相关资源
在教材的导航栏点击【MXNet】或【PyTorch】下载对应离线版本,点击【Jupter记事本】下载源码

深度学习基础
第一节:数据操作
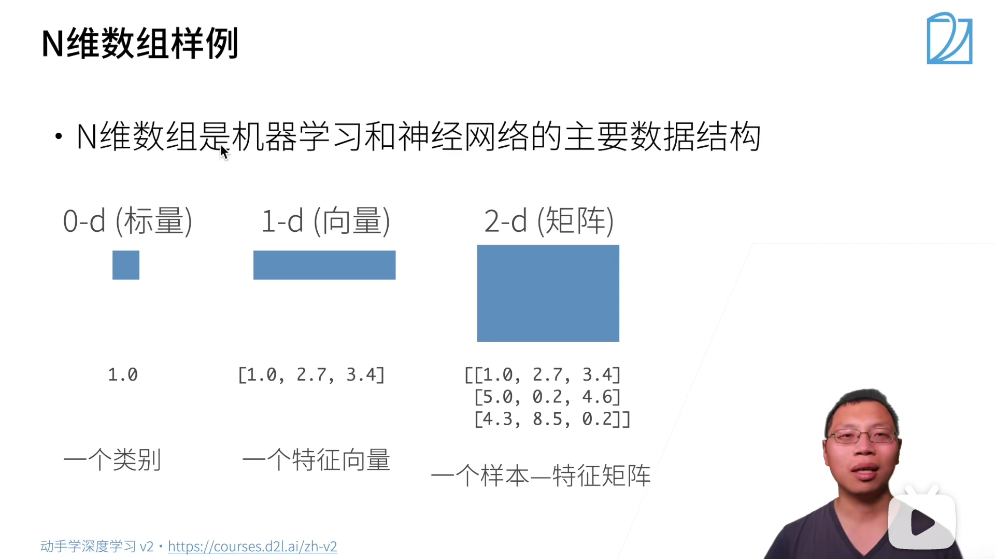
三维数组解释:把RGB通道的三层分别视为3列,叠加起来
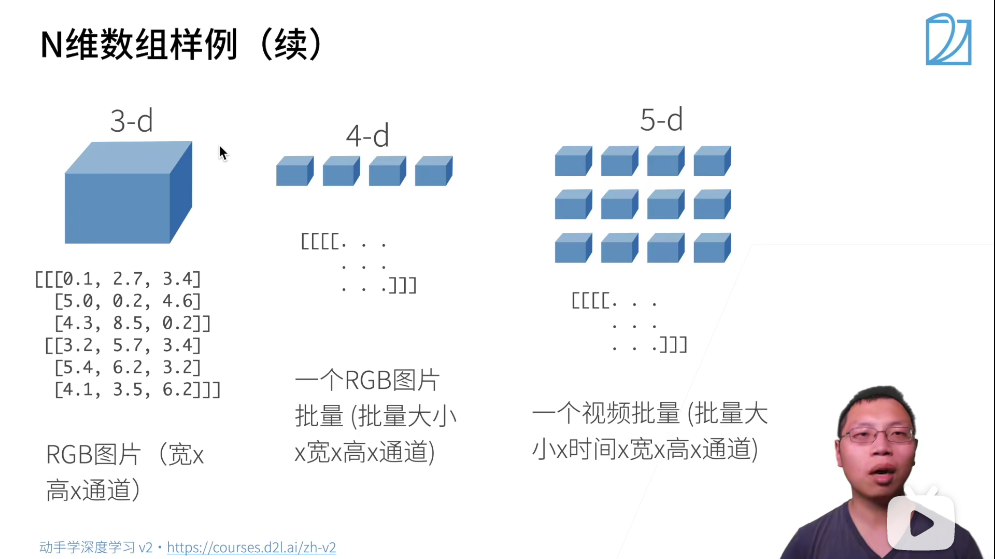
四维数组解释:读入图片不是一张一张读,而是一批一批读,叫一个批量
子区域[1:3,1:]解释:前面1:3表示从第一行到第三行,左闭右开,所以就是取了第1行和第2行,后面1:表示从第一列拿到最后一列,在本例中就是第1列,第2列和第3列。
子区域[::3,::2]解释:跳着访问,::3表示每3行一跳,在本例中就是取了第0行和第3行,::2表示每2列一跳,在本例中就是取了第0列和第2列。
张量表示由一个数值组成的数组,这个数组可能有多个维度。
创建数组需要:
- 形状:例如
矩阵
- 每个元素的数据类型,例如32位浮点数
- 每个元素的值,例如全是0,或者随机数
导入torch
import torch
torch.arange()函数
torch.arange(start, end, step=1, out=None)
返回一个1维张量,长度为%2Fstep)#card=math&code=floor%28%28end-start%29%2Fstep%29&id=dKC4X)包含从到,以为步长的一组序列值(默认start为0,步长为1)
参数:
- start (float) – 序列的起始点
- end (float) – 序列的终止点
- step (float) – 相邻点的间隔大小
- out (Tensor, optional) – 结果张量
指定:
x = torch.arange(12)print(x)print(x.dtype)
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])torch.int64
指定:和:
x = torch.arange(1, 12)
print(x)
tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
指定、和:
x = torch.arange(1, 12, 3)
print(x)
tensor([ 1, 4, 7, 10])
指定和:
x = torch.arange(12, dtype=torch.float32)
print(x)
tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11.])
torch.float32
pytorch里一般使用torch.arange(),而不使用torch.range(),关于两者的区别:【pytorch.range() 和 pytorch.arange() 的区别】
访问张量的形状和元素总数
x = torch.arange(12)
print(x)
# 访问张量形状
print(x.shape)
print(x.size())
# 访问张量长度
print(len(x))
# 访问张量中元素总数
print(x.numel())
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
torch.Size([12])
torch.Size([12])
12
12
torch.reshape()函数
torch.reshape()接受的参数依次为最高维,次高维,…,第三维(通道),第二维(行),第一维(列)
x = torch.arange(12).reshape(3, 4)
print(x)
# 访问张量形状
print(x.shape)
print(x.size())
# 访问张量长度
print(len(x))
# 访问张量中元素总数
print(x.numel())
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
torch.Size([3, 4])
torch.Size([3, 4])
3
12
tensor([[[ 0, 1],
[ 2, 3]],
[[ 4, 5],
[ 6, 7]],
[[ 8, 9],
[10, 11]]])
使用全0,全1,其他常量或从特定分布中随机采样的数字
x = torch.zeros(2, 3, 4)
print(x)
tensor([[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]])
x = torch.ones(2, 3, 4)
print(x)
tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
通过提供包含数值的列表(或嵌套列表)来为所需张量中的每个元素赋予确定值。在这⾥,最外层的列表对应于轴0,内层的列表对应于轴1:
x = torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
print(x)
print(x.sum())
tensor([[2, 1, 4, 3],
[1, 2, 3, 4],
[4, 3, 2, 1]])
tensor(30)
torch.randn()方法从均值为0、标准差为1的标准⾼斯(正态)分布中随机采样得到元素:
x = torch.randn(3, 4)
print(x)
tensor([[-1.0596, -1.1175, -0.0242, 1.0464],
[-1.3995, -1.0616, -0.7274, -0.4666],
[-0.5376, 1.4548, -0.3597, 0.0560]])
运算
按元素运算:标准算术运算符(+、-、、/和*)已被重载过,被升级为按(对应)元素运算
⼴播机制:对不同形状的张量,将其复制元素形成形状相同的张量,再按元素运算
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
print(a, '\n', b)
tensor([[0],
[1],
[2]])
tensor([[0, 1]])
执行a+b运算时
print(a+b)
把a从的列向量向右复制一列,变成成
的矩阵
tensor([[0, 0],
[1, 1],
[2, 2]])
把b从的行向量复制向下两行,变成成
的矩阵
tensor([[0, 1],
[0, 1],
[0, 1]])
再按元素相加:
tensor([[0, 1],
[1, 2],
[2, 3]])
torch.cat()函数把两个张量连接起来:
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
print(X, '\n\n', Y)
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
tensor([[2., 1., 4., 3.],
[1., 2., 3., 4.],
[4., 3., 2., 1.]])
