Redis
基础知识
基础操作
redis一共有16个数据库,默认使用第0个。
| 命令 | 注释 |
|---|---|
| keys * | 查看当前库所有key |
| flushdb | 清空当前库所有key |
| FLUSHALL | 清空所有库的所有key |
| select [number] | 切换至n号数据库(一共有16个) |
| incr | 自增1 |
| decr | 自减1 |
| getrange key start end | 截取字符串的子字符串 |
| setrange key offset value | 替换指定位置的字符串 |
| setex key seconds value | 设置过期时间 |
| setnx key value | 如果key不存在,创建key,如果存在,创建失败 |
redis是单线程的(面试知识)
Redis为什么单线程还这么快?
redis是将所有数据全部放在内存中的,所以用单线程去操作效率最高,多线程(CPU上下文会切换:耗时操作),对于内存系统来说,如果没有上下文切换效率就是最高!多次读写都是在一个CPU上的,在内存情况下,这个就是最佳方案。
五大命令操作
redis的数据结构
- redis存储的是:key,value核是的数据,其中key都是字符串,value有5种不同的数据结构
- value的数据结构:
- 字符串类型 string
- 哈希类型 hash: map格式
- 列表类型 list:linkedlist格式。支持重复元素
- 集合类型 set:不允许重复元素
- 有序集合类型 sortedset:不允许重复元素,且元素有顺序
- value的数据结构:
字符串类型 string
- 插入:
- 设置单个值:set key value
- 同时设置多个值:mset key value key value …
- msetnx:是一个原子性操作,要么一起成功,要么一起失败
- 获取:
- 获取单个值:get key
- 获取多个值:mget key key …
- 删除:del key
列表类型 list
- 插入:
- 将一个或多个值放到列表的头部:lpush key value
- 将一个或多个值放到列表的尾部:rpush key value
- 将一个值插入到某元素的前或后:linsert key before|after pivot value
- 获取:
- 获取具体的值:lrange key start stop
- 获取所有的值:lrange key 0 -1
- 通过 index 获取值:lindex key index
- 返回列表的长度:llen key
- 删除:
- 删除 list 的第一个元素:lpop key
- 删除 list 的最后一个元素:rpop key
- 删除指定元素:lrem key count value
- 截取指定长度元素,删除其他未被截取元素:ltrim key start stop
- 更新:
- 更新指定元素:lset key index value
- 组合命令: | 命令 | 注释 | | :—-: | :—-: | | rpoplpush source destination | 从source中删除最后一个元素,再把这个元素存放到destination的头部 | | | | | | |
集合类型 set(无序)
- 插入:sadd key member
- 获取:
- 获取指定set的所有值:smembers key
- 获取指定set的内容个数:scard key
- 查询指定set的指定值是否存在:sismember key member
- 随机抽取一个元素:srandmember key
- 随机抽取多个元素:srandmember key number
- 删除:
- 删除指定元素:srem key member
- 随机删除一个元素:spop key
- 移动:
- 移动指定的元素到另一个集合中:smove source destination member
- 集合:
- 差集:sdiff key1 key2
- 交集(可实现共同好友):sinter key1 key2
- 并集:sunion key1 key2
集合类型Zset(有序)
- 插入:zadd key
获取:
- 获取所有元素:zrange key 0 -1
- 获取全部元素,从大到小: zrevrange key 0 -1
获取全部元素,从小到大,并附带值:(inf是无穷)
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf withscores1) "xiaohong"2) "2500"3) "ysh"4) "2500"5) "zhangsan"6) "5000"
获取元素个数:zcard key
- 获取指定区间的元素个数:zcount key min max
- 删除:
- 删除指定元素:zrem key member
哈希类型 hash
- 存储:
- 插入一个key-value:hset key field value
- 插入多个key-value:hmset key field value [field value …]
- 获取:
- 获取一个字段值:hget key field
- 获取多个字段值:hmget key field
- 获取全部数据:hgetall key field
- 获取字段数量:hlen key
- 获取所有的key:hkeys key
- 获取所有的value:hvals key
- 删除:
- 删除指定的key字段:hdel key field
- 增减:
- hincrby key field increment
Hyperloglog
什么是基数?
