上一讲我讲了 Serverless 架构兴起的必然因素,在这个过程中,我简单提到了 Serverless 的概念,相信你对 Serverless 已经有了初步的认知,这节课我将继续深入剖析到底什么是 Serverless。
有不少刚接触 Serverless 的同学会认为 FaaS 就是 Serverless,也有同学认为 PaaS 也是 Serverless,还有同学说使用 Serverless 就没有服务器了。总的来说,很多同学对 Serverless 到底是什么并没有一个很清晰的认知,概念还比较模糊,所以咱们就用一节课的时间,搞定这个概念。
在我看来,你可以从广义和狭义两个角度入手,这样会更清楚 Serverless 的特点,对它有个整体的认知。
先来看一下广义上的 Serverless 是指什么?
广义的 Serverless
在我看来,广义的 Serverless 是指:构建和运行软件时不需要关心服务器的一种架构思想。 虽然 Serverless 翻译过来是 “无服务器”,但这并不代表着应用运行不需要服务器,而是开发者不需要关心服务器。而基于 Serverless 思想实现的软件架构就是 Serverless 架构。
那与 Serverless 对应的概念就是 Serverful。回顾上一篇中的电商网站,我们直接在虚拟机上部署网站的架构,就是 Serverful 的架构,在这种架构下,如果要保证网站持续稳定运行,就需要解决很多问题。
- 备份容灾: 要实现服务器、数据库的备份容灾机制,使一台服务器出故障不影响整个系统。
- 弹性伸缩: 系统能根据业务流量大小等指标,响应式地调整服务规模,实现自动弹性伸缩。
- 日志监控: 需要记录详细的日志,方便排查问题和观察系统运行情况,并且实现实时的系统监控和业务监控。
解决这些复杂的问题需要投入大量的人力、物力,小公司几乎无法自己去解决。而对开发者来说,Serverful 的架构开发成本也非常高,原本几行代码就可以搞定一个简单的业务逻辑,但你却得添加庞大的框架,比如 RPC(Remote Procedure Call,远程调用)、缓存等。
Serverless 就是为了解决这些问题诞生的。 它可以把底层的硬件、存储等基础资源隐藏起来,由平台统一调度、运维。并将常用的基础技术抽象、封装(比如数据库、消息队列等)以服务的方式提供给开发者。开发者只专注于开发业务逻辑,所有业务无关的基础设施,都交给 Serverless 平台。
总之, Serverless 和 Serverful 的架构有这样几个区别。
- 资源分配: 在 Serverless 架构中,你不用关心应用运行的资源(比如服务配置、磁盘大小)只提供一份代码就行。
- 计费方式: 在 Serverless 架构中,计费方式按实际使用量计费(比如函数调用次数、运行时长),不按传统的执行代码所需的资源计费(比如固定 CPU)。计费粒度也精确到了毫秒级,而不是传统的小时级别。
- 弹性伸缩: Serverless 架构的弹性伸缩更自动化、更精确,可以快速根据业务并发扩容更多的实例,甚至允许缩容到零实例状态来实现零费用,对用户来说是完全无感知的。而传统架构对服务器(虚拟机)进行扩容,虚拟机的启动速度也比较慢,需要几分钟甚至更久。