指定dim = 0是在轴0(按列)方向拼接两个张量(竖着拼接到一起),指定dim = 1是在轴1(按行)方向拼接两个张量(横着拼接到一起):
print(torch.cat((X, Y), dim=0))
print()
print(torch.cat((X, Y), dim=1))
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[ 2., 1., 4., 3.],
[ 1., 2., 3., 4.],
[ 4., 3., 2., 1.]])
tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],
[ 4., 5., 6., 7., 1., 2., 3., 4.],
[ 8., 9., 10., 11., 4., 3., 2., 1.]])
索引和切片
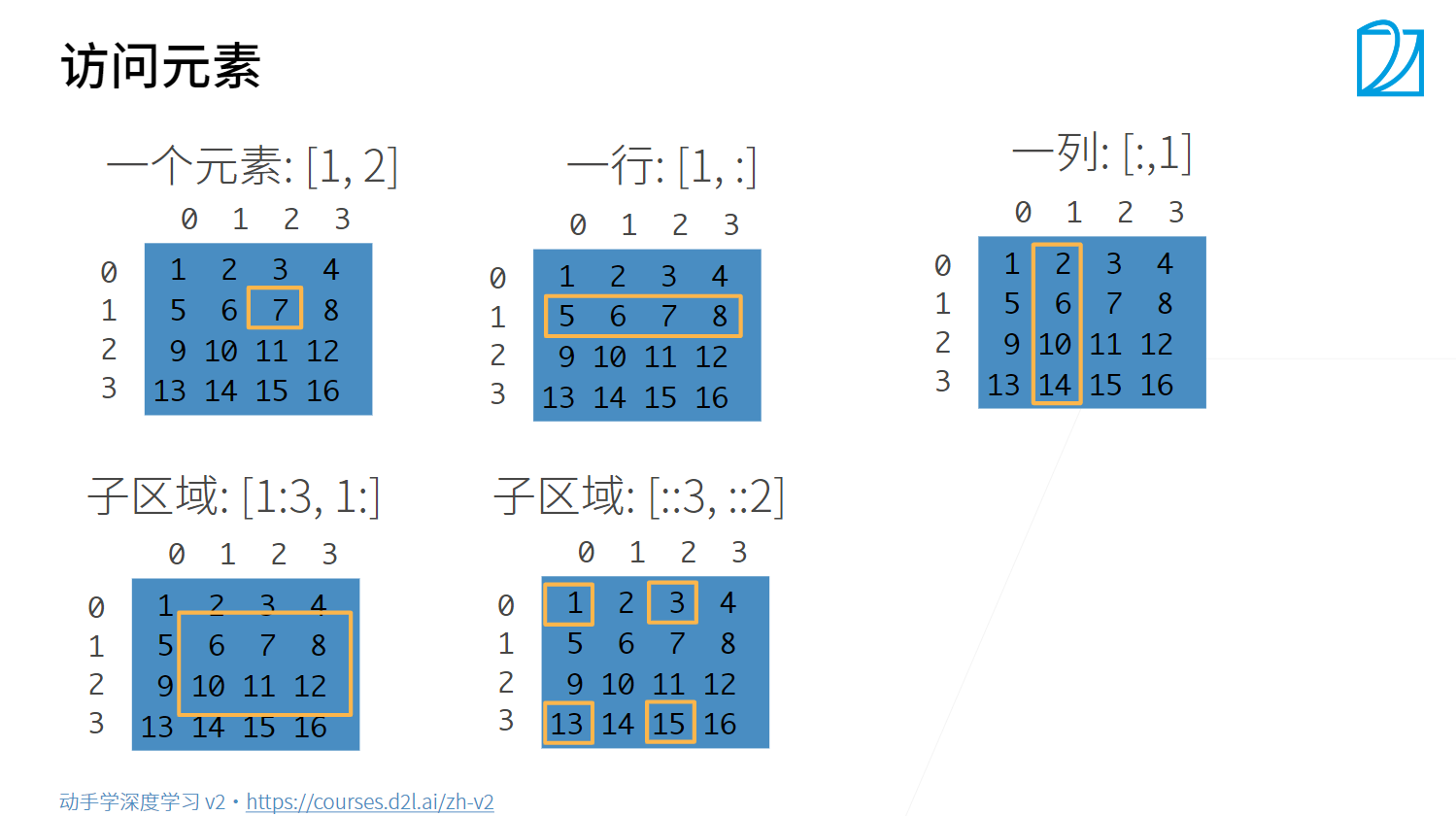
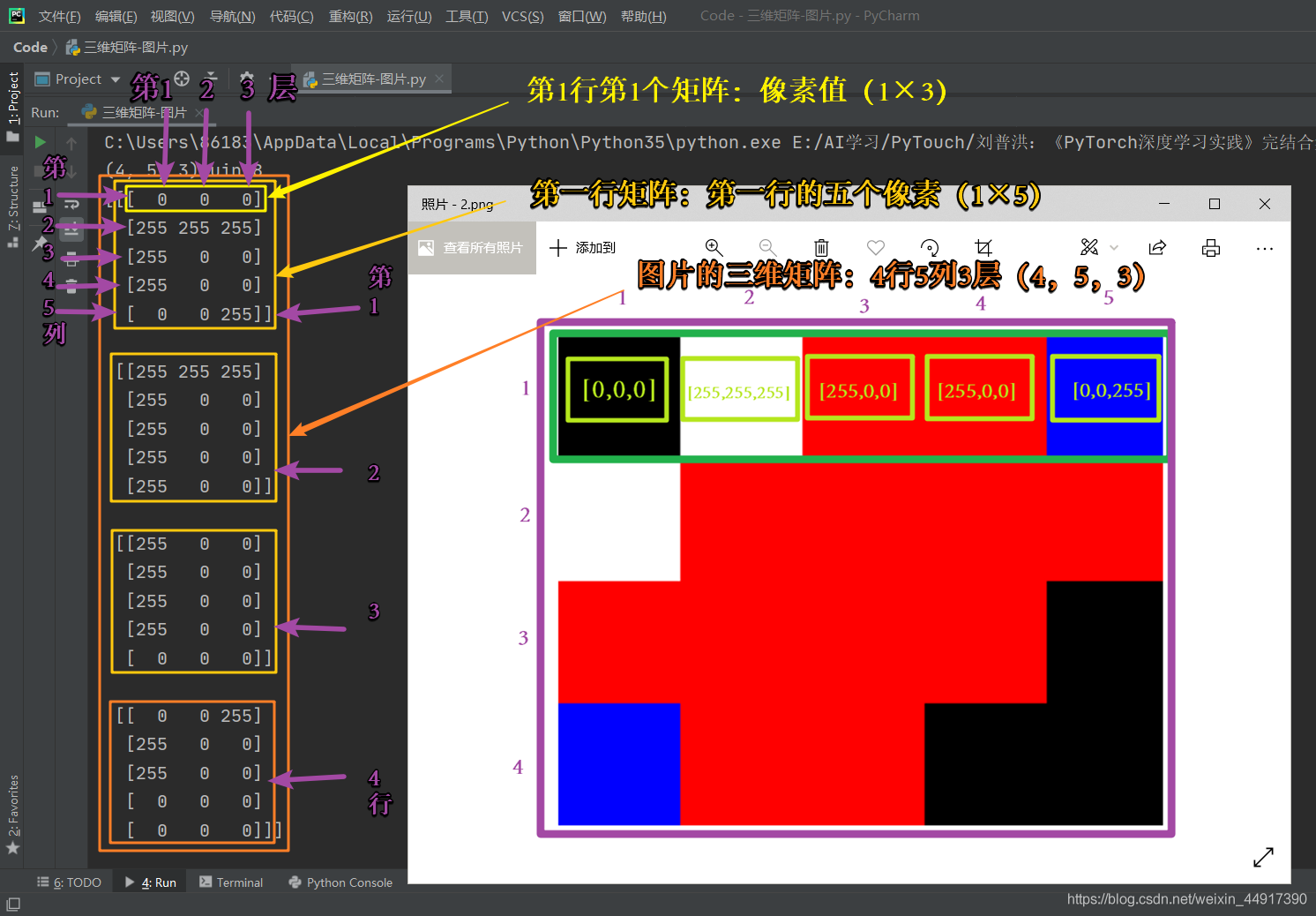
如图,创建对应的矩阵:
x = torch.arange(1, 17).reshape(4, 4)
print(x)
tensor([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12],
[13, 14, 15, 16]])
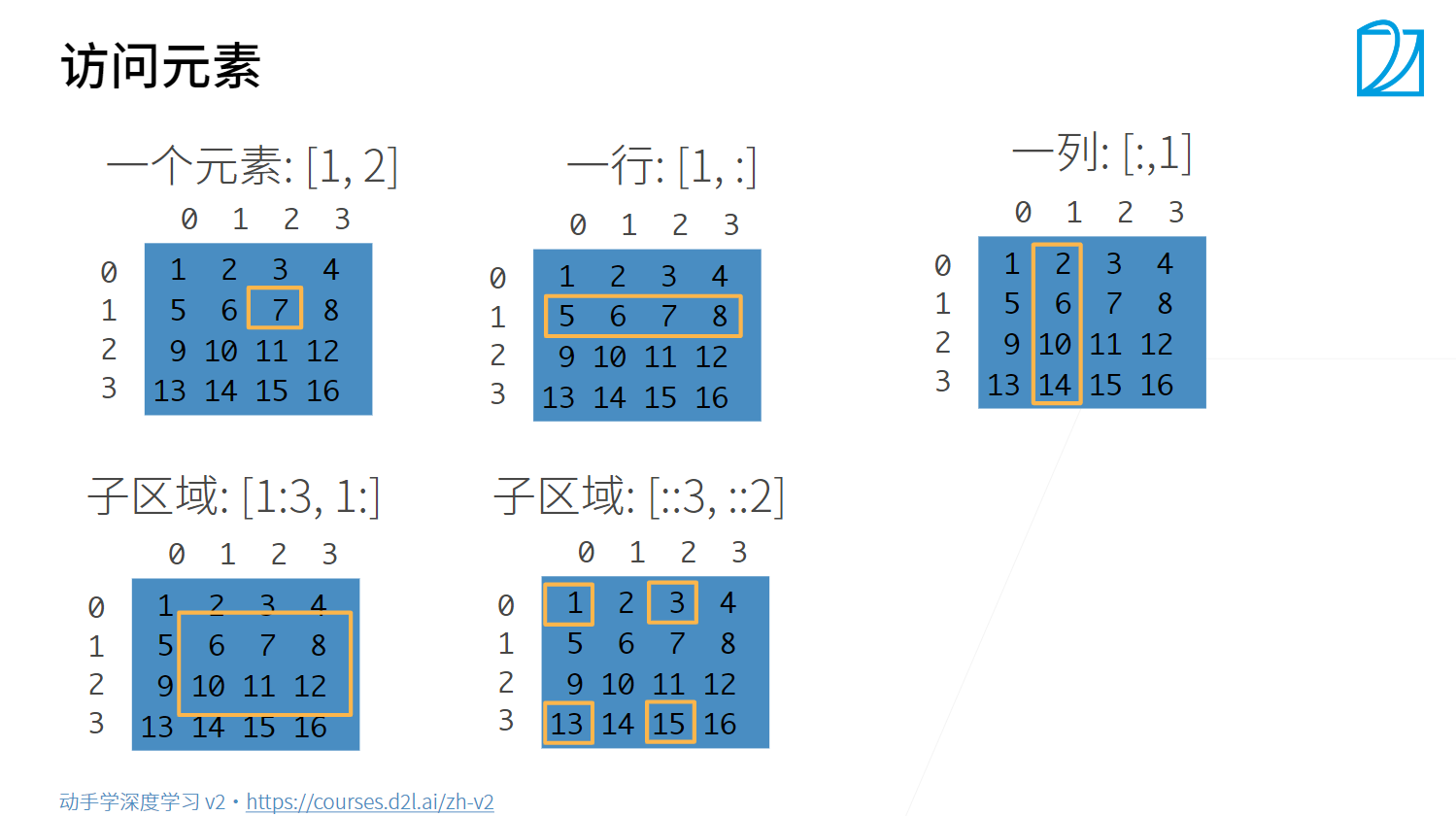
一个元素:[1, 2]
print(x[1, 2])
tensor(7)
一行:[1, :] [-1]
print(x[1, :])
# 和print(x[1])一样,无逗号默认为行操作
print(x[-1])
tensor([5, 6, 7, 8])
tensor([13, 14, 15, 16])
一列:[:, 1]
print(x[:, 1])
tensor([ 2, 6, 10, 14])
子区域:[1:3, 1:]
print(x[1:3, 1:])
tensor([[ 6, 7, 8],
[10, 11, 12]])
子区域:[::3, ::2]
print(x[::3, ::2])
tensor([[ 1, 3],
[13, 15]])
节省内存和原地操作
在Python里,变量名的本质是指针(或可看作Java、C#的引用数据类型),当执行右边是常量的赋值表达式时,实际上是先开辟一块内存空间存储式右侧的值,再令式左侧的变量名指向存储值的这块内存空间。
a = 5
print("id(a)_first:", id(a))
before = id(a)
a = 6
print("id(a)_second:", id(a))
print("是否相等:", id(a) == before)
