学习目标:
1.数据聚合
2.自动补全
3.数据同步
4.es集群搭建
一.数据聚合
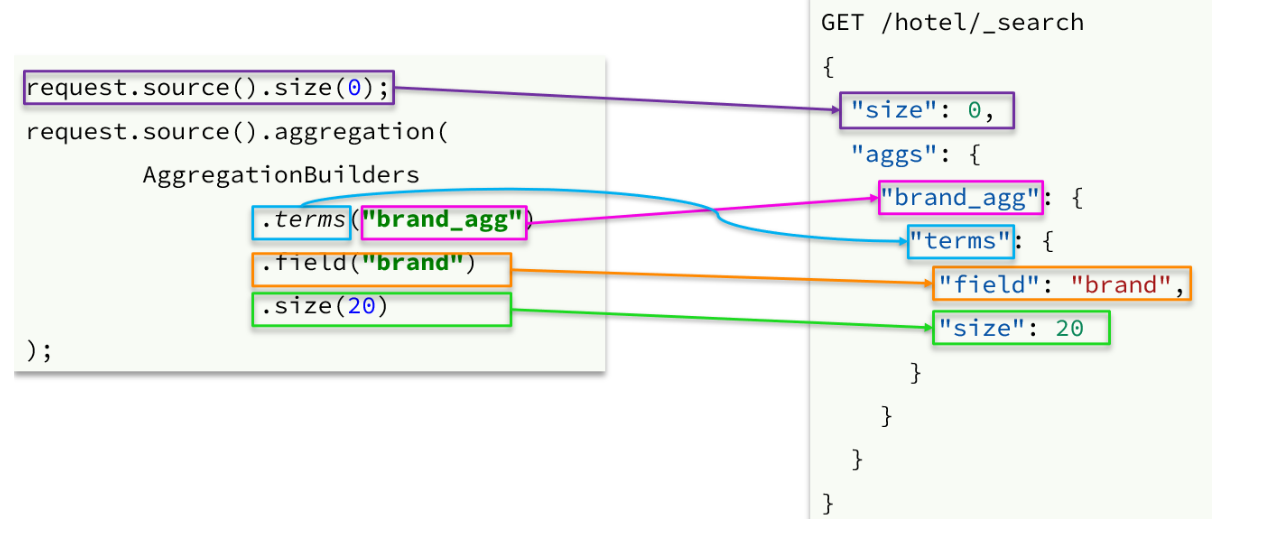
1.语法
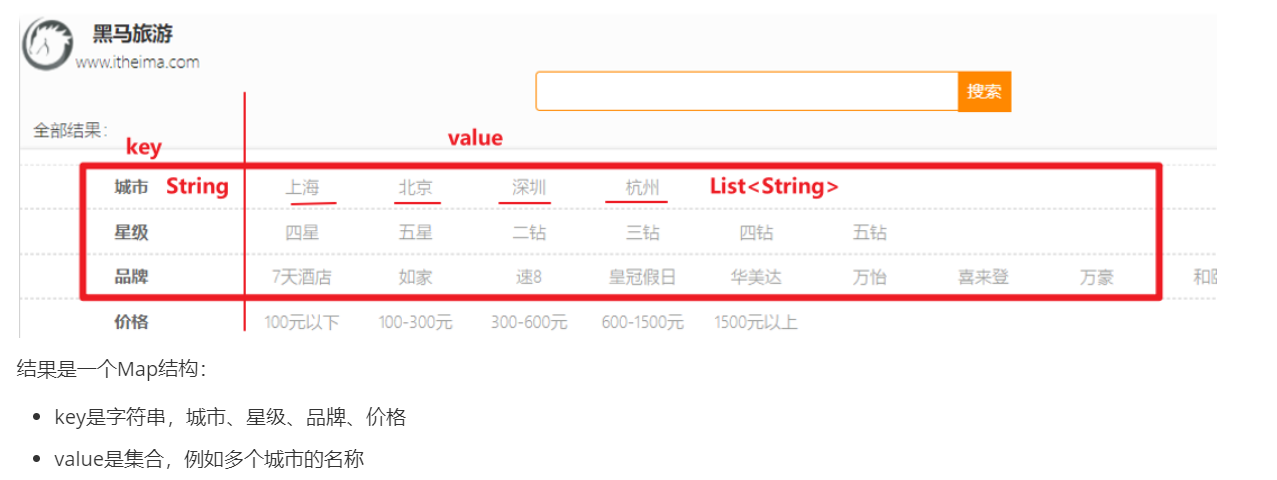
2.业务需求
3.业务实现
service层:
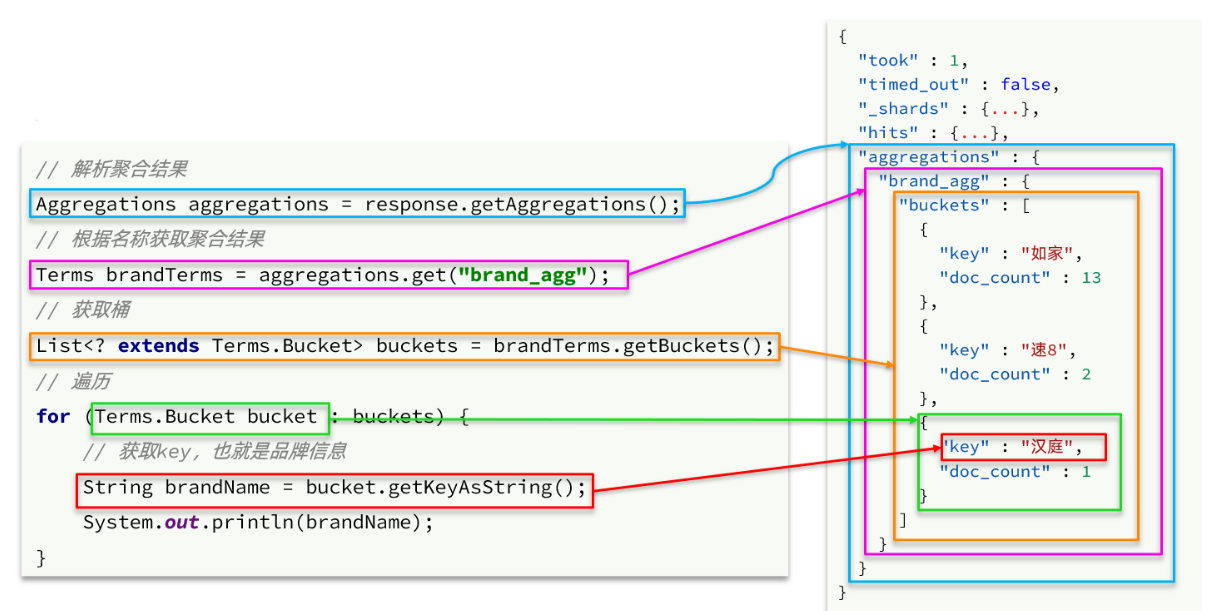
@Overridepublic Map<String, List<String>> getFilters(RequestParams params) {try {//创建请求SearchRequest request = new SearchRequest("hotel");SearchSourceBuilder source = request.source();//2.设置搜索条件buildBasicQuery(params, source); //构建搜索条件 起到过滤作用//3.设置size=0source.size(0);//4.设置聚合请求条件 brand分组 city分组,starName分组buildAggregations(source);//5.执行聚合搜索请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);//解析结果//6.1获取聚合结果Aggregations aggregations = response.getAggregations();List<String> brandList = getAggByName(aggregations, "brandAgg");List<String> cityList = getAggByName(aggregations, "cityAgg");List<String> starList = getAggByName(aggregations, "starNameAgg");//将结果封装成Map<String, List<String>>HashMap<String, List<String>> map = new HashMap<>();map.put("brand", brandList);map.put("city", cityList);map.put("starName", starList);return map;} catch (IOException e) {e.printStackTrace();throw new RuntimeException("搜索出错");}}/*** @param aggregations 