所以,一个应用如果是 Serverless 架构的,必须要实现自动弹性伸缩和按量付费,这也是 Serverless 的核心特点。
狭义的 Serverless
广义的 Serverless 更多是指一种技术理念,狭义的 Serverless 则是现阶段主流的技术实现。之所以说是狭义的,是因为 Serverless 架构正在持续发展中,未来可能有更好的技术方案。
在我看来,狭义的 Serverless 是 FaaS 和 BaaS 的组合,为什么呢?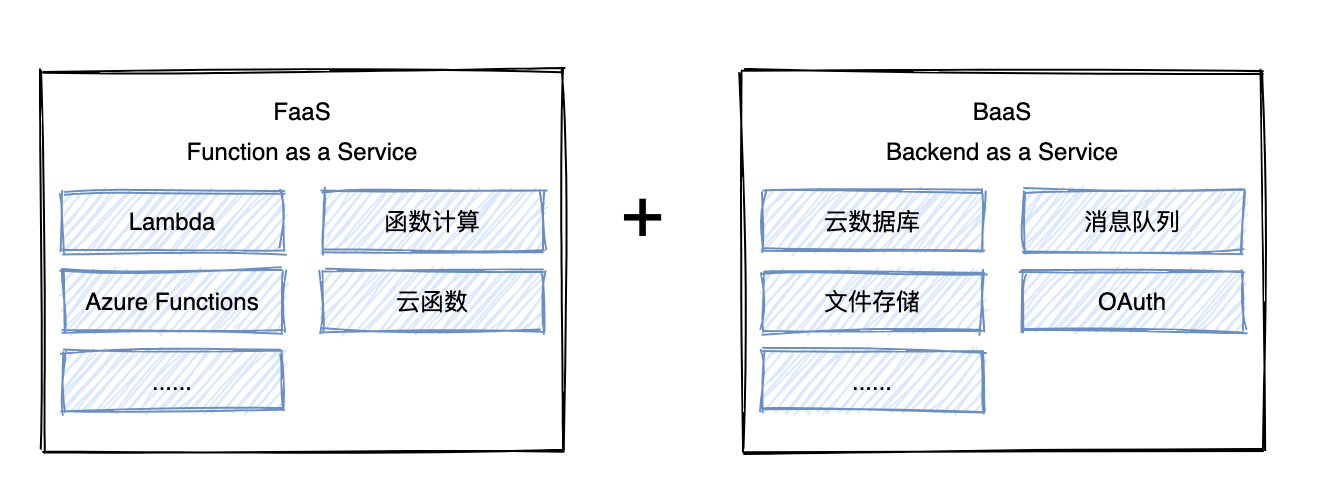
Serverless 架构图
为了弄清楚这个问题,你需要对 FaaS 和 BaaS 有更多的了解。在 01 讲,我简单地提了 FaaS 和 BaaS 的概念,接下来我从一个案例入手,带你对其进行更深入的剖析。
假设你要实现一个接口,返回一个数组,你用的是 Node.js,传统的写法如下:
// index.jsconst express = require('express');const app = express();const port = process.env.PORT || 3000;// 定义 /list 路由app.get('/list', (req, res) => {const data = ['a', 'b', 'c'];// 返回 data 数组res.json(data);});// 监听 3000 端口并启动服务app.listen(port, () => {console.log(`Express running on http://localhost:${port}`);});
如果想让这个接口对外提供服务,还要买一台服务器,在服务器上安装 Node.js 运行环境,然后把这段代码上传到服务器上,通过 node index.js 命令运行起来。然后还要购买域名(如 www.example.com),将域名解析到服务器上,再在服务器上安装 Nginx ,编写 Nginx 配置监听服务器的 80 端口,并将域名下的请求转发到 3000 端口。
既然 Serverless 架构可以让你不关心服务器,那怎么用 Serverless 架构去实现这个功能呢?答案就是 FaaS。
FaaS(Function as a Service)本质上是一个函数运行平台,大多 FaaS 产品都支持 Node.js、Python、Java等编程语言,你可以选择你喜欢的编程语言编写函数并运行。函数运行时,你对底层的服务器是无感知的,FaaS 产品会负责资源的调度和运维,这是它的特点之一,不用运维。
另外,FaaS 中的函数也不是持续运行的,而是通过事件进行触发,比如 HTTP 事件、消息事件等,产生事件的源头叫触发器,FaaS 平台会集成这些触发器,我们直接用就行,这是 FaaS 的第二个特点,事件驱动。
FaaS 的第三个特点是按量付费。 FaaS 产品的收费方式,都是按照函数执行次数和执行时消耗的 CPU、内存等资源进行计费的。除此之外,FaaS 在运行函数的时候,会根据并发量自动生成多个函数实例,并且并发理论是没有上限的,这是它的第四个特点,弹性伸缩。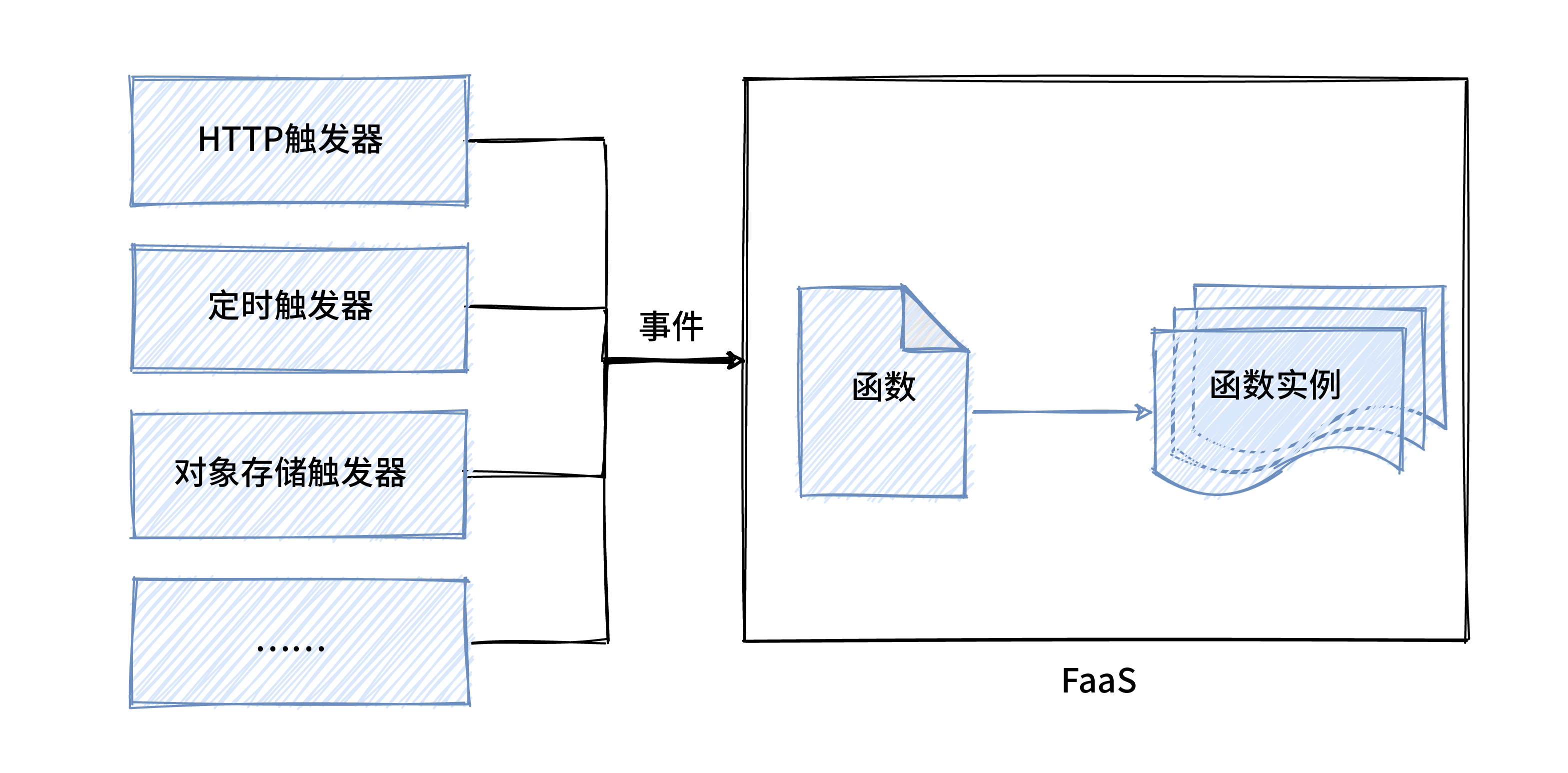
