词语表达
现代机器学习中的一个普遍观点是用向量表示单词。这些向量获取有关语言的隐藏信息,如词类或语义。它也被用来提高文本分类器的性能。
在本教程中,我们将演示如何使用 fastText 来构建这些词向量。需要下载并安装 fastText,请按照文本分类教程的第一步进行操作。
获取数据
为了计算词向量,你需要一个大型的文本语料库。根据语料库,词向量将获取不同的信息。在本教程中,我们使用了维基百科的文章,但可以考虑其他来源,如新闻或网页抓取(更多示例在这里)。要下载维基百科的原始转储,请运行下面的命令:
wget https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2
下载维基百科语料库需要一些时间。有一种替代方案就是我们只研究英语维基百科的前 10 亿字节(大概 1G 不到)。可以在 Matt Mahoney 的网站上找到:
$ mkdir data$ wget -c http://mattmahoney.net/dc/enwik9.zip -P data$ unzip data/enwik9.zip -d data
原始维基百科转储包含大量的 HTML/XML 数据。我们使用与 fastText 一起打包的 wikifil.pl 脚本对其进行预处理(该脚本最初由 Matt Mahoney 开发,可以在他的网站上找到)
$ perl wikifil.pl data/enwik9 > data/fil9
我们可以通过运行下面的命令来检查文件:
$ head -c 80 data/fil9anarchism originated as a term of abuse first used against early working class
这个文本经过了很好地预处理,可以用来学习我们的词向量。
训练词向量
基于这个数据来学习词向量只需要一个命令就能实现:
$ mkdir result$ ./fasttext skipgram -input data/fil9 -output result/fil9
解释这行命令: ./fastext 用 skipgram 模型(或者是 cbow 模型)调用 fastText 二进制的可执行文件(在这里参考如何安装 fastText )。然后,’-input’ 选项要求我们指定输入数据的位置,’-output’ 指定输出要保存的位置。
当 fastText 运行时,屏幕上会显示进度和预计完成时间。一旦程序结束,result 目录中应该有两个文件:
$ ls -l result-rw-r-r-- 1 bojanowski 1876110778 978480850 Dec 20 11:01 fil9.bin-rw-r-r-- 1 bojanowski 1876110778 190004182 Dec 20 11:01 fil9.vec
fil9.bin 是一个二进制文件,用于存储整个 fastText 模型,并可以在之后重新加载。 fil9.vec 是一个包含词向量的文本文件,词汇表中的一个单词对应一行:
$ head -n 4 result/fil9.vec218316 100the -0.10363 -0.063669 0.032436 -0.040798 0.53749 0.00097867 0.10083 0.24829 ...of -0.0083724 0.0059414 -0.046618 -0.072735 0.83007 0.038895 -0.13634 0.60063 ...one 0.32731 0.044409 -0.46484 0.14716 0.7431 0.24684 -0.11301 0.51721 0.73262 ...