聚合结果对象* @param aggName 自定义的聚合名称* @return*/private List<String> getAggByName(Aggregations aggregations, String aggName) {//6.2获取指定聚合结果Terms aggResult = aggregations.get(aggName);//6.3获取结果集合中的分组信息List<? extends Terms.Bucket> buckets = aggResult.getBuckets();//6.4遍历分组,得到分组信息ArrayList<String> resultList = new ArrayList<>();for (Terms.Bucket bucket : buckets) {//获取每个分组的key,加入到集合resultList.add(bucket.getKeyAsString());}//讲集合返回return resultList;}private void buildAggregations(SearchSourceBuilder source) {source.aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(20));source.aggregation(AggregationBuilders.terms("cityAgg").field("city").size(20));source.aggregation(AggregationBuilders.terms("starNameAgg").field("starName").size(20));}
二.自动补全
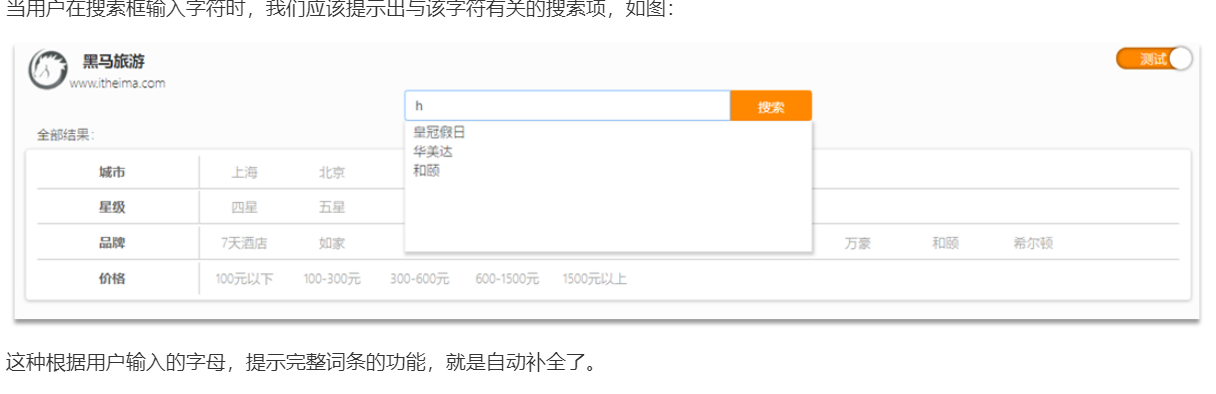
1.自动补全查询的JavaAPI
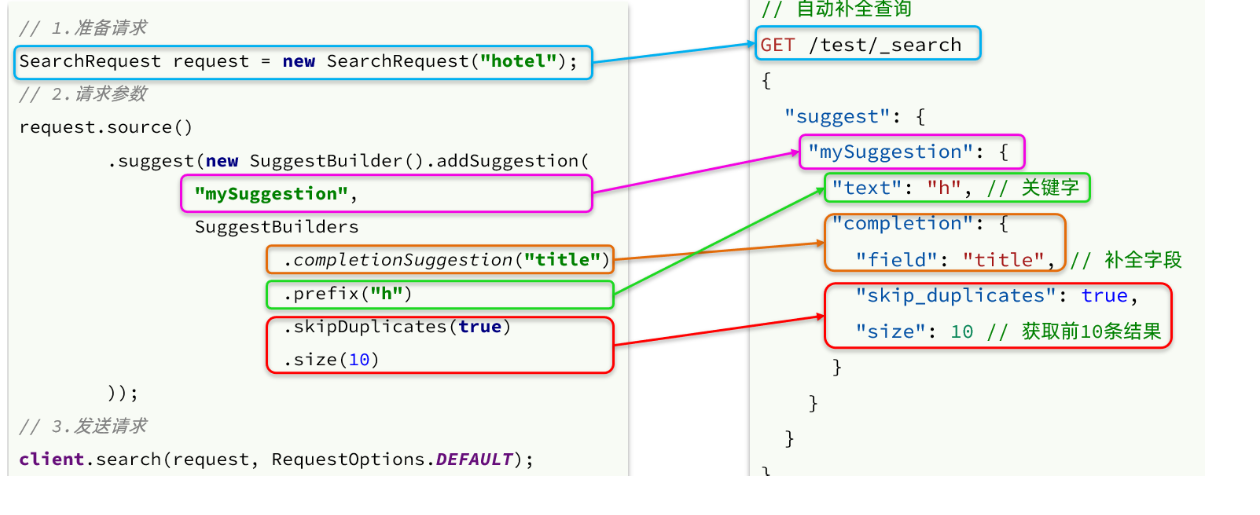
2.代码实现
@Override
public List<String> getSuggestions(String key) {
try {
//1.创建请求
SearchRequest request = new SearchRequest("hotel");
SearchSourceBuilder source = request.source();
//2.添加Suggestions搜索条件
source.suggest(
//3.搜索索引库中suggestions字段 以key为前缀的所有词条 (只显示10个)
new SuggestBuilder().addSuggestion(
