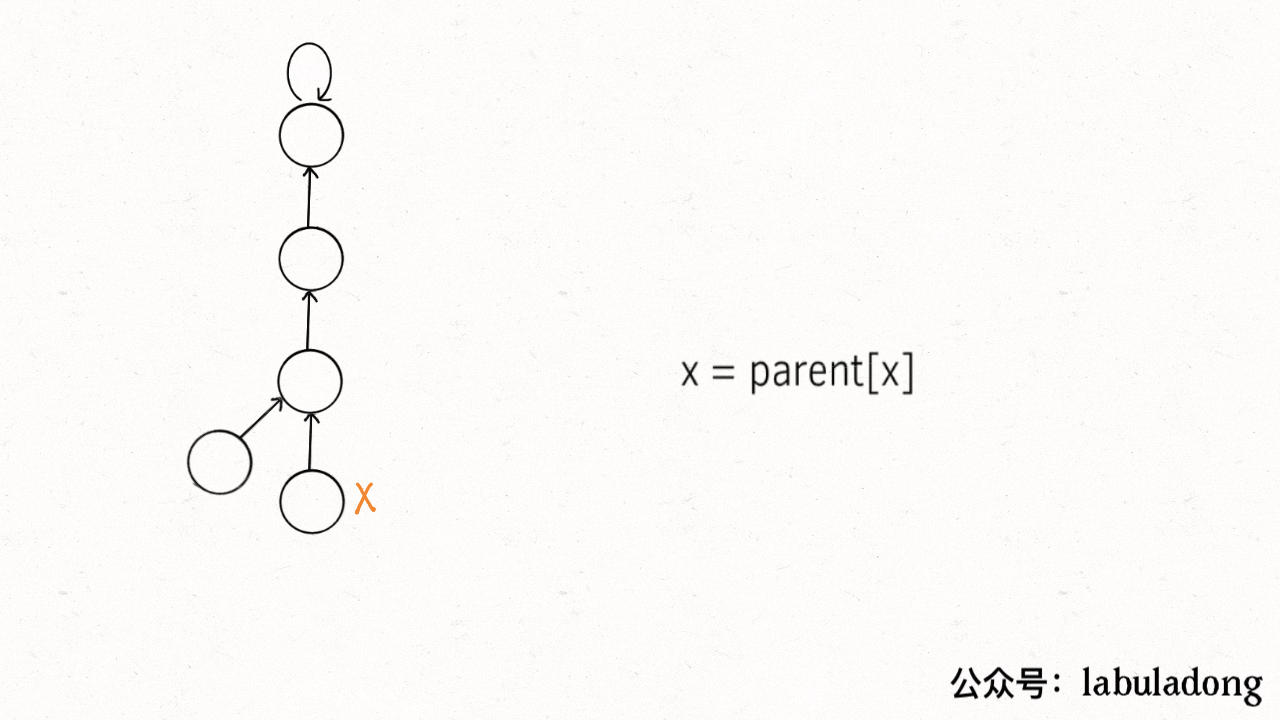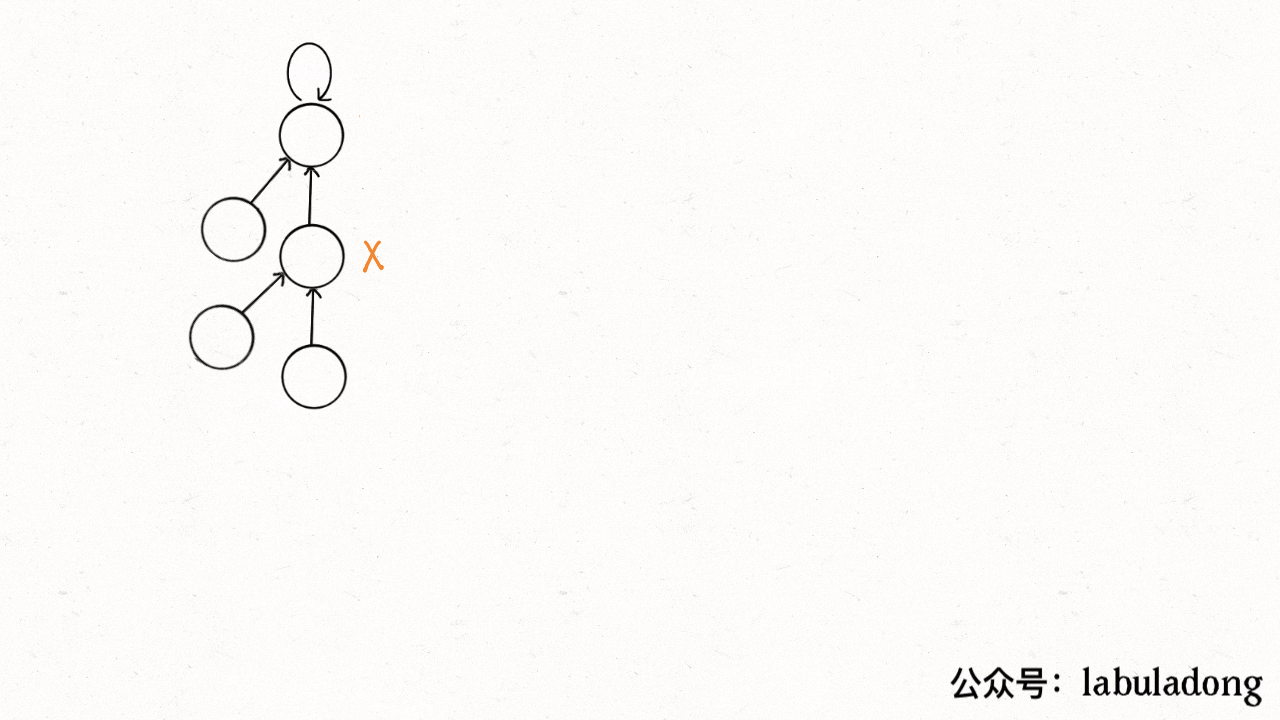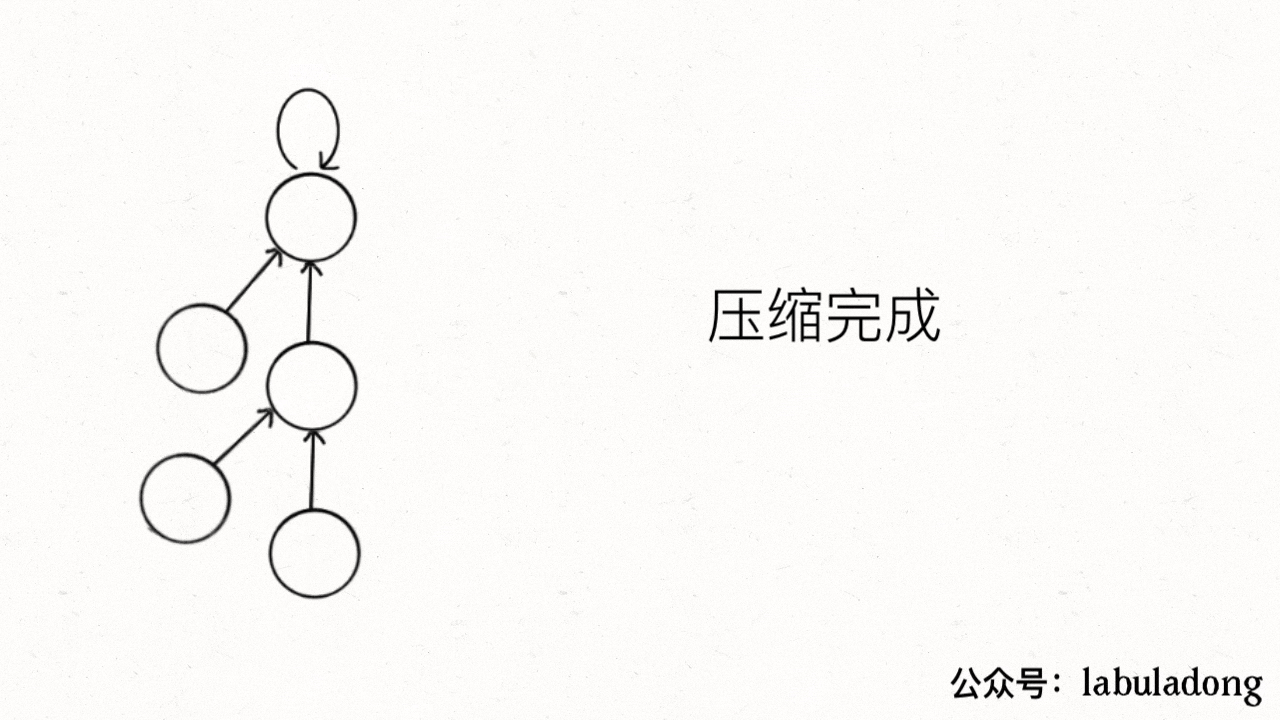
第二种:
func find(x int) {
if parent[x]!=x{
parent[x] = find(parent[x])
}
return parent[x]
}