两个集合中不重复的元素称为基数
简介
优点:占用的内存是固定的,2^64不同的元素的技术,只需要花费12KB内存!如果要从内存角度来比较,Hyperloglog为首选。
作用:用于页面统计(0.81%错误率)
- 存储:
- pfadd key element
- 获取:
- 统计key中元素个数:pfcount key
- 合并(并集):
- PFMERGE destkey sourcekey
Bitmap
位存储
Bitmaps的值只有0和1,是二进制运算
作用:统计用户信息,活跃、不活跃!登录、未登录!打卡!
- 存储:
- setbit key offset value
- 获取:
- 获取key中指定元素的值:getbit key offset
- 统计key中值为1的元素个数:bitcount key
事务
Redis事务本质:一组命令的集合,或者说是一个命令队列。一个事务中的所有命令都会被序列化,在执行事务的过程中,会按照顺序执行。
注意!
- Redis事务没有隔离级别的概念
- 所有的命令在事务中,并没有被直接执行,只有发起执行命令的时候才会执行
- Redis单条命令是原子性的,但是事务不保证原子性
Redis的事务
- 开启事务(multi)
- 命令入列(……)
- 执行事务(exec)
- 取消事务(discrad)
正常执行事务
127.0.0.1:6379> multiOK127.0.0.1:6379> set k1 v1QUEUED127.0.0.1:6379> set k2 v2QUEUED127.0.0.1:6379> set k3 v3QUEUED127.0.0.1:6379> get k1QUEUED#127.0.0.1:6379> discrad - 取消事务127.0.0.1:6379> exec1) OK2) OK3) OK4) "v1"127.0.0.1:6379> keys *1) "k3"2) "k2"3) "k1"
编译型异常
127.0.0.1:6379> multiOK127.0.0.1:6379> set k1 v1QUEUED127.0.0.1:6379> set k2 v2QUEUED127.0.0.1:6379> getset k1 #错误的命令(error) ERR wrong number of arguments for 'getset' command #编译报错127.0.0.1:6379> set k3 v3QUEUED127.0.0.1:6379> set k4 v4QUEUED127.0.0.1:6379> exec #执行报错(error) EXECABORT Transaction discarded because of previous errors.127.0.0.1:6379> keys * #事务直接失败,其他语句也不能正常执行(empty list or set)