"mySuggestion", //自定义查询名称
SuggestBuilders.completionSuggestion("suggestion") //建议查询的构建 参数:查询字段
.prefix(key) //前缀匹配
.skipDuplicates(true) //去重
.size(10) //保留10条
)
);
//4.执行请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
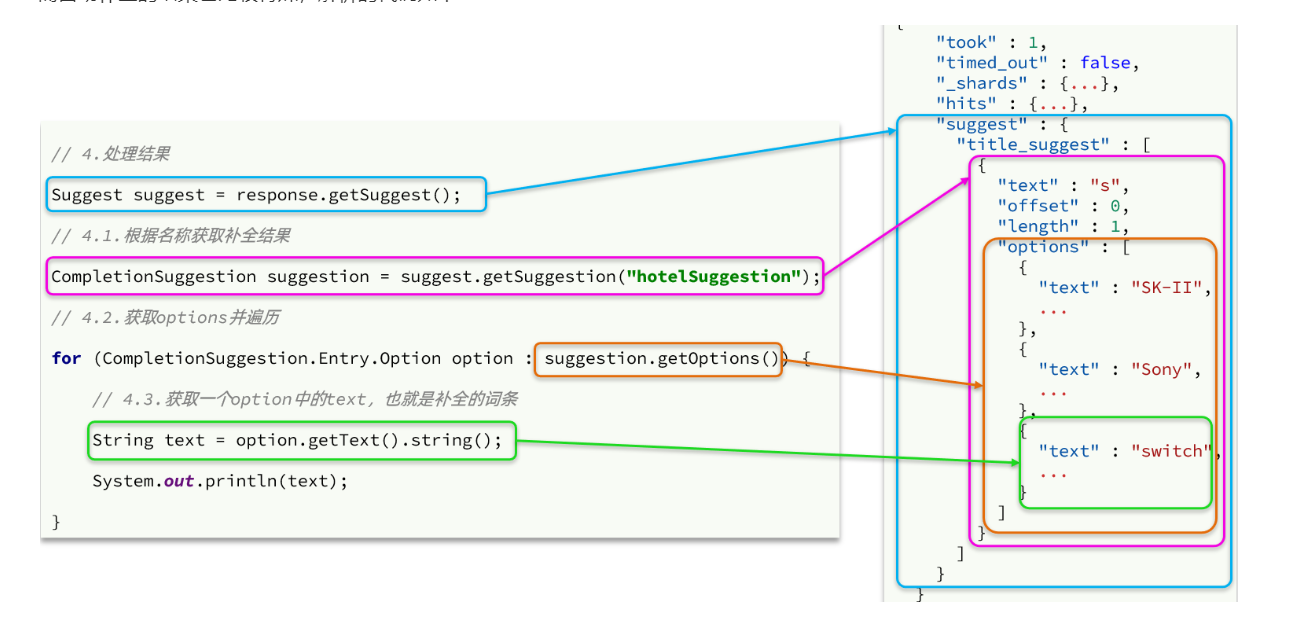
//5.解析响应结果
//查询suggest结果
Suggest suggest = response.getSuggest();
//根据自定义名称,找到具体的suggest结果
CompletionSuggestion suggestion = suggest.getSuggestion("mySuggestion");
//获取options 遍历options
List<CompletionSuggestion.Entry.Option> options = suggestion.getOptions();
List<String> suggestionList = new ArrayList<>();
for (CompletionSuggestion.Entry.Option option : options) {
suggestionList.add(option.getText().toString());
}
return suggestionList;
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException("搜索中断");
}
}
三.数据同步
1.声明交换机、队列
1)引入依赖
<!--amqp-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
2)声明队列交换机名称
package cn.itcast.hotel.constatnts;
public class MqConstants {
/**
* 交换机
*/
public final static String HOTEL_EXCHANGE = "hotel.topic";
/**
* 监听新增和修改的队列
*/
public final static String HOTEL_INSERT_QUEUE = "hotel.insert.queue";
/**
* 监听删除的队列
*/