id(a)_first: 140710131607456
id(a)_second: 140710131607488
是否相等: False
解释:id() 函数返回对象的唯一标识符(对象的内存地址),标识符是一个整数。
令a = 5后,id(a)的地址是140710131607456,令a = 6,此时先分配一块地址是140710131607488的内存空间来存储6这个值,然后再令a指向新内存空间,故赋值操作前后a的地址不再相等。
我们再看另一个操作:
a = 5
print("id(a):", id(a))
b = a
print("id(b):", id(b))
print("是否相等:", id(b) == id(a))
id(a): 140708293781408
id(b): 140708293781408
是否相等: True
解释:b = a是把b作为指针指向了a所指向的那块内存空间,所以b和a(所指向)的地址完全相同。
另一个例子:
a = [1, 0.4, 'string']
print("id(a):", id(a))
b = a
print("id(b):", id(b))
print("是否相等:", id(b) == id(a))
b[2] = "char[]"
print(a)
id(a): 2687673048192
id(b): 2687673048192
是否相等: True
[1, 0.4, 'char[]']
对列表执行原地操作的办法:b[:] =
对b原地操作之后输出a,a就是改变后的列表,说明对b的操作即是对a的操作。
张量亦是如此:
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
before = id(Y)
Y = Y + X
print(id(Y) == before)
False
对张量执行原地操作的办法:Z[:] =
# 创建⼀个新的矩阵Z,其形状与Y相同
# 使⽤zeros_like来分配⼀个全0的块
Z = torch.zeros_like(Y)
print(Z, '\n')
print('id(Z):', id(Z))
Z[:] = X + Y
print('id(Z):', id(Z))
tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
id(Z): 1977010202240
id(Z): 1977010202240
特别的,+= 重载后执行原地操作,即X[:] = X + Y和X += Y等价:
label1 = id(X)
X[:] = X + Y
label2 = id(X)
X += Y
label3 = id(X)
print("label1:", label1)
print("label2:", label2)