FaaS 架构图
基于 FaaS,实现上面的接口就简单了,你只需要写一个函数,然后把代码部署到 FaaS 产品上,设置 HTTP 触发器就可以了。
function handler(event) {// data 数组就是接口的返回数据const data = ['a', 'b', 'c'];return data;}
那假设接下来你要实现一个计算 PV(即页面浏览量或点击量,用户每1次对网站中的每个网页访问均被记录1个PV。用户对同一页面的多次访问,访问量累计,用以衡量网站用户访问的网页数量) 的接口,简单一点你直接在内存中存储 PV,使用 FaaS 你可能会这样写:
// 使用全局变量存储当前 PVlet pv = 0;function handler(event) {// 用户每访问一次就给 PV 的值加 1pv++;return pv;}
当你把函数部署到 FaaS,然后访问接口时,会发现得到的结果永远都是 1。这是因为 FaaS 每次执行函数时,都会初始化一个新的运行环境,然后从头开始执行整个代码,而不是只执行其中的 handler 方法。执行完毕后,运行环境就会被释放。这样每次函数执行,都是新的运行环境,自然不同函数之间就无法共用 pv 这个变量了。这是 FaaS 的另一个特点,无状态。
然而有时候你可能就想要在不同函数中共享内存,怎么办呢?这个问题抽象一下,就是分布式中的状态共享问题。为了解决这个问题,所以 BaaS(Backend as a Service)也被纳入 Serverless 的一部分。
在 01 讲中,我提到 BaaS 本质上就是把后端功能封装起来,以接口的形式提供服务。BaaS 的涵盖范围比较广,包含任何应用运行所依赖的服务,典型的有数据库、中间件等。在 Serverless 架构中,常见的 BaaS 产品有 AWS DynamoDB、阿里云表格存储、消息中间件等,这些服务都可以通过 API 进行访问。这样在 FaaS 中,你就可以通过接口来使用 BaaS,基于 BaaS 来存储数据、实现函数间状态共享了。
所以要实现 pv 统计功能,你可以用表格存储这个 BaaS 服务,表格存储是一个 NoSQL 数据库,可以通过 API 来访问,伪代码如下:
const tablestore = require('tablestore');async function handler(event) {// 从表格存储中获取当前 PVlet pv = await tablestore.get();// 用户每访问一次就给 pv 的值加 1pv += 1;// 保存最新 PVawait tablestore.save(pv);return pv;}
基于 FaaS 和 BaaS 的架构,是一种计算和存储分离的架构。 计算由 FaaS 负责,存储由 BaaS 负责,计算和存储也被分开部署和收费。这使应用的存储不再是应用本身的一部分,而是演变成了独立的云服务,降低了数据丢失的风险。而应用本身也变成了无状态的应用,更容易进行调度和扩缩容。
基于 FaaS 和 BaaS ,你的应用就实现了自动弹性伸缩、按量付费、不用关心服务器,这正是 Serverless 架构的必要因素。所以说狭义的 Serverless 是 FaaS 和 BaaS 的组合。