运行时异常
127.0.0.1:6379> set k1 "v1"OK127.0.0.1:6379> get k1"v1"127.0.0.1:6379> multiOK127.0.0.1:6379> incr k1 #命令正确,语法错误QUEUED127.0.0.1:6379> set k2 v2QUEUED127.0.0.1:6379> set k3 v3QUEUED127.0.0.1:6379> get k3QUEUED127.0.0.1:6379> exec1) (error) ERR value is not an integer or out of range #报错2) OK #其他语句正常执行3) OK4) "v3"127.0.0.1:6379> keys *1) "k3"2) "k2"3) "k1"
乐观锁与悲观锁
监控watch(面试常问)
悲观锁:
- 很悲观,认为什么时候都会出问题,无论做什么都会加锁
乐观锁:
- 很乐观,认为什么时候都不会出问题,所以不会上锁更新数据的时候去判断一下,在此期间是否有人修改过数据
- 获取version
- 更新的时候比较version
- 开启监控:watch key
- 关闭监控:unwatch key
Jedis
使用Java来操作Redis
<!-- jedis --><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.4.1</version></dependency>
SpringBoot整合
说明:在SpringBoot2.x之后,原来使用的jedis被替换成了lettuce
- jedis:采用直连,多个线程操作的话,是不安全的,如果想要避免不安全的,使用jedis pool连接池(BIO)
- lettuce:采用netty,实例可以在多个线程中进行共享,不存在线程不安全的情况!可以减少线程数据(NIO)
源码分析
@Bean@ConditionalOnMissingBean(name = "redisTemplate") //可以自己定义redisTemplate来替换这个默认的@ConditionalOnSingleCandidate(RedisConnectionFactory.class)public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {//默认的RedisTemplate没有过多的设置,redis对象都是需要序列化的//两个泛型都是Object,需要强转RedisTemplate<Object, Object> template = new RedisTemplate<>();template.setConnectionFactory(redisConnectionFactory);return