public final static String HOTEL_DELETE_QUEUE = "hotel.delete.queue";
/**
* 新增或修改的RoutingKey
*/
public final static String HOTEL_INSERT_KEY = "hotel.insert";
/**
* 删除的RoutingKey
*/
public final static String HOTEL_DELETE_KEY = "hotel.delete";
}
3)绑定队列交换机
package cn.itcast.hotel.config;
import cn.itcast.hotel.constants.MqConstants;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MqConfig {
@Bean
public TopicExchange topicExchange(){
return new TopicExchange(MqConstants.HOTEL_EXCHANGE, true, false);
}
@Bean
public Queue insertQueue(){
return new Queue(MqConstants.HOTEL_INSERT_QUEUE, true);
}
@Bean
public Queue deleteQueue(){
return new Queue(MqConstants.HOTEL_DELETE_QUEUE, true);
}
@Bean
public Binding insertQueueBinding(){
return BindingBuilder.bind(insertQueue()).to(topicExchange()).with(MqConstants.HOTEL_INSERT_KEY);
}
@Bean
public Binding deleteQueueBinding(){
return BindingBuilder.bind(deleteQueue()).to(topicExchange()).with(MqConstants.HOTEL_DELETE_KEY);
}
}
4) 配置参数
spring:
rabbitmq:
virtual-host: /
port: 5672
host: 192.168.200.130
username: itcast
password: 123321
2.发送MQ消息
3.接收MQ消息
编写监听器
package cn.itcast.hotel.mq;