print("label2:", label2)
label1: 1405191724288
label2: 1405191724288
label2: 1405191724288
转换为其他Python对象
对tensor调用numpy()方法将其转变成numpy张量,对numpy张量调用torch.tensor转变成torch张量
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
A = X.numpy() # A被转换为numpy张量
print('\n')
print(A)
print('\n')
B = torch.tensor(A) # B被转换为torch张量
print(B)
print('\nA:', type(A), '\nB:', type(B))
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]]
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
A: <class 'numpy.ndarray'>
B: <class 'torch.Tensor'>
转换成标量:调⽤item函数或Python的内置函数
a = torch.tensor([3.5])
print(a, a.item(), float(a), int(a))
print('\n', type(a), type(a.item()), type(float(a)), type(int(a)))
tensor([3.5000]) 3.5 3.5 3
<class 'torch.Tensor'> <class 'float'> <class 'float'> <class 'int'>
第二节:数据预处理
创建人工数据集
首先导入os包
import os
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
这里os.path.join()函数的作用是把多个字符串连接成一个路径,.是当前路径,..是上一级路径,os.path.join('..', 'data')把..和data连接成路径'..\data',os.makedirs('..\data', exist_ok=True)中exist_ok=True的意思是如果不存在此路径则创建之,如果存在则不变,也不抛出异常(如果为False就会抛出异常)
然后再通过os.path.join()方法创建保存文件路径的变量data_file = ..\data\house_tiny.csv
写入文件内容
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n')