第一行说明了单词数量和向量维数。随后的行是词汇表中所有单词的词向量,按降序排列。
高级读者:skipgram 与 cbow 两种模型
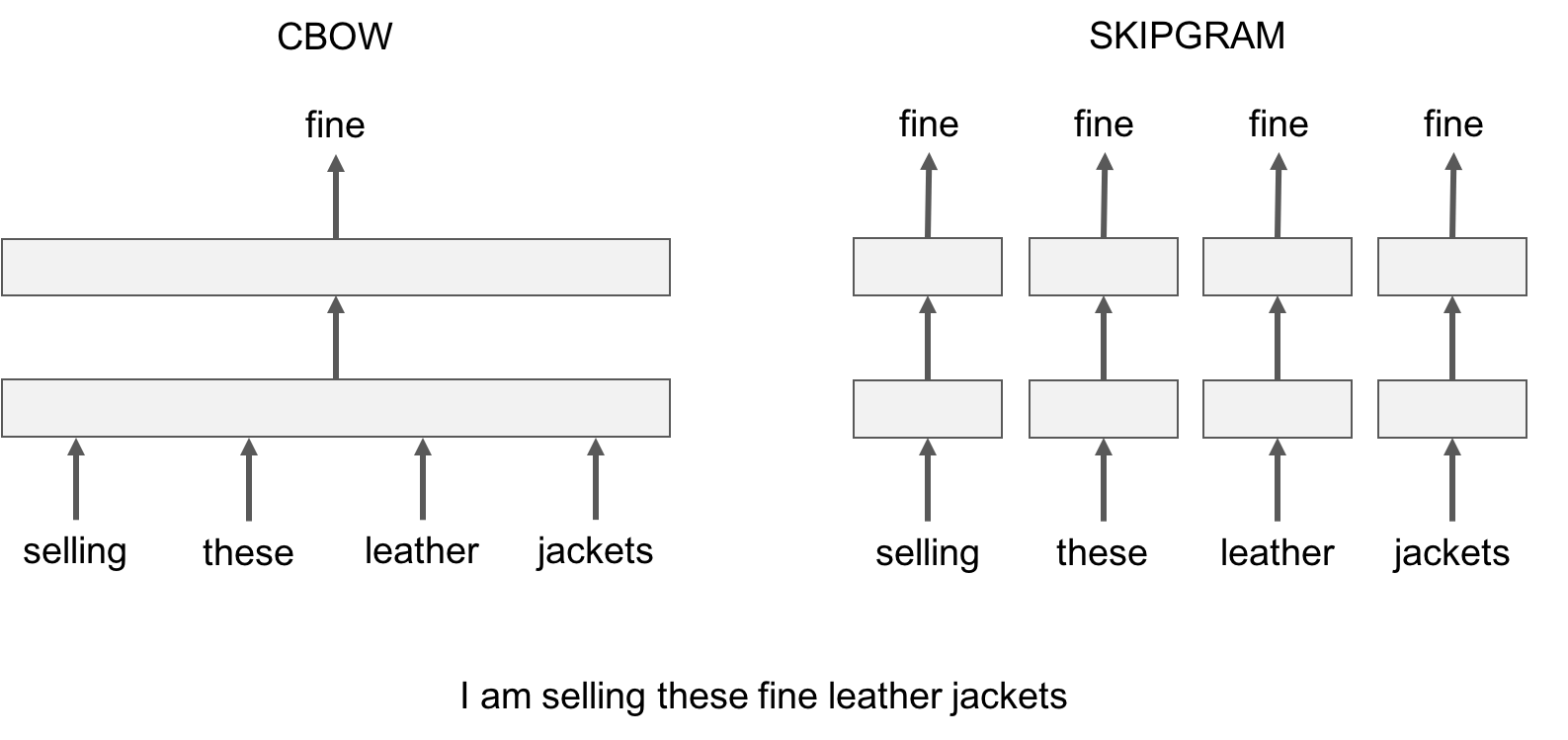
fastText 提供了两种用于计算词表示的模型:skipgram 和 cbow (‘continuous-bag-of-words’)。
skipgram 模型是学习近邻的单词来预测目标单词。 另一方面, cbow 模型是根据目标词的上下文来预测目标词。上下文是指在目标词左边和右边的固定单词数和。
让我们用一个例子来说明这种差异:给出句子 ‘Poets have been mysteriously silent on the subject of cheese’ 和目标单词 ‘silent‘,skipgram 模型随机取近邻词尝试预测目标词,如 ‘subject‘或’mysteriously‘。cbow 模型使用目标单词固定数量的左边和右边单词,,如 {been, mysteriously, on, the},并使用它们的向量和来预测目标单词。下图用另一个例子总结了这种差异。
 要使用 fastText 训练 cbow 模型,请运行下面这个命令:
要使用 fastText 训练 cbow 模型,请运行下面这个命令:
./fasttext cbow -input data/fil9 -output result/fil9
通过这个练习,我们观察到 skipgram 模型会比 cbow 模型在 subword information 上效果更好 在实践中,我们观察到 skipgram 模型比 cbow 在子词信息方面效果更好。
高级读者:调整参数
到目前为止,我们使用默认参数运行 fastText,但根据数据,这些参数可能不是最优的。 让我们介绍一下词向量的一些关键参数。
模型的最重要的参数是维度和子词的大小范围。 维度(dim)控制向量的大小,维度越多,它们就需要学习更多的数据来获取越多的信息。 但是,如果它们太大,就会越来越难以训练。 默认情况下,我们使用 100个 维度,一般情况下使用 100 到 300 范围内中的值。 子词是包含在最小尺寸(minn)和最大尺寸(maxn)之间的字中的所有子字符串。 默认情况下,我们取 3 到 6 个字符的所有子词,但不同语言的适用范围可能不同:
$ ./fasttext skipgram -input data/fil9 -output result/fil9 -minn 2 -maxn 5 -dim 300
根据您已有的数据量,您可能需要更改训练参数。 epoch 参数控制将循环多少次的数据。 默认情况下,我们遍历数据集 5 次。 如果你的数据集非常庞大,你可能希望更少地循环它。另一个重要参数是学习率 -lr)。 学习率越高,模型收敛到最优解的速度越快,但过拟合数据集的风险也越高。 默认值是 0.05,这是一个很好的折中值。 如果你想调整它,我们建议留在 [0.01,1] 的范围内:
$ ./fasttext skipgram -input data/fil9 -output result/fil9 -epoch 1 -lr 0.5
最后,fastText 是多线程的,默认使用 12 个线程。 如果 CPU 核心数较少(只有 4 个),则可以使用 thread 参数轻松设置线程数:
$ ./fasttext skipgram -input data/fil9 -output result/fil9 -thread 4
打印词向量
直接从 fil9.vec 文件中搜索和打印词向量非常麻烦。 幸运的是,fastText 中有一个 print-word-vectors 功能。
例如,我们可以使用以下命令打印词 asparagus,pidgey 和 yellow 的词向量:
$ echo "asparagus pidgey yellow" | ./fasttext print-word-vectors result/fil9.binasparagus 0.46826 -0.20187 -0.29122 -0.17918 0.31289 -0.31679 0.17828 -0.04418 ...pidgey -0.16065 -0.45867 0.10565 0.036952 -0.11482 0.030053 0.12115 0.39725 ...yellow -0.39965 -0.41068 0.067086 -0.034611 0.15246 -0.12208 -0.040719 -0.30155 ...
一个很好的功能是,您还可以查询没有出现在数据中的单词! 实际上,单词由其子串的总和来表示。 只要未知单词是由已知的子串组成的,就有它的表示形式!
这里有一个例子,让我们尝试拼写错误的单词:
$ echo "enviroment" | ./fasttext print-word-vectors result/fil9.bin
你仍然得到一个单词向量! 但它有多棒? 让我们在下一节中揭晓!
最近邻查询
查看最近邻是检查词向量效果的一种简单方法。 这给出了向量能够获取的语义信息类型的直觉。
这可以通过 nn 功能来实现。 例如,我们可以通过运行以下命令来查询单词的最近邻:
$ ./fasttext nn result/fil9.binPre-computing word vectors... done.
然后我们会提示输入我们的查询词,让我们试试 asparagus:
Query word? asparagusbeetroot 0.812384tomato 0.806688horseradish 0.805928spinach 0.801483licorice 0.791697lingonberries 0.781507asparagales 0.780756lingonberry 0.778534celery 0.774529beets 0.773984
太好了! 看来 vegetable 的向量是相似的。 请注意,最近邻是 asparagus 本身,这意味着这个词出现在数据集中。 那么 pokemons?