import cn.itcast.hotel.constants.MqConstants;
import cn.itcast.hotel.service.IHotelService;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class HotelListener {
@Autowired
private IHotelService hotelService;
/**
* 监听酒店新增或修改的业务
* @param id 酒店id
*/
@RabbitListener(queues = MqConstants.HOTEL_INSERT_QUEUE)
public void listenHotelInsertOrUpdate(Long id){
hotelService.insertById(id);
}
/**
* 监听酒店删除的业务
* @param id 酒店id
*/
@RabbitListener(queues = MqConstants.HOTEL_DELETE_QUEUE)
public void listenHotelDelete(Long id){
hotelService.deleteById(id);
}
}
四.集群
面试:
项目中具体使用了几台es ? (如何保证es高可用?)
我们在Linux服务器上搭建了es集群,具体几台不清楚,软件的部署安装都是运维负责的
不过es集群原理我知道些
es可以通过多台es节点,组成高可用集群,一个集群会有一个master节点,负责管理集群分片,如索引库分片
搭建集群后,我们在创建索引库时可以设置分片的数量(分片把一个索引库的数据分成若干份,每一份就是一个分片)
设置副本数量 (每一个主分片 都可以设置副本 保证分片安全 可用)
比如:我们搭建一个 3节点es集群 主分片: 3 副本分片: 1 一共6份分片数据,
master节点可以将6份分片数据分配到不同的clusterNode中,
并且保证 对应的 主分片 和 副本分片不在一起 这样分片越多能存储的数据量越大, 因为有副本 数据也是高可用的
自动选举:
如果master节点挂掉了,其它节点可以感应到 (集群节点会相互通信) 默认 : 超过半数节点认为master挂掉了 会投票选举新的master节点
故障恢复: (green yellow red)
如果任意节点挂掉,分片信号丢失此时集群状态为 yellow es会触发故障恢复,
如果主分片信号丢失 ,会基于副本 将丢失的分片数据恢复
如果副本分片信号丢失 , 会基于主分片 生成副本数据

若有收获,就点个赞吧
0 人点赞