f.write('NA,Pave,127500\n')
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
'r'是只读模式,'w'是写入模式,with open(data_file, 'w') as f:意为以写入模式打开文件(如果文件不存在就创建它)并绑定到f对象上,然后执行对f对象的操作.
打开创建的csv文件,里面已经被写入内容了: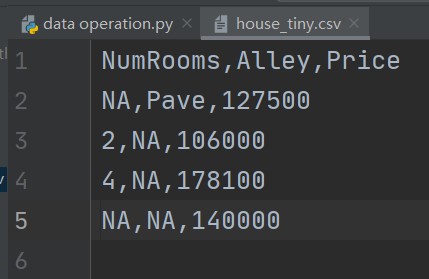
处理csv文件
一般使用pandas库处理csv文件.
导入pandas包:
import pandas as pd
调用read_csv()函数
data = pd.read_csv(data_file)
print(data)
print('\n')
print(type(data))
NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000
<class 'pandas.core.frame.DataFrame'>
该数据集有四⾏三列,其中每⾏描述了房间数量(“NumRooms”)、巷⼦类型(“Alley”)和房屋价格(“Price”),“NaN”项代表缺失值。
处理缺失值有删除和插值两种方法,删除就是直接把有缺失值那一行删除,这种方法简单粗暴,适合有较少确实值的大数据集,但是对于小数据集并不适合.
插值则从当前列中完好的数据中采样得到一个值,并把这个值填入缺失处
通过位置索引iloc从原始数据集data中读取内容:
inputs = data.iloc[:, 0:2]
print(inputs)
NumRooms Alley
0 NaN Pave
1 2.0 NaN
2 4.0 NaN
3 NaN NaN
使用fillna()方法,将平均值填补到NaN处:
inputs = inputs.fillna(inputs.mean())
print(inputs)
NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaN
但是fillna()方法只能填补浮点型和整型数的缺失值,不能填补字符型的缺失值,对于Alley这一列,采用pd.get_dummies()方法,把这一列有缺失值和没有缺失值的类型分开,并且用1代表是否是某类:
NumRooms Alley_Pave Alley_nan
0 3.0 1 0
1 2.0 0 1
2 4.0 0 1
3 3.0 0 1
将outputs分离出来:
outputs = data.iloc[:, 2]
print(outputs)
0 127500
1 106000
2 178100
3 140000
Name: Price, dtype: int64