什么不是 Serverless
除了广义和狭义上的 Serverless, 我经常被同学们问到另一个问题,那就是 PaaS、Kubernetes 、云原生等技术是不是 Serverless?如果不是,它们与 Serverless 有什么关系?这个问题很常见,你可以根据我刚刚总结的 Serverless 的特点进行判断。
在01讲中我已经提到了,PaaS (平台即服务)是云计算虚拟机时代的主要形态之一。 它是指云厂商提供开发工具、依赖库、服务和运行平台等能力,开发者可以依赖这些能力将自己的应用直接部署在云平台上,不用关心底层的计算资源、网络、存储等。虽然与Serverless 很类似,但依旧存在一些区别。
- 付费标准: PaaS 的部署单位是应用,大部分 PaaS 还是将应用部署直接在服务器(虚拟机)上。所以我们对 PaaS 付费,依然是按资源付费,而不是按实际使用量付费。
- 弹性伸缩: 有的 PaaS 虽然提供了弹性伸缩能力,但只能针对底层的服务器进行扩缩容。而 Serverless 的弹性伸缩是请求级别的,扩容速度更快,资源利用也更高效。
Kubernetes 本身也不是 Serverless,只是在概念方面有些类似。 Kubernetes 是一种容器编排技术。在 Kubernetes 中应用运行的基本单位是 Pod(容器组),Pod 是应用及运行环境的集合,所以你也不用关心服务器了。基于 Kubernetes,你能很方便地进行 Pod 的管理,并且实现应用的弹性伸缩。
但从运维的角度来看,主流的 Kubernetes 服务提供商,如 EKS (Amazon Elastic Kubernetes Service) 和 ACK(阿里云容器服务),提供的都是 Kubernetes 集群托管和运维服务,开发者可以方便地管理 Kubernetes 集群中硬件、存储、Pod 等资源,但上层应用的运维和调度还是需要开发者自己进行。
从成本的角度来看,Kubernetes 也无法做到按代码执行次数和实际消耗资源计费,还是和传统的 Serverful 一样,按照资源数量计费。
所以,Kubernetes 是介于 Serverful 和 Serverless 中间的产物。
而云原生指的是原生为云设计的架构模式,就是应用一开始设计开发就按照在云上运行的方式进行,充分利用云的优势。Serverless 几乎封装了所有的底层资源调度和运维工作,让你更容易使用云计算基础设施,极大简化了基于云服务的编程。
因此 Serverless 是云原生的一种实现,
云原生的另一种实现是 Kubernetes。
Serverless 的优缺点
没有一项技术是十全十美的,Serverless 也一样。了解它的优缺点,可以让你今后更好地进行技术选型,决定是否用 Serverless 进行应用开发。根据 Serverless 的定义,Serverless 的优点主要有:
不用运维、
弹性伸缩、
节省成本、
开发简单、
降低风险、
易于扩展。
但它也存在缺点。
- 依赖第三方服务