template;}@Bean@ConditionalOnMissingBean //由于String是redis最常使用的类型,所以单独提出来了一个bean@ConditionalOnSingleCandidate(RedisConnectionFactory.class)public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) {StringRedisTemplate template = new StringRedisTemplate();template.setConnectionFactory(redisConnectionFactory);return template;}
自定义RedisTemplate
@Configurationpublic class RedisConfig {/*** 自定义redisTemplate* @param redisConnectionFactory* @return*/@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {// 为了方便开发,一般直接使用<String, Object>RedisTemplate<String, Object> template = new RedisTemplate<>();template.setConnectionFactory(redisConnectionFactory);// Json序列化配置Jackson2JsonRedisSerializer<Object> objectJackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);ObjectMapper objectMapper = new ObjectMapper();objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);objectMapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance ,ObjectMapper.DefaultTyping.NON_FINAL,JsonTypeInfo.As.WRAPPER_ARRAY);objectJackson2JsonRedisSerializer.setObjectMapper(objectMapper);// String的序列化StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();// key采用String的序列化方式template.setKeySerializer(stringRedisSerializer);// hash的key采用String的序列化方式template.setHashKeySerializer(stringRedisSerializer);// value序列化方式采用jacksontemplate.setValueSerializer(objectJackson2JsonRedisSerializer);// hash的value序列化方式采用jacksontemplate.setHashValueSerializer(objectJackson2JsonRedisSerializer);template.afterPropertiesSet();return template;}}
Redis.conf
配置详解
单位
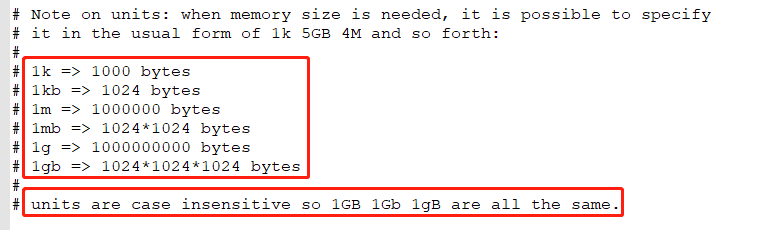
网络
bind 127.0.0.1 # 绑定的ipprotected-mode yes # 保护模式port 6379 # 端口设置
设置redis密码
注意:redis密码默认为空
127.0.0.1:6379> config set requirepass "123456" # 设置密码OK127.0.0.1:6379> auth 123456 # 登录OK
Redis持久化
Redis是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失。(断电即失)
RDB(Redis DataBase)
什么是RDB
在主从复制中,rdb就是备用的,在从机上使用rdb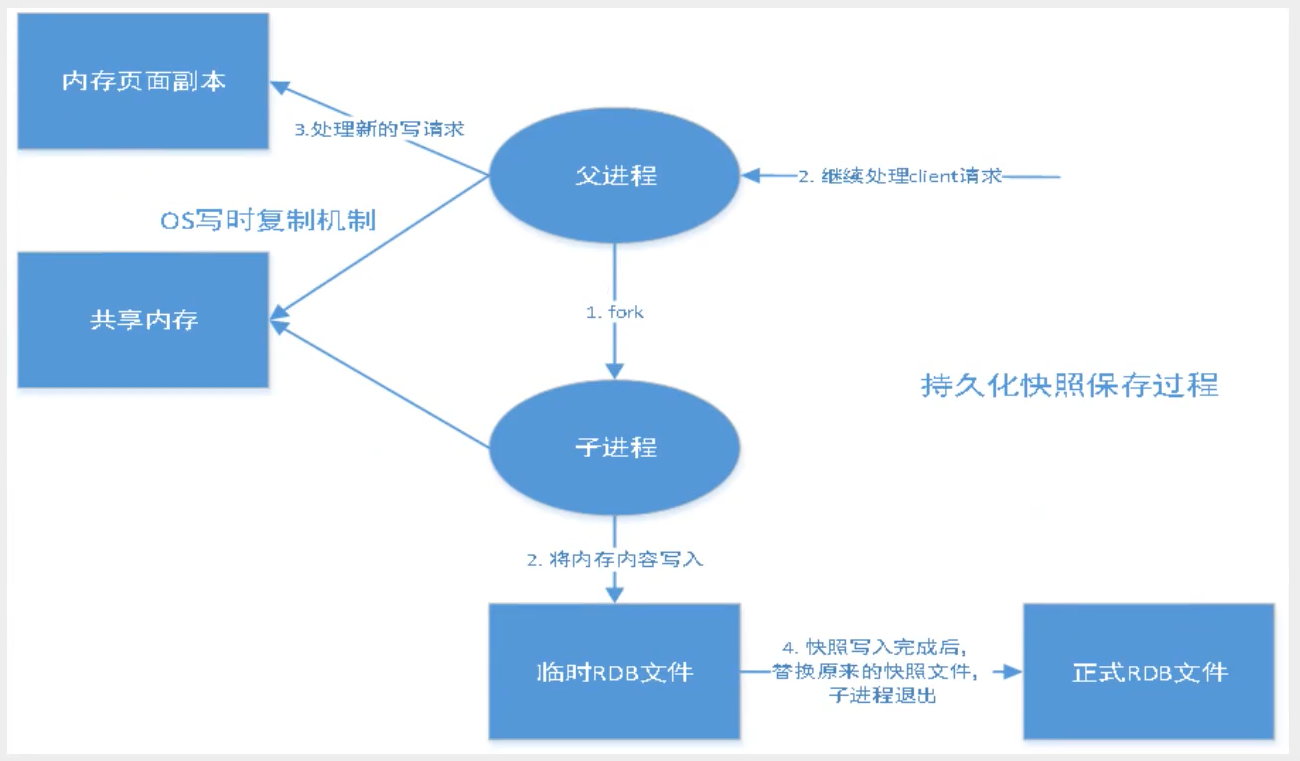
RDB保存的是dump.rdb文件
触发机制
- save的规则满足的情况下,会自动触发rdb规则
- 执行flushall命令,也会触发rdb规则
- 退出redis,也会产生rdb文件
备份就自动生成一个dump.rdb
如何恢复rdb文件
- 只需要将rdb备份文件放在redis启动目录即可,redis启动时会自动检查dump.rdb恢复其中的数据
- 查看需要存在的位置
127.0.0.1:6379> config get dir1) "dir"2) "/usr/local/bin"
优缺点
优点:
- 适合大规模的数据恢复
- 对数据的完整性要求不高
缺点:
- 需要一定时间间隔进程操作!如果redis意外宕机了,这个最后一次修改数据就没有了
- fork进程,会占用一定的空间
AOF(Append Only File)
什么是AOF
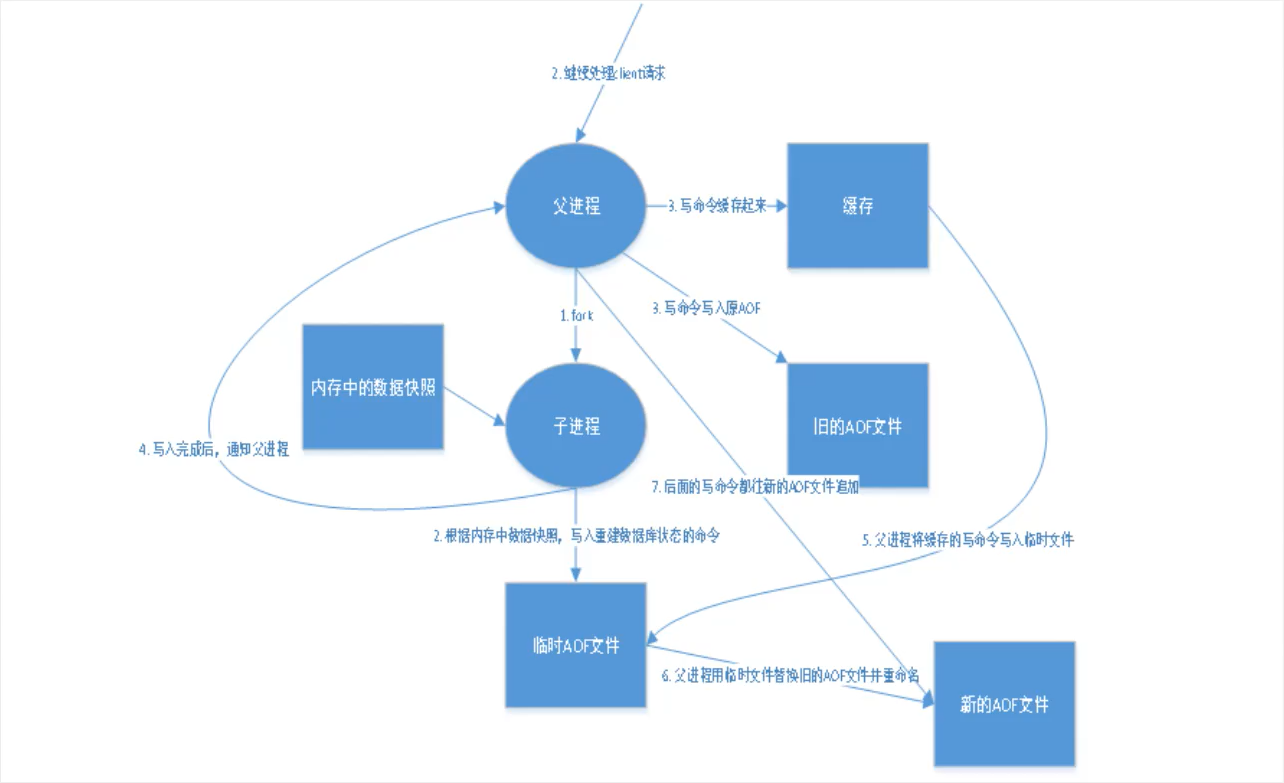
以日志的形式来记录每个写操作,将Redis执行过的所有写操作指令记录下来,只许追加文件但不可以改写文件,redis启动之时会读取该文件重新构建数据,即redis重启的话会根据这个日志文件的内容将指令从前到后执行一次,以完成数据的恢复工作。
AOF保存的是appendonly.aof文件