现在inputs和outputs中的所有条⽬都是数值类型,它们可以转换为张量格式,然后可以进行进一步操作。
a, b = torch.tensor(inputs.values), torch.tensor(outputs.values)
print(a)
print('\n')
print(b)
print(type(a))
tensor([[3., 1., 0.],
[2., 0., 1.],
[4., 0., 1.],
[3., 0., 1.]], dtype=torch.float64)
tensor([127500, 106000, 178100, 140000])
<class 'torch.Tensor'>
第三节:线性代数
按元素操作、求和与降维
访问矩阵的转置:
A = torch.arange(20).reshape(5, 4)
print(A)
print()
print(A.T)
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]])
tensor([[ 0, 4, 8, 12, 16],
[ 1, 5, 9, 13, 17],
[ 2, 6, 10, 14, 18],
[ 3, 7, 11, 15, 19]])
默认情况下,调⽤求和函数会沿所有的轴降低张量的维度,使它变为⼀个标量。我们还可以指定张量沿哪⼀个轴来通过求和降低维度。我们可以在调⽤函数时指定axis=x。由于输⼊矩阵沿x轴降维以⽣成输出向量,因此输⼊的轴x的维数在输出形状中丢失。
对张量A:
shape:[ 5,4]
axis : (0, 1)
沿axis=0求和: [ 4]
沿axis=1求和: [5 ]
A = torch.arange(20).reshape(5, 4)
print(A.sum())
print(A.sum(axis=0)) # 求和所有行的元素来降维(轴0)
print(A.sum(axis=1)) # 求和所有行的元素来降维(轴0)
print(A.sum(axis=[0, 1])) # 沿着行和列对矩阵求和,等价于对矩阵的所有元素进行求和
print(A.sum(axis=1, keepdims=True)) # 指定轴数不变,求和的轴的参数变为1
tensor(190)
tensor([40, 45, 50, 55])
tensor([ 6, 22, 38, 54, 70])
tensor(190)
tensor([[ 6],
[22],
[38],
[54],
[70]])
以一个三维张量为例,按维数求和并指定轴数不变:
a = torch.ones(2, 5, 4)
print(a.shape)
print(a.sum(axis=1, keepdims=True).shape)