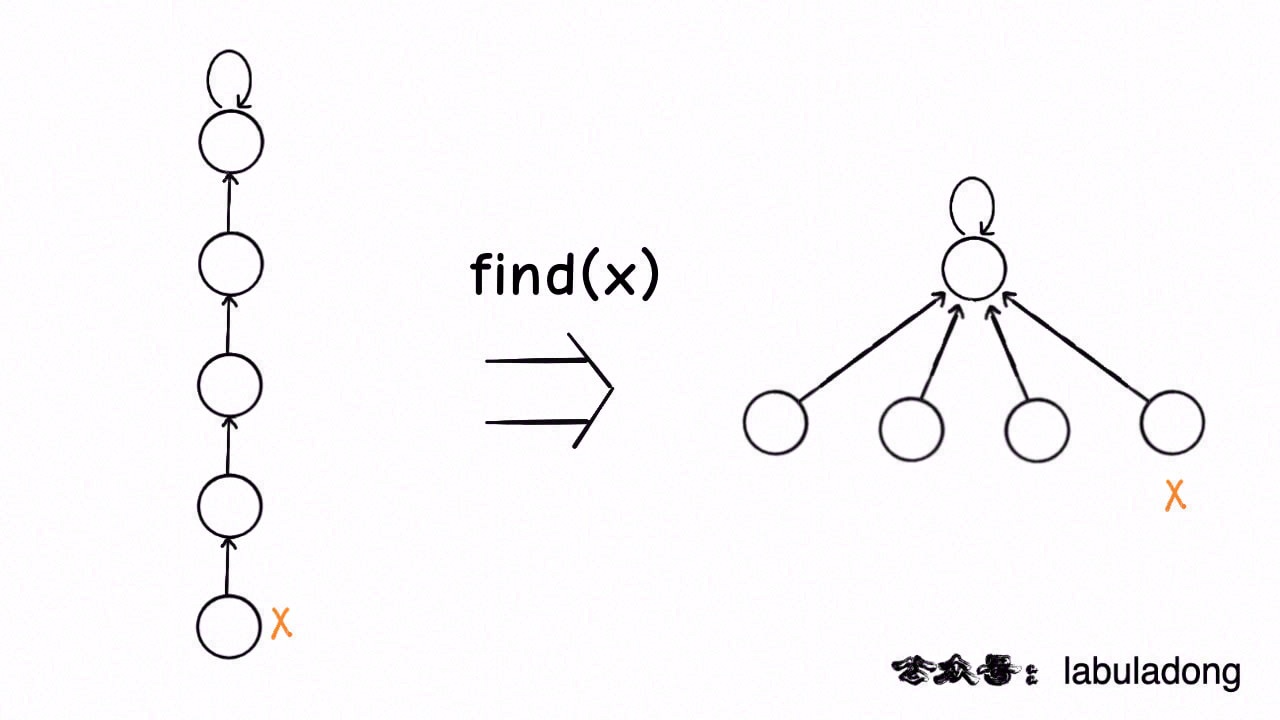
路径压缩技巧将树高保持为常数了,那么 size 数组的平衡优化就不是特别必要了。
总结
Union-Find 算法的复杂度可以这样分析:构造函数初始化数据结构需要 O(N) 的时间和空间复杂度;连通两个节点 union、判断两个节点的连通性 connected、计算连通分量 count 所需的时间复杂度均为 O(1)。
总结一下我们优化算法的过程:
1、用 parent 数组记录每个节点的父节点,相当于指向父节点的指针,所以 parent 数组内实际存储着一个森林(若干棵多叉树)。
2、用 size 数组记录着每棵树的重量,目的是让 union 后树依然拥有平衡性,保证各个 API 时间复杂度为 O(logN),而不会退化成链表影响操作效率。
3、在 find 函数中进行路径压缩,保证任意树的高度保持在常数,使得各个 API 时间复杂度为 O(1)。使用了路径压缩之后,可以不使用 size 数组的平衡优化。

若有收获,就点个赞吧
0 人点赞