修复aof文件
- 如果这个aof文件有错误,redis是启动不起来的,我们需要修复这个文件
- redis给我们提供了一个工具:redis-check-aof —fix 文件名
重写
no-appendfsync-on-rewrite no # 默认是关闭auto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mb # 如果aof文件大于64mb,就会fork一个新的进程来重写文件
优缺点
appendonly no # 默认是不开启aof模式,默认是使用rdbappendfilename "appendonly.aof" # aof模式下的文件名# appendfsync always # 每次修改都会sync(加锁)appendfsync everysec # 每秒执行一次sync,可能会丢失这1s的数据# appendfsync no # 不执行sync,这个时候操作系统自己同步数据,效率最高
优点:
- 每一次修改都同步,文件的完整性会更好
- 默认开启每秒同步一次,可能会丢失一秒的数据
- 从不同步,效率最高
缺点:
- 相对于数据文件来说,aof远远大于rdb,修复的速度也比rdb慢
- aof运行效率也要比rdb慢,所以redis默认配置就是rdb持久化
Redis发布订阅
命令
这些命令被广泛用于构建即时通信应用,比如聊天室和实时广播、实时提醒等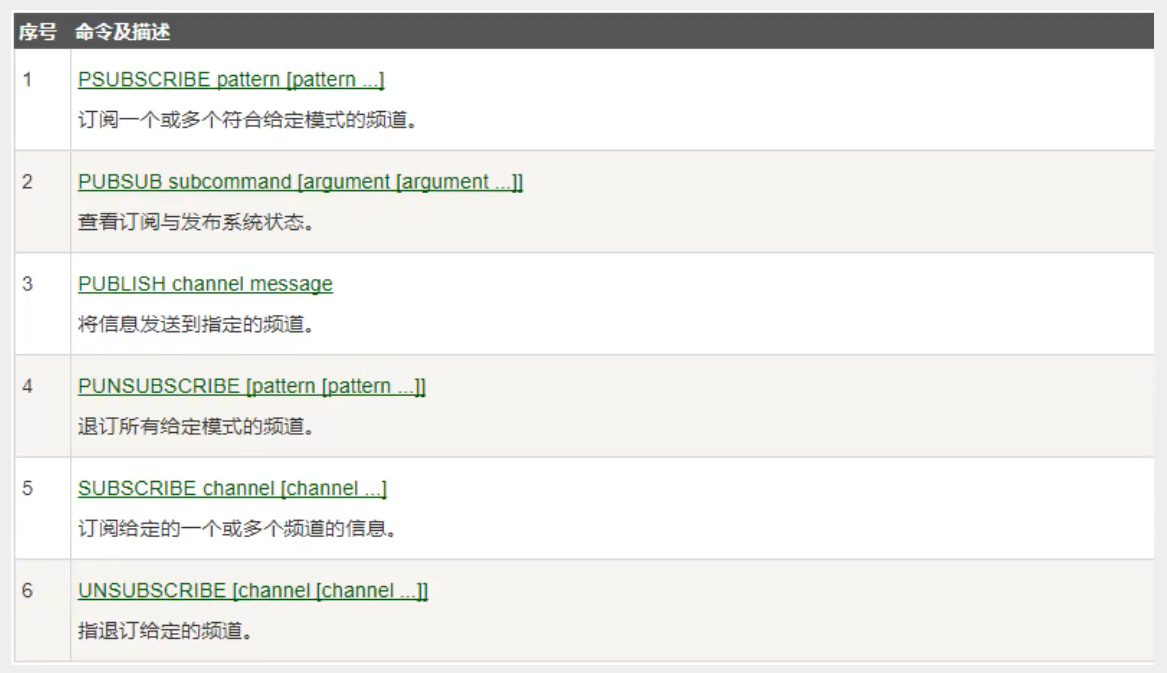
Redis主从复制
概念
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master/leader),后者称为从节点(slave/follower);**数据的复制时单向的,只能由主节点到从节点**。Master以写为主,Slave以读为主。默认情况下,每台Redis服务器都是主节点,且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制的作用主要包括:
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复,实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器压力;尤其在写少读多的场景下,通过多个节点分担读压力,可以大大提高Redis服务器的并发量。
- 高可用(集群)基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础。
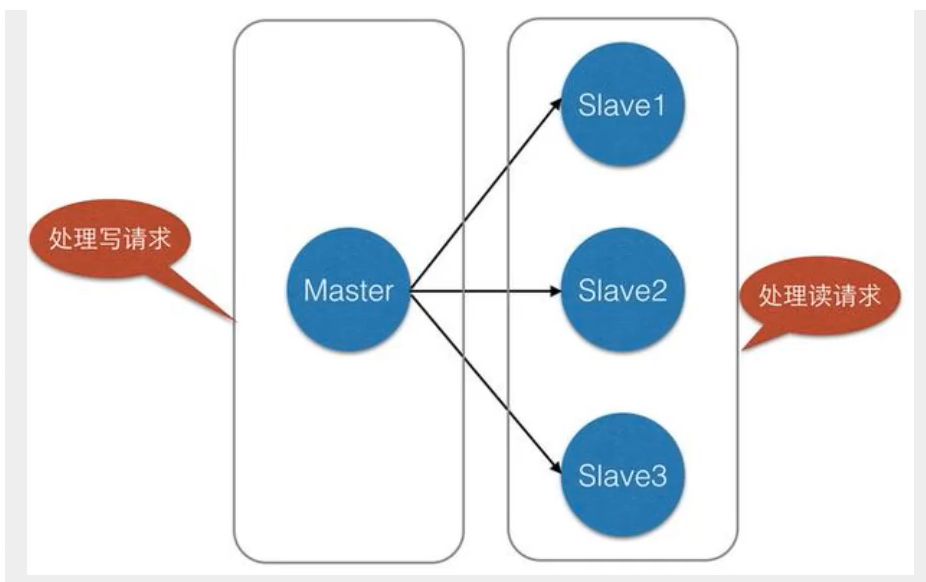
主从复制,读写分离。80%的情况下都是在进行读操作!可以减缓服务器的压力,架构中经常使用,一主二从!
环境配置

若有收获,就点个赞吧
0 人点赞