Query word? pidgeypidgeot 0.891801pidgeotto 0.885109pidge 0.884739pidgeon 0.787351pok 0.781068pikachu 0.758688charizard 0.749403squirtle 0.742582beedrill 0.741579charmeleon 0.733625
相同 pokemons 的不同进化有紧邻的向量! 但是我们拼错的单词呢,它的向量接近于任何合理的东西吗? 让我们看看:
Query word? enviromentenviromental 0.907951environ 0.87146enviro 0.855381environs 0.803349environnement 0.772682enviromission 0.761168realclimate 0.716746environment 0.702706acclimatation 0.697196ecotourism 0.697081
由于这个词中包含的信息,我们拼写错误的单词的向量搭配到了匹配合理的单词! 虽然这并不完美,但主要信息已经获取到了。
高级读者:计算相似度
为了找到最近邻,我们需要计算单词之间的相似度分数。 我们的单词用连续的词向量来表示,因此我们可以对它们应用简单的相似性。 尤其我们使用两个向量之间角度的余弦。 计算词汇表中所有单词的相似度,并显示 10 个最相似的单词。 当然,如果单词出现在词汇表中,它将出现在顶部,其相似度为 1。
字的类比
用类比的思想,我们可以进行词的类比。 例如,我们可以看到我们的模型是否可以根据柏林是德国的首都来猜测法国的首都是什么,
这可以通过 analogies 功能来完成。 它需要三个词(如德国柏林法国)来输出类别结果:
$ ./fasttext analogies result/fil9.binPre-computing word vectors... done.Query triplet (A - B + C)? berlin germany franceparis 0.896462bourges 0.768954louveciennes 0.765569toulouse 0.761916valenciennes 0.760251montpellier 0.752747strasbourg 0.744487meudon 0.74143bordeaux 0.740635pigneaux 0.736122
我们的模型提供了正确的答案 Paris。 让我们来看一个不太明显的例子:
Query triplet (A - B + C)? psx sony nintendogamecube 0.803352nintendogs 0.792646playstation 0.77344sega 0.772165gameboy 0.767959arcade 0.754774playstationjapan 0.753473gba 0.752909dreamcast 0.74907famicom 0.745298
我们的模型认为 psx 的 nintendo 类比是 gamecube,这似乎是合理的。 当然,类比的质量取决于用于训练模型的数据集,并且只能出现存在数据集中的单词。
字符 n-gram 的重要性
使用子字级信息对于为未知单词构建向量特别有趣。 例如,维基百科上不存在 gearshift 这个词,但我们仍然可以查询其最接近的现有词语:
Query word? gearshiftgearing 0.790762flywheels 0.779804flywheel 0.777859gears 0.776133driveshafts 0.756345driveshaft 0.755679daisywheel 0.749998wheelsets 0.748578epicycles 0.744268gearboxes 0.73986
大多数检索的单词共享大量的子字符串,但少数实际上完全不同,如 cogwheel。 你可以尝试其他单词,如 sunbathe 或 grandnieces。
现在我们已经看到了未知词的子词信息的兴趣,我们来检查它与不使用子词信息的模型的比较。 要训练没有子词的模型,只需运行以下命令:
$ ./fasttext skipgram -input data/fil9 -output result/fil9-none -maxn 0
结果保存在result/fil9-non.vec和result/fil9-non.bin中。
为了说明这种差异,让我们在维基百科中使用一个不常见的单词,例如 accomodation,它是拼写错误的 accommodation。这里是没有子词的最近邻:
$ ./fasttext nn result/fil9-none.binQuery word? accomodationsunnhordland 0.775057accomodations 0.769206administrational 0.753011laponian 0.752274ammenities 0.750805dachas 0.75026vuosaari 0.74172hostelling 0.739995greenbelts 0.733975asserbo 0.732465
结果没有多大意义,大部分这些词都是无关的。 另一方面,使用子字信息给出以下最近邻列表:
Query word? accomodationaccomodations 0.96342accommodation 0.942124accommodations 0.915427accommodative 0.847751accommodating 0.794353accomodated 0.740381amenities 0.729746catering 0.725975accomodate 0.703177hospitality 0.701426
最近邻在词 accommodation 附近获取到了不同的变化。 我们还可以获得语义相关的词语,例如 amenities 或 lodging。
结论
在本教程中,我们展示了如何从维基百科获取词向量。 这可以通过任何语言完成,我们提供预训练模型,默认设置为 294。

若有收获,就点个赞吧
0 人点赞