print(a.sum(axis=[0, 2], keepdims=True).shape)
torch.Size([2, 5, 4])
torch.Size([2, 1, 4])
torch.Size([1, 5, 1])
如果我们想沿某个轴计算A元素的累积总和,⽐如axis=0(按⾏计算),我们可以调⽤cumsum函数。此函数不会沿任何轴降低输⼊张量的维度
print(A.cumsum(axis=0))
tensor([[ 0, 1, 2, 3],
[ 4, 6, 8, 10],
[12, 15, 18, 21],
[24, 28, 32, 36],
[40, 45, 50, 55]])
向量、矩阵的乘法
两个向量的点积是一个标量:
x = torch.tensor([5, 3, 9, 2])
y = torch.tensor([8, 12, 7, 4])
print(torch.dot(x, y))
tensor(147)
矩阵和(列)向量
是(列)向量
:
A = torch.arange(20).reshape(5, 4)
x = torch.tensor([5, 3, 9, 2])
# print(A)
# print(x)
print(torch.mv(A, x))
tensor([ 27, 103, 179, 255, 331])
在torch里调用mm()函数实现两个矩阵的乘法(注意:不是按元素相乘)
A = torch.arange(5, 25).reshape(5, 4)
B = torch.arange(8, 20).reshape(4, 3)
# print(A)
# print(B)
print(torch.mm(A, B))
tensor([[ 340, 366, 392],
[ 540, 582, 624],
[ 740, 798, 856],
[ 940, 1014, 1088],
[1140, 1230, 1320]])
范数
范数是将向量映射到标量的函数,可以看作是一种对距离的度量,常用的范数有:
范数:即欧几里得距离,是向量元素平⽅和的平⽅根,也即向量的模(长度)
通过torch.norm()函数计算向量的范数,但是向量不可以是torch.int64类型的
x = torch.tensor([2.0, 6.4, 8.0])
print(torch.norm(x))
tensor(10.4384)
范数:向量元素的绝对值之和
print(torch.abs(x).sum())
tensor(16.4000)
torch.norm()函数是重载的,当接受一个矩阵的时候,它计算该矩阵的弗罗贝尼乌斯范数:
X = torch.arange(20, dtype=float).reshape(5, 4)
print(torch.norm(X))
(矩阵同样不可以是torch.int64类型的)