要用 Serverless,就要用云厂商提供的 Serverless 产品,比如 FaaS、BaaS,这样业务就和第三方云厂商绑定了。并且一旦你选择了一个云厂商,要想从一个云移到另一个台,成本很高(因为现在 Serverless 还没有一个统一的标准,云厂商各做各的,Serverless 产品也都不一样)。所以,依赖第三方服务是优点也是缺点。当然,我觉得这是大势所趋,让专业的人做专业的事,可以极大提高生产力。
- 底层硬件的多样性
目前 Serverless 的技术实现是 FaaS 和 BaaS。你的应用代码在 FaaS 上运行,但其底层的硬件资源多样,也不确定,云厂商可以灵活地选择服务器来运行你的代码,这就让运行函数的物理环境变得不同,甚至有的函数会运行在不同代的 CPU 上。 如果代码不依赖底层 CPU,那影响可能是不同 CPU 性能有差异;如果代码必须运行在某种类型的 CPU 或 GPU 上,那就需要云厂商提供这种能力了。这其实也暴露了云厂商的目的,就是最大化平衡资源利用效率与成本。当然,如果你不是特别关注底层硬件,影响也不大。
- 应用性能瓶颈
基于 Serverless 架构的应用,函数运行前需要现初始化函数运行环境,这个过程需要消耗一定时间。因为函数不是持续“在线”的,而是需要运行的时候才启动(不像传统应用,服务是一直启动的)。
从资源利用率来讲,这种模式可以节省资源,但从应用性能上来讲,这就会降低应用性能,并且还要靠云厂商实现性能优化(让延时只有几毫秒或者几十毫秒,毕竟一个接口最大的耗时是在网络上,可能长达几百毫秒)。但如果你的应用对性能非常敏感,就需要考虑一下怎么去优化应用性能了。
- 函数通信效率低
传统的 MVC(Model-View-Controller) 架构模式中,View 层方法调用 Model 层方法,都是在内存中进行的。而在 Serverless 应用中,函数与函数之间就完全独立了。如果两个函数的数据有依赖,需要进行通信、交换数据,就要进行函数与函数之间的调用(调用方式是 HTTP 调用)。相比之前的内存调用,数据交互效率显然低了很多。而这个问题的本质,是 FaaS 还没有比较好的数据通信协议或方案。
- 开发调试复杂
Serverless 架构正处于飞速发展的阶段,其开发、调试、部署工具链并不完善(基本是每个云厂商各玩各的)。 另外,应用依赖的第三方云服务也很难进行调试。要想在本地开发调试 Serverless 应用,还是比较复杂。
不过在我看来,虽然 Serverelss 存在缺点,但随着技术的不断成熟,这些问题在未来都能得到解决。
总结
这一讲我提到了 Serverless 、Serverless 架构和 Serverless 平台,其中,Serverless 是架构思想;
基于 Serverless 思想的软件架构,就是 Serverless 架构;
Serverless 平台指云厂商的 Serverless 相关的产品。
关于今天这节课,我强调这样几个重点:
- 广义上来讲, Serverless 是一种架构思想,即软件构建和运行时不需要关心服务器;
- 狭义上来讲, Serverless 是 FaaS 和 BaaS 的组合,是当前主流的技术实现。
- Serverless 架构的主要特点是按量付费、弹性伸缩、不用运维, 这是区分一个架构是否是 Serverless 架构的关键因素。

若有收获,就点个赞吧
0 人点赞