tensor(49.6991, dtype=torch.float64)
弗罗⻉尼乌斯范数满⾜向量范数的所有性质,它就像是矩阵形向量的范数
第四节:自动求导
对张量的导数
标量对标量的导数大家都很熟悉,现在把导数拓展到向量/矩阵领域

- 标量对标量的导数是标量
- 向量对标量的导数是向量
- 标量对向量的导数是向量
- 向量对向量的导数是矩阵
- 矩阵对标量的导数是矩阵
- 标量对矩阵的导数是矩阵
- 矩阵对向量的导数是三维张量
- 向量对矩阵的导数是三维张量
- 矩阵对矩阵的导数是四维张量
- …
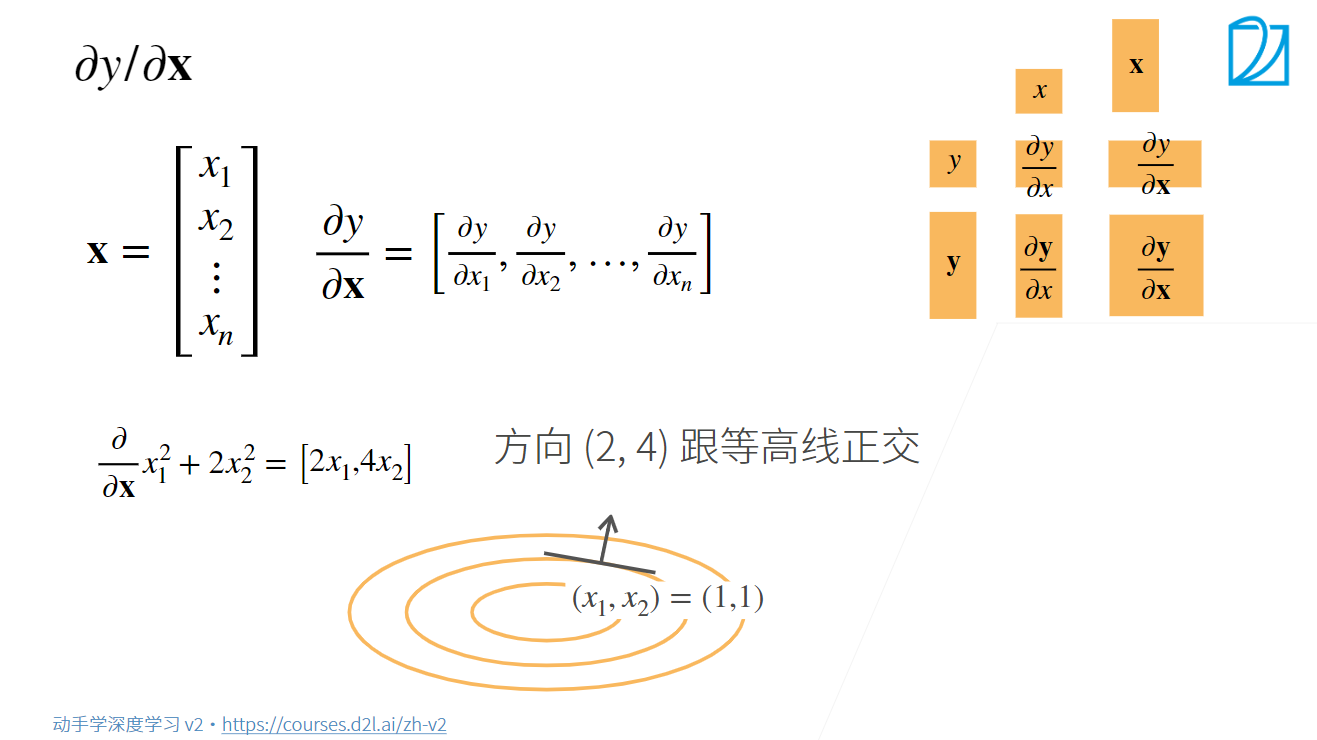
标量对向量的导数是向量(标量,向量
):

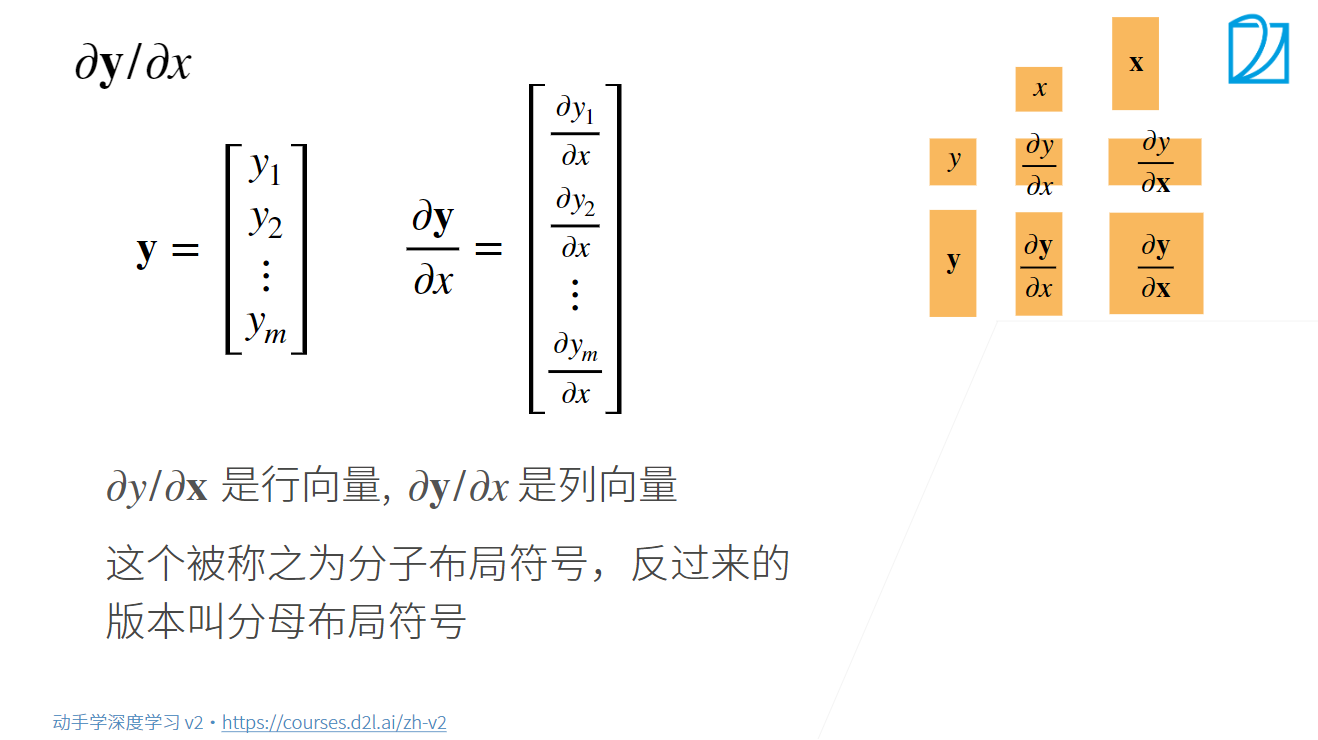
向量对标量的导数是向量(向量,标量
):
向量对向量的导数是矩阵(向量,向量
):
可以看作向量中的每一个元素(标量)先对向量求导,这些导数再组成向量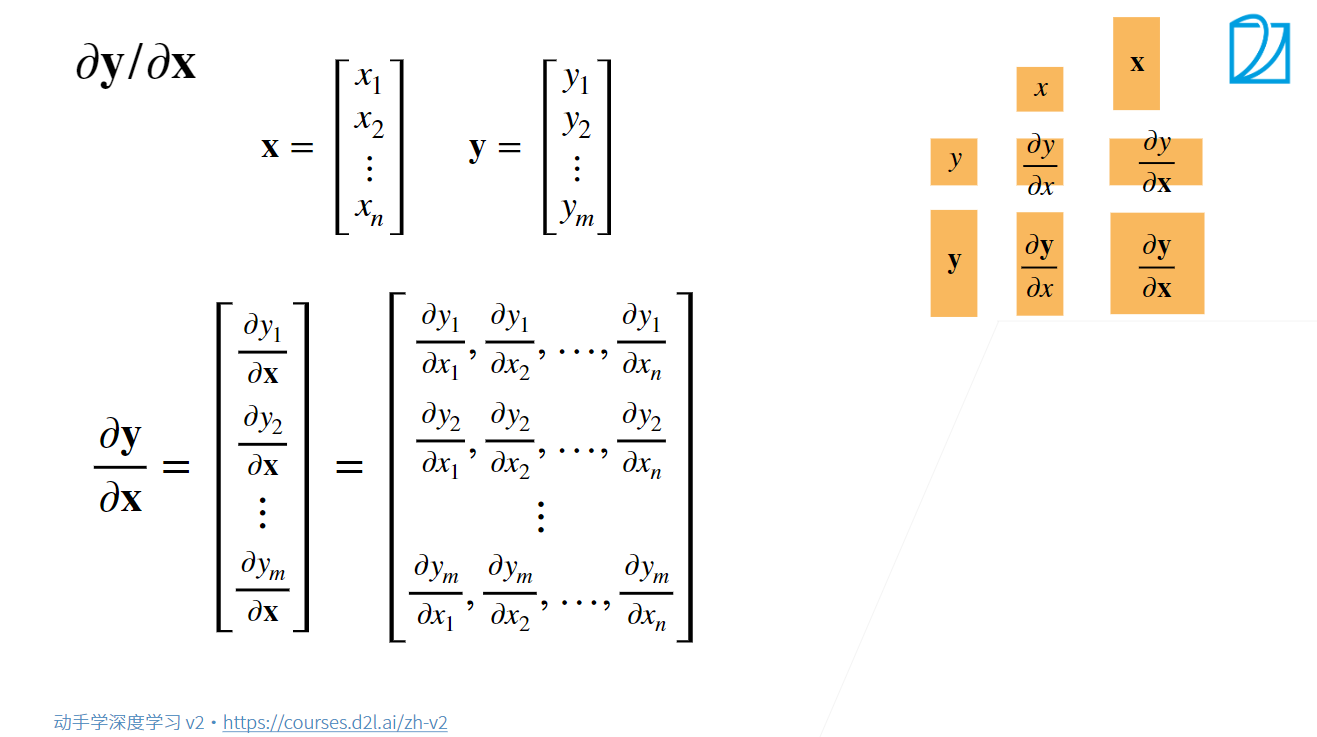

向量的链式法则
反向传播

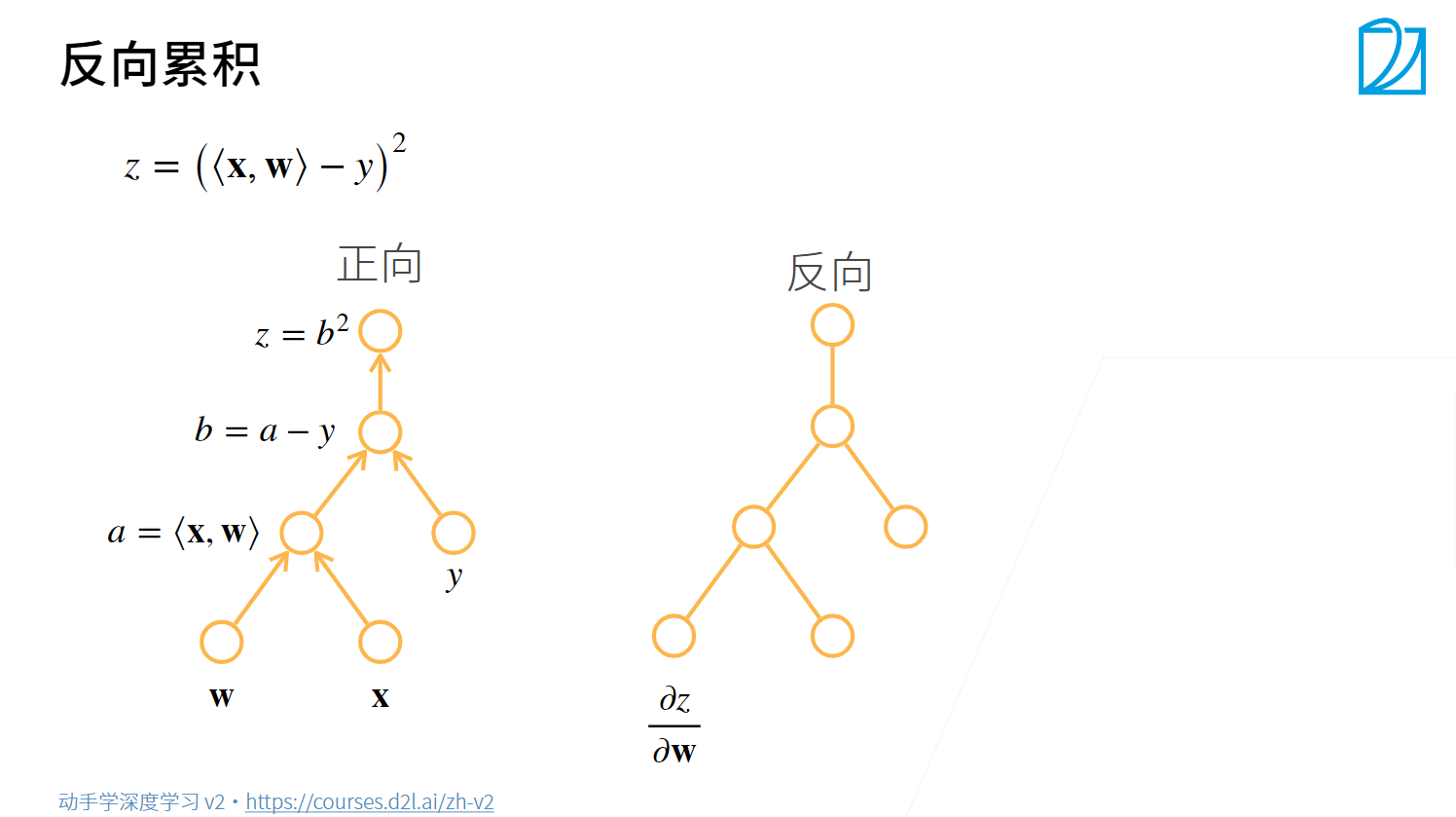
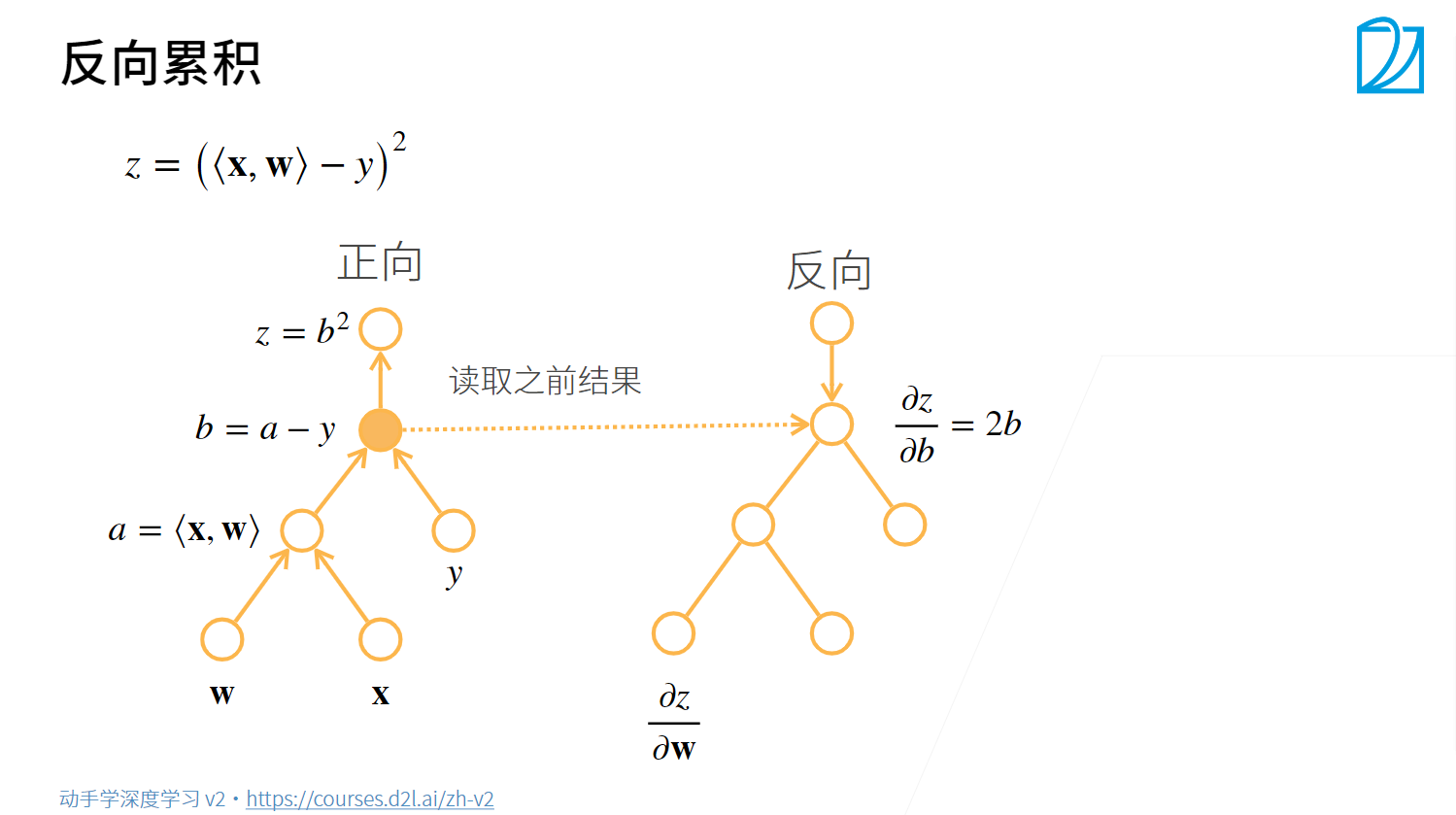
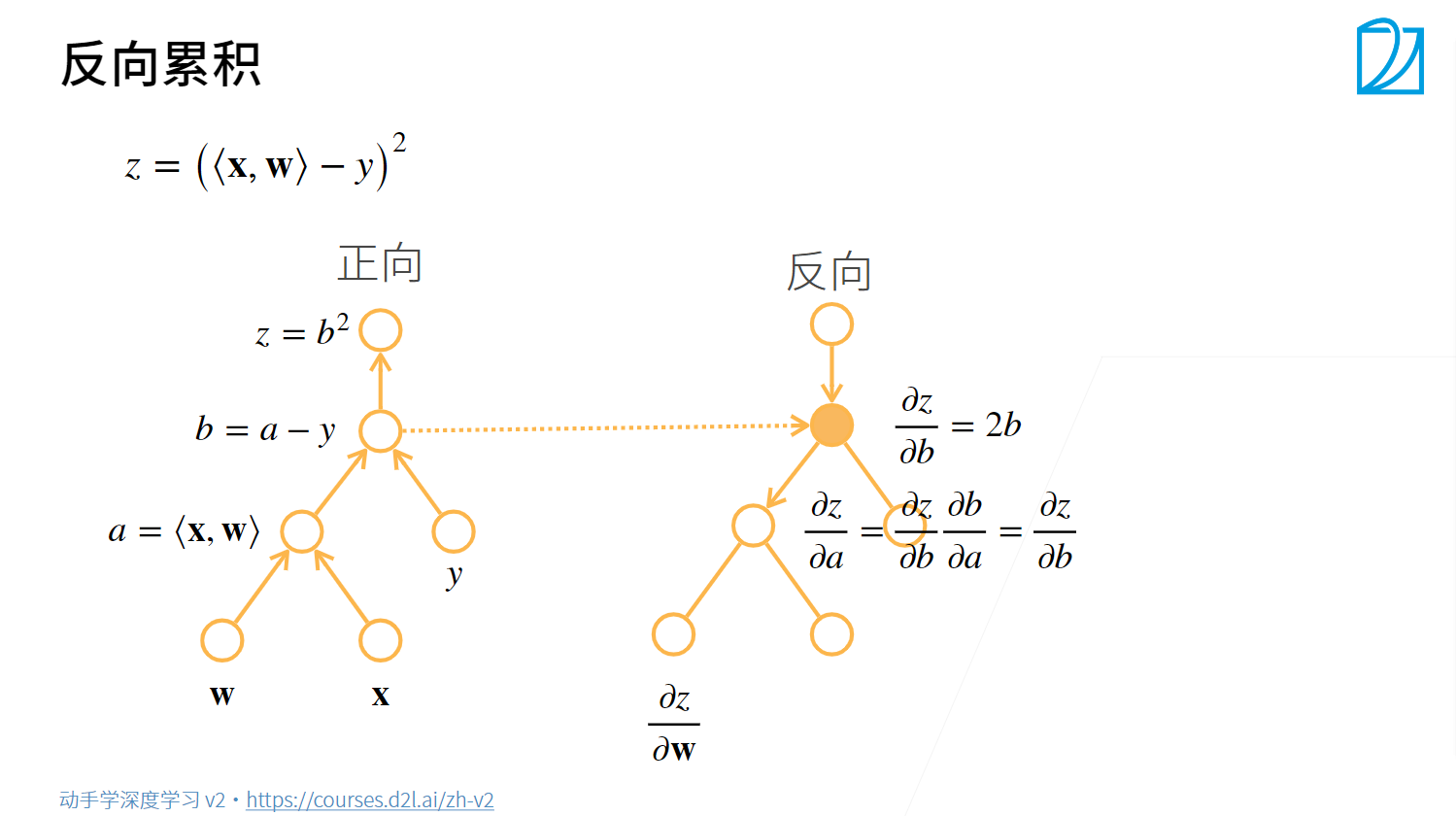
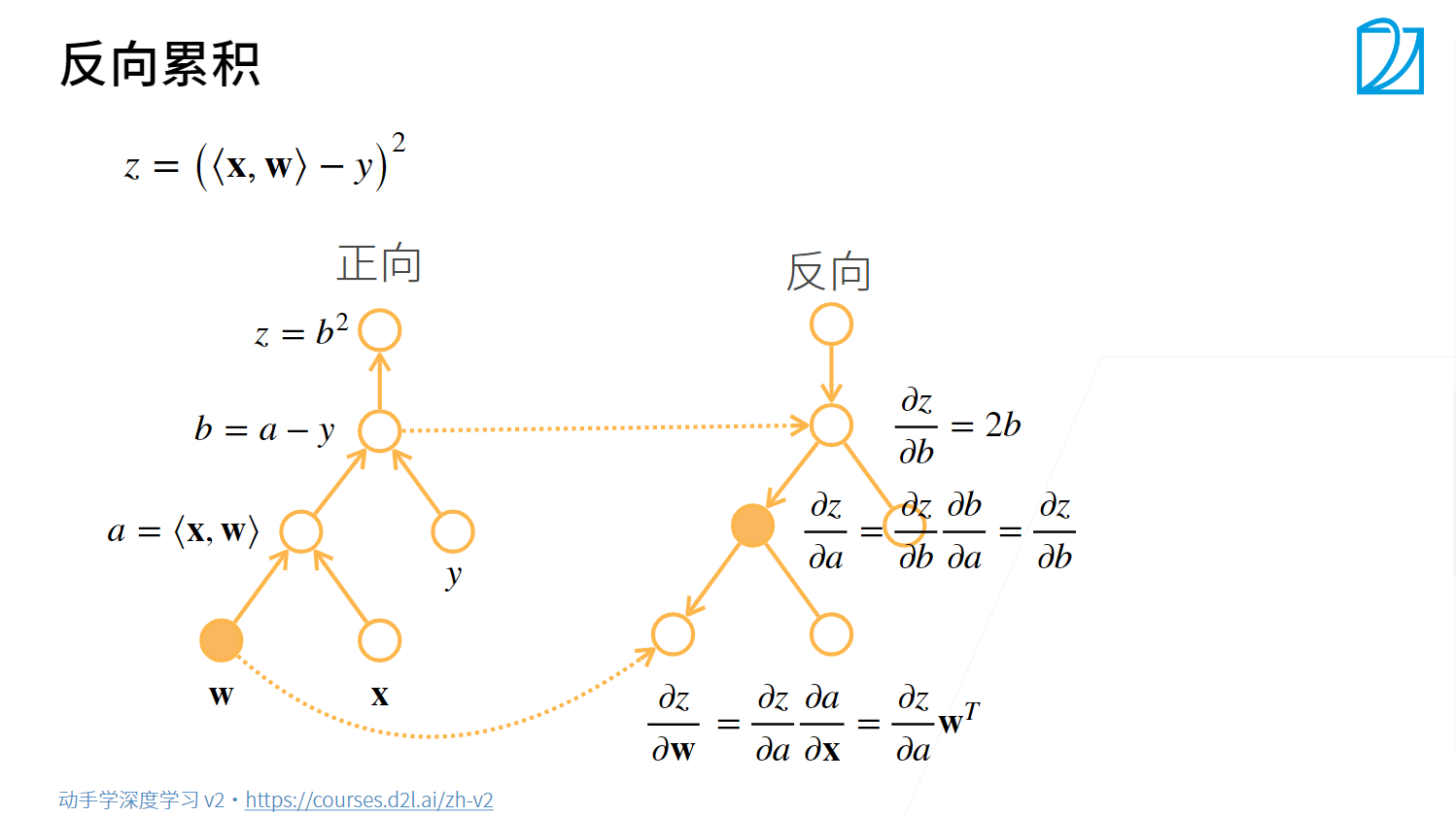


Pytorch的自动求导机制
以关于列向量
求导为例:
x = torch.arange(4.0, requires_grad=True).reshape(2, 2)
# 如果创建tensor时未指定requires_grad=True
# 也可以显式的调用方法x.requires_grad_(True)
print(x.grad)
None
创建函数:
y = 2 * torch.dot(x, x)
print(y)
调用反向传播函数计算梯度:
tensor(28., grad_fn=<MulBackward0>)
y.backward()
print(x.grad)
tensor([ 0., 4., 8., 12.])
验证:
print(x.grad == 4 * x)
tensor([True, True, True, True])
在计算另一个函数对x的梯度前需要先把原本存的梯度清零
# 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值
x.grad.zero_() # 梯度清零
y = x.sum()
y.backward()
print(x.grad)
tensor([1., 1., 1., 1.])

若有收获,就点个赞吧
0 人点赞
